大数据下Apriori算法的改进研究
2020-08-10谢胡林
谢胡林
(绍兴职业技术学院,绍兴312000)
0 引言
在数据挖掘领域中,关联规则旨在找出数据集中项与项之间未知的关系,进而可以从挖掘出的数据对象信息中得到我们需要的信息。Apriori算法可以利用它挖掘数据集中数据项间的潜在关系。
Apriori算法其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集,而且算法已经被广泛的应用到商业、网络安全等各个领域。典型的例子有沃尔玛超市的尿布与啤酒、超市的牛奶与面包、百度文库推荐相关文档、淘宝推荐相关书籍等,这些都是商务智能和关联规则在实际生活中的运用。
但是Apriori算法缺点很明显,使用该算法的时候需要多次对数据库进行扫描,这样会增加算法花费在读写操作上的时间,导致挖掘算法的时间成本上升,这种成本是随着数据库存储数据的增加而呈几何级数上升的;其次,使用该算法则会产生大量的候选频繁集,每一步产生的候选频繁集有时候是非常巨大的,导致算法在广度和深度上的适应性很差。
Apriori算法是最经典、最具影响力的挖掘频繁项目集的算法,该算法在关联规则研究中具有里程碑作用,但是在实际应用过程中,Apriori算法有两个致命的性能瓶颈:其一是多次扫描事物数据库,需要更大的I/O负载,其二是可能产生庞大的候选集,许多专家学者提出了一些基于Apriori算法的改进算法以提高Apriori算法的效率,如散列(Hash)技术、划分(Partition)技术、采样(Sampling)方法等。但是这些改进的算法又或多或少的存在一些问题,如采样方法,它最大的问题就是如何选取样本数据,即便选取了样本数据且提高了算法的效率却降低了算法的精度。
本文以Apriori算法分析为依托,改进算法的四个方面,从而有效地提升算法的挖掘性能,将高职院校就业情况当成是研究对象,在比较后其挖掘成效突出。
1 Apriori算法的优化
1.1 增加数据库
文中以Apriori算法为依托,结合形成的频繁项集Lk-1(k=1,2,…k-1)将数据库Dk加入进来,在Dk里将k-频繁项集和它的事务集合进行保存,假设事务集合是Ei,Ei={t1,t2,…,tm,…,tq},所以,Lk-1在自连接时使得k-候选项集Ck得以形成,计算Ck的支持度的过程中,不必扫描原始数据,仅对Ck子集事务Ei进行扫描即可,之后将不同子集事务Ei的交集计算出来,在上述集合中事务的数量,也就是这一候选项集的支持数,之后删除低于支持度的一些候选项集,从而可以使访问效率提升,这一算法优化后的伪码见下。
输入:原始数据库将m个事务包括在内
输出:D里涉及的频繁项集

1.2 挖掘频繁1-项集
首先,分类数据块。把数据库结合相应的规定进行划分,使其数据块大小一致,向计算节点进行传送,将Map模型有效地执行。
其次,初始化数据化。在不同计算节点里把全部数据向
之后,Map函数。局部扫描其中的健值,再将
再次,Reduce函数。将Map函数的输出结果进行接收,同时进行合并,使局部候选1-项集得以形成,这样能够使全局候选集得以形成。
最后,结合支持度,使频繁1项集L1得以形成。倘若L1不成功,那么算法结束。这一算法优化后的伪码见下。


1.3 挖掘频繁2-项集
首先,将数据块以及频繁1项集L1输入。初始化数据块。在不同计算节点,把数据向
之后连接。通过不同节点中的L1使C2得以形成。
接着使用Map函数局部扫描数据库,从而将C2的sum进行获取。之后Reduce函数。自获取Map函数的输出结果,将其与局部候选2项集重组,这样使得全局候选2项集得以形成。
最后,生成结果。自既定的最小支持度,使频繁2项集L2得以形成,倘若生成不成功,那么把L1当成是结果输出,算法完成。这一算法优化后的伪码见下。

1.4 加入动态存储空间
通过Apriori算法可以看出,全部的2-频繁项集中全部元素均以1-频繁项集密切相关,相同地,超出2的频繁项集里,全部元素均与2-频繁项集密切相关,结合这一现象,文中将动态存储空间进行应用,对这一算法进行优化,从而快速提取数据库。
建立以(k-1)-频项集为依托的动态存储空间,以这一算法为基础,使k-频繁项集形成,在(k>2)过程中,以(k-1)-频项集为依托,将链掊作进行实施,使k-频繁集的提取速度提升,这样能够使扫描次数下降,使运算速度提升。
2 实验仿真
想要使算法的挖掘成果体现出来,将以Hadoop为基础的大数据平台进行应用,将Linux系统广泛推广,以Vmware虚拟机为依托,对其进行建立,软件方面将64位Windows系统应用,硬件方面将酷睿i5作为CPU,6G内存,将主节点1个,从节点2个进行建立,将不同数据容量进行设置,将与学生就业评价相关的数据记录进行选取,共计一千条。把评价质量项目进行划分,共六个方面,企业对学生的技术能力、社会能力、工作能力以及自主能力等进行评价。

表1 数据集属性
所以,对输入项目来说,其数量是5个,最小支持度是1,挖掘分析数据中的六个方面内容,其项目集是Item={{I1},{I2},{I3},{I4},{I5},{I6}},使得数据表得以形成,具体见表2-表3。
通过图1可以看出,这一算法评价指标具体的成效,同时能够看出,在不同记录的情况下,这一指标的结果是有着很大的不同之处的,从某种程度来看,这意味着这一就业评价指标是十分典型的。通过图可以看出,这一算法和以SVM为依托的样本分类进行比较,其成效是不同的。可以看出,这一算法的样本分类,与SVM分类进行比较,前者要好一些,这是由于将数据库加入进来,同时将频繁1-项集进行优化,将频繁2-项集进行优化,同时将动态存储空间加入进来,从而使得Apriori算法的性能发生了很大的变化,从而有效地提升了这一算法的挖掘成效。
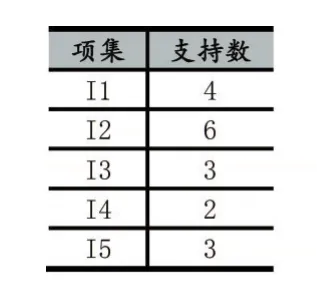
表2 数据项对应集

表3 候选集集合
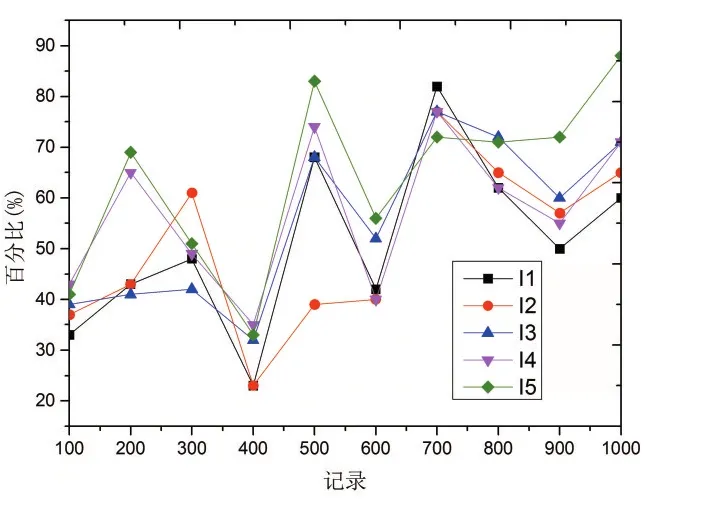
图1 算法评价成效
3 结语
本文结合Apriori算法自身的问题,有效地优化Apriori算法,优化的这一算法,其性能发生了很大的改变,在评价分析高职院校就业指导后,得出结论这一算法的挖掘成效是十分显著的。
