基于Selenium框架的电力系统数据爬取应用研究
2020-07-27余凯汤渊黎海震夏伟轩
余凯 汤渊 黎海震 夏伟轩
摘 要:为了从大量数据中快速,高效地提取出有用的数据以方便数据分析。利用Python语言中的Selenium库是目前广泛应用于爬虫设计的一种方法,以其代码精简,拾取方便且效率较高等特点,应用于绝大部分企业的数据挖掘平台中。通过应用Python和Selenium的方法实现了数据的提取,并通过使用异常捕抓、函数封装,统一调用实现了数据的导出和上传的自动化,结果表明使用Selenium爬虫会优于网页爬虫。
关键词:Selenium;异常处理;爬虫;电力系统
中图分类号:TP311.5 文献标识码:A 文章编号:2096-4706(2020)05-0026-04
Research on Application of Power System Data Crawler
Based on Selenium Framework
YU Kai,TANG Yuan,LI Haizhen,XIA Weixuan
(Power Supply Service Center of Dongguan Power Supply Bureau of Guangdong Power Grid Company,Dongguan 523000,China)
Abstract:In order to extract useful data from a large number of data quickly and efficiently to facilitate data analysis. Using the Selenium library in Python language is a method widely used in crawler design at present. It is used in the data mining platform of most enterprises because of its simple code,convenient picking and high efficiency. The method of Python and Selenium is used to extract the data,and the automation of data export and upload is realized by using exception capture,function encapsulation and unified call. The results show that Selenium crawler is better than web crawler.
Keywords:Selenium;abnormal jump catch;web crawler;electric system
0 引 言
随着大数据时代的发展,越来越多的企业意识到了数据的重要性,如何从数以亿计的信息中提取出自己想要的信息,已经成为的大数据时代的必修课,爬虫技术也应运而生,其通过设计规则,自我驱动抓取网页信息的特点,做到了在大大减少人力消耗的前提下,提取出企业所要用的数据。通过网页抓取后台数据,快速解析网页代码达到获取网页元素信息和数据包的方式,在无需破坏或介入数据库的前提下,直接从系统和頁面取得想要的信息。为各类分析挖掘提供数据源支持。
通过爬虫获取的各类信息纷杂,对爬虫数据统一进行必要的分析与预处理进行数据上传是适应业务场景的必要环节。很多企业也通过其特有的方式构建了其处理信息的平台,将爬虫接入这些信息平台,使数据能够通过后台直观地展现在其他应用软件上,以此开展更多的业务场景是为企业创造数据竞争力,帮助企业适应大数据时代的重要环节,因此,如何智能化地利用科技手段实现爬虫与信息平台的互通十分关键。
1 业务分析
在电网企业电力营销日常工作中,需要在营销系统、计量系统以及其管理系统之间往返使用特定数据索引进行数据提取、分析和整理后上传到其他系统进行分析,这部分工作往往重复性高、操作流程长。为避免此类工作耗费大量时间和精力,使用爬虫技术进行跨平台跨系统之间的数据提取和整理,实现电力系统数据整合上传的自动化操作。
如整合当月电量数据进行分析的工作,需要对供售电量、电量排名、电量构成、行业电量数据进行导出及上传,需要登录到电力系统,使用爬虫导出当月每一天的供售电量、电量排名、电量构成、行业电量等在内的19个电力数据。
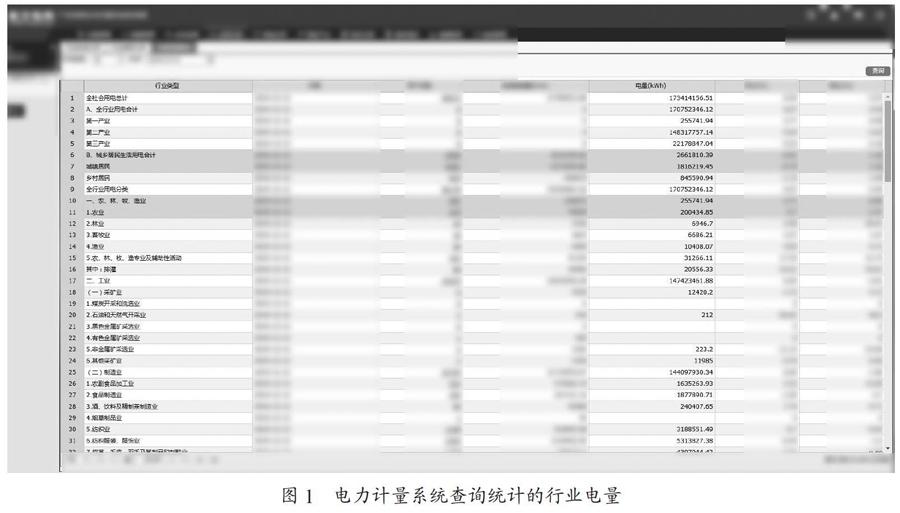
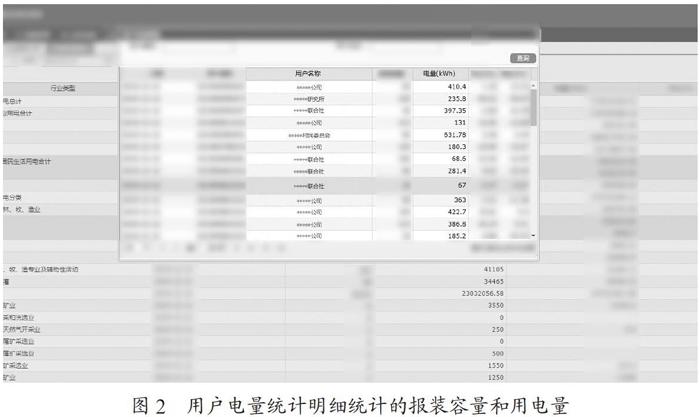
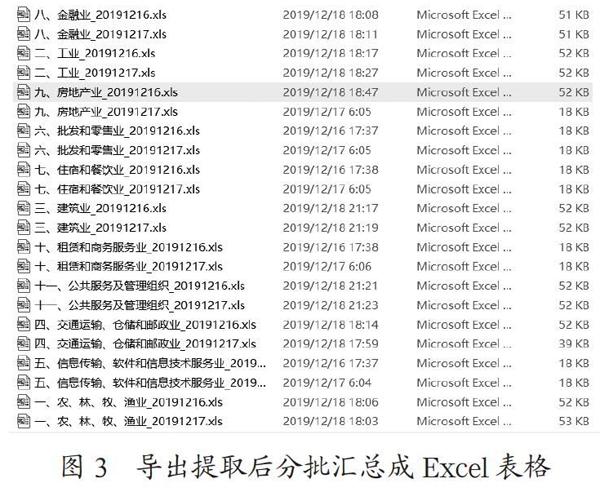
由图1、图2所示,对电力系统分析,发现电力系统主要由查询部分、数据部分以及功能按钮组成,以导出各行业售电量为例,要爬取该数据,可以通过在查询部分中点击查询按钮,再点击行数据内数量的超链接,就可以预览数据部分,最后点击功能按钮中的导出按键既可以将数据导出为如图3所示的Excel表格,以上的步骤与Selenium爬虫不谋而合,可以通过Selenium模拟用户进行查询、点击以及导出三个行为,实现数据的自动导出。
2 Selenium介绍
2.1 Selenium原理
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7,8,9,10,11)、Mozilla Firefox、Safari,Google Chrome、Opera等,Selenium通过对浏览器的驱动,对对象元素进行控制,同时Selenium支持多种开发语言,比如Java、C和Python,通常会使用Python+Selenium+ Chrome/Firefox的组合来解决现有的网络爬虫登录以及绕过JS和滑块问题,目前Chrome和Firefox已经完全替代了之前的PhantomJS无界面浏览器,能完成所有操作又节省内存。这样Chrome/Firefox负责渲染解析JavaScript,Selenium负责驱动浏览器和Python进行对接,Python负责做后期的处理,三者构成一个完整的爬虫结构。
这样的结构搭配,可以实现很多的操作,比如填写表单、点击链接、鼠标拖拽,鼠标点击等,为爬虫操作带来极大的方便,能解决一系列人工操作的问题,为网络爬虫通过验证登录信息提供了方便,模拟浏览器正常流程图,如圖4所示。
2.2 Selenium相关API
安装Selenium命令:pip install selenium,安装核心API后可以进行多种操作,比如窗口切换、表达操作鼠标操作等为实现模拟操作环境提供接口。在电力系统中,主要用到了5个API,分别是核心驱动模块,访问网址模块,元素定位方法,网页延时模块,退出浏览器模块,核心驱动模块可以配合访问网址来启动Chrome浏览器并登录电力系统,元素定位方法可以定位需要模拟点击或者输入的位置,以及定位网页中点击按钮所在框架的位置,定位位置后通过模拟用户点击导出按钮实现数据的提取,而显式等待和隐式等待可以等待一段时间再执行下一个命令,解决由于网速等原因造成的页面卡顿而无法定位元素位置,以及点击导致的运行出错问题,在导出完所需的所有数据之后可以通过退出浏览器模块退出,通过以上5个API可以对电力系统实现一个效率高、稳定性强的Selenium爬虫。
3 具体实现
3.1 架构设置
一个优秀的爬虫应该具有:明确的爬取目标、高效的爬取策略、有效的前置后后置处理以及快速的运行速度,针对4个要求,本节设计了符合“计量自动化系统”的爬虫架构,共4个模块,分别为用户基本行为模块、数据导出模块、数据处理模块、数据存储模块,总结如下:
用户基本行为模块负责完善点击,查找元素等在Selenium中的基本行为,通过捕抓异常的方式让代码不会因为一次页面点击失败或者导出超时等原因而停止后续的操作,使得代码具有强有力的生命力,在电力系统中,该模块可以保证数据的正常导出,是下面3个模块的基础,保证了Selenium爬虫的稳定性,点击模块的流程图如图5所示。
数据导出模块负责进入到电力系统中导出按钮所对应的框架中,并点击导出数据按钮,数据处理模块负责将导出的Excel按照用户的需求挑选出所需的行或者列,保持与后续数据上传的接口与数据列名的一致性,并剔除不需要的数据,减少内存的占用,数据存储模块则是将处理好的Excel以前一天的时间命名,并保存到对应的文件夹中。
以上三个步骤配合用户基本行为模块可以实现完整的电力系统的数据导出,最终得到包含各行业售电量情况、东莞电量分布情况在内的19个Excel,以各行业售电量情况为例。流程图和结果如图6、图7所示。
最后为了使代码更整洁高效,将每一个文件的导出代码封装成一个函数,再将函数放到类下面,建立main.py文件,在文件内进行类的实例化和类函数的调用,并通过建立定时任务的方式,使得Selenium爬虫能自动导出所需要的文件。
3.2 结果对比
由图8、图9可以发现,通过Selenium爬虫的方式模拟人工进行数据导出的结果在数据的排版上会优于网页爬虫,同时也可以保持数据编码与原数据一致,并且使用Selenium也可以省略网页分析,正则表达式提取等其他爬虫所需结合的提取方式,减少了运行所需的时间,提高了效率。
4 结 论
通过Python和Selenium设计了一套符合电力系统网页特点的爬取、上传的架构,将用户行为都封装成了函数的形式,通过调用这些简单的用户行为函数实现每一个文件的导出,并将这些函数定义为类,在main.py文件中可以通过类来调用每一个函数,实现每一个文件的导出,在有需要的时候也可以单独调用类函数导出数据,经过多次实验,以导出的方式提取数据,结果将优于使用网页爬虫,并且在导出数据时可以关闭屏幕。
参考文献:
[1] 安子建.基于Scrapy框架的网络爬虫实现与数据抓取分析 [D].长春:吉林大学,2017.
[2] 樊涛,赵征,刘敏娟.基于Selenium的网络爬虫分析与实现 [J].电脑编程技巧与维护,2019(9):155-156+170.
[3] 花君林.基于Selenium的Python网络爬虫的实现 [J].电脑编程技巧与维护,2017(15):30-31+36.
[4] 杜彬.基于Selenium的定向网络爬虫设计与实现 [J].金融科技时代,2016(7):35-39.
[5] 刘洋,田儒贤,唐兰文.基于WebDriver技术的定向网络爬虫研究 [J].电脑知识与技术,2020,16(3):34-36.
[6] 陈清.基于Python的网站爬虫应用研究 [J].通讯世界,2020,27(1):202-203.
[7] 楼姗姗.大数据环境下基于python的网络爬虫技术探讨 [J].决策探索(中),2019(11):92.
[8] 朱梓熙,吴文庆.一种智能自动获取信息的方法——以获取养老机构信息为例 [J].科技创新发展战略研究,2020,4(1):47-51.
[9] 庄文龙,陈惠娟.基于Selenium2的自动化测试应用 [J].福建电脑,2019,35(8):89-91.
[10] 李瑞,徐家喜.基于selenium2的自动化测试系统的设计和实现 [J].福建电脑,2018,34(7):26-27+2.
[11] 冯晶晶.基于Selenium的Web自动化测试框架的设计与实现 [D].北京:北京工业大学,2018.
[12] 刘瑾.Web系统Selenium WebDriver自动化测试框架搭建 [J].电子技术与软件工程,2017(21):171-172.
作者简介:余凯(1978-),男,汉族,广东湛江人,电力工程师,本科,研究方向:电力营销。
