跨传感器异步迁移学习的室内单目无人机避障
2020-07-28薛喜地杨学博孙维超于兴虎高会军
李 湛,薛喜地,杨学博,孙维超,于兴虎,2,高会军,3
(1. 哈尔滨工业大学智能控制与系统研究所,哈尔滨 150001;2. 哈尔滨工业大学宁波智能装备研究院,宁波 315201;3. 哈尔滨工业大学机器人技术与系统国家重点实验室,哈尔滨 150001)
0 引 言
近年来,各种类型的无人机在军民领域得到了广泛的成功应用,从巡查航拍到自主协作、分布式定位建图等[1-2],都大幅提高了人们的工作效率。小型多旋翼无人机体积小、机动性高等特点使其在包括室内的各种复杂环境中执行多种任务。因此,在复杂陌生环境中实现自主智能导航,则能够充分利用其高机动性多自由度的特点,执行大量地面移动机器人无法完成的任务,如地面拥挤情况下的物资传递、快速巡查追踪等[3-4]。然而,无人机的高性能自主导航算法的研究非常具有挑战性,在环境结构不确定、光线不稳定,以及室内存在具有形态差异大、行走方向随意性高的行人等场景下,如何实现自主稳定导航一直是该领域的难点之一。
目前,基于模型的方法[5-6]是无人机自主决策导航的常用手段,但其效果过度依赖于对无人机自身动态及其所处环境的精确建模。同时,对环境和自身建模的计算量巨大,且对建模时存在的模型误差难以进行补偿。对于初次到达的陌生环境,更是需要重新进行一系列的建模工作,使得该类算法应用范围较为狭窄。
与此不同,自然界的生物则通过不断与环境进行交互,并且获得环境的反馈来强化生物的某项能力。例如动物的行走、捕猎、群体协作等能力,均是在不断试错的过程中来持续改善和提升自身的决策策略与技能。该类型学习过程的特点是无需对环境进行精确建模,仅通过与环境的不断交互来持续改进策略,即为强化学习算法[7]的核心思想。可以看出,强化学习属于端到端的学习类型,即输入一个环境状态,直接输出一个决策动作。
然而,由于强化学习应用于无人机导航决策领域的时间较短,现有研究存在的主要问题有:1)强化学习策略的迁移问题:目前强化学习最关键的环节是仿真环境,如果仿真环境里建立的几何模型和物理模型能够足够逼近现实世界,那么在仿真环境里训练好的策略直接移植到实物无人机上即可获得一致的效果。但建模误差通常难以避免,因此仿真环境训练得到的策略迁移到实物无人机上的效果并不理想。文献[8]提出一种仿真数据与现实数据相融合的方法(Generalization through simulation, GTS),将仿真环境下训练得到的卷积层与现实数据训练得到的全连接层拼接在一起,使得仿真模型与现实环境得到一定程度上的统一。但该方法仍存在策略迁移造成的性能降低,如其在仿真环境下无人机的运行轨迹比较平直,而迁移到实物之后却比较扭曲。因此,强化学习策略从仿真环境移植到实物,仍存在一系列需要开展深入研究的迁移学习问题。2)在有行人场景下采用无深度信息单目视觉感知的避障性能有待提高:单目无深度信息的摄像头具有成本低、重量轻、使用门槛低等特点,在小型无人机上应用日趋广泛,但由于无深度信息,以及行人的多样性及高动态性,使采用单目视觉实现室内有行人环境的端到端导航具有较高挑战性。现有基于单目视觉的无人机室内导航方法,大多数都是在无人的室内环境下进行实验,这也就导致该类算法在实际环境中的实用性不足。前述GTS算法是目前基于强化学习的无人机自主导航方向较为前沿的研究,但其依旧是在无行人干扰的环境下进行实验。
本文的主要贡献为:1)针对强化学习策略迁移问题,提出一种基于跨传感器迁移学习的全新框架,使得迁移到实际环境中的策略对比现有方法具有更好的泛化性能。2)为进一步提高室内有行人环境下的单目无深度信息避障性能,提出了一种异步深度神经网络结构,通过规划器与行人信息的结合,解决现有方法由于行人形态差异过大造成的策略不稳定问题,使得在不具备深度信息的情况下,仍能够实现在室内有行人时的有效、稳定避障。实验结果表明了该方法的有效性和可行性。
1 仿真环境和任务介绍
1.1 仿真环境
本文基于Cyberbotics公司研发的Webots仿真平台对无人机在室内环境下的三维自主避障任务进行仿真,强化学习系统的框图如图1所示,虚拟仿真环境如图2所示。在Webots仿真器中进行强化学习训练,涉及到其中的三个高级组件:1)场景树:在场景树里配置物理引擎的仿真步长、无人机、三维环境等信息,用以仿真“世界”的搭建;2)控制器:用以搭建无人机的底层控制以及强化学习算法,控制无人机的运动;3)监督器:用以监控仿真环境的运行,以及根据控制器在强化学习训练时发出的重置环境指令重置环境。同时,Webots仿真环境提供了一系列Python的接口函数,方便研究人员直接控制仿真环境里现有的无人机模型。本文深度强化学习所用到的深度学习框架为Pytorch框架。
在图1中,“控制器”模块和“强化学习”模块共同组成一个智能体(即无人机的“大脑”),该智能体从“无人机仿真环境”中获取环境状态观测之后,给出一个决策动作去作用于“无人机仿真环境”模块,而“无人机仿真环境”模块返回给智能体相应决策动作所产生的环境状态改变,如此构成了一个完整的强化学习经典反馈框架。为使仿真环境更加接近现实环境,本文在仿真环境搭建了一个类似室内走廊场景的虚拟环境,如图2中的(a)图和(b)图所示。仿真所用到的小型无人机如图2(c)所示,为Webots平台内置无人机模型,在仿真环境里可以通过接口函数获取电机转速、陀螺仪、加速计、气压计、GPS定位等数据,用于后续算法开发。
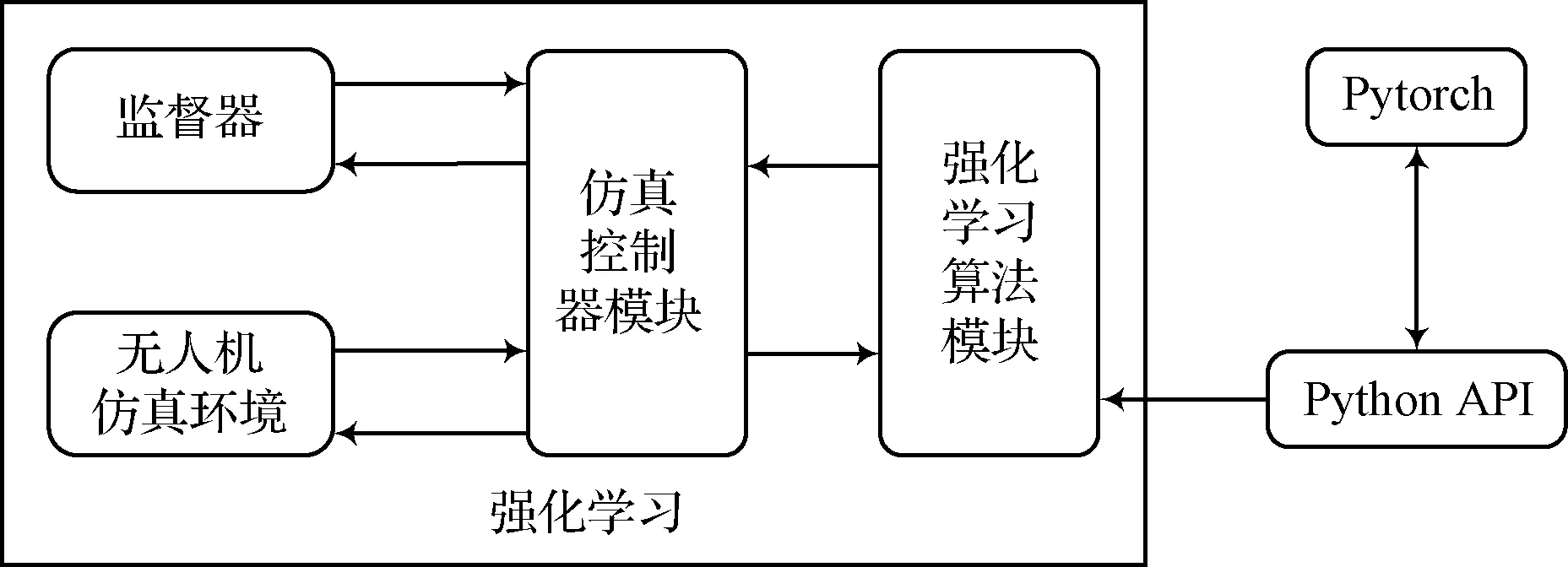
图1 强化学习系统Fig.1 Reinforcement learning system

图2 三维仿真环境Fig.2 3D simulation environment
值得注意的是,在仿真环境里并未直接采用单目相机作为传感器,而是采用激光雷达作为传感器,是因为仿真环境里采集到的相机图像不够逼近现实,将会大幅降低迁移效果。同时为方便模型搭建,本文将Webots内置的激光雷达模型直接连接于无人机上方,但将其重量参数设置为零,因此不会对飞行控制带来额外问题,如图2(c)所示。同时,为与后续实际环境下采集数据所用的RPLidar A2型激光雷达参数保持一致,这里将仿真环境里的激光雷达的刷新频率设置为15Hz。此外,为了实现从激光雷达到单目视觉的跨传感器迁移学习,本文将仿真环境和现实环境下的单线激光雷达的可视范围均限制在无人机正前方的180°范围内,从而与摄像头的视野范围基本保持一致。
1.2 任务介绍
本文所涉及的实验任务可描述为:首先,在1.1节所述的仿真环境中,结合深度强化学习方法,训练得到一个稳定的初级避障策略。无人机在仿真建筑物中自主漫游,将其最主要的目标设定为“存活”的更久。其次,在现实环境中,结合上述初级避障策略来进行跨传感器的迁移学习,使其能够更好的适应现实环境。特别地,现实环境与仿真环境的一个明显差异是现实环境中存在行人这一不确定因素,因此在迁移过程中还需要研究提高有行人场景下的避障策略的稳定性和适应能力。
2 深度强化学习和迁移学习结合的室内无人机避障
2.1 基于DDPG算法的室内无人机避障
近些年来深度强化学习算法取得了显著进展,其中“深度”指的是强化学习结合了深度神经网络,其优势在于其能够通过上百万甚至千万的参数实现强大的拟合与泛化能力。因此将强化学习的训练参数以深度神经网络的形式拟合,极大的扩宽了强化学习的应用范围。本文采用深度确定性策略梯度[9]强化学习算法(Deep deterministic policy gradient, DDPG),其网络结构如图3所示。该算法结合了Q-Learning强化学习算法和深度学习的优势,是一种基于策略梯度(Policy gradient)的学习算法。DDPG算法为离线策略(Off-policy)类型的算法,具有经验回放(Memory replay)机制,该机制类似于人类在跟外界环境交互的过程中储存起来的记忆。每次训练时随机在记忆池里抽出一定数量(Batch size)的样本来训练,类似于人类的“反省”,有了经常的“反省”,算法对于历史数据的利用将更加充分,有利于得到效果更优的策略。

图3 本文的DDPG算法网络结构示意图Fig.3 Schematic diagram of DDPG algorithm network structure for this work
DDPG网络结构上不考虑后期的优化因素,可以看作是由两个深度网络构成,其中一个是表演者(Actor),从环境获取状态信息s,输出执行动作a;另一个是评论者(Critic),其结合环境的状态信息s以及表演者输出的动作a,输出一个评分。因此两个网络构成了对抗竞争的关系,其中表演者的目标是要最大化评论者的评分,评论者的目标时最小化自己给出评分的变化率(旨在使其策略稳定下来)。因此当DDPG算法训练收敛之时,表演者可以针对当前环境给出一个比较优秀的动作,而评论者也可以给出一个比较准确的评分。因此表演者网络和评论者网络的代价函数如式(1)所示。其中la和lc分别为表演者网络和评论者网络的代价函数,表演者最大化评论者的评分q,也就是要最小化-q。表演者最小化状态值函数的变化量。
(1)
DDPG算法同一般强化学习算法一样,具有状态空间(State space)、动作空间(Action space)、回报函数(Reward function)三大要素,而这三大要素随着不同任务而变化。本文所设计的三要素如下。
1) 状态空间:本文的强化学习算法在仿真环境里进行训练,利用单线激光雷达作为环境感知传感器,因此状态空间定义为单线激光雷达的一系列深度值数组,本文对其180°范围内的数据进行降采样,每隔9°采样一次,组成一个长度为20的数组。此时激光雷达数据储存格式如式(2)所示。其中s表示状态空间,D表示新的激光雷达数据。li表示表示降采样后的第i个激光雷达射线对应的深度值。
s=D=[l1,l2,…,l18,l19,l20]
(2)
动作空间:DDPG强化学习策略可以输出连续的动作空间,而本文设定没有全局定位信息,因此将动作空间a分解为无人机的线速度v和偏航角速度w,如式(3)所示。值得注意的是,神经网络往往比较适合处理-1~1之间的数据,因此在这里将无人机的线速度和角速度均映射到[-1, 1]区间。
a=[v,w]
(3)

(4)
(5)
2.2 跨传感器强化学习策略的迁移
本文2.1节详细叙述了无人机使用单线激光雷达作为传感器在仿真环境下训练得到稳定的初级避障策略,本节进一步研究从只使用激光雷达传感器的初级避障策略,到只使用单目视觉的实物无人机避障策略的跨传感器迁移学习方法。整体算法框架如图4所示

图4 整体算法结构图Fig.4 The overall algorithm structure diagram of this work
迁移学习包含众多类型的算法,其中比较实用的一种类型是模仿学习[10-13],其核心思想为在迁移学习新策略过程中,存在一个专家策略来不断地指导新策略,在迁移学习训练的过程中,目标是缩小新策略与专家策略之间的差距。因此,模仿学习属于有监督学习。
专家策略的获取方法有多种,例如监督学习、半监督学习、无监督学习等等。本文研究的核心问题在于将仿真环境训练得到的策略迁移到实际环境当中,因此采用2.1节训练得到的初级避障策略作为专家策略,属于无监督学习类型。
如图5所示,在进行迁移学习训练之前,需要用摄像头以及激光雷达传感器在如图6所示的现实环境中采集数据,并利用上述专家策略来对数据集进行自动标注。在采集数据集过程中,摄像头图片数据与单线激光雷达数据在每个程序周期里进行对齐及同步,实现两种传感器数据的逐帧绑定。

图6 现实世界环境示意图Fig.6 Schematic of the real world environment

图5 激光雷达和摄像头安装结构示意图Fig.5 Lidar and camera fixed structure diagram
值得注意的是,激光雷达的刷新频率为15 Hz,因此将摄像头的图片采样周期也强制同步至15 Hz。从另一个角度分析,如采样频率过高,采集到的数据在短时间内的相似度很高,则会占用过多的计算资源且意义不大。
采集得到的数据集格式为一系列(I,L)数据对,其中I为图片数据,L为激光雷达数据。图片大小为640×480,格式为RGB。采集数据完毕之后,对数据集进行离线处理。利用2.1节中训练得到的初级避障策略作为专家策略,输入数据集中的激光雷达数据,专家策略输出一系列决策动作a来作为图片数据集的标签,这也就实现了迁移学习过程中的自动标注。处理后的新数据集格式为(I,B),其中B为专家策略输出的一系列决策动作a,用来当作图片数据集的标签。
最后,迁移学习利用上述离线处理得到的新数据集来训练深度网络,也就实现了跨传感器强化学习策略的迁移学习。深度神经网络采用的是性能优良的Resnet18深度神经网络,同时,Pytorch深度学习框架提供了Resnet18网络的部署实现模板,使用非常方便。因此,本文在其模板网络结构后添加了规格为(256, 128, 16)的三层全连接层,网络最终有两个输出,分别是无人机的给定线速度v和给定偏航角速度w。
在训练时,网络的一个批次数据大小采用的是128,代价函数采用经典的均方误差,如式(7)所示。其中l为网络的整体代价函数,lv为回归线速度v部分的子代价函数,lw为回归给定偏航角速度w部分的子代价函数,两个子代价函数的具体表达式如式(7)和(8)所示。
l=lv+lw
(6)
(7)
(8)
3 基于异步深度网络的有行人环境优化
本文第2节提供了本次工作所设计的跨传感器迁移学习的详细内容,实现了在室内无人环境下的无人机自主导航避障。然而,室内经常会有形态差异大、行走方向随意性大的行人群体存在,这将导致2.2节所述方法得到的避障策略在有行人时表现出与行人交互不友好、路径不稳定等问题。
导致上述迁移学习策略在有行人场景下表现不佳的原因可以追溯到以下两点:1)Resnet18网络在有行人场景下的泛化能力不足,源自于其网络结构较为简单所带来的弊端;2)从上述迁移学习拟合得到的策略可以看出,迁移学习得到的策略依旧为端到端决策类型的策略,而端到端策略的优势在于研究人员不必去详细研究其计算过程,只需关心该策略的输入和输出即可,输入一张图片即可输出一个决策动作。但同时也带来一个很严重的问题,即输入一张带有行人的原始图片数据,神经网络的“注意力”可能会更多地聚焦在室内的建筑物环境上,而在行人身上投入较少的“注意力”,这也会导致无人机在有行人场景下与行人交互不友好,甚至为了保持与建筑物的安全距离而撞到行人。
因此,本文提出一种基于异步深度网络的神经网络结构来改善有行人情况下的无人机避障性能,该异步网络结构如图7所示。从图中可以看出,异步网络结构具有两个分支,左侧分支为Resnet8深度网络,右侧分支为YOLO v3-tiny深度网络[14-16],两个分支网络的输出最终汇聚到一起,经过四个全连接隐藏层,最终输出的决策动作分别是无人机的给定线速度v和给定偏航角速度w。其中“异步”指的是,为了提高整个网络在前向传播时的计算速度,本文将resnet18和YOLO v3-tiny两个分支分别放置在两个子线程下进行运算,最终两个线程的计算结果在主线程上汇总,再将汇总起来的计算结果经过四个全连接隐藏层的计算后输出结果。
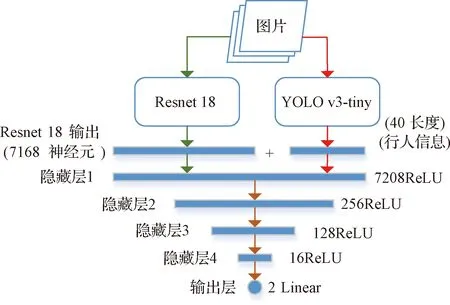
图7 异步网络结构示意图Fig.7 Schematic diagram of asynchronous network
YOLO v3系列网络借鉴了残差网络结构[17-19],形成层数更深的神经网络,有着更强大的拟合能力。同时其采用多尺度检测的图像金字塔[20-21]机制,提升了预测框的平均重合率(mAP)以及对体积较小物体的检测性能。而YOLO v3-tiny为YOLO v3网络的简化版,牺牲部分预测准确率以及回归精度来很大程度上提升网络的前向传播速度。YOLOv3-tiny的前向传播速度甚至可以达到YOLO v3网络的10倍左右,易于在轻量级移动设备上使用。
该网络结构的特点是利用YOLO v3-tiny网络卓越的分类能力,将环境中的行人信息提取出来,再与Resnet18的结构融合后进行综合决策,这也解决了本节开头所述的两大问题。值得注意的是,本文所使用的YOLO v3-tiny网络为利用Coco数据集进行预训练过的网络,因此可以直接使用YOLO v3-tiny网络来提取行人信息。
其中YOLO v3-tiny网络输出行人预测向量信息(对于每个行人输出一个预测框),该向量格式如式(9)所示,pi表示第i个行人的图像中预测框的位置信息,其中xti,yti表示第i个行人预测框在图像中的左上角坐标,同样xbi,ybi表示第i个行人预测框在图像中的右下角坐标。最终行人向量信息如式(10)所示,其中pi表示第i个行人的预测框信息。这里取行人个数上限为10个人,因为对于一般情况室内同一视野内同时近距离出现超过10个人的可能性非常小,换而言之,若近距离人数超过10个则当前环境非常拥挤,无人机几乎无法在这种场景下飞行。若当前视野内人数不足10个人时,则该行人向量末端用0补齐。同样地,该异步网络训练时的代价函数等配置与2.2节所述一致。
pi=(xti,yti,xbi,ybi)
(9)
f=(p1,p2,…,p9,p10)
(10)
4 实验结果及分析
4.1 仿真环境下强化学习训练结果分析
强化学习训练的回报函数曲线如图8所示,从图中可以看出无人机在仿真环境中随着训练时间的增加,其与环境交互所获得的回报也越来越多,最终趋于平稳,在宏观上表现为无人机稳定在建筑物内无碰撞飞行,这也从正面验证了本文2.1节所设计回报函数的合理性。硬件设备为GTX 1080Ti GPU、i7 8700 K CPU,训练所花费时长约为3.7 h。

图8 回报函数曲线Fig.8 Reward function data
4.2 跨传感器迁移学习训练结果分析
网络的拟合能力对比分析:跨传感器迁移学习、采用分段动态学习率,下降曲线如图9(a)曲线所示。动态学习率使得网络梯度在每个训练阶段都以相对比较合适的下降速度来更新网络参数,防止网络下降过慢或者梯度爆炸。训练所用的硬件设备与4.1节所述一致,数据集总量为100,000数据样本,将整个数据集训练200次总耗时约为20 h。从图9中左侧图片的曲线(“*”形状)可以看出,随着训练的进行,损失函数不断收敛,最终趋于0附近。这表明该异步网络结构有足够的能力拟合有行人环境下的数据集。而单独Resnet18的损失函数下降曲线如图9左侧图片中的蓝色曲线(“-”形状)所示,可以看出单独Resnet18网络训练该数据集最终也能逐渐趋于收敛,但其拟合精度的瓶颈比较明显,最终的拟合精度要比异步深度网络低。
网络的前向传播速度的对比分析:图9(b)表示在几次室内导航任务中深度网络的平均输出帧率,其中曲线(“*”形状)表示双线程运行异步网络的输出帧率曲线变化,曲线(“-”形状)表示单线程运行异步网络的输出帧率随时间变化曲线。综合两条曲线可以明显看出基于双线程运行的帧率大致为单线程的2倍。这意味着双线程运行的网络前向传播速度有显著提高。本次实验也在NVidia公司的TX2单板计算机上测试了该异步网络的平均帧率,其结果是25.7 Hz,这意味着在机载计算环境中亦可以保证实时性。
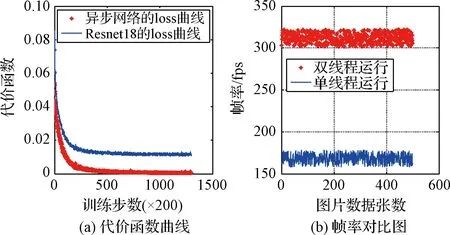
图9 代价函数下降曲线及网络帧率对比图Fig.9 Cost function decline curve and network frame rate comparison chart
异步网络在室内有行人实际场景中的泛化能力分析:为了检验该异步深度网络在有行人环境下的泛化能力,在实际有行人的室内环境中进行了飞行测试,部分飞行轨迹图如图10所示。其中实线轨迹是本次研究所设计算法的无人机飞行轨迹,虚线轨迹是GTS算法的在实物上复现的飞行轨迹。通过对比轨迹可以发现实线轨迹几乎是全程在以最大安全裕度在飞行,同时在有行人的情况下也能够非常稳定和平滑度轨迹避开行人。而虚线轨迹相对比较扭曲和不平滑,最终虚线曲线在“行人”文字标记处碰撞到行人而导致任务结束。从而综合以上可以得出,本文所设计的异步网络在有行人环境下具有较好的泛化能力和轨迹稳定性。

图10 无人机飞行轨迹对比图Fig.10 Comparison chart of UAV flight trajectory
各算法无人机飞行测试中的存活时间对比分析:如图11所示,本次飞行存活测试分别测试了基本DDPG算法、GTS算法、单Resnet18网络、异步网络在上述条件下的性能。为了与目前较为有代表性的算法性能做对比,本文分别在室内有行人、室内无行人、室内光线不稳定、陌生室内等几种环境下对无人机进行飞行存活时长测试。这里“存活时长”定义为从无人机起飞开始计时,在室内漫游飞行至无人机发生碰撞为止所花费的总时长。值得注意的是,为了使得各个算法更有可对比性,本文在做该项测试时尽量保证了各算法的基本条件一致,主要包括室内行人数量、光线、硬件设备、计算平台等主要因素。对于某一个算法在某一个场景下分别测试多次,最终取平均结果作为最终的参考存活时长。

图11 无人机存活时间对比图Fig.11 Comparison chart of UAV survival time
从图11中可以看出,基本DDPG算法的性能最弱,这是由于其仿真环境里的视觉部分迁移到现实世界效果不佳。同时可以看出,单Resnet18网络与GTS算法的性能几乎持平,而基于异步网络结构的算法性能远超另外三种算法,这也说明了异步网络结构的算法有着更好的稳定性和更友好的行人交互性能。
值得注意的是,这里的基础DDPG算法指的是在仿真环境里直接用单目视觉的图片数据作为状态输入,DDPG算法直接输出决策动作,最后将训练收敛的策略直接移植到实物上进行测试。
5 结 论
本文首先在Webots仿真环境训练得到一个稳定的仅使用虚拟激光雷达作为传感器的初级避障策略;其次通过将真实激光雷达与单目摄像头图像数据逐帧绑定来采集现实环境中的数据集,利用上述初级避障策略当作专家策略,实现从虚拟激光雷达到现实单目视觉的跨传感器迁移学习;最后针对室内有行人的场景设计了一种基于Resnet18网络和YOLO v3-tiny网络相结合的异步深度神经网络结构,改善了单Resnet18深度网络进行迁移学习时,在有行人室内环境下的避障效果,同时基于双线程的机制极大加速了深度网络的前向传播速度。仿真及实验结果表明,本文所提出基于跨传感器异步迁移学习方法能够在光线不稳定、陌生、有行人的室内环境下,相对于现有工作有着泛化能力更强、轨迹裕度更大、更稳定的优点。
