基于混合深度卷积网络的图像超分辨率重建
2020-08-06胡雪影郭海儒
胡雪影,郭海儒,朱 蓉
(1.河南理工大学计算机科学与技术学院,河南焦作 454000;2.嘉兴学院数理与信息工程学院,浙江嘉兴 314000)
(*通信作者电子邮箱zr@mail.zjxu.edu.cn)
0 引言
图像超分辨率(Super Resolution,SR)重建旨在通过输入一幅或多幅低分辨率(Low Resolution,LR)图像重建出包含丰富细节的高分辨率(High Resolution,HR)图像。重建技术作为一个不适定的逆问题,其过程需要尽可能收集和分析更多的相邻像素以获取更多的线索,用于上采样过程中补充丢失的像素信息。而单图像超分辨率(Signal Image Super Resolution,SISR)[1-2]重建则是要利用一幅图像中包含的丰富信息以及从样本图像中得到的视觉先验,识别重要的视觉线索,填充细节,并尽可能忠实和美观地呈现。近年来,重建技术在医疗影像、卫星遥感、视频监控等领域都有着广泛的应用。
在计算机视觉任务中,为由低分辨率图像重建出高分辨率图像,研究者们已经提出多种SISR 方法,主要可分为传统的SISR 方法[3-4]和深度学习方法[5]。传统的SISR 方法是基于经验算法实现,会遗忘大量的高频信息且需要一定量人为干预,方法的性能结果与实际应用要求有着较大的差距。
由于出色的性能,深度学习方法已成为模式识别与人工智能领域研究的热点,其中的卷积网络(Convolutional Network,ConvNet)[6]近年来更是在计算机视觉任务中取得巨大成功。Dong 等[7]提出的超分辨率卷积神经网络(Super-Resolution Convolutional Neural Network,SRCNN)使用了三层卷积网络首次将深度学习运用到图像超分辨率重建中,网络以端到端的方式学习从LR 到HR 的映射,不需要传统方法中的任何工程特性,并且获得比传统方法更先进的性能。Kim等随后提出的深度递归卷积网络(Deeply-Recursive Convolutional Network,DRCN)[8]和极深度超分辨网络(Very Deep Super-Resolution network,VDSR)[9]取得了当时最先进的性能。Wang 等[10]在生成对抗网络为主体的增强型超分辨率生成对抗网络(Enhanced Super-resolution Generative Adversarial Networks,ESRGAN)中,融合感知损失提高对低分率图像的特征重构能力,还原图像缺失的高频语义信息,取得了逼真视觉效果;Mao 等[11]提出具有对称结构的编解码网络(Restoration Encoder-Decoder Network,REDNet)对SR 过程产生的噪声有抑制作用,能恢复出更加干净的图片。残差通道注意力网络(Residual Channel Attention Network,RCAN)[12]通过在卷积网络引入注意力机制,通过考虑卷积特征通道之间的相互依赖性来自适应地重新缩放通道方式的特征;Hui等[13]提出的信息蒸馏网络(Information Distillation Network,IDN),在信息蒸馏模块里,局部特征可被有效提取且有着轻量级参数和计算复杂度。深度SR 方法优秀的性能在特定的图像超分辨中得到应用[14-16]。
但上述方法在成功将深度学习技术引入超分辨率问题的同时,也具有一定的局限性。SRCNN 存在着依赖于小图像区域的上下文,训练收敛太慢,网络只适用于单尺度的缺陷;VDSR 虽然解决了SRCNN 存在的问题,但VDSR 较小的感受野使得其网络卷积层简单链式堆叠,鲁棒性与泛化性得不到保证;DRCN 则由于使用了循环卷积网络,导致训练时间长,存储量大,不便于实际应用;而ESRGAN采用对抗的方式生成SR 图像,破坏了SR 图像与HR 图像像素间的对应关系,且网络规模庞大不利于训练与使用。
针对上述SR方法存在的问题,本文提出一种基于混合深度卷积网络的图像超分辨率重建方法。该方法中卷积与反卷积构建的编解码结构去除图像SR过程产生的噪声,空洞卷积扩大卷积感受野,通过不同卷积方式的混合使用构建端到端网络,重建出符合原高分辨率图像的超分辨率图像。
与前述SISR方法相比,本文所提方法具有如下特点:
1)网络直接学习低分辨率和高分辨率图像之间的端到端映射,采用卷积与反卷积级联编解码方式,消解图像特征中含有的噪声。
2)在图像重建部分中应用空洞卷积层,使小的卷积核获得大的感受野,提升重建效果的同时降低计算量。
3)使用残差学习快速优化网络,通过在网络中添加多个个跳跃连接,加速训练过程并提高重建结果性能。
1 相关工作
1.1 高分辨率图像成像模型

实验研究中,低分辨率图像成像模型通常表示为:其中:IL为低分辨率图像;IH为高分辨率图像;D为下采样算子;B为模糊算子;n为加性噪声。
由式(1)推导由低分辨率图像得到高分辨图像的超分辨率重建过程模型:

其中:B-1D-1n可简化为S(生成噪声),得到式(3):

由式(3),经过上采样(D-1)、去模糊(B-1)、降噪(-S)等一系列处理操作,可将低分辨率图像重建为高分辨率图像。
1.2 卷积编解码结构用于图像特征去噪
计算机视觉的图像处理非常依赖于图像的特征。图像的特征就是用较少的数据来描述捕获图像内容中包含的重要信息,因此,图像特征本质上可以理解为图像的稀疏化表示[17]。由此,Zeiler 等[18]提出了反卷积网络(DeConvolutional Network,DeCNN)的概念,这是一种基于正则化图像稀疏表示方法,能够提取出图像特征并利用这些特征重构图像;陈扬钛等[19]将基于L1正则化反卷积网络模型应用于图像表述与复原,去除图像噪声;Long 等[20]在用于图像分割的全卷积网络(Fully Convolutional Network,FCN)模型中使用反卷积层(Deconvolution layer)获得优异效果,突出证明了反卷积网络在图像处理中的巨大作用;Xu等[21]发现真实的模糊退化很少符合理想的线性卷积模型,采用反卷积网络捕获图像退化特征进而复原图像(式(4)),而不是单纯地从生成模型的角度对异常值进行完美建模[22]。

其中:x为输入图片;c为图片的通道数量;i为图像像素;k为特征图数量;⊗为卷积操作;Z为特征图,是局部隐变量,对于每个输入x都不一样。f是卷积核,为全局变量,对所有输入x都一样。
借鉴上述思想及方法,将卷积与反卷积联结使用,并且增加卷积深度,使其在图像超分辨率重建去噪过程中发挥更大的作用,进一步证实较深的卷积与反卷积层联合使用可以显著提高超分辨率的性能。
1.3 空洞卷积用于扩大卷积感受野
研究者们对深度学习的不断探索,贡献了很多经典的卷积神经网络。LeCun 等的开拓性成果LeNet[23],是大量神经网络架构演进的起点,为后续相关深度学习研究领域提供灵感;和LeNet 相似的AlexNet[24],不仅解决了网络较深时存在的梯度弥散问题,提高训练速度,而且还增强了模型的泛化能力;继承LeNet 以及AlexNet 部分框架结构的VGG[25]更是直接利用了多层小卷积核叠加的优点(3个3×3的卷积核的链式叠加正则等效于1 个7×7 的卷积核),这种设计不仅可以大幅度地减少参数,其本身带有正则性质的卷积图能够更容易学习一个通用的、可表达的特征空间;残差网络(Residual Network,ResNet)[26]则是在网络中增加直连通道,允许原始输入信息直接传到后面的网络层中。这不仅可以极快地加速神经网络的训练,也能比较大地提升模型的结果准确率等。
然而深度卷积神经网络对于其他任务存在着一些致命性的缺陷。例如:下采样/池化过程导致内部数据结构丢失、空间层级化信息丢失、小物体信息无法重建等。而图像超分辨率重建过程需要更多的相邻像素(即依赖大感受野)。因此如何在卷积感受野大小与网络参数数量二者中找到一个平衡点,是一个至关重要的问题。而空洞卷积(扩张卷积)能在不使用会导致信息损失的pooling 层且计算量相当的情况下,提供更大的感受野,这恰恰与图像超分辨率重建的理念(SISR网络不需要pooling 层)相重合。因此,空洞卷积的设计恰好可解决上述如何找到最佳平衡点问题。
空洞卷积诞生于图像分割领域[27],图像输入到网络中经过CNN 提取特征,再经过pooling 降低图像尺度的同时增大感受野。在图像需要全局信息或者语音文本需要较长的序列信息依赖的问题中,都有很好的应用效果[20,28-29]。对比传统的卷积加池化操作,普通多层卷积联结使用,只能达到卷积层数与感受野大小成线性关系,而空洞卷积与卷积的联合使用,可以使感受野与层数呈指数级增长。如图1 所示,圆点为卷积点,深色区域为感受野。
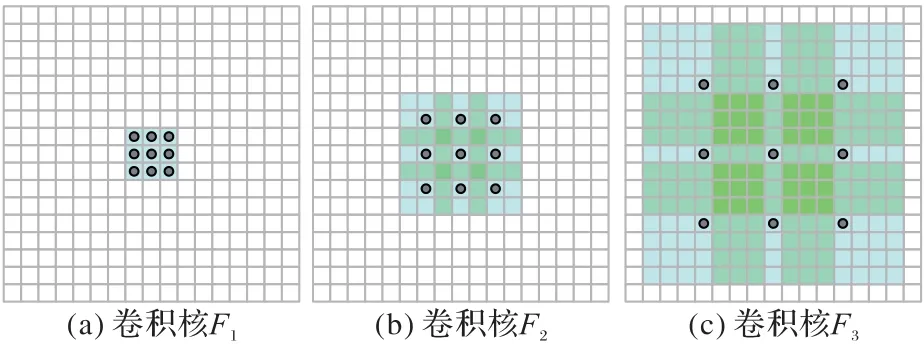
图1 不同比率空洞卷积感受野对比Fig.1 Comparison of receptive fields of dilated convolutions with different ratios
将图1中不同比率点距的空洞卷积层联结,级联卷积效果如图2所示。
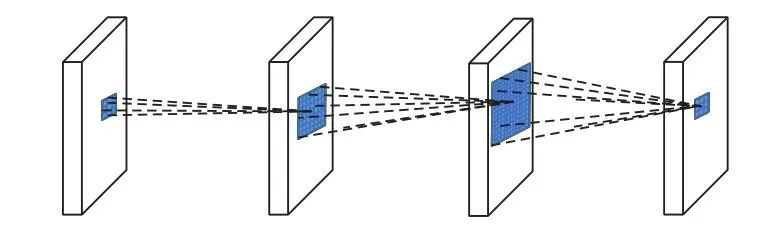
图2 不同比率空洞卷积多层级联Fig.2 Multi-cascade of dilated convolutions with different ratios
空洞卷积网络参数数量呈线性增长,而使卷积感受域指数扩展,保证网络参数量限度的同时增大感受野。图1(a)是由3×3 卷积核F1通过1 倍的卷积产生的,其卷积点间距为1,其每个卷积具有3×3的感受野;(b)F2是由F1通过2倍的卷积产生的,卷积点间距为2,F2中的每个卷积核的感受野为7×7;(c)F3是由F2通过4 倍的卷积产生的,卷积点间距为2,F3中的每个卷积核的感受野为15×15。与每一层关联的参数数量相同。
在图像超分辨重建网络中,采用卷积与空洞卷积的级联使用,扩大了卷积感受野,在不增加网络容量的前提下能获得更多相邻像素信息。
1.4 残差学习用于深度网络
传统的卷积层或全连接层在进行信息传递时,或多或少会存在信息损耗丢失问题。He 等[26]为解决深层网络训练困难的问题提出的残差网络(ResNet)[26]在卷积网络中增加直连通道,允许原始输入信息直接传到后面的网络层。不仅可以极快地加速神经网络的训练,并且提升了模型的准确率。确切地说,残差网络通过直接将输入信息绕道传到输出的方式,在某种程度上解决了图像特征细节缺少的问题,保护图像信息的完整性。即整个网络只需要学习输入、输出的残差部分,简化了学习目标和难度。残差块的结构如图3所示。
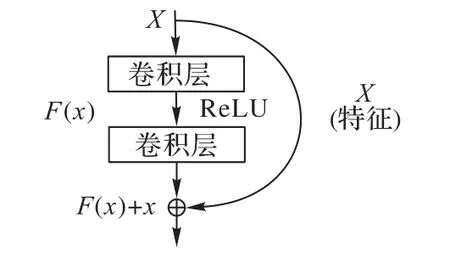
图3 残差结构Fig.3 Residual structure
如图3 所示,假设原始网络学习函数为H(x),将其分解为H(x)=F(x)+x。分解后原始网络(图3 垂直向下的流程)拟合F(x),分支x(图3 弯曲部分,为跳跃连接)。在ResNet中引入了残差函数F(x)=H(x)-x(即目标值与输入值的偏差),通过训练拟合F(x),进而由F(x)+x得到H(x)。如果F(x)=0,则相当于引入了一个恒等映射到图像超分辨率重建任务中,使用残差学习通过在卷积网络添加跳跃连接可将图像初始特征直接传输到网络中后层,协助梯度的反向传播,加快训练进程,提高结果性能。
2 本文方法
2.1 网络模型
本文所构建的网络模型主要由四个模块组成:上采样、特征提取、编解码结构去噪和图像重建。上采样模块将低分辨率图片通过简单上采样,得到与高分辨率图像具有相同像素的低分辨率图像;特征提取模块将图像表示为可供处理的特征映射;编解码结构完成图像特征去噪任务;任务完成后,将反卷积去噪中的最终特征映射输入重建模块,最终生成超分辨率重建图像。具体模型如图4所示。
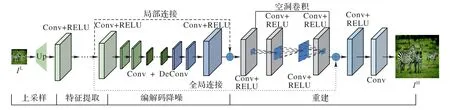
图4 网络架构Fig.4 Network architecture
2.1.1 上采样
在基于深度学习的图像超分辨率重建任务中,由高分辨率图像的重建模型(式(3)),需要通过上采样将低分辨率图像放缩至与高分辨率图像具有相同像素数量的次低分辨率图像。而上采样中最简单的方式是重采样和插值:主要通过将输入图片重新缩放到一个想要的尺寸,同时计算每个点的像素点。文献[7-9]即是采用在图像输入网络前使用双三次线性插值对低分辨率图像进行上采样,但此方法形式上增加了人工干预,过多添加工程特征,影响重建效果。受文献[20,22]的思想启发,本文采用反卷积网络结构将输入低分辨图像上采样到目标图像大小。此部分使用卷积核为3×3的反卷积层将低分辨率图像上采样至目标图像同等尺度大小,作为特征提取层的输入。
2.1.2 图像特征提取
传统图像恢复中,图像特征提取的一种策略是先将图像块进行密集提取[30],之后用一组预先训练的基底(如主成分分析(Principal Component Analysis,PCA)[31]、离散余弦变换(Discrete Cosine Transform,DCT)[32]等)来表示。而在卷积神经网络中,此部分可纳入到网络的基础优化中,卷积操作自动提取图像特征。形式上,本文的特征提取子网络表示式(5):
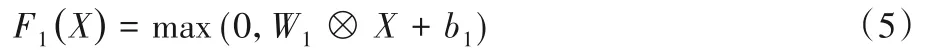
其中:X为上采样后低分辨率图像;W1和b1分别表示卷积权值和偏置,其中W1大小为3×3×64;“⊗”表示卷积运算,运算添加0 边界,步长为1,使输入、输出尺寸保持一致,防止产生边界降秩。同时使用RELU[33](max(0,×))用于卷积特征激活。使用双层64 个3×3 卷积核的卷积层提取上采样后图像的特征,获取到图像特征细节。
2.1.3 编解码去噪结构
在特征去噪结构中,卷积与反卷积级联使用构造编解码结构,可以最大限度地消解图像特征噪声。卷积层保留了主要的图像内容,反卷积层则用来补偿细节信息,在达到良好去噪效果的同时较好地保留图像内容[34]。针对输入含有噪声图像特征和干净图像,本部分网络结构致力于学习一个残差即F(X)=Y-X得到。形式上,这一层形式化表示为:
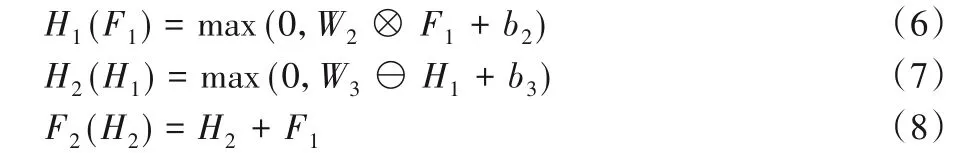
其中:F1为特征提取阶段输出;W2和b2为卷积权值与偏置大小,W2为3×3×64;W3和b3为反卷积权值与偏置,W3大小为3×3×64;“⊖”表示反卷积运算。式(8)是一个跳跃连接[26],正如残差网络的设计初衷,跳跃连接可以解决网络层数较深的情况下梯度弥散问题,同时有助于梯度的反向传播,加快训练过程。
卷积层逐渐缩小特征图大小,保留了主要的图像内信息,获取图像特征的抽象内容;反卷积层再逐渐增大特征图的大小,放大特征尺寸的同时恢复图像特征细节信息。同时采用跳跃连接加快训练过程,最终在确保编解码结构输入输出尺寸大小一致的同时,也保证了在移动端计算能力有限情况下的测试效率,获得去除噪声的图像特征图。
本部分卷积层全部使用64 个3×3×64 的卷积核。但前半部分的卷积运算不添加0边界且步长为2,使特征输出尺寸变为输入的一半。而在后半部分的反卷积特征恢复中,卷积运算添加0 边界、步长为2。将特征图恢复到原来大小,保证图像尺度完整性。
2.1.4 图像重建
在重建过程中,输入隐藏状态的特征图F2,输出超分辨率的重建图像,可以看作为特征提取阶段的逆运算。在传统的SR方法中,通常平均化重叠高分辨率特征图以产生最终的完整图像。而在网络卷积中,使用卷积核W dc作为一个反作用基底系数,将高维隐藏状态图像特征的每个位置看作高分辨率图像所对应像素不同维度的矢量形式。反之可以将特征图投影到图像域中,获得超分辨率重建图像。受此启发,定义了一个卷积层来生成最终的高分辨率图像:
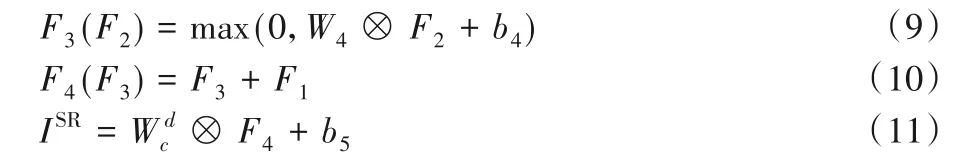
式(9)为形式化的空洞卷积,W4为空洞卷积的卷积权值,设置rate分别为1、1、2、4。式(10)是一个跳跃连接,提高训练速度;式(11)为超分辨率图像重建,ISR为输出的超分辨率重建图像,为c个大小为1×1×64 的卷积核,c代表着图像通道数量,b5表示卷积偏置。
本部分前4 层卷积使用64 个3×3×64 的卷积核对图像特征进行高维提取运算,其卷积核卷积点间距分别为1、1、2、4,可以以更大感受野对图像特征进行运算。随后使用64 个3×3×64 卷积核构成的卷积层,将初次提取到的图像特征与高维特征进行加和运算,保证了特征的充分利用。最后使用C(C为高分辨率重建图像通道数量)个1×1×64卷积核的卷积层重建出需要的高分辨率图像。
本文通过将上述四种不同功能驱动的模块(它们都与卷积网络具有相似的形式)联结在一起,形成一个具有去噪、增大感受野的混合深度卷积神经网络,用作图像超分辨率重建任务。
2.2 训练
2.2.1 损失函数与优化
对于任意给定一个训练数据集{X1C,Y1C}n-1i=0,本文的目标是找到准确映射值Y=F(x),使获得的超分辨率重建图像F(x)与真实高分辨率图像Y之间的均方误差(Mean Squared Error,MSE)[35]最小,同时也有利于图像质量评价指标——峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[36]的提高。尽管高PSNR 并不代表重建图像的绝对优秀,但当使用替代评估指标(如SSIM(Structural SIMilarity))来评估模型时,仍然观察到满意的性能。
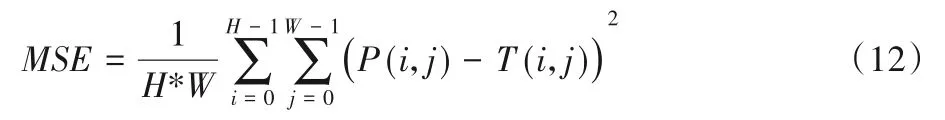
其中:P(i,j)、T(i,j)分别表示预测图像与真实图像;H、W分别为图像的高度和宽度。

即:
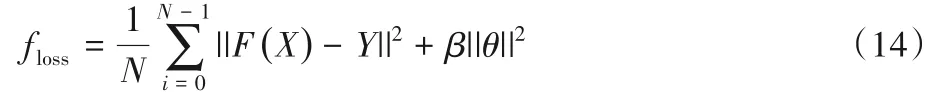
在本文中,将MSE作为一部分并入损失函数floss(式(14))。通过添加L2权重衰减对训练进行正则化,β表示权值衰减的乘系数,设为10-3,θ即为所求参数。这样在得到最终损失的条件下,可以微调节参数来尽可能地达到最优结果。
2.2.2 优化方式
本文使用Adam 优化方法[37]更新权重矩阵,以将损失函数数值降至最低。其参数更新公式为:

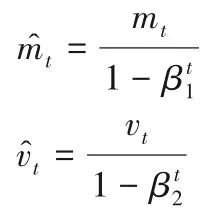
其中:β1设为0.9;β2设为0.999 9;ε设为10-8;学习率η为0.001;mt为梯度的第一时刻平均值;vt为梯度的第二时刻方差值。
2.2.3 参数设置
在训练之前,需要初始化网络参数以供后续网络训练更新。对于权重初始化,结合Kin等[9]描述的方法。本文从平均值为零、标准偏差为0.001(偏差为0)的正态分布中随机抽取数值,初始化每层的卷积核权重W,而偏置b则全部置0。初始学习率被设置为0.001,之后每训练20轮递减1/2。
实验的硬件环境为AMD Ryzen 2700X 八核的处理器;Nvidia GeForce GTX 1080 Ti GPU;软件环境为Ubuntu 16.04的操作系统。网络模型采用tensorflow 框架构成。实验训练了网络参数100 轮次(每轮次1 000 次迭代,迭代批次大小32),100个轮次后停止学习。
3 实验结果与分析
3.1 数据集
训练集 使用公开自然图像数据集BSD200[38](200 个图像)与T91 数据集[39](91 个图像),其适用于大多数实验。在SRCNN/VDSR中已证明深度模型通常受益于海量数据的训练。实验中将291个训练图像进行旋转90度、镜像、倒置等操作,获得包含1 164 个图像的增强训练数据集;同时在增强训练数据集上裁剪64×64 大小(裁剪步幅为16)的子图送入网络,便于学习网络参数。将网络模型应用于任意大小的图像,因为它是基于完全卷积的,而裁剪可更加方便地优化网络模型参数。
测试集 使用通常用于基准测试[7,40]的数据集Set5[41](5个图像)和Set14[42](14 个图像)、BSD100[38](100 个图像)以及由Huang等[43]提供的城市图像Urban100数据集。
由于卷积网络的特殊性,其只能将图像放缩双倍大小。本文在测试数据集评价了两个尺度因子,包括×2和×4。
3.2 定性定量分析
1)编解码结构降噪。
在本文所提方法中,用编解码结构卷积提取图像特征,保留主要特征;用反卷积针对特征上采样,恢复图像细节,从而完成图像特征噪声过滤,进而达到图像特征降噪的目的。
如图5(a)显示了有反卷积构建编解码结构与不具有反卷积网络对比示例。当没有反卷积层时,网络模型为标准卷积网络。通过观察比对可发现含有反卷积编解码去噪部分的网络可以达到更高的精度(以PSNR为指标)。
2)空洞卷积。
空洞卷积不改变卷积运算本身的运算方式与参数,通过修改卷积核的构造以不同的方式使用过滤器参数。空洞卷积使用不同的扩张比例因子在不同的范围内应用相同的卷积核参数,以达到获取更多图像上下文信息的目的。显然,第一层的特征图包含不同的结构(例如,不同方向的边),而第二层的特征图在强度上主要不同。
如图5(b)展示了具有空洞卷积与不具有空洞卷积网络对比示例,空洞卷积通过扩张卷积感受野促进了性能的提高。
最后,图5(c)中展示了同时使用反卷积和空洞卷积与二者皆不使用的性能对比曲线,发现当二者同时使用时对性能提升效果显著。
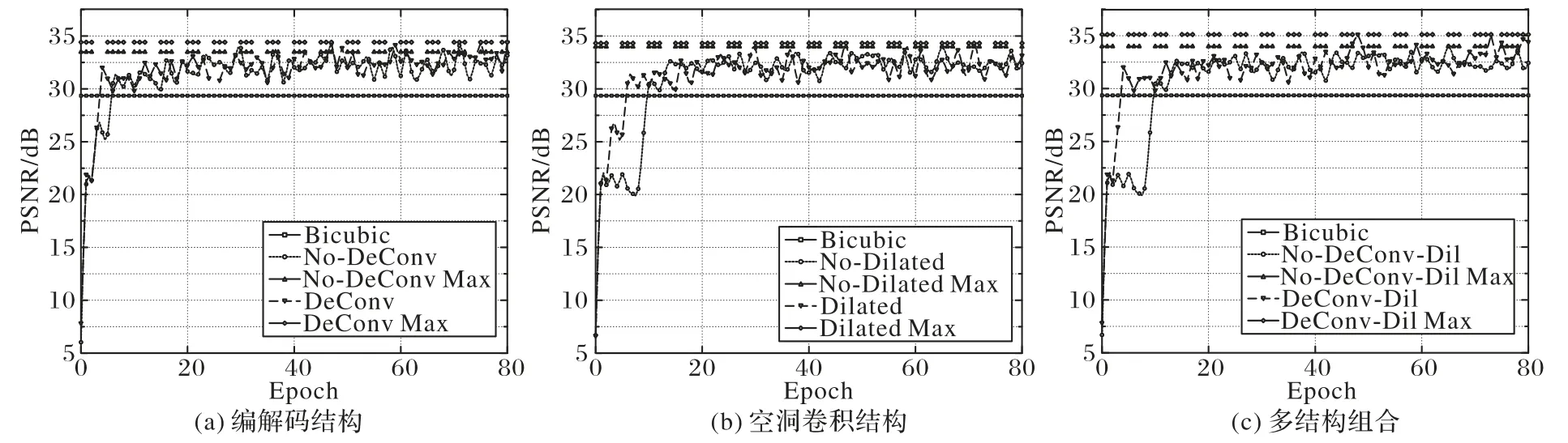
图5 各网络结构性能结果分析Fig.5 Performance result analysis of different network structures
3)残差学习。
输入图像在网络计算中携带着大量的细节信息,但如果在输入与输出之间存在许多卷积递归,就会产生梯度问题,如梯度消失/爆炸等。它们之间的映射关系学习是非常困难的,并且学习效率非常低。此时,可以通过设置残差学习快速解决这个问题。
在网络中添加了两个跳跃连接,如图4 所示:其一为特征去噪部分局部连接,协助梯度的反向传播,加快训练过程;另一个则为远程跳跃连接,加快训练过程,提高结果性能。具体对比分析结果见表1。
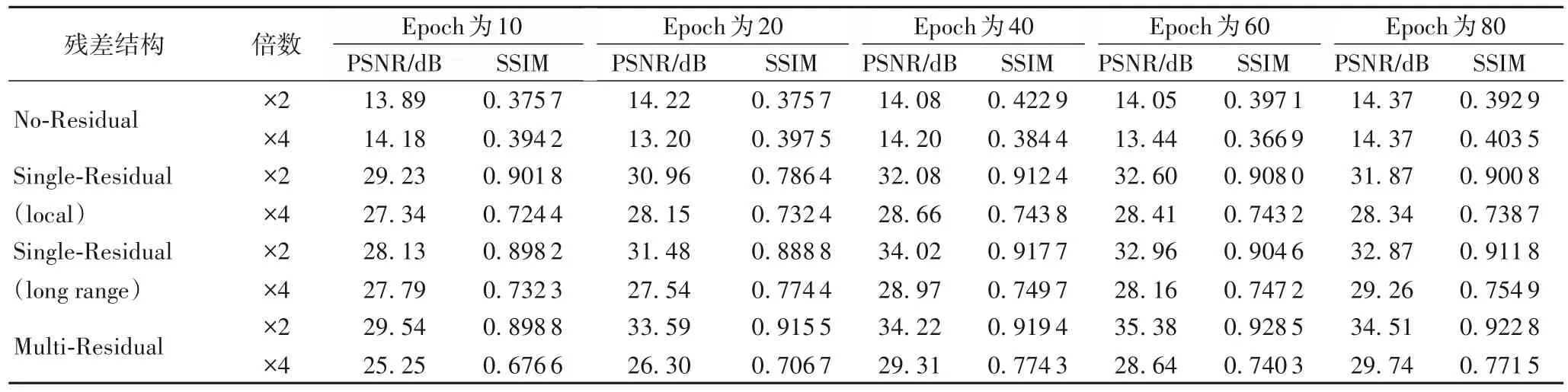
表1 残差学习测试(学习率:0.001)Tab.1 Residual learning testing(learning rate:0.001)
表1 实验采用全卷积网络,在数据集Urban100 上针对比例因子2 和4 在不同训练轮次下的超分辨率重建定性定量分析结果,学习率设为0.001,评测指标为PSNR/SSIM。经过对比分析可以发现,含有跳跃连接的网络无论是训练速度还是评测指标都比非残差学习网络的结果更加优异,而在未含跳跃连接的网络中,不仅训练收敛困难,并且结果很差。而这也证明了残差学习在模型训练的表现良好。通过对比,发现含有单跳跃连接的网络中,远程连接比局部连接的结果性能更好,而训练收敛速度次之。在含有多跳跃连接的网络,无论是收敛速度还是结果性能都比单连接网络结果优异。
综上,使用残差学习所学习映射的效果要比直接学习效果相对较好,学习速度更高。
3.3 结果分析
将本文所提方法与其他几种已有先进图像超分辨率重建方法在多个公开数据集上进行图像重建结果对比,评估其特性与性能。用于对比的几种方法有:1)Bicubic:像素插值方法[44];2)A+:调整锚定邻域回归法[40];3)SRCNN:简单的端到端全卷积图像超分辨率方法[7];4)VDSR:带有残差学习的深度全卷积图像超分辨率处理网络,全卷积网络图像超分辨率重建效果最好方法[9];5)REDNet:由卷积层-反卷积层构成的对称的编解码框架,对图像超分辨与去噪表现出优异效果[11]。
在表2中,显示了多种优秀SR 方法在多个公开数据集上进行测试结果。通过对比可发现,在这些数据集中,本文提出的方法明显优于其他传统SR 方法如A+等,且对比其他网络SR方法,在PSNR和SSIM上均有提高。
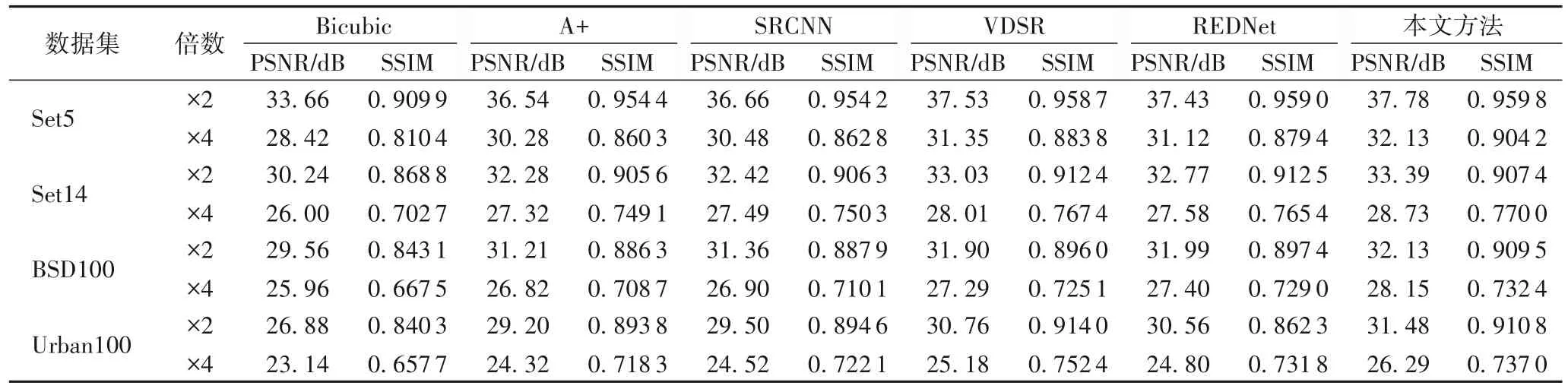
表2 各SR方法性能对比Tab.2 Performance comparison of different SR methods
图6(a)返回的是Set14 数据集第008 号图像使用了放大因子为4 的超分辨重建结果,观测到本文方法返回结果图在抗锯齿方面表现更好;图6(b)返回的是在BSD100 数据集第43 号图像使用了超分因子为2 的超分辨重建结果,观测到本文的方法在船顶部分细节恢复得更加锐利与清晰;图6(c)返回的是在Urban100 数据集第82 号图像使用了比例因子为4的超分辨重建结果。相比其他超分辨率方法,可以观测到本文的方法在人物腿部部分恢复得更清晰与连续。

图6 各SR方法重建结果对比Fig.6 Comparison of reconstruction results by different SR methods
通过对比发现,无论在客观数据还是在主观视觉效果对比上,本文所获取的重建图片效果明显优于其他先进SR 方法,因此,本文所提方法相较于其他SR 方法有明显性能优异之处。
4 结语
本文提出了一种带有去噪功能的混合深度卷积网络方法,用于图像超分辨率重建。首先,探索了卷积与反卷积构建的编解码结构对图像特征噪声的消解效果;接着,探讨了空洞卷积对卷积感受野的提升作用;然后,发现残差学习不仅能更快优化网络,而且能提升图像重建效果。在Set5、Set14、Urban100 以及BSD100 等公开数据集上进行图像重建对比,表明所提方法比现有的方法在基准图像上有更好的效果。
但是本文所提算法在取得优异结果的情况下,也存在着一些不足。由于反卷积结构的限制性,本文只能将低分辨率图像重建为偶数倍的超分辨率图像,而奇数放大倍率则表现不好,在之后的研究中,将通过优化上采样方式来解决这一问题。
