基于数据挖掘的高校教改项目评审机制研究
2020-08-10王佳乐方刚
王佳乐,方刚
(重庆三峡学院,重庆404100)
0 引言
高质量的高等教育教学改革项目研究将直接影响着学校教育教学管理的成效,决定着高校可持续建设与发展的命运[1]。为了建立科学的、合理的、符合实际的项目评审机制,项目组织部门开展了项目评审[2]、项目监管[3]和项目管理[4]的机制研究;高等院校更热衷于项目评审管理机制研究,如文献[5]探讨了基于帕累托定律模型的高校科研项目评审机制;文献[6]对高职院校教改项目评审机制进行了优化研究。随着大数据技术的广泛应用,基于智能信息化的项目评审研究掀起了高潮,如文献[7]提出一种面向工作分解结构的评审人员指派方法;文献[8]通过对抗性设计方法解决项目评审中的社会伦理问题,为专家、申请者、大众提供争论和表达异议的民主环境;文献[9]针对评审过程的不透明带来了评估不公正、结果不准确的隐患,探讨了大数据信息化项目在第三方服务模式下的评审。如何立项建设高质量的教育教学改革项目?这向教育教学改革项目评审工作提出了严峻的挑战,可见,研究其评审机制具有重要的现实意义和应用价值。
1 项目评审过程中存在的问题
(1)评审专家来源单一独特
项目组织管理部门在评审时选择评审专家的方式不一样,有的选择具有单一性,在学科布局上不够合理,不能够做到本校学科全覆盖;如选择优势学科带头人作为专家,而其它学科的项目可能因不深入评审而被落选。有的选择具有独特性,专家组成结构缺乏多样化,要么是清一色的校内各级领导,要么是清一色的教授博士,缺少一线应用专家。
(2)评审专家库更新频率不快
有的学校虽然建立了评审专家库,但基本是静态的,没有动态淘汰专家的机制,新鲜血液补充不及时,专家观念老化现象比较严重。有的学校评审项目聘请专家是临时的,聘请者的主观性很大。
(3)运用人工智能方法计算评审结果不多
项目管理部门在汇总专家评审结果时,计算项目总成绩的方式相对单一,有的运用专家划分的等级,分组确定立项名单;有的运用专家评审的分数,通过平均成绩或加权平均成绩排名来确定立项名单;有的运用专家确定的名次,按比率划分名额来确定立项名单。虽然这些方法在一定程度上反映了申请项目本身的质量,但评审成绩会受到来自专家职业道德、责任心和学科领域的影响,特别是直接按分数来确定是有很大偏差的。目前,能够运用数学模型,通过人工智能的方法来评价项目质量的方式很少。
2 项目评审机制框架及构建
(1)项目评审机制架构
大数据时代下,建立基于数据挖掘的教育教学改革项目评审机制,主要包括建立专家动态调整机制、学科领域关联机制、评阅成绩审定机制和评审专家信誉度机制四个部分;项目评审机制的框架结构如图1所示。
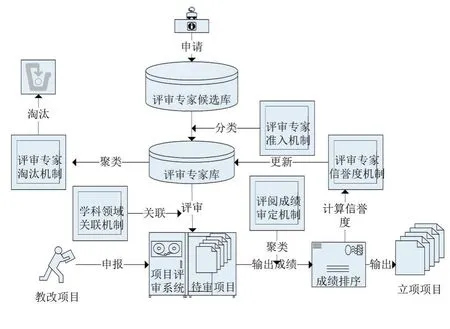
图1 项目评审机制框架结构
(2)评审机制构建思路
①建立评审专家动态调整机制
动态调整机制包括评审专家准入机制和评审淘汰机制两部分:评审专家准入机制通过数据挖掘分类方法把专家候选人自动添加到评审专家库中;评审专家淘汰机制主要是用数据挖掘聚类方法把信誉度较差的专家从评审专家库中淘汰。
②建立学科领域关联机制
关联机制是将待审项目与评审专家进行智能关联,主要解决的问题是怎样把待审项目提交给最佳评审专家组,即用数据挖掘关联分析方法提取频繁模式,进而生成评审专家组。
③建立评阅成绩审定机制
成绩审定机制是把所有评审专家的评阅成绩进行聚类分析排序,确定出立项建设的教改项目。
④建立评审专家信誉度机制
评审专家信誉度机制首先建立信誉度计算方法,每次评审结束后更新评审专家库的专家信誉度,为评审专家淘汰机制提供数据支撑。
3 建立项目评审机制
3.1 建立评审专家动态调整机制,为形成优质评审专家库奠定基础
专家库中每个学科领域的专家数对评审专家动态调整机制影响不大,但数量要求至少两名;评审专家准入机制和淘汰机制构建过程如下。
(1)评审专家准入机制
评审专家准入机制主要是把评审专家候选库中的专家通过数据挖掘的分类方法(如决策树方法ID3等)自动加入到评审专家库中。
首先,确定入选专家的规则,具体描述如下:
第一规则:校内学科领域全覆盖规则;即加入候选专家可以填补评审专家库中学科领域空白,如果候选专家数多于填补名额,则选择第二规则。
第二规则:教育教学业绩分多优先规则;即教育教学业绩分数多的先进入评审专家库,如果教育教学业绩分数相同,则选择第三规则。
第三规则:专业技术职称高者优先规则;如果职称相同,则选择第四规则。
第四规则:教育教学经历长者优先规则;如果教育教学经历时间相同,则选择第五规则。
第五规则:成为专家候选人早者优先规则;此选择具有唯一性。
其次,转换候选专家数据库信息,以专家候选人为实体,确定特征(属性):
①是否填补学科领域,取值为:是,否。
②教育教学业绩分数,取值为:高,中,低。
③专业技术职称,取值为:高,中。
④教育教学经历,取值:长,中。
⑤申请候选时间,取值:早,迟。
最后,用分类算法(如决策树方法ID3等)生成入选专家类和落选专家类,并将入选专家添加到评审专家库中。
(2)评审专家淘汰机制
评审专家淘汰机制主要是用数据挖掘的均值聚类算法把信誉度较差的专家从评审专家库中淘汰。
首先,把所有评审专家的信誉度构成一个数据集合;
然后,用数据挖掘的均值聚类算法(),将评审专家根据信誉度分成两类:信誉度较好和信誉度较差。
最后,淘汰信誉度低集合中的评审专家。
3.2 建立待审项目与评审专家的学科领域关联机制,保障评审质量
在评审过程中,如果领域专家对待审项目研究的内容不熟悉或把握不全面,可能造成误评,影响评审成绩。学科领域关联机制主要是用数据挖掘的关联分析算法把待审项目提交给最佳评审专家组。
首先,建立项目涉及领域和评审专家熟悉或精通领域的数据库;
其次,用数据挖掘的关联分析算法(如Apriori算法)提取频繁模式;
最后,把支持度较高的且包含项目涉及领域的频繁模式形成一组评审专家及其对应的待评审项目。
3.3 建立评阅成绩审定机制,保障评出优质教改项目
评阅成绩审定机制主要是把不同评审专家评阅相同项目时给出的评阅成绩进行聚类分析汇总排序,确定出立项建设的教改项目。
假设有M个评审专家,从N个待审项目中,评选出K个建设项目,这里M,N,K均为整数。
首先,针对第p个专家评阅的项目成绩进行K均值聚类分析,聚类得到K个集合,这里令评阅成绩最高所在的集合为第1个集合,最低所在的集合为第K个集合,其余依次类推,则每个项目的审定成绩为Gp:
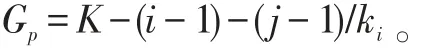
i表示集合排序,即第i个集合;
j表示第i个集合中的项目按评阅成绩的排序;
ki表示第个集合中的项目总数,则有
其次,针对第q个项目,汇总来自所有评审专家的审定成绩Gp,根据专家信誉度Hl计算出加权平均成绩,即为项目的最终审定成绩Gq:这里Hl为第l个评审专家的信誉度。
最后,汇总N个评审项目的最终审定成绩Gq,选择出前K个项目作为立项建设的教改项目。
3.4 建立评审专家信誉度机制,支撑评审专家动态调整机制
专家进入评审专家库时,信誉度c(0≤c≤1)定为100%,专家每参加一次评审,其信誉度就更新一次,信誉度的更新机制如下:
(1)参加一次评审的信誉度计算方式为:
本次信誉度=专家本次评审推荐项目命中数/本次立项建设总数
(2)当前信誉度的更新计算方式为:
当前信誉度=历史信誉度×本次信誉度,或者
当前信誉度=(历史信誉度+本次信誉度)/2,或者
当前信誉度=(历史信誉度×+本次信誉度)/(n+1),n为参与评审次数。
4 结语
基于数据挖掘的教育教学改革项目评审机制能动态地、公平地添加专家到数据库,努力建立广覆盖面和高素质的评审专家库,并合理地将评审项目分配给关联性较强的专家组,科学地计算评审成绩得到高质量的立项建设项目,达到项目评审的最终目的。
