改进VGG模型在苹果外观分类中的应用
2020-08-03岳有军田博凯王红君
岳有军, 田博凯, 王红君, 赵 辉,2
(1.天津理工大学电气电子工程学院,天津市复杂系统控制理论与应用重点实验室,天津 300384;2.天津农学院工程技术学院,天津 300384)
苹果产业中,对采摘后的苹果进行外观分类是一个重要环节,在苹果生长过程中难免会产生病害导致表面存在病斑或者腐烂现象,所以需要对采摘后的苹果进行分类。目前大多数的苹果外观分类还是采用人工的方式,这样会消耗大量的人力,效率低下,影响后续苹果的销售。因此,实现对苹果外观快速、准确分类对苹果产业的快速发展具有重要意义。
目前对苹果的分类识别研究已经取得了一些进展,尹秀珍等[1]采用支持向量机(SVM)的方法,对苹果果实病害进行分类识别;霍迎秋等[2]利用压缩感知理论,求解待测样本特征向量在特征矩阵上的稀疏表示系数向量,通过对系数向量的分析实现苹果病害的分类; Omrani等[3]利用径向基函数的支持向量回归对苹果病害进行检测。Khan等[4]提出一种基于强相关性和基于特征选择的遗传算法对苹果病害进行分割和识别。王梓萌等[5]通过主成分分析(PCA)分别与马氏距离判别模型和Fisher判别模型结合,比较两种判别模型对霉心病的判别精度,完成对苹果的霉心病的检测。由于采摘后的苹果外观存在病斑或腐烂的情况在苹果图像中的比例较小,不容易分辨,用传统方法识别难度较大,很难保证相对较高的精度。
近年来,随着深度学习的发展,卷积神经网络开始广泛应用到各行各业[6-11]。农业方面,王细萍等[12]通过基于卷积网络和时变冲量学习的方法对苹果病变图像进行识别;程鸿芳等[13]利用改进LeNet卷积神经网络的方法对苹果图像进行识别。Muhammad等[14]提出基于相关系数和深度卷积神经网络特征的方法用于果树病害自动分割识别;Jiang等[15]将改进卷积神经网络的深度学习方法应用到了检测苹果叶片病害中。这些研究表明,卷积神经网络对苹果的外观分类识别有很好的应用性,克服了传统方法在效率和精度上的不足。
为了实现对采摘后的苹果进行精确的分类识别,提出了一种基于改进VGGNet的识别方法。考虑到苹果病斑和腐烂数据的多样性,数据集中收集了多种的苹果病斑和腐烂样本,并应用数据增广技术,增加数据集中图片的数量,避免网络发生过拟合现象。以构建的分类网络为基础,将其用于苹果外观图像的特征提取与表达,建立苹果外观分类器,并通过实验检验本文方法的有效性。
1 VGGNet卷积神经网络
1.1 VGGNet
VGGNet网络作为一个经典的卷积神经网络,主要包含输入层、卷积层、池化层和全连接层。
卷积层的作用是做特征提取,每个卷积核与上一层输入的特征图进行卷积,具体就是卷积核以一定的步长在特征图上进行滑动,并进行卷积运算,这样就能得到此层的特征图。每一个卷积核进行卷积运算后就能得到一个特征图,也就是说能提取到一种特征。池化层也叫下采样层,作用是主要用于特征降维,压缩数据和参数的数量,减小过拟合,对后续层中所需要的参数也有了大幅度的缩减,同时提高模型的容错性。池化层主要分为最大池化(max pooling)和平均池化(average pooling)两种,最大池化就是对邻域内特征点取最大,平均池化即对领域内特征点取平均值,比较常用的是最大池化。
全连接层在整个卷积神经网络中主要起到分类器的作用,将学到的分布式特征映射到样本标记空间。全连接层通常在最后一个卷积层或池化层之后,其每一个神经元和上层的全部神经元相连接。
VGGNet的最主要的思想就是增加网络深度,减小卷积核尺寸(3×3)。减少卷积核的好处就是可以减少参数和计算量。VGGNet结构相对于其他深层卷积神经网络来说,对结构和数据量相对较小的训练数据集有较好的处理能力,并且易于实现,识别效率较高。其中最典型的结构是VGG-16,有13个卷积层和3个全连接层,共16个权重层。VGG-16的输入为224 pixel×224 pixel的RGB图像,经过整个卷积网络的处理之后,输出为输入图像属于每个类别的概率。模型总体上分为6部分,前5部分为多个卷积核大小为 3×3的卷积层构成,后一部分为3个全连接层。VGG-16中的每个卷积层卷积步长(stride)为1 pixel,并通过边界填充(padding)为1 pixel来保持输入输出维度保持不变。池化层采用的是最大池化,窗口大小为2×2。3个全连接层的通道数分别为4 096、4 096、1 000,1 000表示输入图像在1 000类中每一类的得分,由于VGG-16是在ImageNet数据集上训练得到的,所以分类数为1 000。最后一层为softmax层,用于将得分转化为输入图像属于每个类别的概率。为了使权重具有非线性特征,在卷积层中使用了ReLU做非线性变换,加快网络收敛速度。
1.2 改进VGGNet
由于苹果外观分类数据集和ImageNet数据集相差较大,将VGG-16直接应用于苹果外观分类会导致识别准确率的降低,所以针对苹果外观分类的特点对VGG网络进行改进。
1.2.1 批归一化
卷积神经网络学习过程的本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也会大大降低。对于输入的数据,已经进行了人为的归一化,由于前面训练参数的更新将导致后面层输入数据分布的变化。
为了解决这个问题,使用了批归一化的方法。在网络的每一个卷积层之后,激活函数之前,又插入了一个归一化层。
此方法是将每一层的激活值进行归一化之后,将它们映射到方差为1均值为0的区域,从而解决了梯度消失的问题。当梯度变大之后,网络更新速度和训练速度变快,带来的好处是达到相同的正确率所需要的迭代次数更少,迭代相同次数时正确率会变高。
批归一化处理算法如下,批处理输入数据为m个样本x1~xm,输入数据的均值μ为
(1)
方差σ为
(2)
然后将数据归一化
(3)
公式如下:
yi=γixi+βi
(4)
(5)
βi=E(xi)
(6)
式中:参数γi和βi是通过训练学习得到的,Var为方差函数,E为均值函数。
1.2.2 全局平均池化
传统的卷积神经网络一般在卷积层之后添加全连接层进行特征的向量化,此外由于神经网络的黑箱特征,设计几个全连接层还可以增加卷积神经网络的分类性能,几乎成了卷积神经网络的标配。但是,全连接层有一个缺点就是参数量过多,一方面增加了神经网络训练和测试计算量,降低了速度;另一方面参数过多会导致网络的过拟合。
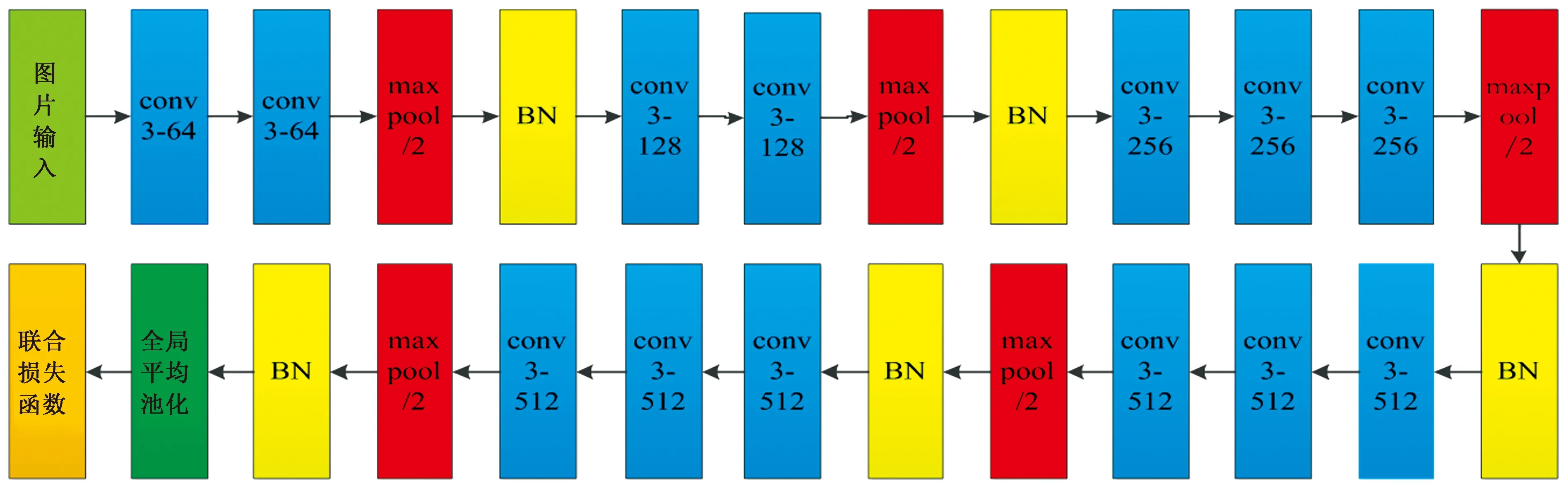
conv3-64、conv3-128、conv3-256和conv3-512等表示卷积核大小为3×3,通道数为64、128、256和512的卷积层,maxpool为步长为2 pixel最大池化层,BN(batch normalization)为批归一化层图2 改进VGG模型Fig.2 Improve the VGG model
针对于此问题,可以通过全局平均池化来解决。全局平均池化相对于传统的全连接层来说,能防止网络的过拟合,并增强特征图与类别的关系。
全局平均池化的主要思想是将每个进入全连接层之前的特征图融合为一个特征点,然后将这些特征点组成特征向量输入到softmax中进行分类,这样就会降低参数数量,减小计算量,防止网络的过拟合。例如网络最后一层的数据是n个m×m的特征图,全局平均池化就是计算每一张特征图的像素点的均值,输出一个特征点,这样n个特征图就输出n个特征点,这些特征点组成一个1×n的特征向量,就可以输入到softmax中进行分类了。如图1所示。

图1 全局平均池化Fig.1 Global average pooling
1.2.3 联合损失函数
对于常见的图像分类问题,通常采用softmax loss损失函数来求损失,softmax loss是将前一层的输出映射到(0,1)的区间内,最小化分类概率和真实分布的交叉熵使分类的概率更加接近真实类别。但是在苹果外观分类问题上,由于苹果病斑和苹果腐烂的情况非常相似,导致特征差异化不大。
可以采用softmax loss和center loss联合损失函数的方法,在softmax loss可以保证类间特征距离最大的基础上,加入center loss可以保证类内的特征距离最小,让同一类别的样本都能靠近对应类别的特征中心,使训练更加容易并方便进行优化。
softmax loss损失函数为
(7)
center loss损失函数为
(8)
式中:xi表示一共m个样本中属于yi的第i个样本特征;wj表示在全连接层的参数矩阵中的第j列,b为偏置;cyi表示第yi类别的特征中心。
1.3 苹果外观识别模型
基于改进的苹果外观分类模型在VGG-16模型的基础上添加了批归一化层,并采用全局平均池化层替代了之前的全连接层,最后采用联合损失函数的方法加入了center loss配合softmax loss使用,保证了识别模型的准确性。模型如图2所示。
2 实验研究
2.1 实验数据
以采摘后的苹果为研究对象,用采摘后的苹果图片作为数据进行训练。由于收集到的图片数量有限,为了增加数据的多样性,降低网络过拟合的风险,在预处理阶段需要利用数据增广技术来处理数据。数据增广技术是在保证数据类别不变的前提下,对原始图片进行各种变换,增加数据量,提高模型的泛化能力。数据增广的方式有很多,现采用下面几种方式进行数据增广:
(1)对原图像进行随机旋转(90°~180°)和水平翻转。由于是对采摘后的苹果进行外观分类,所以苹果在图片中的方向是不确定的,可以采用随机旋转的方法增加数据集的随机性。水平翻转不同于旋转180°的方法,而是类似于镜面的翻转,可以改变苹果在图片中的位置,增加数据集的数量。
(2)对原图像进行平移和放大。平移是将图像沿着x方向或y方向进行移动,或者沿x和y方向移动,保证苹果在图片中位置的随机性。因为每个苹果在图像中的大小不一样,所以可以对原图像进行等比例放大。经过平移和放大之后,可以进一步增加原有数据集的数量。
(3)在原图像中添加噪声。过拟合通常发生在卷积神经网络学习高频特征的时候,因为低频特征很容易就能学到,高频特征只有到最后才能学到,但高频特征对神经网络未做的任务没有帮助,会对低频特征产生影响,可以使用随即加入噪声来消除这写特征。
经过在原有获取到的数据集基础上进行数据增广之后,可以得到约20 000张苹果图片,其中15 000张图片作为训练集,5 000张图片作为测试集。将数据集分为正常、病斑和腐烂苹果三类,每一类的标签分别为0、1和2,如图3所示。训练之前,将数据集中所有图片统一设置为224×224像素。

图3 苹果数据集示意图Fig.3 Schematic diagram of apple dataset
2.2 试验平台
试验在Ubuntu 18.04的操作平台下进行,计算机配置为Intel Xeon(R)CPU E5-2650 v4@2.20 Hz×48、12 GB的 GeForce GTX 1080Ti×2 GPU并且运行内存为64 GB。采用Tensorflow深度学习框架,结合Python语言编程实现网络的训练和测试。
2.3 参数设置
采用随机梯度下降法(stochastic gradient descent, SGD)对网络进行训练,用批次训练的方法将训练集和测试集分为多个批次,训练时的batch size设置为64,测试时的batch size设置为50,迭代次数(epoch)为100次。初始学习率设置为0.01,并且分阶段逐次减小为原来的0.1倍,正则化系数设置为0.005。
3 实验结果和分析
为了测试改进后的网络对苹果外观识别准确率产生的影响,将改进后的模型与改进前的模型、AlexNet以及GoogLeNet进行准确率的比较,验证方法的有效性。
3.1 分类算法精度分析
文中为改进后的算法,命名为improve VGGNet,进行训练时不同模型的损失函数曲线如图4所示。

图4 不同CNN模型的训练损失Fig.4 Training loss of different CNN models
可以看出,改进后模型的损失函数相对于其他卷积神经网络模型在训练时较早的就达到拟合状态,逐渐接近于0。
训练时的准确率如图5所示,可以看出几个模型的准确率在迭代次数在30 000次以上都达到了一个较高的值,改进后的模型相对于其他模型较早的稳定在1附近,相对于对于其他模型准确率有明显提升。

图5 不同CNN模型的准确率Fig.5 Accuracy of different CNN models
3.2 不同方法的性能对比
为了验证本文算法在对正常苹果、病斑苹果和腐烂苹果分类的有效性,在测试集下,将目前在分类方面应用较多的AlexNet、GoogLeNet和VGGNet算法进行对比,各模型识别结果如表1所示。
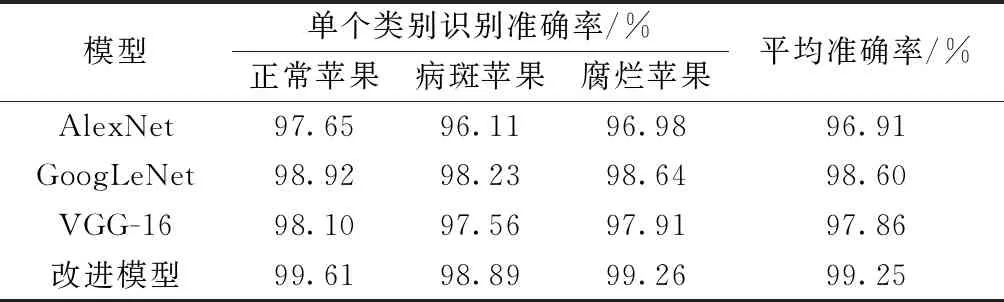
表1 不同方法的性能对比
从表1中可以看出,在卷积神经网络中,AlexNet、GoogLeNet、VGG-16和改进模型识别率分别为96.91%、98.60%、97.86%和99.25%。可以看出经过改进后的模型相比较其他四种模型对于苹果的识别率还是有明显提升的,证明了本文方法的有效性。GoogLeNet与之最为接近,AlexNet由于卷积层数较少等原因,在卷积神经网络中最低。
总体来看,三类苹果中正常苹果识别率最高,腐烂苹果居中,因为苹果中病斑特征不太明显,所以病斑苹果识别率最低。经过改进后的模型相对于其他3种模型识别率较高,能很好地满足苹果外观分类的要求。
4 结论
提出了一种基于VGG模型的苹果外观分类方法,得出以下结论。
(1)针对VGG-16在苹果外观分类的训练过程中容易出现计算量大、过拟合的问题,提出在利用数据增广技术增大数据量的同时,用批归一化、全局池化和联合损失函数对网络进行优化,优化后的网络比原网络的平均准确率提高1.4%。
(2)试验表明对采摘后的苹果进行外观分类平均准确率达到99.25%。为了验证改进后模型在苹果外观分类上的有效性,与在苹果识别方向应用较多的AlexNet、GoogLeNet和未改进的VGGNet算法进行对比,结果表明改进后模型的平均准确率均高出其他模型。
(3)改进后的模型虽然计算量不大,但是仍有可优化空间,今后还需要在确保精度高的同时,使计算量最小,从而方便后续对苹果外观分类的研究和应用。
