基于实例分割的车道线检测及自适应拟合算法
2020-08-06袁家政刘宏哲
田 锦,袁家政,刘宏哲
(1.北京市信息服务工程重点实验室(北京联合大学),北京 100101;2.北京开放大学智能教育研究院,北京 100081)
(*通信作者电子邮箱jzyuan@139.com)
0 引言
随着人工智能的飞速发展[1],传统汽车工业与信息技术的结合,使得智能驾驶技术的研究取得了很大的进步。智能驾驶技术是当今计算机视觉研究的主要焦点,无论是在学术层面还是在工业层面。计算机视觉[2]主要是利用计算机来模拟人类的视觉功能,即它提取、处理和理解图像信息,并将其用于检测、测量和控制。在汽车智能驾驶技术中,视觉传感器比超声波雷达和激光雷达能获得更精确、更丰富的信息。
自动驾驶[3]最具挑战性的任务之一是交通场景的理解,包括车道检测和语义分割等计算机视觉任务。车道检测有助于引导车辆,可用于驾驶辅助系统,而实例分割提供了关于车辆或行人等周围物体的更详细位置。基于摄像头的车道检测是实现这种环境理解的重要一步,因为它允许汽车在道路车道内正确定位。这对于任何后续的车道偏离或轨迹规划决策也是至关重要的。因此,进行准确的基于摄像头的车道检测是实现自动驾驶的关键。然而,在实际应用中,考虑到恶劣的天气条件、昏暗或眩光等许多严酷的场景,这些任务可能非常具有挑战性。
通常,传统的车道检测算法包括以下步骤:车道标记生成、车道标记分组、车道模型拟合和时间跟踪。提取正确的车道是成功生成车道标记的关键。许多传统的方法是利用边缘、颜色、强度和形状等信息来检测车道,这些算法必须根据算法手动解调算子,工作量大,鲁棒性差。当行驶环境发生明显变化时,车道线检测效果不佳。同时大多数方法对光照变化、天气条件和噪声敏感,当外部环境发生显著变化时,许多传统的车道检测系统都会失效。
卷积神经网络(Convolutional Neural Network,CNN)通常采用下采样的方法来实现更深层次的架构,扩大感知域来捕捉图像中的大尺度对象。然而,这种操作通常会减少详细的空间信息,这对于语义分割任务非常重要。为了解决这一问题,已经提出了几种网络体系结构。通常使用两种方法来恢复或保留详细信息。第一种方法使用编解码器体系结构。该编码器类似于许多分类网络,如VGG(Visual Geometry Group)[4]和残差网络(Residual Network,ResNet)[5]。解码器由连续的上采样操作组成,以重建与输入图像相同的分辨率。反卷积是一种可学习的上采样层,是对特征图进行上采样的最常用方法,如全卷积网络(Fully Convolutional Network,FCN)[6]。向上采样后,FCN 使用直接来自编码器的特征映射来恢复更多的细节。DeepLab 系列[7-8]使用扩展卷积来保持特征图的空间大小。基于卷积神经网络的SegNet[9]学习高阶特征,提高了算法的性能。它通过将训练算法应用于一个通用的图像数据集,对其他测试图像进行分类,生成训练标签。提出了一种基于颜色层融合的纹理描述方法,得到了道路区域的最大一致性。将离线和在线信息结合起来检测道路区域。之后,Seg_edge[10]在此研究的基础上结合了语义边界信息,提高了分割的精度。ENet[11]采用了类似ResNet 的一种方法,将其描述为拥有一个单独的主分支和扩展,这样可以以更快、更有效的方式执行大规模计算。
车道线检测是整个路面检测的重要组成部分[12]。在车道线检测问题中,利用神经网络学习车道线特征,提高了车道线特征提取的准确性,适用于复杂的道路环境。最流行的目标检测方法Faster R-CNN[13]和YOLO(You Only Look Once)[14]并不适用于车道检测,因为边界框检测更适合紧凑的对象,车道线则不然。悉尼大学使用了一个CNN[15]和递归神经网络(Recursive Neural Network,RNN)[16-18]来检测车道线,CNN 提供了用于检测车道线的几何信息的车道线结构。Kyungpook National University 将CNN 和RANSAC(RANdom Sample Consensus)算法相结合[19],即使在复杂的道路场景中也能稳定地检测到车道信息。百度map project team 提出了一种用于车道线检测的中立网络(Dual-View Convolutional Neutral Network,DVCNN)[20]。韩国机器人与计算机视觉实验室提出了一种提取多个感兴趣区域[21]的方法,融合可能属于同一类的区域,并使用主成分分析网络(Principal Component Analysis Network,PCANet)[22]和神经网络对候选区域进行分类。
深度学习提取的特征信息不能直接使用,需要对直线特征点进行聚类与拟合。在车道线聚类和拟合算法中,常用的拟合模型有线性抛物线、最小二乘曲线拟合、三次曲线和贝塞尔曲线拟合[23-25]。
在以上基础上,本文基于深度学习技术,提出了一种新的车道线检测及自适应拟合的方法。首先通过训练改进的Mask R-CNN[26]神经网络得到车道线特征;由于提取到的车道线特征只有离散的车道线的坐标信息,并不能直接使用,提出一种聚类算法对得到的离散车道线特征点信息进行聚类,这样不仅可以有效地排除不同车道线互相之间的干扰,还能进一步获取多车道线信息;最后为了实现车道线更精准、更全面的输出,提出一种自适应的车道线拟合方法,通过对驾驶区域进行划分,采用直线拟合算法和三次样条拟合算法分别对不同视野的区域内的车道线进行分段拟合,从而提高车道线拟合算法的精度,最终生成最优车道线拟合参数方程。
1 Mask R-CNN模型的改进和优化
本文采用的神经网络模型建立在Mask R-CNN 深度学习框架之上,因为它是一个小巧、灵活的实例分割框架,可以实现最好的结果。Mask R-CNN 模型整体结构如图1 所示。Mask R-CNN 在概念上很简单:Faster R-CNN 对每个候选对象有两个输出,一个类标签和包围框偏移量;在这个Mask RCNN 添加第三个分支,输出对象掩码,即输出分割,这是一个二进制掩码,表示对象在包围框中的像素位置。但是,额外的掩码输出与类和框输出不同,需要提取对象的更精细的空间布局。简而言之,可以把Mask R-CNN 理解成为是一个在Faster R-CNN 之上的扩展模型,在每个感兴趣区域(Region Of Interest,ROI)上加一个用于预测分割掩码的分层,称为掩码层,能够有效地检测图像中的目标,同时还能为每个实例生成一个高质量的分割掩码,就相当于多任务学习。同时,掩码层只会整个系统增加一小部分计算量,所以该方法运行起来非常高效,重要的是能够同时得到目标检测和实例分割的结果。
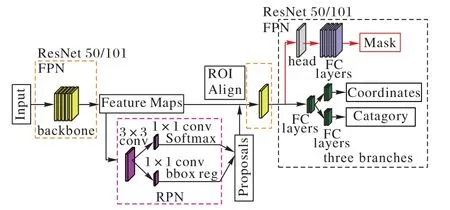
图1 Mask R-CNN整体结构Fig.1 Overall structure of Mask R-CNN
同时,Mask R-CNN 引入了ROI Align,如图2所示,其思想是简单地取消量化操作,使用双线性插值得到浮点数坐标像素上的图像值,将特征聚集过程转化为一个连续的操作,以得到更准确的检测结果输出。值得注意的是,ROI Align 并不只是补充候选区域边界上的坐标点,然后将它们集中起来。
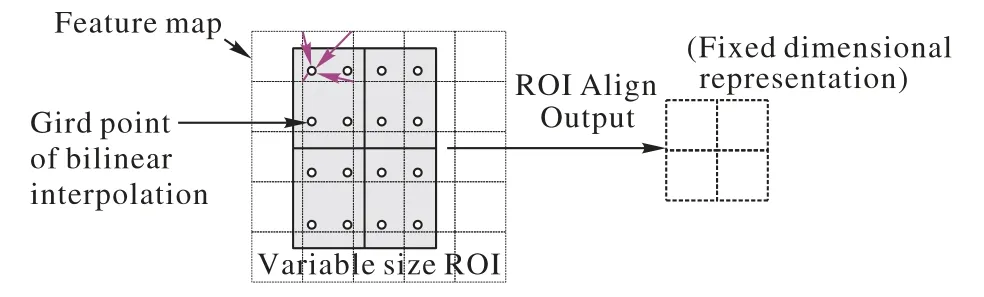
图2 Mask R-CNN所采用的ROI AlignFig.2 ROI Align used by Mask R-CNN
Mask R-CNN 主干网络可以采用ResNet50 或者ResNet101,也可以用FPN 替换前面的整体结构。本文采用ResNet101 作为Mask R-CNN 的骨干网络进行特征提取,ResNet中包括有多个由conv、bias、BN(Batch Norm)组成的运算块,考虑到在模型训练完成后只做前向运算的模型存在一些冗余的计算步骤。为了减少这些冗余的步骤,本文将每次bias 运算的βb(偏置),BN 运算的α(规模)、β(偏置)、μ(均值)和σ2(方差)五个参数合并简化成α'和β'两个参数,然后通过Y=α'X+β计算结果,减少运算块中所需的运算次数和运算参数,从而达到提高模型运行速度的目的。

2 车道线自适应拟合处理
2.1 聚类模型设计
虽然通过深度学习到了车道线特征,但提取到的车道线特征只有离散的车道线的坐标信息,并不能直接使用。因此本文提出一种将车道线的特征点聚类方法,这样不仅可以有效地排除多车道线互相之间的干扰,还能进一步获多车道线信息,为后续车道线的拟合提供更精准、更全面的输入。
F(x,y) 表示提取到的特征点坐标,特征段B(xs,ys,xe,ye,k,b,n)表示由一系列车道线坐标组成的车道线标记线段信息。其中:(xs,ys)和(xe,ye)表示一段车道线的起始坐标和结束坐标,k和b为聚类特征坐标的直线参数,n表示当前车道线线段的坐标数量。
通过深度学习提取到的车道线线段已经包含的特征坐标信息点可以表示当前车道线特征线段,于是本文采用最小二乘直线结合特征点来聚类特征直线,并根据特征点判断线段横向位置的连续性,具体采用的聚类方程如下:

其中B(k)表示为:
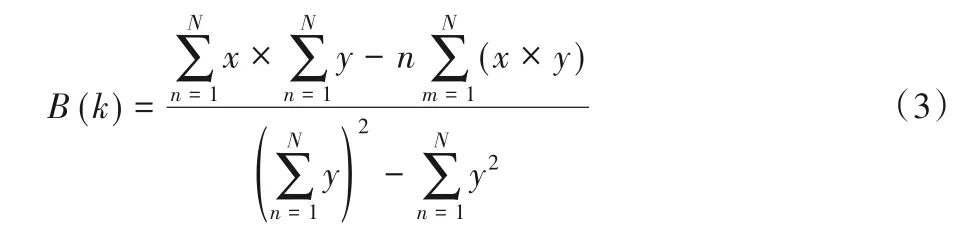
B(b) 表示为:
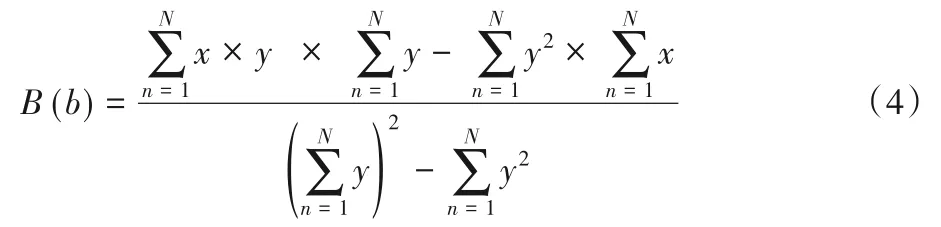
横向约束条件为:
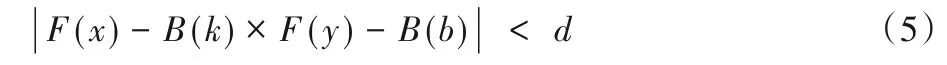
其中d为特征点的最大偏移距离。在图像的透视效果下,d随距离的增大而减小。
2.2 道路区域划分
在进行拟合算法设计之前,需要先对路面区域进行划分,假设智能驾驶车辆在数据采集过程中,车载摄机采集周期为10 ms,最高时速为200 km/h,通过计算,可以知道一个周期内大约前进10 m。原则上,摄像机能得到的车辆前方最多能获得100 m 标线的清晰图像,过于远处的车道线人眼也很难识别。通过摄像机采集得到的原始图像如图3 所示,本文将网络模型识别到的整体车道线的上边缘作为区域C,此区域以上是天空图像,不包含车道标识线信息;B 区是中视野区域,存在弧度较大的曲线,其中的车道信息反映了车道线的曲率,需要采用复杂的拟合模型进行拟合处理;A 区是近视野区域,也是视野的主要部分,其中的车道可以近似为直线,可以采用简单的拟合模型进行处理;这样根据整体路面信息划分之后,在设计拟合算法时,只需在划分好的路面区域内关注当前车辆前方图像的近视野和中视野区域内的车道线以及不同区域内的线性特点设计不同的拟合模型,以此提高拟合算法的准确性。
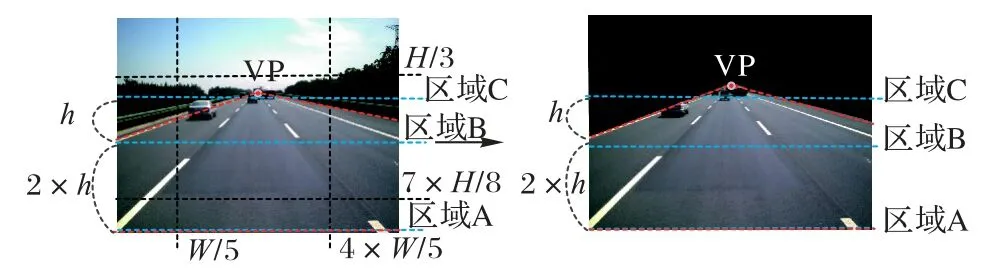
图3 驾驶区域划分Fig.3 Driving area division
2.3 拟合模型设计
2.3.1 直线拟合模型设计
近视野区域A 主要由直线组成,所以本文采用直线拟合模型进行处理。通常采用霍夫变换(Hough Transform,HT)和最小二乘法(Least Squares,LS)两种算法获取直线。霍夫变化是将直线检测问题转化为霍夫空间中的峰值问题;但霍夫变化算法本身有一些限制,当霍夫变化算法应用于含噪声特征时,如果分辨率太小,则粗分辨率中的单元的数量将被分配到在精细分辨率下的多个较小的离散参数单元。累加器无法获得足够的累积票数,导致检测失败。因此,在有噪声的影响的情况下,霍夫变化的检测精度有限。
最小二乘法作为常用的线性回归方法之一,则是从均方误差的意义上获得给定数据集的绝对精确的线;但最小二乘法对偏离回归线的异常值非常敏感。若数据集中含有强噪声时,整个数据集的分布标准偏差都会受到噪声点影响,这使得噪声点很容易被误认为是正常的数据点,因此这些异常值不能被消除。当这些数据点相对集中但包含一些强度相等并且在两侧分布的噪声点时,它将导致新的回归线在消除噪声后在相反的方向上更加偏向一边。因此,消除噪点在相反的方向变得越来越困难。
考虑到霍夫变换和最小二乘法各自的优缺点,本文结合这两种算法提出一种新的检测方法,整体流程如图4所示。
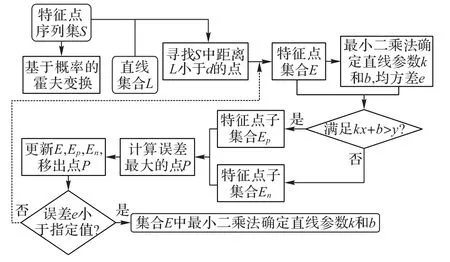
图4 直线拟合整体流程Fig.4 Flowchart of linear fitting
首先利用霍夫变换确定直线所在的大致区域,然后对每条直线区域内的已经经过聚类的特征点信息使用改进的最小二乘法确定直线参数,整体步骤如下:
1)对车道线离散特征点进行霍夫变换,获取直线信息;
2)特征点集S中寻找距离得到的直线不大于d的特征点,构成集合E;
3)集合E中利用最小二乘法确定直线参数k和b,以及均方误差e;
4)对集合E中的任一特征点(xi,yi)进行划分,满足kxi+b>yi的特征点构成子集Epos,满足kxi+b<yi的特征点构成Eneg;
5)在Epos和Eneg两个集合中,找出并移除误差最大的点,然后更新集合Epos和Eneg,重复第3)步,直到误差e<ε。
2.3.2 曲线拟合模型设计
对于车道线曲率不大的区域,直线拟合模型获得的车道线信息基本可以满足车道线检测的需求,但并不能适应曲率较大的车道线环境。本文将直线拟合模型只用于区域A中的车道线拟合,对于线性特点更加复杂的区域B 采用曲线模型设计。考虑到常用的抛物线曲线拟合模型在直线和弯道的连接处不具有自适应能力,本文在此之上采用一种线性的三阶方程拟合模型,具体公式如下:
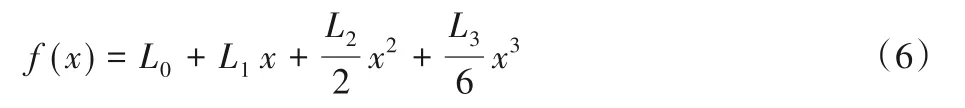
图5 显示了具有两条车道的曲线拟合的示意图,本文用式(6)中的三次多项式f(x)对聚类后的点进行拟合处理。在拟合过程中,每条车道线都是独立的三次样条模型。其中,L0,L1,L2,L3是曲线模型的参数信息,L0代表航向和偏航角,L1代表斜率,L2代表曲率,L3则代表曲率的变化率。
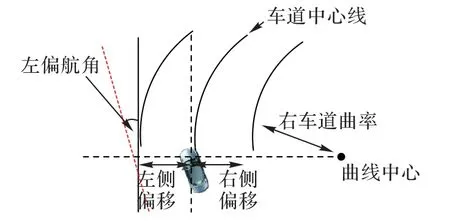
图5 曲线拟合示意图Fig.5 Schematic diagram of curve fitting
3 实验结果及分析
3.1 Mask R-CNN模型实验结果
在分割中通常使用交并比(Intersection Over Union,IOU)作为对分割精准度的一个标准测量标准。本文引入IOU 作为判别依据,将车道线的判断准则定义如下:给定一条检测到的车道线及其对应的标注真值,将其栅格化为点集。定义车道线标注真值点集到检测车道线点集的距离小于20 cm 的点个数为该标注车道线到检测车道线的匹配点数。因此,输入的离散点在真值区域内被视为正检点,正检点的总长度为TP;输入的离散点在真值区域内被视为错检点,错检点的总长度为FP;所有标注真值的点集总和与TP的差为漏检值漏检长度FN,则最后得到的精度IOU表示为:

本文在CityScapes 数据集上验证模型速度和精准度,CityScapes数据集是奔驰公司发布的一个大规模数据集,其中包含了50 个城市不同情况下的街景,以及30 类物体标注,共有超过5 000张的精细标注图像,是目前公认的自动驾驶领域内最具权威性和专业性的图像语义分割评测集之一。本文在显卡为GTX1080ti 的硬件设备下训练改进后的神经网络模型,并最后给出了和Mask R-CNN在该数据集上的检测精度和处理速度,表1 为与原始模型的处理速度(Frame Per Second,PFS)对比,表2为与其他模型的精度对比。
表1 显示了本文改进后的Mask R-CNN 模型与原始的Mask R-CNN 模型处理速度之间的对比。从表1中可以看出,本文改进后的模型与原始的模型相比,处理速度得到了较大提高。

表1 模型处理速度对比Tab.1 Comparison of model processing speed
本文在Cityscapes 数据集上将本文的模型和其他现有的模型进行了精度实验对比,表2列出了对比实验结果。从表2中可以看出,本文的模型分割精度具有较高的检测精度,高于之前的分割模型,具有较好的鲁棒性。

表2 Cityscapes数据集上模型精度对比Tab.2 Comparison of model accuracy on Cityscapes dataset
图6 显示了在不同场景下本文模型的训练结果,其中第一行为检测的车道线信息,第二、三行为有整体路面信息约束下的车道线信息。从图6中可以看出,本文提出的模型可以准确地识别不同驾驶场景下的车道线信息,同时也能很好地适应不同的驾驶环境,在路面遮挡、曝光强等不同复杂环境干扰下依然能准确地检测出当前路面环境下的车道线特征。实验结果证明,本文方法具有较高的检测精度,能够适应不同的复杂真实环境,但在车道线边缘仍存在一些噪点。噪点的出现和模型训练样本数量不够多、模型迭代次数较少有很大的关系,将采用更多的标注数据对模型训练、迭代,进一步提高模型的分割精度。

图6 Mask R-CNN训练结果Fig.6 Training results of Mask R-CNN
3.2 车道线自适应拟合实验结果
为了验证车道线拟合算法的鲁棒性,本文在多个数据集上进行了当前车道线检测和多车道线检测。其中包括国家自然科学基金委和西安交通大学发布的TSD 数据集,TSD 为第十届中国自主驾驶未来挑战赛(2018)视觉信息环境基本认知能力离线测试提供的测试数据集,TSD 数据集全部采集自中国的真实驾驶化境下的道路场景,其中包括阴影、遮挡、磨损和曝光过强等复杂的路面环境。表3 给出了在TSD 数据集下本文的自适应分段拟合算法和其他拟合算法拟合精度之间的对比。实验表明,本文的拟合算法平均精度为97.05%,均高于样条曲线和贝塞尔曲线的拟合精度,具有较好的鲁棒性。

表3 TSD数据集上不同拟合模型的结果 单位:%Tab.3 Results of different fitting models on TSD dataset unit:%
图7 显示了部分复杂场景下对车道线的拟合结果。从图7中可以看出,直线模型或曲线模型只能单一解决不同的场景特点,当场景明显发生变化时,精度较差,无法很好地适应不同场景下车道线弯道、远处端点变换率大的线性特点。本文提出的自适应分段拟合方法很好地解决了这个问题,本文采用拟合算法更符合真实的车道线特点,在车道线线段的近点、结合处和远端拟合精度高,从图中可以看出,本文的方法在弯曲角度较大、受到遮挡等干扰的复杂场景下依然具有较好的拟合效果,很好地适应了不同真实驾驶环境下车道线的线性特点,生成的拟合方程更加精准。

图7 多车道场景下拟合结果Fig.7 Fitting results in multi-lane scene
4 结语
本文提出了一种基于实例分割方法的复杂场景下车道线检测方法。该方法将深度学习与传统算法相结合。首先利用改进后深度学习网络模型提高特征点提取的精度和处理速度;然后在不同视野内利用分段拟合算法对提取的特征信息进行拟合;最后实现在各种复杂环境下车道线信息的鲁棒提取。结果表明,本文改进的深度学习网络模型能够更好地适应各种类型的道路场景,在直线、弯道、背光场景及车辆遮挡场景下,该算法具有较好的检测精度,鲁棒性强,并具有更高的检测速度。为了使其更具有市场实用性,进一步提高处理速度和检测精度是下一步工作的研究重点。
