基于深度时空Q网络的定向导航自动驾驶运动规划
2020-08-06胡学敏陈国文张若晗童秀迟
胡学敏,成 煜,陈国文,张若晗,童秀迟
(湖北大学计算机与信息工程学院,武汉 430062)
(*通信作者电子邮箱huxuemin2012@hubu.edu.cn)
0 引言
自动驾驶技术可以有效降低司机的行车劳累程度,提高交通系统的运作效率和安全性。自动驾驶中的运动规划是在已获取车辆状态、环境、交通规则等数据的条件下,为车辆从当前状态到下一目的状态做出合理的驾驶动作,是自动驾驶最核心的技术之一。因此,研究自动驾驶的运动规划,对提高自动驾驶的智能性和可靠性有重要意义。
目前应用较为广泛的传统运动规划算法主要有快速搜索随机树算法[1]、启发式搜索算法[2]、人工势场法[3]和基于离散优化算法[4]。此类传统的路径规划算法在自动驾驶中取得了较好的应用效果,但是在实现过程中需要根据已知环境和规则来建立相应的数学模型,因此在这些规则之中可以获得较好的效果,却难以适应新的环境。
近年来,随着机器学习技术的发展,采用基于机器学习的方法来解决复杂的运动规划问题成为了研究热点。这类方法主要分为基于模仿学习[5]的方法和基于强化学习[6]的方法。前者主要通过深度神经网络获取所需图像或其他环境感知信息,实现感知数据到运动指令的函数映射。其中,在训练深度神经网络时,需要大量带标注的样本来对模型进行监督学习,从而有效地拟合从感知数据到运动指令的端到端的规划函数。美国伍斯特理工学院提出了一种自动驾驶汽车的端到端学习方法,能够直接从前视摄像机拍摄的图像帧中产生适当的方向盘转角[7]。Waymo 公司设计的递归神经网络ChauffeurNet,通过专业驾驶数据学习自动驾驶策略,可以处理模拟中的复杂情况[8],这类基于模仿学习的方法具有较强的运动规划和道路识别能力,但是需要大量多样化、带标注的样本数据,并且由于样本的限制其泛化能力有限。
强化学习是智能体通过从环境中感知状态,在可选的动作中选择一个最大回报的动作并执行,来到达下一个状态的学习策略。智能体在不断地探索学习中学会如何在当前环境中获得最大回报,由此来寻找最优策略。强化学习方法有较强的决策能力,且不需要大量带标注的样本,但是传统的强化学习缺乏环境感知能力,难以得到准确清晰的环境特征。将深度学习和强化学习结合起来得到的深度强化学习,既有较强的特征提取能力,也有较高的决策能力。其代表模型深度Q 网络(Deep Q-Network,DQN)[9]和深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)[10]可以通过提取图像或是视频的特征来进行实时决策,并在诸多领域已经超越了人类的表现[11]。然而,目前原始的深度强化学习算法DQN 和DDPG 仅仅利用卷积神经网络(Convolutional Neural Network,CNN)[12]提取图像的空间信息,没有关联时间信息,从而导致在学习过程中容易忘记之前所学习的信息,在长期信息学习中效果不好。此外,NVIDIA 公司研究的自动驾驶运动规划算法[13]和其他基于深度强化学习的自动驾驶算法[7]都只达到了避障、循迹和单一的转弯目的,没有利用全局路径信息,导致在定向导航的自动驾驶场景中表现不佳。
针对目前基于深度强化学习的自动驾驶运动规划方法没有关联时间信息、没有利用全局路径信息且无法实现定向导航的问题,本文提出了一种将深度强化学习和长短期记忆(Long Short-Term Memory,LSTM)网络[14]相结合的深度时空Q网络(Deep Spatio-Temporal Q-Network,DSTQN)。该模型通过由CNN 和LSTM 构成的深度时空神经网络提取车载相机获取的连续帧图像的空间和时间信息,并输入Q 网络中选择合适的驾驶指令。此外,为有效利用全局路径信息,在网络输入的环境信息中加入指向信息,将全局路径信息以可视化图形的方式融入到驾驶场景图像中,实现在全局路径下定向导航的自动驾驶运动规划。本文提出的方法既解决了自动驾驶模型训练需要大量带标注样本,以及强化学习在长期信息学习方面存在的难题,同时也使自动驾驶车辆能够利用全局路径信息实现定向导航,为强化学习算法在运动规划领域的应用提供了新的思路。
1 基于深度时空Q网络定向导航运动规划算法
本文设计的基于深度时空Q网络的定向导航运动规划算法在原始的DQN 算法中融入LSTM,采用CNN 和LSTM 提取空间与时间信息,将时空信息输入Q网络得到转向与加速(包含油门与刹车)的决策动作,然后反作用于环境。为实现定向导航,将环境信息送入神经网络前对其添加指向信息来实现车辆的定向导航。算法结构如图1所示。
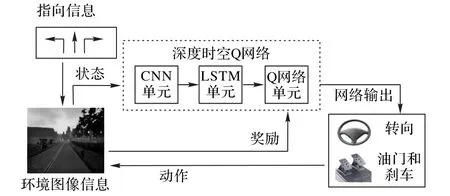
图1 定向导航深度时空Q网络算法结构Fig.1 Structure of deep spatio-temporal Q-network with directional navigation
1.1 DQN算法
深度Q 网络是深度强化学习的一种经典算法,它将深度学习中的卷积神经网络和强化学习中的Q 学习(Q-Learning)[15]结合起来,利用CNN 估计值函数。其中,将环境图像数据作为状态输入CNN中,输出从状态中提取的环境特征,然后建立强化学习模型,其核心是三元组:状态、动作、奖励。智能体通过获取的当前环境状态来选取一个动作,并观察得到的奖励和下一个状态,再由得到的信息不断更新网络,从而使智能体学会选择更优的动作,获取更大的奖励。
在DQN 实现中,通过将从环境中获取的信息输入到主训练Q 网络,经过Q 函数的计算,获得一系列动作a与Q值相对应的序列,让智能体选取Q值最大的动作,由这个动作来产生新的状态环境并获得奖励[9];并且在训练的同时,将智能体与环境交互所获得的数据存放到回放经验池中,然后在后续训练中随机抽取数量固定的数据样本送入网络中训练,通过计算损失函数,使用梯度下降方法反向传播来更新Q 网络的权重参数θ,重复训练,直至损失函数收敛,寻找到最优策略。损失函数如式(1)所示:
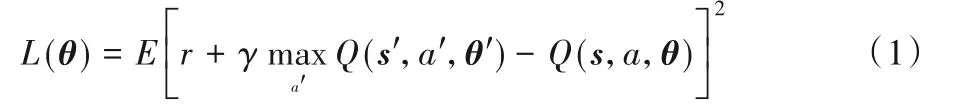
计算Q值如式(2)所示:
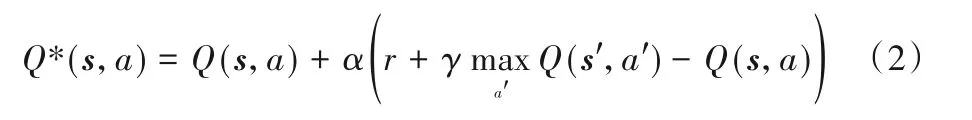
其中:s为智能体所处的当前状态,s'为智能体完成动作后的下一个状态;a为当前做出的动作,a'为下一个选择的动作;r为当前做出动作所获得的奖励;θ为主网络权值参数,θ'为目标网络权值参数;γ为折扣因子。
1.2 深度时空Q网络
由于DQN 只利用CNN 提取图像空间特征,而没有考虑时间关联性,而在自动驾驶的场景图像中,既包含了静态的当前帧图像的空间信息,又包含了动态的前后帧图像的时间信息,因此如果直接采用原始的DQN 会导致时间特征的丢失,降低运动规划指令预测的准确性。由于LSTM 能够处理较长的时间序列,因此本文采用LSTM作为深度时空Q网络的时间特征提取层,提取自动驾驶场景序列图像的前后帧图像的长期时间信息,解决强化学习在长期学习中存在的问题。本文设计的DSTQN特征提取模型由CNN与LSTM两部分组成。
为兼顾提取驾驶场景图像特征和网络的轻量化问题,本文以文献[16]的网络为原型,设计本文的CNN结构,如图2所示。该网络一共有4 层,输入图像是将从车载相机中获取的连续4 帧图像,加入定向导航的指向信息处理后,将每帧图像转化成84×84 的8 位单通道彩色图像,并堆叠起来构成一组84×84×4的图像信息。接下来是3个卷积层,卷积核大小依次为8×8、4×4 和3×3,卷积核的数量分别为32、64 和64。第4 层为全连接层,输出4×1×512的节点映射集合。
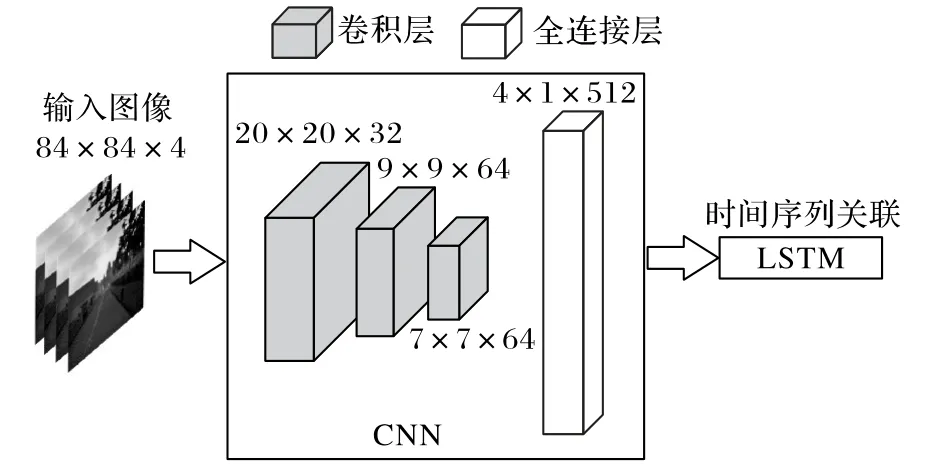
图2 CNN结构Fig.2 CNN structure
本文采用的LSTM 结构源于文献[14],如图3(a)所示,LSTM 神经元通过三个门来控制细胞状态:遗忘门、输入门和输出门。遗忘门以上一层神经元的输出ht-1和本层输入的数据xt为输入,通过Sigmoid 层处理得到ft,表示上一层细胞状态Ct-1被遗忘的概率;输入门第一部分是ht-1和xt通过Sigmoid 层(如图3(a)中σ 所示)处理后输出it,第二部分使用tanh 激活函数(如图3(a)中tanh 所示),输出为C't,it×C't表示多少新信息被保留;将旧细胞状态Ct-1×ft加上it×C't,得到新的细胞状态Ct;第三阶段即输出门,首先将ht-1和xt输入Sigmoid 层,处理得到[0,1]区间的ot,然后将新的细胞状态Ct通过tanh函数处理后与ot相乘得到当前神经元的输出ht。
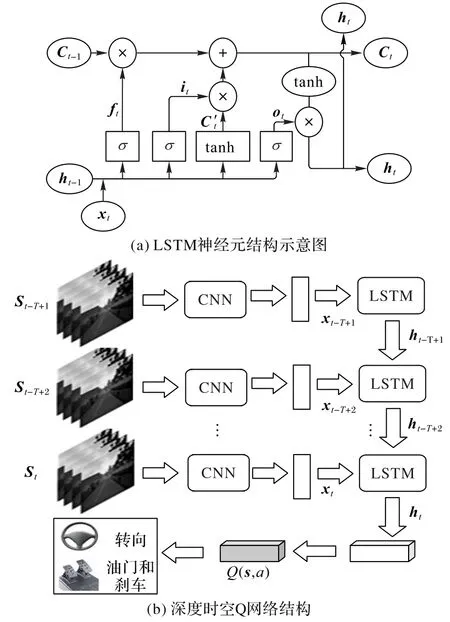
图3 LSTM结构和深度时空Q网络结构Fig.3 Structures of LSTM and deep spatio-temporal Q-network
虽然通过CNN 输入前后4 帧的图像来关联短期时间序列,但是难以通过这种方式提取长期的时间信息,因此本文在利用CNN 提取自动驾驶图像的空间特征之后,把空间特征信息通过LSTM 层进行时间处理,提取前后帧之间的时间信息,其过程如图3(b)所示。对于CNN 提取的特征向量xt,然后将这个特征向量输入到LSTM 网络中,ht和ht-1即为当前LSTM单元和上一个单元的输出。每个LSTM 单元输出之后再通过1 个512 节点的全连接层后经过Q 网络输出Q值。本文设置的LSTM 网络以T(本文中T=10,为经验值)帧展开来进行训练。与原始的DQN 相比,加入了LSTM 网络的DSTQN 可以处理较长的输入序列,并拥有寻找时间上的依赖关系的能力,实现驾驶场景图像前后帧之间的信息关联。
本文利用CNN 和LSTM 构成的深度时空神经网络,提取连续帧图像的空间和时间信息,并将时空信息输入Q 网络输出合适的驾驶指令,实现在自动驾驶中的运动规划。
1.3 定向导航运动规划算法
传统的基于深度强化学习的自动驾驶运动规划算法,是汽车作为智能体通过选择运动规划的动作指令,在不断的“试错”中学习车道保持、避障等行为策略。然而,目前的算法均面向单一路径,只适用于避障和循迹的场景,没有考虑“T”形路口或“L”形路口等道路岔口,不能沿着指定路线进行运动规划。而人类驾驶员在驾驶汽车时预先知道自己的目的地以及全局路径路线,或者在行车导航上会清晰地标明行车路线,并在弯道处提醒驾驶员做出正确方向的转弯操作。其中一种方法就是利用抬头显示(Head Up Display,HUD)设备,将全局导航信息投影在汽车挡风玻璃上,随前方驾驶场景一同作为驾驶员的观测画面。受到HUD 的启发,本文提出一种利用指向信息进行定向导航的方法,将全局路线的信息融入到深度强化学习中,实现自动驾驶车辆按照既定路线的定向导航运动规划。
本文提出的定向导航自动驾驶运动规划方法基于预先获取车辆的全局行驶路线,在车载相机获取环境图像后,根据获取的路线信息,在当前帧图像中添加指向信号,如图4所示。
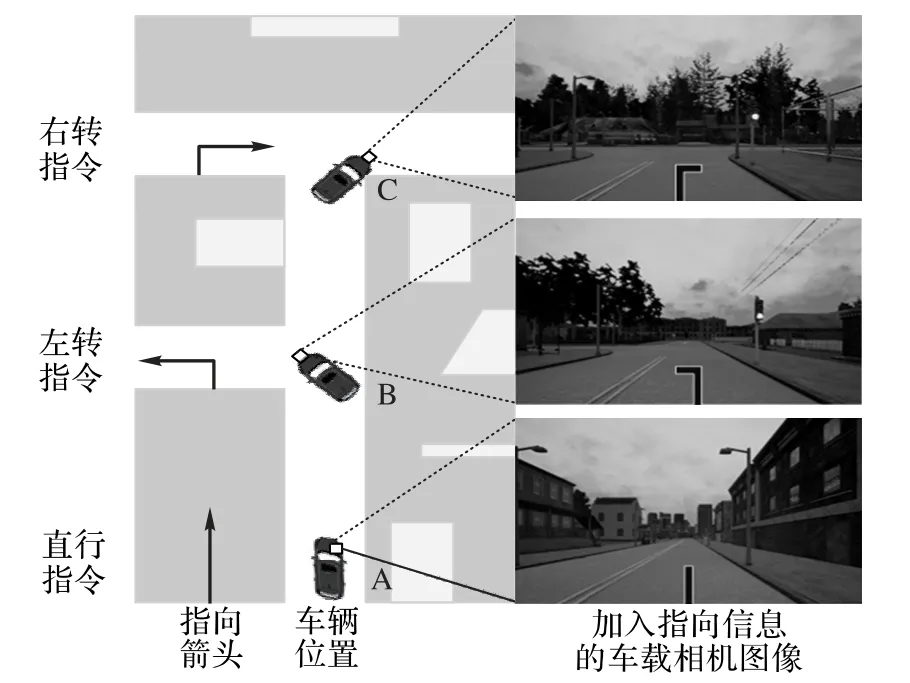
图4 定向导航指向信息示意图Fig.4 Guide information schematic diagram for directional navigation
具体做法是:当需要直线行驶时,在图像的道路上加入一个直行的箭头作为定向导航信息来指引车辆直行;在路口处对当前图像加入一个转弯的箭头作为定向导航信息来指引汽车进行左转或右转操作。需要注意的是,指向信息是人为在全局路线中预先设定的,在路口处加入左转或右转箭头,其他位置则加入直行箭头。由于CNN 能够提取自动驾驶图像中的特征,包括车道线、道路边缘、其他障碍物等,而在基于学习的自动驾驶运动规划模型中,输入图像是环境信息的主要来源,因此将指向箭头融入输入图像,能够利用CNN 提取全局路径信息,实现定向导航。
本文设计的算法是通过将自动驾驶模拟环境中得到的图像处理后作为状态s输入到深度时空神经网络中,得到一系列的状态序列,从而通过Q 网络选择一个动作a,车辆由此动作进行自动驾驶,并获得下一状态s',不断循环。因此,深度时空Q网络中三元组:状态空间、动作空间和奖励函数的设计在模型学习中起到至关重要的作用。
1.3.1 状态空间S的设计
状态空间S是获取的状态s的集合,它反映汽车当前所处的环境。网络通过对状态感知来获取信息,进而对汽车发出相应的指令。本文所采用的汽车仿真模拟平台是英特尔公司研发的Carla[17],通过在模拟器内部设置前向RGB摄像头获取驾驶路径的实时彩色图像。由于原始图像尺寸过大,且均为三通道的图像,需要大量存储内存以及运算资源,并且增加网络训练难度和训练时间,因此本文对采集到的图像进行处理,将其转换为“P”模式的单通道彩色图像,并将尺寸处理成84×84。此外,本文将当前时刻t的最近前n帧(本文中n=3)作为前后帧信息,经过同样的处理后与当前帧叠加为4通道的84×84图像,作为状态输入到CNN中。因此,本文的状态空间S如式(3)所示:

其中:t表示当前时刻,st为当前帧的状态。
1.3.2 动作空间A的设计
动作空间A是车辆根据当前所获得的状态环境可能做出的动作集合,Q 网络从此集合中选取一个动作指令,将指令传递给车辆执行,从而进入下一个状态。汽车行驶动作的加速度与转向角度都是连续且时刻变化的。基于这种情况,本文选择转向和加速作为二维矢量来控制车辆,即:A=(ste,acc)其中,转向ste为0 表示直行,正、负值分别表示向右和向左转动方向,且归一化到-1~1;加速acc包含油门和刹车,分别用正、负值表示油门和刹车,同样归一化到-1~1。由于Q 网络每次只能选取一个离散的动作,故本文将转向和加速离散化。考虑到车辆在行驶过程中,左右转弯的可能性均等,而向前加速比减速更多,因此在转向上设置左右对称的离散值,而在加速上选取非对称值。此外,还考虑到转弯的时候加速度不宜过大的情况。
综合以上因素,本文选取的ste∈{-0.6,-0.2,0,0.2,0.6}五个级别,acc∈{-0.5,0,0.5,0.9}四个级别,并且将这二者组合成7个动作空间,如式(4)所示:

其中:a1=(0,0),a2=(0,-0.5),a3=(0,0.9),a4=(-0.2,0.5),a5=(-0.6,0.5),a6=(0.2,0.5),a7=(0.6,0.5),分别表示静止、直行减速、直行加速、加速同时小幅度左转、加速同时大幅度左转、加速同时小幅度右转、加速同时大幅度右转7个动作。
1.3.3 奖励函数R的设计
奖励是当前状态下衡量智能体所做动作的好坏,以及对后续影响的优劣程度,在本文中起引导车辆学习驾驶的作用。本文将全局路线设计成由数个离散点组成的基准路线。如图5 所示,基准线用白色虚线表示,Qj-1、Qj、Qj+1表示离散的子目标点。车辆在沿全局路线行驶的过程是不断达到子目标点的过程,即到达一个子目标点后就朝下一个子目标点行驶。要使汽车学会在既定航线上行驶,需要同时关注横向奖励和纵向奖励。横向奖励使车辆能够学会如何行驶在车道范围内而不超过车道中线和车道边线;纵向奖励使车辆能够学会不断靠近子目标点从而实现不断前行。车辆按照指定路线行驶时奖励为正,且车头指向与道路方向夹角越小、车辆越靠近道路中线,获得的奖励越高;反之,当超过车道中线和车道外侧,或者车头偏离道路方向时,获得的奖励应该为负分。
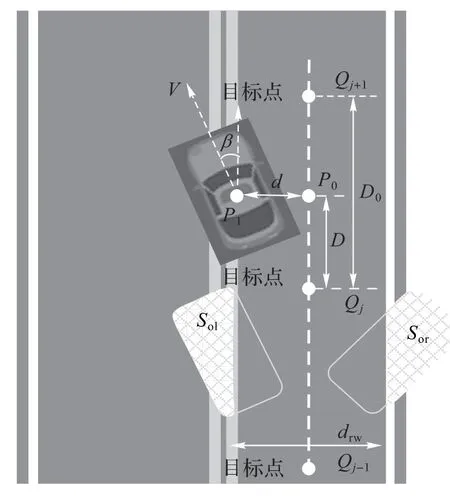
图5 奖励函数中各参数示意图Fig.5 Parameters in reward function
根据强化学习奖励函数设计的经验和对自动路径规划问题的理解,设计出奖励函数如式(5)所示:
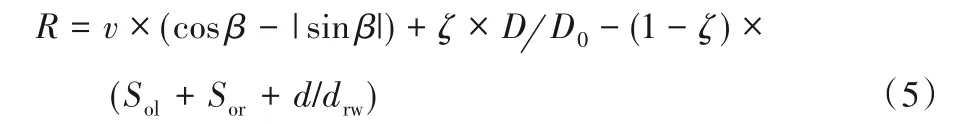
其中:v为车辆当前行驶速度;β为车头偏离基准线的角度;D为汽车中心点距离上一个目标点的路径在基准线上的投影长度;D0为当前位置对应附近两目标点距离;d为车辆中心点偏移基准线的垂直距离;Sol为车辆超出对向车道线的面积比值;Sor为车辆超出道路边线的面积比值;drw为车道宽度(此处是4);ζ为权重,代表横向与纵向规划的奖励所占比重大小,本文经过多次实验,且为了奖励汽车向前行驶,将ζ设置为0.6。P1为汽车中心点,P0为汽车中心点在基准线上的投影点。
1.4 网络参数设置与模型训练
在深度强化学习算法中,网络参数对训练的结果有较大的影响,因此参数的设置与调整十分重要。本文针对DSTQN模型所设置的参数如表1 所示。其中:折扣因子表示随着训练的不断进行,时间远近对当前训练获得奖励的影响程度;初始学习率是指在开始训练更新策略时更新网络权值的程度大小;训练批次大小指在训练神经网络时每一次送入模型的样本数量;记忆池是用来存储已训练的样本数据的;探索次数是指在探索一定次数后模型开始训练;初始和终止探索因子表示在训练不同阶段探索时选取动作的概率大小。本文采取贪心算法[18]来决定动作的选取,采用一个初始探索因子ε来决定汽车选取动作是随机探索还是根据Q值概率,然后根据训练次数的加大,ε逐渐减小,直到等于终止探索因子ε'时维持不变。根据贪心算法,本文选择最大Q值对应的动作,则能获取趋于最优的自动驾驶运动规划结果。

表1 DSTQN算法中的参数设置Tab.1 Parameter setting of DSTQN algorithm
2 实验与结果分析
考虑到真实汽车驾驶环境复杂度和安全性问题,本文选取模拟驾驶平台Carla 进行实验。Carla 是英特尔实验室AleyeyDosovitskiy 和巴塞罗那计算机视觉中心共同开发的开源驾驶模拟器,其逼真的模拟场景、大范围的地图、多路况和天气以及各类汽车信息传感器的模拟,很适合作为自动驾驶的模拟器。通过Carla 模拟器官方提供的应用程序编程接口可以获取车辆的实时速度、加速度、朝向、碰撞数据、在环境中的GPS坐标等数据,以及交通规则评估数据,如汽车超出当前车道的面积比值等信息;还可以自主添加相机、激光雷达和传感器来获得驾驶图像、障碍物信息和其他信息。本文选取的汽车模拟环境是一个小镇,道路为双车道,车道宽度为4 m,拥有直行以及“L”形路口和“T”形路口,选用的车辆宽度为2 m。
本文实验的软件环境为Ubuntu16.04,深度神经网络框架采 用Keras,硬件环境CPU 为Core I7-7700K(Quad-core 4.2 GHz),GPU为NVIDIA GTX 1080Ti,内存为32 GB。
2.1 模型学习性能测试
由于本文的目的是训练自动驾驶的定向导航,因此在模拟器中未加入交通信号灯、行人和车辆等障碍物。为验证模型在直行、左右转弯中的表现,本文选取Carla 模拟器中两条不同的复杂路径,如图6中R1 和R2 所示,起点用圆形表示,终点用正方形表示,这两条路线既包含了较长的直线行驶,也包含了“L”形和“T”形路口所需的左转弯和右转弯,其中转弯个数、直道数目和路径长度如表2 所示。汽车每一轮训练会随机选取一个起始点,遇到终止条件结束并开始下一轮训练。其中,终止条件包括汽车到达该路径终点,或者行驶到对向车道、行驶出机动车道路、车头指向与道路方向垂直、在路口走错方向。
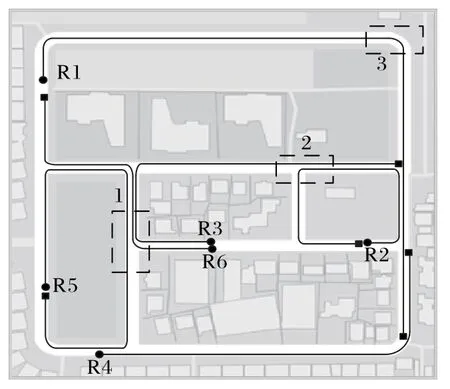
图6 训练和测试全局路径Fig.6 Global routes for training and testing
在强化学习算法中,每一步迭代汽车获得的奖励是评判汽车强化学习效果的重要标准之一,同时测试自动驾驶模型时汽车每轮次所行驶的距离也是一个重要指标,所以本文使用汽车的单次迭代奖励和每轮次汽车行驶的距离作为学习效果的表现形式。
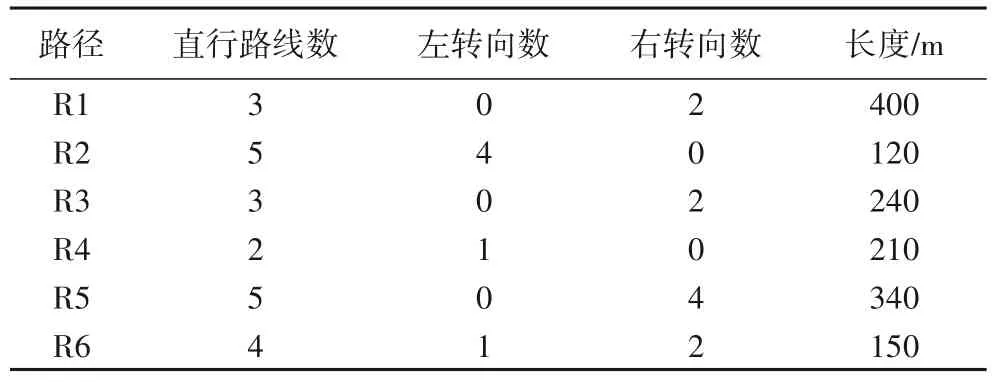
表2 训练和测试路径的数据信息Tab.2 Data information of training and testing routes
为了体现本文方法的学习性能,采用原始的DQN[9]进行同样的训练来与本文提出的DSTQN(ζ=0.6)进行对比。图7(a)表示模型学习过程中每一次迭代的奖励,图7(b)和(c)表示车辆在R1 和R2中训练时每轮行驶的距离。由于迭代次数较多,因此图7中的曲线都是进行了平滑处理的结果。可以看出在训练初期奖励很小且行驶距离很短,两种方法相差不大,这个时候汽车处于观察阶段;而在训练中后期,加入定向导航方法的奖励快速升高并达到了奖励值5,且在R1 和R2中的行驶距离分别达到400 m 和120 m,即能够完成所有转弯和直行的动作并到达2 条训练路径的终点。而未加入定向导航的原始DQN 方法学习速度要落后许多,奖励值最高才到达3,且在R1 和R2中的行驶距离最远分别才达到200 m 和70 m,分别在图(6)中标号为3 和2 的矩形虚线框路口很难完成转弯的动作,没有按照既定的全局路线行驶。由此可以看出加入定向导航信息的DSTQN 比原始的DQN 学习速度快很多,能够大幅度缩短训练时间,并且最终获得奖励更高,行驶距离更远,效果更好。
为了验证奖励函数中关于超参数ζ的设置,本文分别选取了ζ的几个典型取值0.1,0.5、0.6 和0.9 来构造奖励函数,并进行相同的训练。由于选取不同的ζ时奖励函数发生改变,每步获得奖励无法作为不同奖励函数下汽车训练效果的评价指标,因此选择每轮行驶距离作为评价指标。对比实验结果如图7(b)和图7(c)所示,可以看出在训练了约1 200 轮之后,当ζ=0.6时,基于DSTQN 的方法在两条路径中行驶距离均最大,在路径R1和R2分别达到了400 m和120 m;ζ=0.5时在两条路径上行驶距离分别最大为380 m 和110 m;ζ=0.9时最大行驶距离仅仅为300 m 和90 m;ζ=0.1时最大行驶距离分别为220 m 和90 m。可见ζ=0.6时算法学习性能最佳,在训练相同轮数后行驶的距离最远。
2.2 驾驶稳定性能测试
驾驶稳定性也是自动驾驶的一个重要指标。本文选取4条路经进行测试,如图6中R3、R4、R5、R6 所示。这4 条测试路径几乎不与训练路径重复,但是又涵盖了整个地图场景,且同样包含了直线路段、“L”形和“T”形路口等,每条路中转弯个数、直道数目和路径长度如表2所示。
在测试过程中,本文选取了原始DQN[9]、异步优势演员-评论家(Asynchronous Advantage Actor-Critic,A3C)算法[19]、DDPG[11]和模仿学习的方法[17]进行对比测试。其中,DQN 和DSTQN 是本文训练了120 万步的模型,而A3C 方法则采用的是Intel公司在Carla中训练了1 000万步的模型,DDPG算法是本文训练了100 万步的模型,模仿学习算法是Carla 官方训练的模型。为衡量驾驶稳定性,本文采用测试路径整个过程的平均偏差dave作为评判标准,计算如下:

其中:di为车辆在完成当前测试路径的第i个状态时,从汽车的中心点到车道中心的垂直距离(如图5中的参数d所示);Ntest为测试当前路径时总的迭代次数。
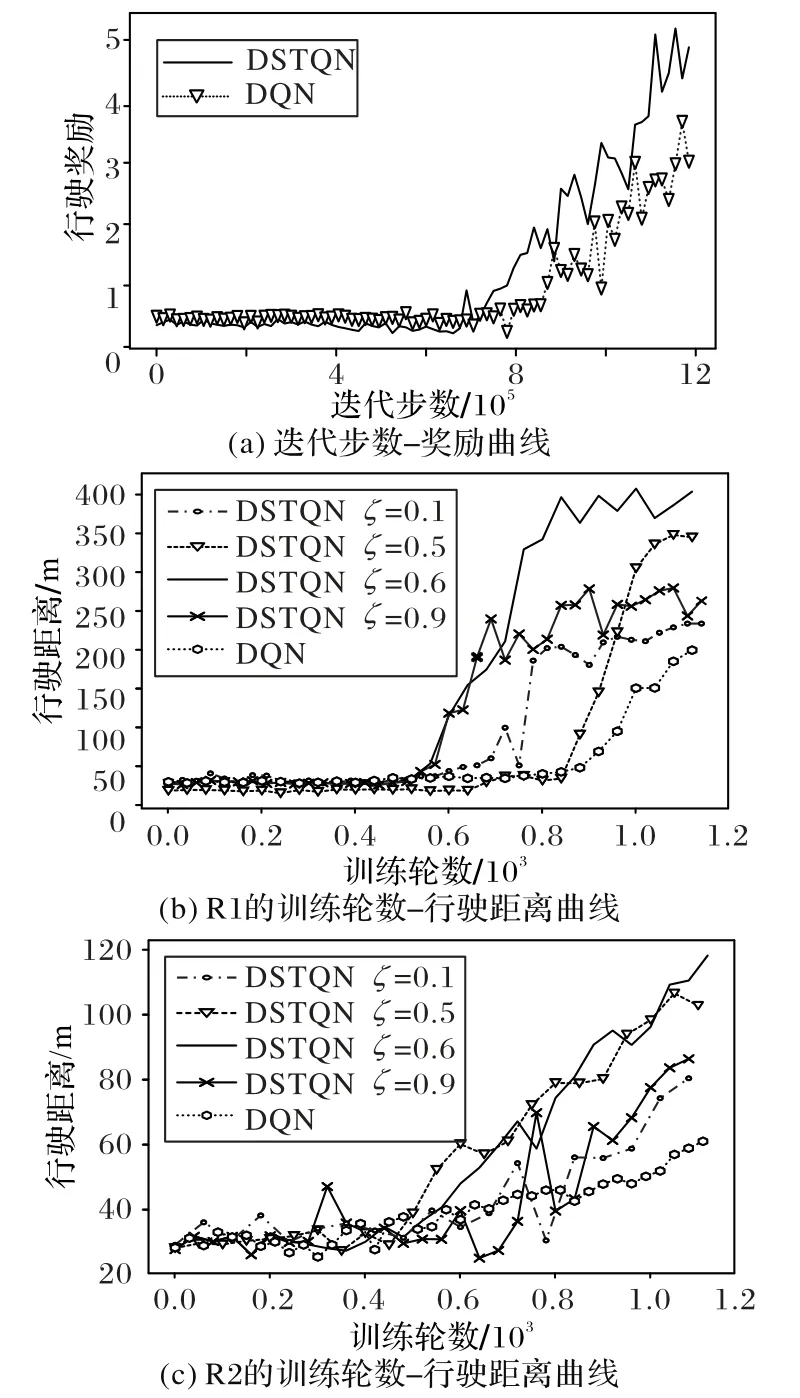
图7 训练的奖励曲线与行驶距离曲线Fig.7 Reward and driving distance curves of training
表3 是不同方法在4 条测试路线的平均偏差。由表3 可以看出,DQN方法均未完成测试路线的巡航,A3C方法只完成了R3和R4,DDPG 只完成了R3和R4,模仿学习没有完成R5,而DSTQN 方法由于采用了定向导航的方法则能全部完成。在完成的路径中,除了R4路径中A3C方法的平均偏差稍微低于DSTQN 之外,其他路径中DSTQN(ζ=0.6)的平均偏差要比Intel 公司训练的A3C 方法低很多。这是因为基于DSTQN 的方法能够利用定向导航信息来完成既定行驶路线,且利用了驾驶图像的时间和空间特征,运动规划指令预测更加准确,因此车辆行驶更加稳定,效果更好,而未利用定向导航信息的方法对全局路径掌握不足,通常只能完成直行而无法按照既定路线行驶,大多在弯道时就偏离了轨迹,特别是在有多个定向转弯的路径中(如R5),而只有基于定向导航指向信息的DSTQN 方法能完成路径规划顺利到达终点。对于只有一个定向转弯的测试路径R4,由于对比方法A3C 是Intel 公司在Carla中训练了1 000 万步的结果,训练次数远大于本文提出的DSTQN(ζ=0.6)方法的120 万步训练,因此DSTQN 在具有长直线的测试路径中具有更好的表现,而DDPG 和模仿学习在各条路径下表现均不如DSTQN方法。
图8 为三种方法在R6 第一个弯道(如图6中标号为1 的虚线框所示)的驾驶场景截图。可以看到在转弯时,DDPG 方法能够完成既定的右转动作,但在转弯后行驶到了道路中间;模仿学习方法转弯时左右晃动严重,多次越过车道中线;DQN方法在拐弯处偏离了既定的右转方向,导致测试失败;A3C方法虽然能够完成既定的右转动作,但是右转之后驶入了对向车道。只有DSTQN 方法在转弯时较标准沿着安全的规定路线行驶,可以看出DSTQN方法行驶稳定性更高。

图8 测试过程的驾驶场景截图Fig.8 Snapshots of driving scenarios in testing process
本文对奖励函数中不同超参数ζ训练出的模型进行了测试:当ζ=0.1时汽车更加注重横向奖励,使其在各条路径平均偏差都比较小,但无法完成有较多转弯的R5 和R6 路线;ζ=0.5和ζ=0.6时所有路径均能完成,但ζ=0.6时偏差距离小于ζ=0.5时的偏差距离;ζ=0.9时无法完成R3 和R5。综合训练过程中不同ζ的训练效果和不同ζ模型的测试结果,可以看出,ζ=0.6时算法学习性能强,测试稳定性高,超参数ζ设置为0.6最为合适。
2.3 模型实时性测试
模型实时性也是自动驾驶的一个重要指标,直接反映了该模型从接收图像输入到输出相应的驾驶动作需要的时间。对于高速行驶的汽车,实时性显得尤为重要,本文分别测试了DQN 模型、A3C 模型、DSTQN 模型和模仿学习模型在四条测试路径上的平均决策时间,如表4 所示。可以看到四种方法决策时间均小于0.2 s,本文设置图像显示帧率为每秒5帧,故四种方法均可在当前帧完成决策。由于DQN 方法模型结构较为简单,实时性较高而决策效果不佳;A3C方法决策时间较长,若帧率过大则无法完成决策;DSTQN 方法和模仿学习方法决策时间都较短,能够充分满足决策问题对实时性的要求。

表4 实时性测试结果Tab.4 Testing results of real-time performance
3 结语
本文提出了一种基于深度时空Q网络的定向导航自动驾驶运动规划算法,该算法在原始DQN中加入了CNN 和LSTM网络以同时提取驾驶场景的空间图像特征和前后帧之间的长期时间特征;此外,为了利用全局导航信息,在输入图像中加入指向箭头,实现定向导航的自动驾驶。实验结果表明,与现有方法相比,本文方法具有更好的学习性能和驾驶平稳性,且能够让车辆按指定路线沿着全局导航路径行驶,达到真正的自动驾驶目的。由于本文方法旨在解决自动驾驶的定向导航和行驶稳定性问题,因此本文方法没有考虑道路上的障碍物,如车辆和行人。未来的工作将集中在处理避障问题上,并在模型中引入交通信号。
