基于聚类分析的智能答疑系统在招生咨询方面的应用
2020-08-06王艳军陈子航沈雪静
王艳军 李 舒 陈子航 董 坤 沈雪静
(1.河南师范大学 智能计算与数据挖掘工程中心 招生办公室,河南 新乡 453007;2.河南师范大学 计算机与信息工程学院,河南 新乡 453007)
1 引言
招生宣传在当今重视教育发展的时代背景下尤为重要,随着时代的变化,伴随着新高考改革步伐的进行,考生数量每年呈现递增态势,信息通道在重复构建。据调查,考生每年报考时都存在信息获取不完善等诸多问题。新生一般通过官方网站、QQ群和咨询电话等方式获取报考信息,其中使用较多的方式是进行人工咨询和网上询问,其存在电话热线高峰期难拨通、咨询问题不能及时被解答等问题,另外网上答疑的方式单一,常会出现答非所问的现象,因为咨询信息量巨大,答疑人员只是集中解答相似度较高的问题,无法特别细致地进行解答。随着科技发展迅速,引入更加科学智能化的咨询平台就显得尤为重要。
2 网上的智能答疑系统
随着目前教育规模的不断扩大,大学生数量急剧增加,给高校招生录取工作带来很大压力,单纯的招生信息管理系统已经远远不能满足需求,因此笔者根据需求并结合教育相关政策提出了智能答疑系统的建设目标,即以网络为基础,利用先进的信息化手段和工具,实现资源数字化,实现计算机管理大量的数据。智能答疑系统将积聚大量的数据,如何挖掘数据中所隐含的有价信息,应用这些有价信息去指导学校的招生工作,从而改善整个招生咨询的管理,提高录取管理效率是一项非常有意义的工作。
2.1 答疑系统的基本模式
网上的智能答疑是由图1过程操作完成,对于常见性问题以及重复性问题,由智能机器人自动识别并对其进行解答,若出现智能机器人无法解决的问题,将会自动转化为人工服务,可以分级管控,答疑质量与效率兼顾;快捷搜查对照回答,减少答疑培训;设有过程跟踪管理,具有即时答疑即时互动的优点,减少了招办人工延时答疑的问题,而且手机通知答疑结果,更为便捷。通过对不同类别的生源进行信息采集,将其分类分析,最后生成一个分析报告,使结果更加明了。
2.2 答疑系统信息访问来源
图2数据是智能答疑系统根据聚类分析思想而自动检测并生成的结果图,较以往人工整理更加快捷便利。
3 引入聚类分析方法
数据挖掘是近些年来发展起来的新技术,通过数据挖掘,人们可以发现数据背后隐藏的有价值的、潜在的知识,为科学地进行各种商业决策提供强有力的支持。而聚类分析是数据挖掘中的一项主要技术,它是将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中,从而为相关数据基础上的决策提供依据,保障整个招生咨询工作。
3.1 聚类分析基本思想
由于所研究的样品或指标之间存在不同程度的相似性。于是根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间相似程度的统计量,以这些统计量为划分类型的依据。把一些相似程度较大的样品或指标聚合为一类,把另外一些彼此之间相似程度较大的样品或指标又聚合为另一类,直到把所有的样品或指标聚合完毕。在聚类分析中,通常我们将根据分类对象的不同分为Q型聚类分析和R型聚类分析两大类。笔者在本文中多采用Q型聚类分析。Q型聚类分方法是对样本进行分类处理,根据变量的分类结果以及它们之间的关系,可以选择主要变量进行回归分析或Q型聚类分析。
3.2 聚类方法的步骤
3.2.1 数据预处理
数据预处理包括选择数量、类型和特征的标度,它依靠特征选择和特征抽取,特征选择是选择主要的特征,特征抽取把输入的特征转化为一个新的显著特征,它们经常被用来获取一个合适的特征集,避免“维数灾难”。数据预处理还包括将孤立点移出数据,孤立点是不依附于一般数据行为或模型的数据,因此孤立点经常会导致有偏差的聚类结果,因此为了得到正确的聚类,我们将孤立点剔除。
在招生工作中,对考生信息进行分类的几个最主要特征是区域类别、考生类别、专业类别。招生人员在进行招生录取过程中,依据上述三个类别区分各考生的信息。同时在招生中还存在一些扰乱的信息,比如:有些考生在我校招生咨询留言板上询问关于其他院校的一些情况,或者询问一些与报考院校不相关的信息,这些都称之为孤立点,需要将其剔除才能获取较为准确的聚类结果,以便于分析。为此我们采集到了某高校在招生过程中处理问答信息的相关数据,如表1所示。

表1 招生问答信息表
3.2.2 为衡量数据点间的相似度定义一个距离函数
既然相似性是定义一个类的基础,那么不同数据之间在同一个特征空间相似度的衡量对于聚类步骤是很重要的,由于特征类型和特征标度的多样性,距离度量必须谨慎,它经常依赖于应用。例如,通常通过定义在特征空间的距离度量来评估不同对象的相异性。
在招生应用中,本文采取的是欧式距离的度量方法,对来自不同省份不同专业的考生进行算法分析。因为在进行招生时,不同区域的招生要求存在差异,不同专业类别的招生要求也不相同,这就要求我们需要将地域相同,专业类别相同的考生归为一类,因此借助二维空间内的相似性度量来进行距离计算,我们假设该生所在地域为横坐标,所选专业类别为纵坐标,建立空间直角坐标系,如图3所示。
我们将横坐标不同区域的考生分别定义为X1,X2,专业类别定义为Y1,Y2,将距离函数关系定义为D,可设计算公式如下:
其中当考生所在区域相同时,X2-X1=0,当所在区域不同时,X2-X1=1;当考生所报类别相同时,Y2-Y1=0,当所报类别不同时,Y2-Y1=1;在计算距离函数时,D越小,说明考生相似性越高,反之越低。
借助欧式距离函数,我们可以将考生进行分类,减小统计难度。
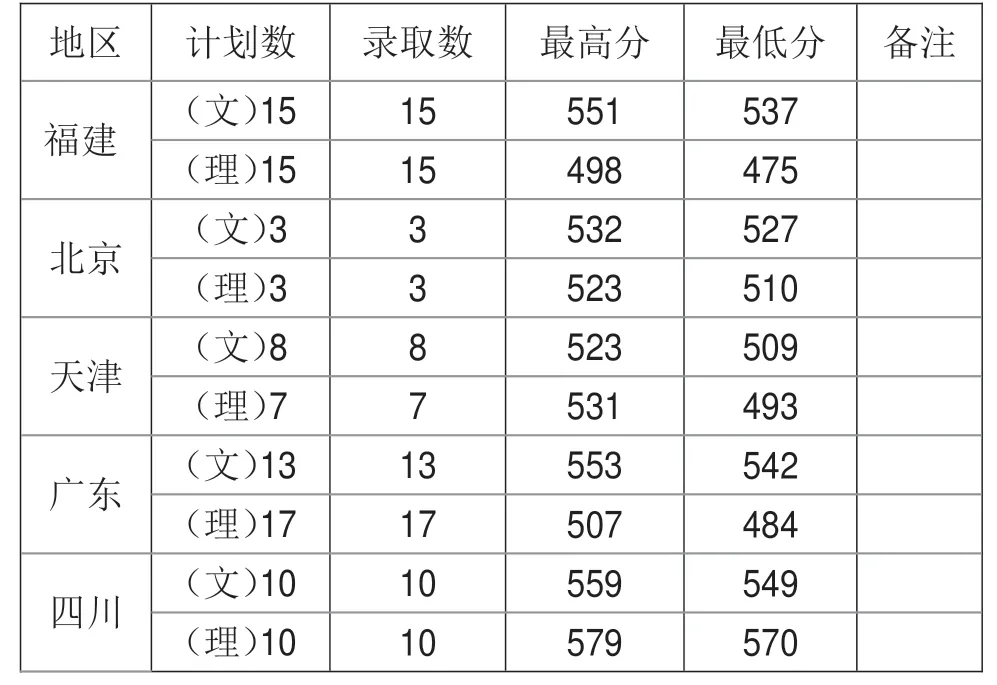
表2 招生数据
表2是某高校在2019年对5个省份招生的数据,当我们用欧式距离对其进行分析的时候,可以看到对福建的招生中根据地域来计算,因为都处于同一个省份,故D 为0;另外在福建招生中,文科生与理科生分别招生15人,在对类别进行计算的时候,D 为1;相比较北京和福建招生时,两者属于不同的省份,故D为1。分析表2数据可知,当我们只有数据却未知其具体分类情况时,可以采用欧式距离算法对其进行分析,根据D 的数值将其更加细致地分类,从而减少了人工操作的繁琐。
3.2.3 聚类分组
在招生工作中,首先根据不同的省份将其进行第一次分类,将相同省份的考生集中在一起,因为不同的省份之间对考生的要求不同,将其进行分类是为了避免出现回答问题时的失误;再根据考生是文科生还是理科生进行第二次分类,因为每年文科生和理科生录取的分数线都有一定的差异,而且相对于专业而言,有些专业只允许理科生填报,而有些专业是只允许文科生填报,为了避免出现这种填报的严重性错误,需要将理科生和文科生区分开来;然后再根据所询问的专业进行第三次分类,不同的专业分数要求不同,尽量减少分数的浪费以及错误的填报。
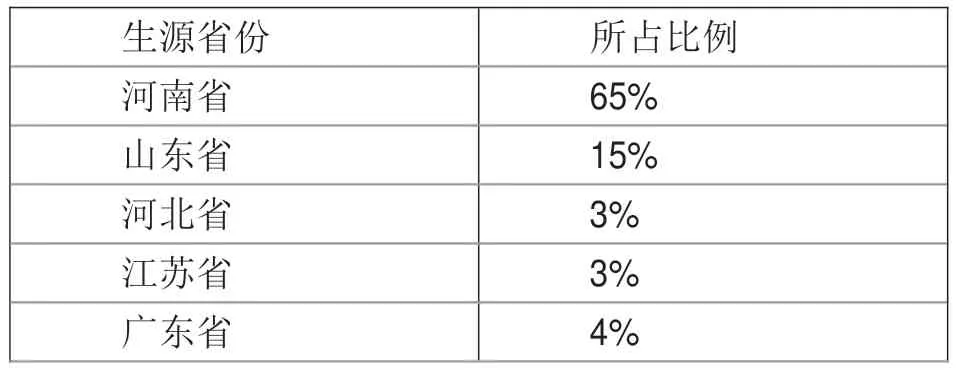
表3 生源省份信息表
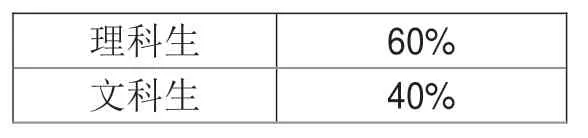
表4 高校文理招收统计表
3.2.4 评估输出
评估聚类结果的质量是一个重要阶段,聚类是一个无管理的程序,也没有客观的标准来评价聚类结果,它是通过一个类有效索引来评价。类有效索引在决定类的数目时具有重要作用,通常决定类数目的方法是选择一个特定的类有效索引的最佳值,这个索引能否真实得出类的数目是判断该索引是否有效的标准。
在招生工作中的类有效索引便是文科生和理科生的区别,但仅靠文科生和理科生的区别,不能完全得出类的数目,还需对区域以及专业进一步分类,以便得出更准确的结果。
4 结语
本文在面对招生的过程中提出一种基于聚类分析的答疑模式,将考生信息进行聚类,得到较好的分类结果,不仅提高了工作速度,还节省了时间和人力,并且结合互联网技术,将智能答疑系统应用于招生工作,其在未来的高校招生领域具有较好的应用前景。