基于多核支持向量机的小麦条锈病遥感监测研究
2020-08-03刘良云白宗璠
高 媛,竞 霞,刘良云,白宗璠
(1.西安科技大学测绘科学与技术学院,陕西西安 710054;2.中国科学院遥感与数字地球研究所,数字地球重点实验室,北京 100094 )
条锈病是我国乃至世界发生面积广、危害程度大的一种小麦病害,严重时可导致小麦减产40%以上[1]。传统依靠人工田间调查的小麦条锈病监测方法费时费力,难以多点同时大面积展开,且由于缺少病害空间分布的准确信息,易导致杀菌剂的漏施、多施,造成作物药害以及土壤污染等环境问题[2]。近年来,随着高光谱遥感技术的发展,一些基于遥感探测数据的无损快速诊断技术被用于作物病害监测中[3],尤其是利用冠层光谱数据的作物病害遥感探测取得了重要进展[4-7],但其研究主要是基于已有植被指数或者光谱特征,并未考虑冠层反射光谱在受到土壤覆盖度、冠层几何结构、大气等环境因子对光谱的吸收影响时随着时空的变化[8],因此针对不同时空下的小麦条锈病,如何获取动态的冠层光谱敏感因子显得尤为重要。刘 琦等[9]在325~1 075 nm全波段范围内成功建立模拟识别小麦条锈病的模型,但其数据直接使用全波段,包含大量无效信息,存在冗余等问题。独立变量分析(independent component analysis,ICA)是一种提取高阶统计上线性无关特征的方法,可以从一组混合观察信号中分离出独立信号,最早用于盲源信号分离问题,具有较高的收敛速度[10]。目前,已有研究将ICA应用于植物重金属污染胁迫信息分析[11-12]。因此,本研究采用独立变量分析对小麦冠层全波段光谱数据进行特征提取,获取冠层光谱敏感因子。
小麦受到条锈病菌侵染后,光合能力和叶绿素含量迅速降低,而日光诱导叶绿素荧光与光合作用之间具有直接的联系[13],能够敏感反映作物光合生理上的变化[14]。张永江等[15]利用标准FLD(fraunhofer line discrimination)方法预测了小麦条锈病不同病情严重度的日光诱导叶绿素荧光,证实了日光诱导叶绿素荧光可以反映田间小麦条锈病的发病状况。冠层反射光谱主要反映作物的生化特性,对作物色素含量的变化比较敏感,但难以揭示植被光合生理状态[16],且受土壤颜色、阴影或者其他非绿色景观成分等背景噪声的影响较大[13]。条锈病菌侵染后,小麦植株水分、叶绿素含量、光合速率和光能转换率等一些生理生化指标均会发生变化[4],综合利用反射光谱在作物生化参数探测方面的优势和叶绿素荧光在光合生理诊断方面的优势,能够更加客观地映射小麦条锈病害的真实状况,提高小麦条锈病的遥感探测精度。但目前的研究往往将冠层反射光谱数据与叶绿素荧光数据割裂开来分析或者仅仅只是将这两种特征进行直接拼接作为病情指数估测模型的输入参量[17-18],并未考虑各种特征数据与病情指数之间的最优映射关系。多核学习是在支持向量机(support vector machine,SVM)的基础上提出的一种新算法,能够将不同的核函数组合起来学习,弥补单核支持向量机在针对样本特征具有异构性时建模的不足[19]。
鉴于此,本研究首先将快速独立分量分析(fast independent component analysis,FastICA)方法应用到冠层反射光谱的特征提取上,为模型构建提供良好的数据源。在融合冠层反射光谱特征与日光诱导叶绿素荧光指数时,分别选用可较好模拟二者与病情指数相关关系的核函数进行映射,使不同病情指数下的样本能够被组合后的特征更好表示,在此基础上利用多核学习支持向量机方法有效组合不同特征和不同核建立病情指数估测模型,以期可以更好地揭示小麦条锈病病情指数与小麦的冠层光谱所表现出的生理生化参量之间的本质关系,提高小麦条锈病病情指数反演的精度。
1 材料与方法
1.1 试验设计
试验于2018年春季在河北省廊坊市中国农业科学院试验站进行。其中,试验区域小麦分为健康组(编号A、D)和染病组(编号B、C),每个试验组面积220 m2,每组分为8个样方(A1~A8、B1~B8、C1~C8、D1~D8),因此共有32个样方,其中健康组和染病组各16个。小麦品种为铭贤169,染病组于2018年4月9日喷洒接种条锈病菌孢子,孢子溶液浓度9 mg·100 mL-1。
1.2 数据获取与预处理
1.2.1 冠层光谱测量
冠层光谱测量使用ASD Field Spec 4光谱仪,测量时间为北京时间11:00-12:30,共测定2018年5月18日、5月24日和5月30日3个时期小麦条锈病不同病情严重度下的冠层光谱数据。观测时测量高度始终离地面1.3 m,探头垂直向下,探头视场角25°,每区域测量10次取均值,并在测量前后用标准BaSO4参考板进行校正。利用公式(1)根据测量得到的光谱数据计算反射值。
R=Ltarget/Lboard×Rboard
(1)
式中R为冠层反射率,Ltarget为目标辐亮度,Lboard为参考板辐亮度,Rboard为参考板反射率。
1.2.2 病情指数调查
小麦条锈病病情指数调查与冠层光谱测量同步进行,测量方法为5点取样法,即在每个样方中选取对称的5个点,每点约1 m2面积,各点分别选取30株小麦调查其发病情况。病情严重度分为9个梯度:0、1%、10%、20%、30%、45%、60%、80%和100%,分别记录各梯度下小麦叶片数,根据记录结果利用公式(2)计算测试群体的病情指数(disease index,DI)。
(2)
式中x为各梯度的级值,n为最高梯度值9,f为各梯度的叶片数[20]。
1.2.3 日光诱导叶绿素荧光指数提取
日光诱导叶绿素荧光指数在使用ASD Field Spec 4光谱仪测定的冠层光谱数据的基础上利用辐亮度和反射率两种方法提取[21]。基于辐亮度的叶绿素荧光提取算法能够得到叶绿素荧光强度值,属于日光诱导叶绿素荧光的直接提取方法。该算法依据夫琅和费暗线原理,利用夫琅和费线内的一个波段和夫琅和费线外的一个(或多个)波段的表观辐亮度,通过计算自然光照条件下太阳光激发的荧光对“夫琅和费井”的填充程度估算叶绿素荧光的强度。关于填充程度的计算,目前已有多种算法,本研究采用鲁棒性较好的3FLD算法[22],其计算公式如公式(3)所示[23]。
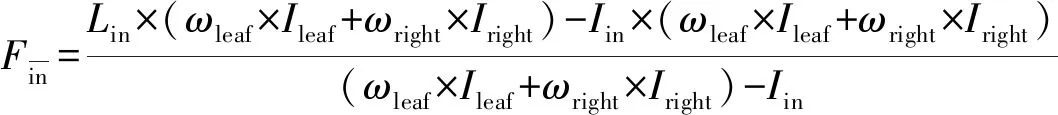
(3)
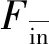
已有研究表明,O2-A(760nm)波段氧气吸收形成的夫琅和费暗线特征明显,荧光较强[24],且估测精度高[25]。基于此,本研究利用3FLD算法估测了O2-A波段的日光诱导叶绿素荧光强度。同时为了提高日光诱导叶绿素荧光提取精度,减弱冠层光谱数据测量不同时间段太阳光照强度等外界因素对日光诱导叶绿素荧光估算值的影响,本研究将计算得到的日光诱导叶绿素荧光的绝对强度分别除以夫琅和费吸收线内的太阳入射辐照度,获取该吸收线处的日光诱导叶绿素荧光的相对强度[26]。
(4)
式中Frelative为日光诱导叶绿素荧光相对强度,Iin为参考板获取的夫琅和费吸收线内的太阳入射辐照度。
基于反射率方法提取的日光诱导叶绿素荧光是1个反映荧光强度的反射率指数,属于叶绿素荧光的间接提取方法。由于叶绿素发射的荧光对常用于评价植物健康活力的红边区的表观反射率有一定贡献,因此基于反射率的提取算法实质为通过分析荧光对650~800 nm红边区域反射率的影响来构建荧光光谱指数。目前,基于反射率的叶绿素荧光指数通常分为反射率比值指数、反射率一阶导数指数以及填充指数三类[21],反射率比值指数利用一个受荧光影响强的波段和一个受荧光影响弱的波段的比值去除与反射率相关的光谱信息以获取荧光信息,如Zarco-Tejada等[27]构建的R690/R655、R740/R720、R440/R690、R750/R800等比值指数。反射率一阶导数指数主要用于探测红边光谱区荧光发射的细小变化[23],如Zarco-Tejada等[28]构建的一阶导数光谱指数D730/D706。填充指数是通过两个波段反射率的差间接反映荧光信息,但该指数除荧光信息外,也受随大气和太阳观测几何的变化的夫琅和费暗线深度的影响,仅适用于在相同时间和观测条件下的数据对比[23]。基于此,本研究仅计算目前常用的反射率比值指数和反射率一阶导数指数并依据其与病情指数之间的显著相关性进行指数筛选得到最终用于建模的反射率荧光指数。
1.3 模型构建方法
1.3.1 独立主成分分析
针对计算所得的冠层反射光谱,采用快速独立分量分析(FastICA)方法提取特征。FastICA,又称固定点算法,是ICA的一种快速算法,具有收敛速度快、分离效果好的优点。ICA最早应用于盲源分离,能够将测量得到的混合信号分离为相互独立的源信号,数学模型表达式如公式(4) 所示:
X=AS
(5)
其中,k(x,x′)=exp(-‖x-x′‖2/2σ2),由实地观测得到的n个样本点的冠层反射光谱构成的n个行向量所组成;S=[S1,S2,…,Sm]T,为m个待测量独立成分特征矩阵,A为混合矩阵,该矩阵与样本中各独立成分比重相关,维数为n×m,一般m≤n。
ICA在假设各成分之间相互独立的基础上,从混合的观测信号X中分解出源信号S,即寻找混合矩阵W,使得
Y=WX
(6)
其中,Y是计算得到的独立源信号S的最佳逼近。
1.3.2 多核支持向量机模型
SVM是一种建立在统计学习理论基础上的基于结构风险最小化的学习方法,通过使用映射函数将低维输入空间的样本映射到高维空间,使其变为线性情况,其核心问题为核函数的确定[18]。传统的SVM中常用的基核函数包括高斯核以及多项式核等,其表达式分别为:
k(xi,xj)=exp(-‖xi-xj‖2/2σ2)
(7)
k(xi,xj)=(xi·xj+1)p
(8)
其中,σ是高斯核参数,p是多项式核函数中的阶数。
但是传统单核SVM受到核函数的限制,当建模特征来源广且与目标参量不一定满足同一种映射关系时,无法充分挖掘特征与目标参量间的相关信息,使其应用受到限制[19]。多核学习方法是在SVM的基础上发展而来的算法,其核心思想为基于Mercer定理,用多个基本核函数的凸组合代替传统单一核函数的方法来克服传统单核函数的固有缺陷,提高学习性能[29]。多核学习中核函数的通用表达式为
(9)
式中Km表示传统SVM中的基核函数,M表示基核函数的个数,dm是基核函数线性组合的权系数。
基于此,为了在构建小麦条锈病病情严重度估测模型时充分利用日光诱导叶绿素荧光和冠层反射光谱特征信息,本研究基于多核学习理论,以高斯核和多项式核作为基核函数,利用Matlab R2014b编程语言,采用梯度下降法计算权重系数,并以KKT条件作为算法的停止准则,构建多核学习支持向量机模型[29]。
1.4 模型精度验证
鉴于留一交叉验证法能够充分利用样本中所有数据,在有限样本容量下尽可能减少“过拟合”问题,可以得到较为稳定的误差指标,尽量避免因为随机抽选训练集和测试集导致测试误差的随机变化,本研究采用该方法对模型精度进行检验。精度评价指标选用模型估测DI值与实测DI间的决定系数(determination coefficient,r2)和均方根误差(root mean square error,RMSE)[30]2个 指标。
(10)
(11)
2 结果与分析
2.1 特征参量的优选
2.1.1 冠层反射光谱特征的选取
利用FastICA算法提取冠层反射光谱特征向量时,由于1 800 nm之后的冠层反射光谱数据信噪低,且在1 351~1 450 nm处光谱数据受空气中水汽影响较大,因而为了减少噪声干扰,选取波长在400~1 800 nm范围内且不包含水汽影响的波段作为有效波段进行分析。由于不同波段的冠层光谱反射率与小麦条锈病病情指数之间的相关性不同(图1),因此为了减少FastICA的输入波段数,降低噪声干扰,选取与DI显著相关的波段作为FastICA的输入波段,然后依次进行标准化以及白化操作以获取独立分量,最终依据表1中得到的各独立分量与病情指数之间的相关系数挑选最终的冠层反射光谱特征。最终共挑选出冠层光谱特征6个,分别位于468~523 nm、558~713 nm以及1 410~1 563 nm波段处。
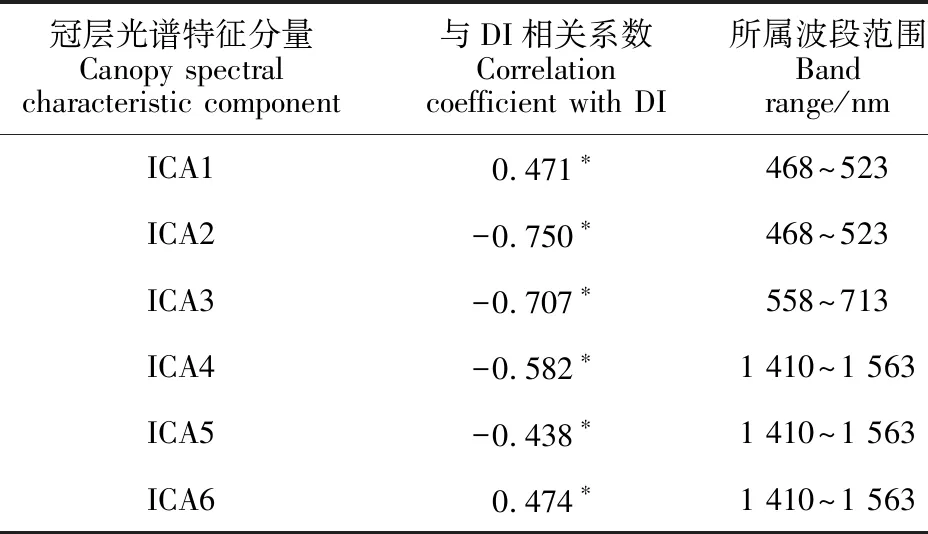
表1 冠层反射光谱独立成分分量信息Table 1 Independent components of canopy reflectance spectrum
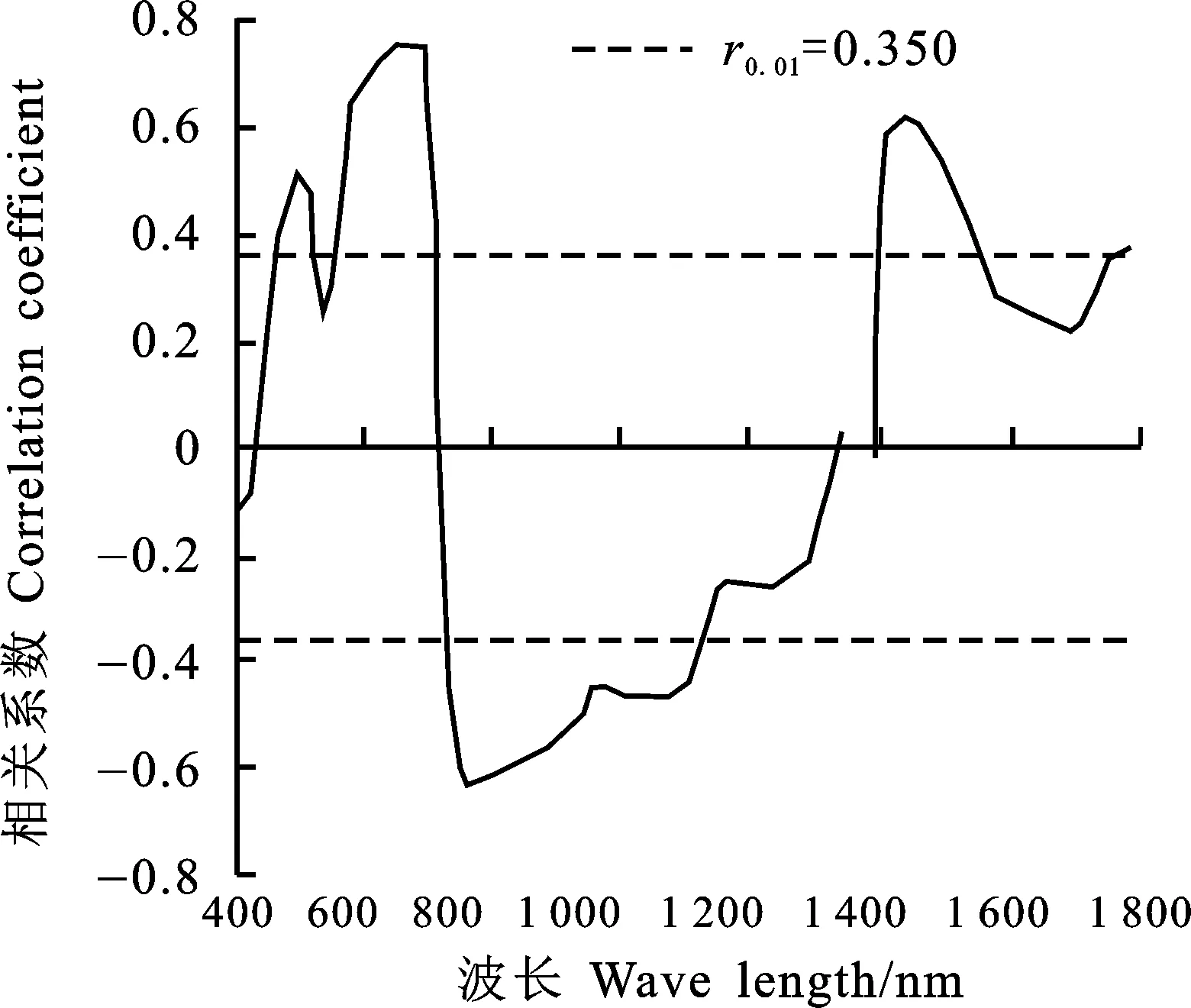
图1 小麦冠层光谱与条锈病病情指数相关关系
2.1.2 日光诱导叶绿素荧光特征的选取
在选取日光诱导叶绿素荧光特征时,首先基于辐亮度算法计算O2-A波段的日光诱导叶绿素荧光强度;其次,对于基于反射率的荧光指数,在利用公式(1)将冠层辐亮度数据转化为反射率的基础上,参考已有的研究成果计算常用的反射率比值指数以及反射率一阶导数指数R440/R690、R690/R655、R740/R720、R750/R800、D730/D706。最后计算上述特征参量与小麦条锈病病情指数之间的相关系数,挑选与DI极显著相关的叶绿素荧光指数作为用于建模的日光诱导叶绿素荧光特征。从表2可以看出,O2-A吸收线位置处荧光相对强度、R440/R690、R740/R720、D730/D706与小麦条锈病病情指数达到了极显著相关,可以作为日光诱导叶绿素荧光监测小麦条锈病严重度的敏感因子。

表2 日光诱导叶绿素荧光指数信息Table 2 Solar-induced chlorophyll fluorescence index
2.2 模型的构建与精度评价
2.2.1 不同特征参量的最优核选取
针对优选的冠层反射光谱特征以及日光诱导叶绿素荧光特征参量,分别利用支持向量机学习算法构建小麦条锈病病情严重度估测模型,并采用留一交叉法对不同模型精度进行验证,分析各特征参量与病情指数之间的映射关系,以确定反射光谱数据和日光诱导叶绿素荧光的最优核函数,其结果分别如图2和图3所示。图2描述了冠层反射特征参量分别采用高斯核和多项式核构建支持向量机模型的效果,可以看出,对于利用FastICA提取的冠层反射率独立成分分量而言,采用高斯核的效果优于多项式核。而图3的结果表明,对于叶绿素荧光指数而言,采用多项式核的效果优于高斯核。叶绿素荧光主要反映作物光合作用状态,受土壤等非绿色植被背景噪声的影响较小,因此可以选用特定分布的核函数如多项式核作为其与病情指数之间的映射函数。但对于作物冠层反射率而言,在获取反射率光谱时,受土壤等背景噪声的影响较大,导致获取的样本点反射率光谱与病情指数的关系不一定符合某种分布[2],而高斯核函数能够实现高维空间的非线性映射,即使在样本分布未知的情况下,其旋转对称性可确保不造成大的偏差,从而获得较高的反演精度。
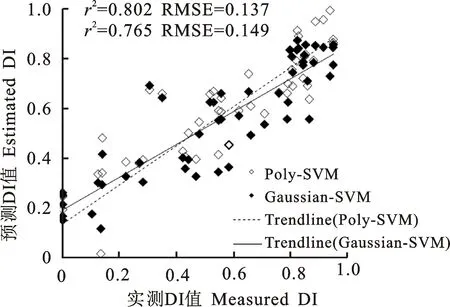
图2 基于冠层反射率的小麦条锈病病情严重度反演模型预测DI值与实测值散点图

图3 基于荧光指数的小麦条锈病病情严重度反演模型预测DI值与实测值散点图
2.2.2 多特征融合下的模型构建与精度评价
常用的多特征融合方法主要有直接拼接法和基于核函数的特征融合法两种。其中,直接拼接法将所有特征并列形成高维的特征向量,并未考虑不同类型特征各自具有的特性,仍采用单一核函数映射所有特征来构建模型,不仅无法充分挖掘特征中包含的信息,同时可能还会增加分类器训练和预测时的计算代价。而基于核函数的特征融合法将不同的特征用不同的核函数进行映射实现多特征融合,更有利于样本数据特征的表达,可以在一定程度上弥补各个单特征的缺点,最大限度地发挥各种特征的优势,提高模型监测精度。
为了验证多特征融合下的多核学习支持向量机在小麦条锈病病情指数反演中的优越性,首先比较仅采用冠层反射光谱特征或日光诱导叶绿素荧光特征的单一特征建模精度与将这两种特征直接拼接的多特征融合的建模精度(表3);然后对比分析直接拼接法与基于多核学习的多特征融合两种不同特征融合方法的建模精度(图4)。

表3 多特征融合与单特征模型的精度对比Table 3 Accuracy comparison between multi-feature combination and single feature model
从表3可以看出,相对于使用单一特征,使用多特征融合方法的模型反演精度总体上有所提高。在使用高斯核建模时,基于直接拼接法融合冠层反射率特征以及叶绿素荧光指数特征后的模型预测DI值和实测DI值间的r2为 0.787,RMSE为0.142,优于仅使用冠层反射率(r2= 0.725,RMSE=0.161)或者仅使用叶绿素荧光指数特征(r2=0.765,RMSE=0.149)时的模型精度;对于多项式核SVM而言,采用直接拼接法的模型r2为0.847,RMSE为0.120,优于采用单一特征的建模精度。其次,由图4可以看出,采用基于核函数的多特征融合方法模型的预测DI值与实测DI值之间的拟合程度最优,其r2为0.915,RMSE为0.090,相对于采用直接拼接法,其r2分别提高了16.3%、8.0%,RMSE分别减少了 36.6%、25.0%。说明对于冠层反射率光谱特征以及日光诱导叶绿素荧光指数特征而言,采用直接拼接法进行多特征融合虽然在一定程度上可以提高模型反演的精度,但该方法仍使用单一核函数映射融合后的特征,不能够较好地反映不同类型特征具有的特性。而基于多核学习的多特征融合的小麦条锈病病情指数反演模型,可以最大限度地利用特征特性,将冠层反射光谱特征在作物生化参数探测的优势以及叶绿素荧光在光合生理诊断方面的优势结合起来,提高病情估测的精 准度。
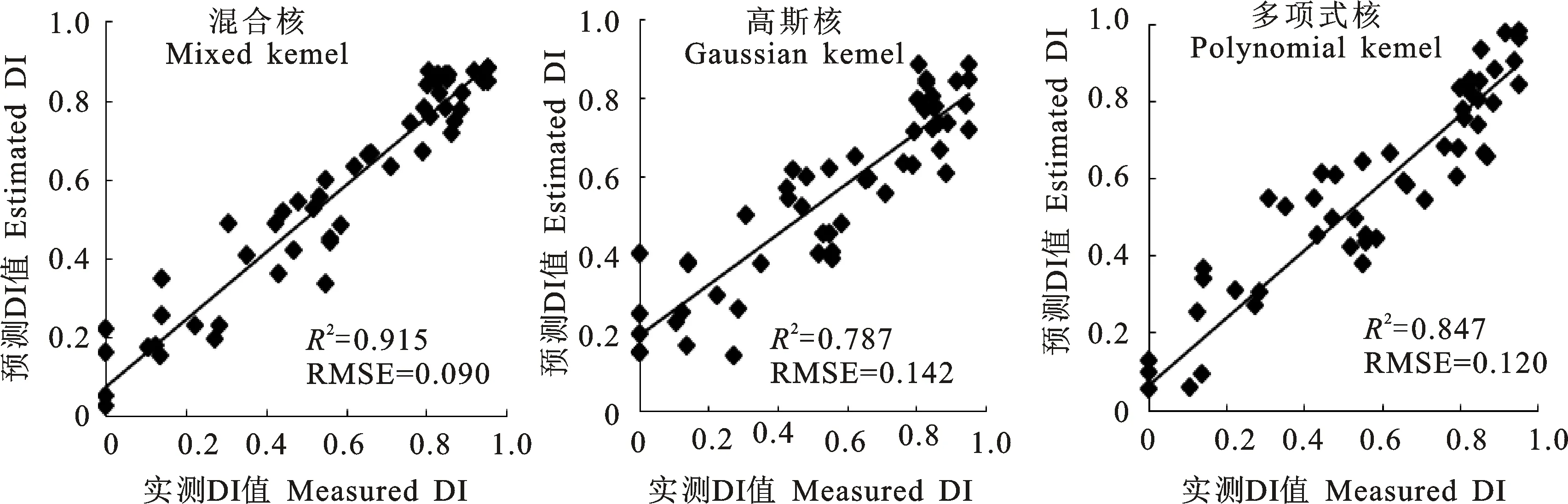
图4 反射率与荧光融合的小麦条锈病病情严重度反演模型预测DI值与实测值散点图
3 讨 论
小麦条锈病原菌在侵入小麦后,会造成小麦水分、叶绿素含量、光合速率和光能转换率等一些生理生化指标均发生变化[4]。综合利用反射光谱在作物生化参数探测方面的优势和叶绿素荧光在光合生理诊断方面的优势能够比较全面客观地映射小麦条锈病害的真实状况,提高小麦条锈病的遥感估测精度。本研究表明,基于直接拼接法融合日光诱导叶绿素荧光及冠层光谱反射率特征作为输入变量构建的小麦条锈病遥感探测模型的估测精度较采用单一荧光数据或反射光谱数据所构建的模型均不同程度提高,其中对于高斯核SVM,采用直接拼接法的多特征融合模型比采用单一冠层反射光谱数据或叶绿素荧光数据的模型预测DI值与实测DI值之间的r2分别提高了 8.6%、2.9%,RMSE分别减少了11.8%、4.7%;对于多项式核SVM而言,r2分别提高了 26.0%、5.6%,RMSE分别减少了31.8%、12.4%。
对于日光诱导叶绿素荧光指数与反射光谱特征的融合而言,虽然采用直接拼接法融合日光诱导叶绿素荧光和反射光谱数据作为小麦条锈病病情严重度估测模型的输入参量能够在一定程度上提高模型估测精度,但是不同光谱特征与病情指数之间不一定满足相同的最优映射关系,因此,本研究在提取可见光-近红外反射率独立分量特征组以及日光诱导叶绿素荧光指数特征组的基础上,使用不同的核函数分别对不同特征组建模,以期可以找到不同特征参量与病情指数之间的最优映射函数。本研究结果表明,对于冠层光谱而言,由于其实际测量时受到土壤、植株叶片角度等影响较大,采用在样本分布情况未知下仍有较好建模结果,且以高斯核效果更优,而对于日光诱导叶绿素荧光指数而言,采用多项式核的效果优于高斯核。基于此,本研究构建了特征最优核映射的多核学习支持向量机模型。通过对比分析反射光谱数据和日光诱导叶绿素荧光数据特征进行直接拼接后的单核学习SVM模型与基于不同特征最优核映射的多核学习SVM模型的预测精度发现,基于特征最优核映射的多核学习模型效果较采用直接拼接法的多特征融合模型更优。
在提取冠层反射光谱特征参量时,虽然本研究采用的独立成分分量方法在一定程度上能够避免全波段信息含量巨大、无效信息冗杂的问题,但如何消除数据测试时外界环境条件差异对光谱影响,使所建模型具有更强的稳定性和适用性,还需要更加深入的研究。其次,在寻找不同特征参量组与病情指数之间的最优核函数映射时,本研究仅采用高斯核和多项式核作为基础核进行分析,当改变遥感监测条锈病的敏感因子或者分析更多的核函数时,最优映射核是否会改变以及如何更客观合理地挑选不同特征参量的最优核函数还有待进一步研究。
小麦病害不仅导致其反射光谱及日光诱导叶绿素荧光发生变化,而且病害的发生与小麦的生育期及其外界温湿度条件等均有关系,如何综合利用时相信息、温湿度条件、反射光谱和日光诱导叶绿素荧光数据以及农学知识等多种数据和技术手段提高小麦条锈病遥感逆向识别的精度则是下一步工作的重点。
