基于语义共现与注意力网络的问题分类方法
2020-08-01马伟锋季曹婷马来宾
楼 姣,马伟锋,季曹婷,马来宾
(浙江科技学院 信息与电子工程学院,杭州 310023)
随着互联网技术的发展,各类网络问答社区(community question answering,CQA)相继出现并蓬勃发展,而问题分类作为问答社区的核心技术,受到了研究者的高度关注。早期问题分类主要使用基于规则的方法、基于统计的方法及两者相结合的方法,通过提取问题中的中心词[1]、词性[2-3]、依存关系[3]等特征或对特征进行组合[2]的方式对问题进行分类,并取得了良好的分类效果[4]。然而上述方法忽略了问题本身的词序和语义信息。随着深度学习的发展,深层神经网络凭借能够自动提取特征的优势,在文本分类任务中得到了广泛的应用。Kim等[5-6]通过使用卷积网络(convolutional neural network,CNN)探究了深度学习网络模型在句子分类中的应用。Zhou等[7-8]将长短时记忆神经网络(long short-term memory network,LSTM)与卷积神经网络、注意力机制相结合,捕获文本的深层语义特征。Yao等[9]利用共现词与文档词之间的关系,构建文本图卷积神经网络用于文本分类。近年来,除了对文本分类模型结构进行改进外,许多研究者开始探索如何对文本扩展语义并进行特征融合。徐健等[10]提出了一种融合双语信息的问题分类方法。张栋等[11]利用问题及其答案联合学习词向量表示,增强问题文本词向量的语义信息。Yu等[12]使用疑问词注意力机制关注问句中的疑问词特征,扩展了问句的语义信息。江伟等[13]在词嵌入层后加入卷积层提取N-gram短语的向量表示,通过学习短语的权重加强文本语义表示。谢雨飞等[14]通过依存句法树提取问题文本的语义单元,扩展了问题文本的语义信息。肖琳等[15]提出基于标签语义注意力的文本分类方法,提升了模型的预测精度。
上述研究在问题分类任务中取得了较好的结果,但对垂直领域问答社区的问题分类仍有待进一步研究。目前,面向汽车故障领域的问答社区问题分类主要存在以下难点:一是现有的问题分类方法主要基于含有疑问词的问句[16],而多数用户提出的汽车故障问题并不涵盖疑问词;二是问答社区中用户表述汽车故障有其灵活性,难以区分整体特征相似但局部差异较大的问题类别,并且常出现问题文本较短导致语义信息不足等现象。针对上述问题,本研究在现有的深度学习模型基础上结合注意力机制,借助汽车故障问答社区丰富的用户交互文本,提取共现词作为问题文本的扩展语义信息,提出基于问题-答案语义共现的多层次注意力卷积长短时记忆网络(co-occurrence word attention convolution LSTM neural network,CACL)模型的问题分类方法。
1 问题分类模型结构与方法
基于问题-答案语义共现的多层次注意力卷积长短时记忆网络模型结构如图1所示。图1中,W为权重参数矩阵,uw为注意力权重,αt为语义重要程度归一化后的结果,S为文本表示。

图1 CACL模型结构图Fig.1 Model structure of CACL
CACL模型处理过程如下:1)在输入层引入共现词注意力机制,通过汽车故障问答社区中问题-答案文本联合构建共现词注意力矩阵,关注问题文本中与共现词相似词的语义信息;2)将共现词注意力矩阵输入卷积神经网络提取局部特征;3)利用共现词注意力矩阵捕捉有效的卷积特征,将其输入长短时记忆网络抽取长距离依赖特征;4)利用词级别注意力机制将长短时记忆网络的输出特征进行高层次特征抽取;5)使用Softmax分类器进行问题分类。
1.1 基于共现词注意力机制的表示
由于汽车故障问题文本特征稀疏,缺乏充足的语义信息,并且一般的深度学习模型所使用的词向量并没有特别关注那些对分类结果贡献度较大的词,因此本文提出了基于问题-答案语义共现的注意力机制,利用问答社区拥有较多用户交互文本的优势,通过提取问题-答案中的共现词,构建问题文本与共现词的注意力矩阵,具体方法如下所述。
1)问题文本q={w1,w2,…,wn},n表示问题文本q所包含的词语数,n∈[1,N];共现词u={o1,o2,…,om},om表示问题文本q的第m个共现词,m∈[1,M]。使用Word2vec模型[17]预训练的词向量Vq={x1,x2,…,xd},xd表示问题文本的词向量在d维上的值;Vu={y1,y2,…,yd},yd表示共现词的词向量在d维上的值。
2)计算问题文本中每个词与对应多个回答所有词的余弦相似度
(1)
利用自定义的停用词表过滤无实意的词,最终选取问题文本中与答案文本相似度最高的K个词作为有效共现词,如答案文本中与问题文本“排气管”“冒黑烟”语义接近的词有“排气管”“排气口”“冒黑烟”“冒烟”“黑烟”等。
3)引入共现词注意力矩阵A∈Rn×m来表征问题文本中各个词与共现词之间的相似度,其元素
Anm=f(wn,om)。
(2)
式(2)中,函数f的计算方法同式(1)。
根据共现词注意力矩阵,我们最终还需要为原问题文本生成维度一致的注意力特征图Fa∈Rn×d,其实现方法如下:
Fa=A×W。
(3)
式(3)中:W∈Rm×d为权重参数矩阵,需在模型训练中不断学习以更新。
1.2 卷积神经网络的运用
使用单通道卷积层对基于共现词的注意力特征图Fa进行卷积,得到新的特征ci。在对Fa进行卷积操作时,一般选取h×d维大小的卷积核,其中d为词向量的维度,h为卷积计算中滑动窗口的大小。ci的计算方式如下:
ci=fr(W0·Sa,i:i+h-1+b)。
(4)
式(4)中:ci为由卷积操作得到的第i个特征;fr为非线性激活函数,本文使用ReLu函数作为激活函数;W0为卷积核的权重参数矩阵,W0∈Rh×d;Sa,i:i+h-1为Fa中第i行到第i+h-1行的局部特征,b为偏置项。对每个窗口中的局部特征进行卷积操作,最终得到特征图
C=(c1,c2,…,cn-h+1)。
(5)
1.3 长短时记忆网络的运用
卷积神经网络虽然能够提取问题文本的局部特征,但它在捕获长距离依赖特征时有局限性。而长短时记忆网络恰好能弥补这一缺陷。因此,本文将卷积神经网络提取的特征输入长短时记忆网络,用于获取问题文本的长距离依赖特征。参照Hochreiter等[18]最早提出的长短时记忆网络结构,最终得到长短时记忆网络的输出结果H,H=(h1,h2,…,ht-1,ht,ht+1)。长短时记忆网络的结构如图2所示,其中ht为长短时记忆单元在t时刻的输出结果,xt为经过卷积后时序t的输入信息。
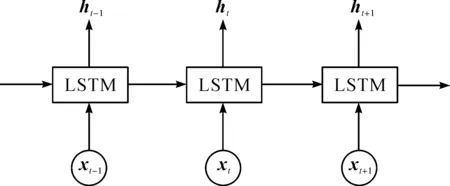
图2 长短时记忆网络结构图Fig.2 Long short-term memory network structure
1.4 词级别注意力机制的运用
参考Yang等[19]提出的层次注意力模型(hierarchical attention network,HAN),在长短时记忆网络完成长距离信息提取后,将其输出作为词级别注意力层的输入,并构造加权注意力参数矩阵。通过不断的训练,该参数矩阵将会根据问题文本中语义的重要程度分配权重,聚焦文本中的重要部分,最终得到文本表示S。注意力参数矩阵的计算方式如下:
(6)
式(6)中:ft为激活函数tanh;Ww为加权注意力参数矩阵;ht为长短时记忆网络的输出;bw为偏置项;ut为语义向量;uw为注意力权重;αt为语义重要程度归一化后的结果。
1.5 问题分类
对长短时记忆网络的输出特征使用Softmax分类器分类,得到问题文本qi到类别j的概率
p=fs(WcS+bc)。
(7)
式(7)中:fs为Softmax分类器;Wc为权重参数矩阵;bc为偏置项。
在模型训练过程中,将交叉熵作为损失函数衡量模型损失,并加入正则项防止过拟合。模型训练的最终目标是最小化交叉熵损失。损失函数的计算方式如下:
(8)
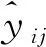
2 试验结果与分析
2.1 数据集的标注与划分
本文使用的数据集为自定义基准数据集,来源于一些专业汽车网站的汽车故障问答社区。目前,绝大部分汽车类问答社区尚未建立完整的汽车故障问题分类体系,一般的中文问题分类多采用文献[20]的分类体系,它将问题归纳为人物、地点、数字、时间、实体、描述6大类,而大多数汽车故障问题都属于描述类,因此该分类体系并不适用于汽车故障问题领域。本文根据汽车的故障现象[21],将其归纳为工况异常、渗漏异常、气味异常、声响异常、烟气异常、温度异常、消耗异常、外观异常、仪表异常9大类,分类情况及其实例见表1。

表1 汽车故障问题分类及其实例
本文的基准数据集共包含汽车故障问题8 000条,依据表1的汽车故障问题分类对其进行人工标注,并对部分存疑的数据最终通过我们这个项目组探讨处理。为验证本文所提算法模型的有效性,将随机抽取总样本的20%作为测试数据集,从剩余80%的数据中再抽取10%作为验证数据集,其余的作为训练数据集。汽车故障问题数据集的分布统计见表2。

表2 汽车故障问题数据集的分布统计Table 2 Data set distribution statistics of automobile fault problems 条
2.2 评估指标的选择
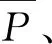
(9)
式(9)中:TP为实际为正且预测为正的样本数;FP为实际为负但预测为正的样本数;FN为实际为正但预测为负的样本数;TN为实际为负预测为负的样本数;i为测试集中的样本数。
2.3 对比试验的模型选择
为验证本文提出模型的有效性,我们使用同一数据集对不同模型进行对比试验。在进行对比试验之前,为获取更优质的词向量,我们使用汽车故障语料库中的问题文本和答案文本,采用与文献[7]一致的参数设置,联合训练词向量。具体而言,使用Word2vec的Skip-gram模式,上下文窗口设为5,词向量维度设为100,最终得到问题文本在Word2vec中的向量表示。对比试验选取的模型分别为SVM[22]、CNN、LSTM、Bi-LSTM[8]、C-LSTM[7]及我们提出的CACL。
2.4 结果分析
表3是当前问题分类的主流模型与CACL模型对比试验后所得出的各项指标评估值。由表3可知,传统的机器学习模型SVM并不能有效学习问题文本语义,在问题分类任务中不具备优势,而主流的深度学习模型CNN、LSTM、Bi-LSTM、C-LSTM在学习文本语义方面具有显著优势;相比较于其他5种模型,本文提出的CACL模型在汽车故障问题分类中有较好的表现。这表明利用共现词注意力矩阵有助于扩展问题的文本语义,能有效提升汽车故障问题的分类精度。

表3 对比试验各项指标评估值Table 3 Index evaluation values of comparative experiment %
表4是Bi-LSTM、C-LSTM及CACL模型在不同汽车故障问题类别间的F1值对比。F1值是精确率和召回率的调和平均数,能够有效评估模型精确度。从表4中可以看出相比较于Bi-LSTM和C-LSTM模型,CACL模型整体性能都有所提升,尤其对工况异常、声响异常及温度异常等故障问题的分类效果最为显著。这说明利用共现词注意力矩阵能够更好地聚焦问题文本中与答案文本语义相似的内容,答案文本能够在一定程度上对问题文本进行语义限定,从而在面对整体特征相似,但局部特征差异较大的汽车故障问题时有较强的区分能力。
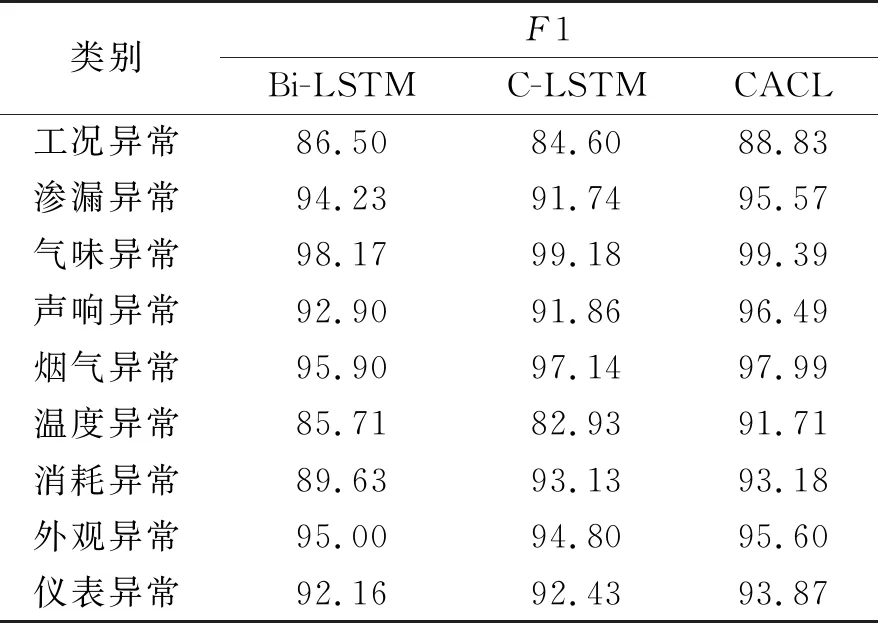
表4 3种模型在不同汽车故障问题类别上的F1值对比

图3 各项指标评估值随共现词个数变化的情况Fig.3 Change of index evaluation values with numbers of co-occurrence words
为了更好地选取优质共现词,我们对共现词的来源进行试验对比。选取汽车故障问题文本中与答案文本语义相似的词作为共现词Ⅰ型,选取答案文本中与问题文本语义相似的词作为共现词Ⅱ型,共现词Ⅰ型与共现词Ⅱ型去重之和作为共现词Ⅲ型。分别对上述3种共现词的来源通过各项指标评估值进行试验对比,同时,为了最大限度地保留所有的共现词,设置共现词个数K=25,试验结果见表5。由表5可知,共现词Ⅰ型的指标评估值都要优于其余两类共现词。这是由于共现词Ⅰ型中的词都来自问题文本本身,能够最大限度地减少关注问题文本中的非共现词,使共现词注意力矩阵更加聚焦出现共现词的这部分文本特征。因此,最终选取共现词Ⅰ型作为汽车故障问题文本的共现词来源。试验结果表明,共现词的来源也是影响汽车故障问题分类精度的因素之一。

表5 不同来源共现词的各项指标评估值试验对比的结果Table 5 Experimental comparison results of index evaluation values for co-occurrence words from different sources %
3 结 语
本文针对汽车问答社区中汽车故障问题文本复杂,局部语义特征较难提取的问题,提出一种基于问题-答案联合构建共现词注意力矩阵的问题分类方法。依托汽车问答社区中丰富的用户交互文本识别出问题文本中与之语义相似的共现词,作为问题文本的扩展语义信息,捕捉两者的内在相关性,并在这基础上构建共现词注意力矩阵,使其聚焦问题文本中与答案文本语义共现的部分。同时,利用卷积神经网络与长短时记忆网络提取问题文本的局部特征及长距离依赖特征。最后,通过词级别注意力机制,再次重点关注问题文本中贡献度较大的部分内容,去除冗余文本特征。试验结果表明,CACL模型能够有效提高汽车故障问题分类的精度。但是,本研究仍存在一些不足之处,如模型仅适用于已有答案的问题,此外模型未涉及其他领域的问答社区,未来我们将对上述不足做进一步研究。
