语义相似度领域基于XGBOOST算法的关键词自动抽取方法*
2020-08-11王成柱魏银珍
王成柱 魏银珍
(武汉邮电科学研究院 武汉 430074)
1 引言
随着互联网的成熟与移动互联网的普及,人类进入了一个数据爆炸的时代,无处不在的文本信息塞满了我们的生活,我们需要对这些信息进行选择与过滤,而人工筛选的成本过大,因此,如何有效并且准确地自动抽取文本中的关键信息便成了自然语言处理领域急需解决的基础问题和研究热点,对文本分类[1],情感分析[2],文档检索[3],问答系统[4]等细分领域的研究有着重大意义,而关键词自动抽取便是其中的核心问题。
关键词自动抽取被定义为自动识别一组最能描述文本主题的词语的任务,这组词语可以很好地代表文本的中心意思,当我们知道文本的中心意思后,无论是对文本进行分类,情感分析,或者意图识别,都可以很快地做出判断。而在语义相似度计算中,关键词自动抽取是影响相似度计算结果的重大因素,利用关键词我们可以生成多种基于关键词的相关特征,更好地判断文本的相似程度。
GBDT(Gradient Boosting Decision Tree)是一种基于梯度提升的集成学习算法,其主要思想是通过弱模型的迭代加权累加形成一个强模型。XGBOOST(eXtreme Gradient Boosting)是陈天奇对GBDT的一种高效实现,在学术界和工业界有着广泛实现。本文XGBOOST算法引入关键词自动抽取领域,并与传统机器学习算法进行比较。
本文提出的关键词自动抽取算法是针对语义相似度领域,即在比较两个文本是否相似时,对两个文本抽取关键词,由于该场景的特殊性,存在相似与不相似两种不同分布,因此本文在单一文本的关键词自动抽取技术的基础上,提出了一种基于KL散度的关键词特征,并且引入XGBOOST算法,融合KL散度,TF-IDF等多种特征提出了一种基于机器学习的关键词自动抽取方法。
2 相关工作
关键词自动抽取方法可以分为两大类,无监督方法和有监督方法。
无监督方法利用候选词的统计特征的得分进行排序,选取最高的若干个作为关键词。无监督方法包括基于统计模型的算法、基于语义的算法和基于图模型的算法。基于统计模型的关键词抽取算法中常见的有基于词频和TF-IDF的算法,该类方法简单易实现,通用性与实用性较好,但准确率较低,通常作为关键词抽取算法的基础。基于语义的算法使用词,句子和文本的语义特征进行关键词抽取,该类方法考虑了语法的含义,但是依赖于背景知识库,词典等,难以推广与迁移。基于图模型的算法是近年来研究者研究无监督方法的主流方向,图是一种数学模型,它能非常有效地探究关系和结构信息,受到PageRank在信息检索领域巨大成功后的启发,2004年Mihalcea和Tarau提出一种基于图的排序算法TextRank,该方法的基本思想是将文本看成词的网络,该网络中链接表示词与词之间的共现关系,一个词的重要性由链向它的词的重要性与数量决定。由于需要构造图结构,因此该方法不适合短文本或句子。
有监督方法是利用标注训练集,抽取候选词的各类特征,将问题转换为一个机器学习问题,通过模型对每个候选词进行判定。自1999年Frank提出采用朴素贝叶斯分类器,利用TF-IDF和相对位置两个特征抽取关键词以来,研究者不断尝试各种经典分类器,并且细化已有特征和提出新的特征,诸如决策树,支持向量机,条件随机场,随机森林等分类器,词频,长度,位置,词嵌入向量等特征以及不同场景下的加权处理都被研究者不断地研究与运用,进而提出更有效的关键词自动抽取方法。
本文针对语义相似度领域,研究了KL散度用于关键词自动抽取的可实现性,并且融合KL散度,TF-IDF等多种特征,基于XGBOOST算法构建了一个机器学习模型,结果表明,该方法比现有的无监督方法和基于传统机器学习的有监督方法效果更好。
3 基于XGBOOST的关键词自动抽取方法
本文在语义相似度领域利用KL散度构造了一个关键词评分指标,并且设计了一种基于XGBOOST算法,融合KL散度,TF-IDF等多种特征的关键词自动抽取方法。
3.1 关键词特征
3.1.1 KL散度
在数理统计中,KL散度也被称为相对熵,是一种度量一个概率分布与另一种概率分布偏离的方法,对于离散概率分布P和Q,从Q到P的KL散度定义为

对于连续随机变量的分布P和Q,其KL散度定义为

本文将两个文本相似与否当成两种不同的概率分布,相似标记为1,不相似标记为0,对于这两种概率分布可以应用KL散度得到偏离程度。


由数据统计的结果,我们可以得到每个特征在不同分布中的概率,利用这两个离散概率分布,根据KL散度计算出的结果即为每个特征的重要性得分,如果 pk=qk,即该词语在相似对文本对与不相似文本对中出现的概率相等,其KL散度则为0,该特征的影响可以忽略不计,这种方法可以有效地增加在标记ti=1的文本对中共同出现的词语,及在标记ti=0的文本对中单独出现的词语的重要性得分。
3.1.2 TF-IDF
词频(Term frequency,TF)是指词语在给定文本中出现的频率:
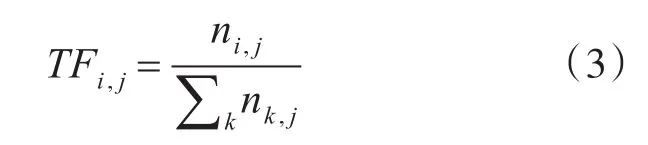
其中ni,j表示第i个词语在第j个文本中出现的次数,表示第j个文本中的总词数,
通常情况下认为词频高,该词为文本中的关键词的可能性越大。在某些长文本或者文档中,有TF变化得到多种相关特征,如标题TF,摘要TF等被提出,但实际情况经常存在某些常用词的使用频率特别高,其本身却并不是关键词,因此在整体语料的基础上引入了逆文档频率(Inverse document frequency,IDF)来衡量包含一个词语的普遍重要性:
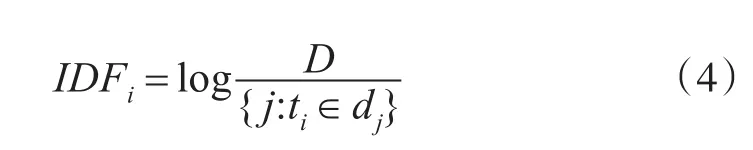
其中D表示总文本数,ti表示第i个词,dj表示包含ti的文本,j表示包含ti的文本数。在某些时候可能存在特殊情况,若文档集中不存在某个生僻的词语,这会导致公式中的分母为0,此时的IDF值便没有意义了,因此在实际操作中,本文中做了平滑处理:

根据某一特定文本的高频词语,以及该词语在整个文件集合中的逆文档频率,我们可以综合起来得到tfidf:

TF-IDF是一种无监督学习的关键词抽取方法,综合了词频与逆频率的优势,当TF-IDF值越大时,即该词语在当前文本中出现频率高,而在其他文本中较少出现,则说明该词的重要性程度越大。经过几十年的研究与发展,关键词自动抽取出现了各种各样的方法,但是由于TF-IDF的有效性和简单性,它仍然在当今关键词自动抽取的学术界与工业界占据了重要的地位。
3.1.3 词长
词长特征是指词语本身的长度,通常关键词的长度一般为2和3,因此关键词的长度具有很好区分性。
3.1.4 词性
词性是浅层的语言特征,不需要对文本进行复杂的分析,根据关键词的词性分布规律,本文将词性设计为多维布尔型特征,选取的关键词词性标注为NN,VV,JJ,AD,,DT,VA,VE,DT,如果一个词的词性标注为NN,那NN对应的特征记为1,其他的词性特征则记为0。通过对词性特征进行选择性组合,既可以避免词性特征维度过高与稀疏,同时也有很好的区分性。
词性特征能够有效克服基于传统统计方法无法解决高频但无非重要性的词语,从而提高关键词自动抽取的性能。
3.2 XGBOOST算法介绍
Boosting算法属于集成学习,其主要思想是通过迭代生成多个弱模型,然后将每个弱模型的预测结果相加得到一个强模型。
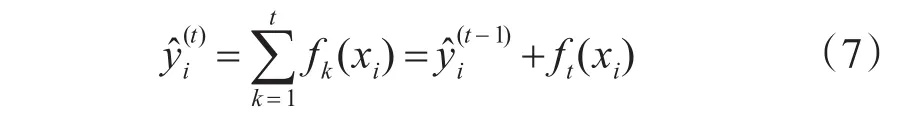

在XGBoost中,我们对损失函数进行泰勒展开:

由损失函数的公式可知,γ与λ越大,表示希望获得结构相对简单的树,确定树的叶子结点之后,进行树的分裂,我们采用贪心生长的方法,遍历所有特征,基于分裂前目标函数值与分裂后最小目标函数值,找到增益最大的点为最优点,其对应的特征即为最优特征,以此循环,直到一定深度或者无法继续分裂时停止,此时的树便是第t轮迭代的最优子结构树。将每轮得到最优子结构树进行累加求和即得到XGBOOST算法的最终模型。
XGBOOST是GBDT的一种高效实现,它相较于传统的GBDT有着多方面的优势,它利用泰勒展开求二阶导比一阶导即梯度更加准确,支持线性基分类器,加入正则项控制模型复杂度,同时它也支持分布式计算,更加适用于大规模数据集的训练,并且可以进行列抽样,能够降低过拟合,减少计算量。本文利用采用python语言的XGBOOST工具包实现了关键词自动抽取模型。
3.3 实验流程
本文实验的输入数据为一段文本,已标记数据中会标识每个文本中的关键词,将文本预处理后得到文本中的词语与词性标注以及对应的标签,实验分为两个步骤,训练阶段和预测阶段。
步骤1训练阶段:对数据集中的训练集进行预处理与特征抽取,利用XGBOOST算法训练获得关键词自动评分模型。
步骤2预测阶段:利用训练阶段得到的模型对测试数据进行关键词评分,对文本中的词语进行得分排序,取排名前N的词语为该文本的关键词。
本文关键词自动抽取框架如图1所示。
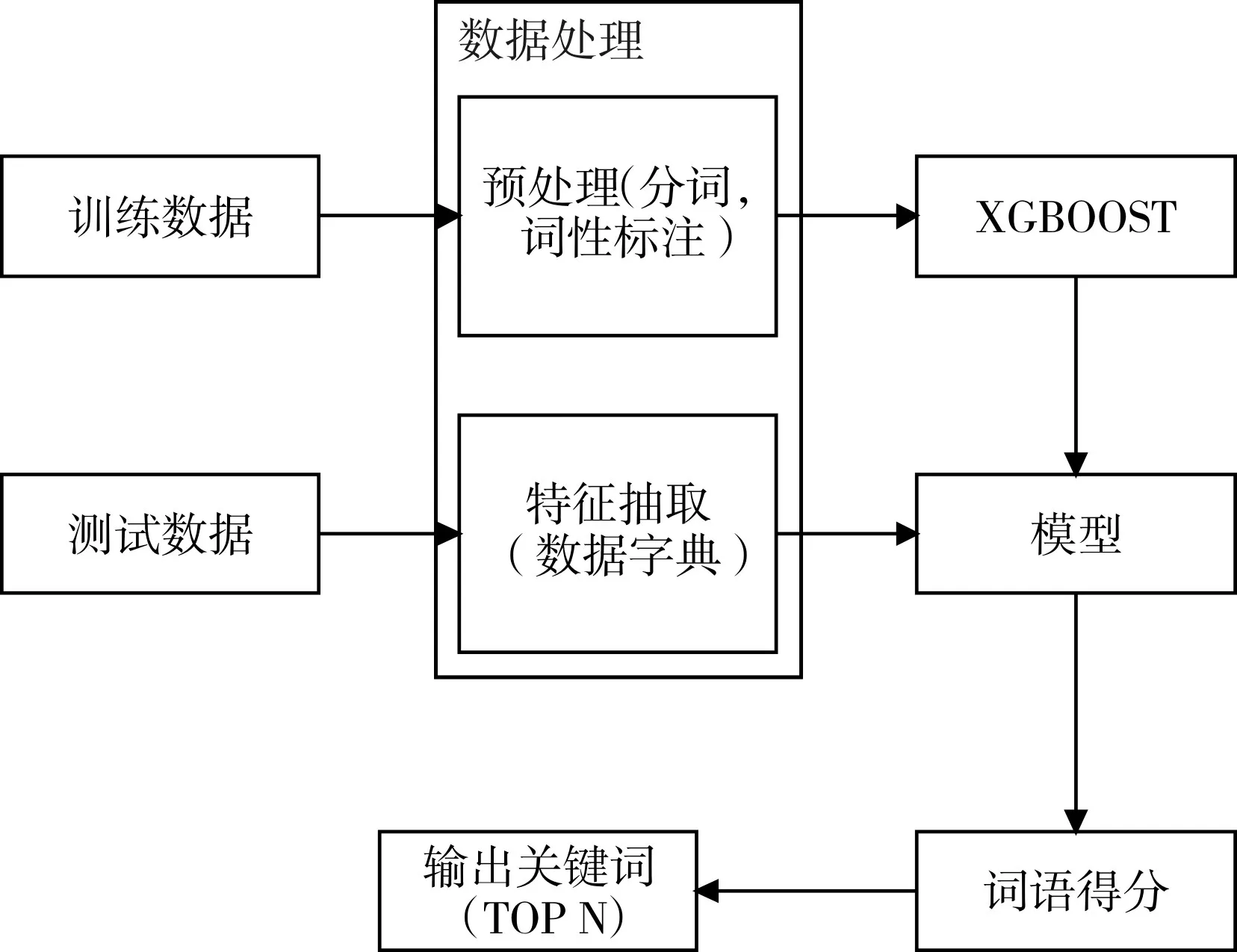
图1 关键词抽取框架
其中特征抽取部分依赖于数据字典,即根据大规模语料计算得到的每个词语的KL散度与TF-IDF得分字典,输出关键词部分中含有一个超参数N,即选取文本中排名前N的词语作为关键词输出,可以根据不同场景来确定不同的N值。
4 实验分析
4.1 实验数据
本文采用电商客服中的客服回答模板语料,共303个句子,预处理之后得到7821个词语,其中标注为关键词的词语个数为1557个,将其切分训练集与测试集,如表2所示。
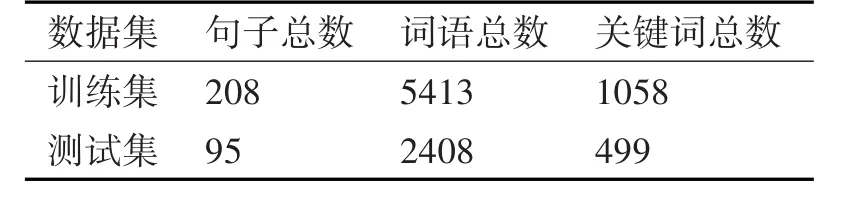
表1 数据集
4.2 评估指标
由于本文研究的是语义相似度计算领域的关键词自动抽取方法,对于两个文本,关键词抽取的个数相同时才方便用于计算语义相似度的特征,如Jaccard距离,因此我们每个句子中抽取N个关键词,只需要关心每个句子中抽取的N个词语中关键词的准确率,至于当句子中关键词个数大于N时,还有多少个关键词未被抽取出,即召回率,在此场景下我们并不关心。
本文中关键词自动抽取的评估指标采取句子中得分排名前N的词语的准确率作为评估指标,即准确率P=句子得分排名前N的词语正确的个数/句子中关键词的个数(大于N按N算)。
4.3 算法性能对比
实验中XGBOOST模型选择基于树的模型做提升计算,参数booster为gbtree,学习率eta设置为0.1,训练的最大深度max_depth设置为9,此时性能最优。
针对不同的超参数N,即选取每个文本中得分排名前N的词语作为关键词,本文算法与无监督方法KL散度,TF-IDF,以及有监督方法SVM和LR进行了评估指标的对比,结果如图2所示。

图2 算法性能对比图
由图2可以明显地看出有监督方法相对于无监督方法准确率有大幅提升,在无监督方法中,KL散度的表现比TF-IDF更好,因此在语义相似度计算领域,KL散度可以代替TF-IDF得到词语的重要性得分,在有监督方法中,XGBOOST算法的准确率高于SVM算法和LR算法,并且在效率方面也大幅领先,运算时间相对而言更少。因此,在语义相似度计算领域,本文提出的KL散度方法是优于TF-IDF的,基于XGBOOST算法的有监督方法也比传统的机器学习方法准确率更高。
5 结语
在语义相似度计算领域,本文提出了一种基于XGBOOST算法,融合KL散度,TF-IDF等多种特征的关键词自动抽取方法,根据得分排序选择最终关键词。实验证明,该方法不仅优于单一的无监督方法,也比基于传统机器学习算法的有监督方法效果更好。
本文的下一步研究工作将会考虑更多的词语特征,如依存关系,词向量表示,并且扩大标注数据集,进一步优化关键词自动抽取的效果。并且将该方法用于语义相似度计算中,通过提高关键词抽取的准确率来优化语义相似度计算的结果。
