基于迭代寻优策略合同网协议的任务分配算法
2020-07-27姚亚宁杨风暴吉琳娜吕红亮白永强
姚亚宁,杨风暴,吉琳娜,吕红亮,白永强
(中北大学信息与通信工程学院,山西 太原 030051)
“体系韧性”是未来高动态强对抗战场态势环境下完成使命的主要保证。现代战争场景复杂多变,战术行动形式多样,但共同的特点是反应敏捷,决策灵活。当作战体系中作战单元被摧毁或作战单元间通信链路中断时,需要快速对任务处理流程进行重构,提升极端情况下的任务保障能力,实现弹性可伸缩的保障服务。完备的集中式指挥作战体系由多个异构的作战节点和指挥中心构成,因此,作战体系的重构问题可转化为多智能体系统(Multi-Agent System,MAS)满足快速性条件下的任务分配问题。
作战体系重构的核心是在有限的时间内实现合理的任务迁移和分配,合同网协议作为一种研究多智能体间任务分配的算法,其收敛性和求解质量已被广泛认同[1]。张海俊[2]等根据参考阈值响应模型引入信任度参数,提出了动态合同网协议,在招标过程阶段直接向信任度高的智能体进行投标,减轻了系统通信压力,提升了其处理大规模任务集的综合性能。在此基础上,李明[3]等提出了再招标的策略,使信任度高但重载的智能体能将标书再次分发,避免因拒标而导致信任度降低的情况,使其下次投标不受影响。姜继娇[4]等通过限制智能体接收标书的数目、提出任务优先度优化任务分配模型,缩短协商过程的通信次数。杨影[5]等以无人战斗机为研究对象,将复杂自适应系统理论与合同网协议结合,构造损失函数和约束条件,建立了合作任务分配模型,通过求解一个非线性规划问题得到任务分配方案,仿真结果表明该算法可以实现全局优化。
上述研究重点多集中于改善算法中的决策过程,未考虑决策依据的真实性对决策结果的影响,即忽略了协作过程中智能体之间存在的欺骗行为。多智能体协作过程中,自身利益必然是一个理性智能体的重要目标[6]。全局利益和自身利益冲突时,智能体可能做出欺骗举动来最大化自身利益。针对这个问题,本文以经典合同网协议为研究基础,提出一种迭代寻优策略,强迫智能体的投标信息在迭代过程中逼近真实数据,所有智能体连续两次投标信息完全一致后算法收敛,得到欺骗行为下的最优任务分配方案。
1 合同网协议框架
经典合同网协议由Reid G.Smith[7]于1980年提出的,是一种适用于多智能体间任务分配的算法。算法中拍卖双方智能体分为投标者和管理者,协商过程模拟交易流程,其流程可分为如下四个阶段。
1)招标:管理者初始化标书,以广播的形式向各投标者发送招标信息;
2)投标:投标者接收标书后根据自身情况投标或拒标;
3)评估:管理者根据投标信息选出最佳投标者,向其发送中标讯息,并拒绝其他投标者标书;
4)通告:管理者广播合同签订情况。
合同网协议流程可用UML顺序图描述如图1。
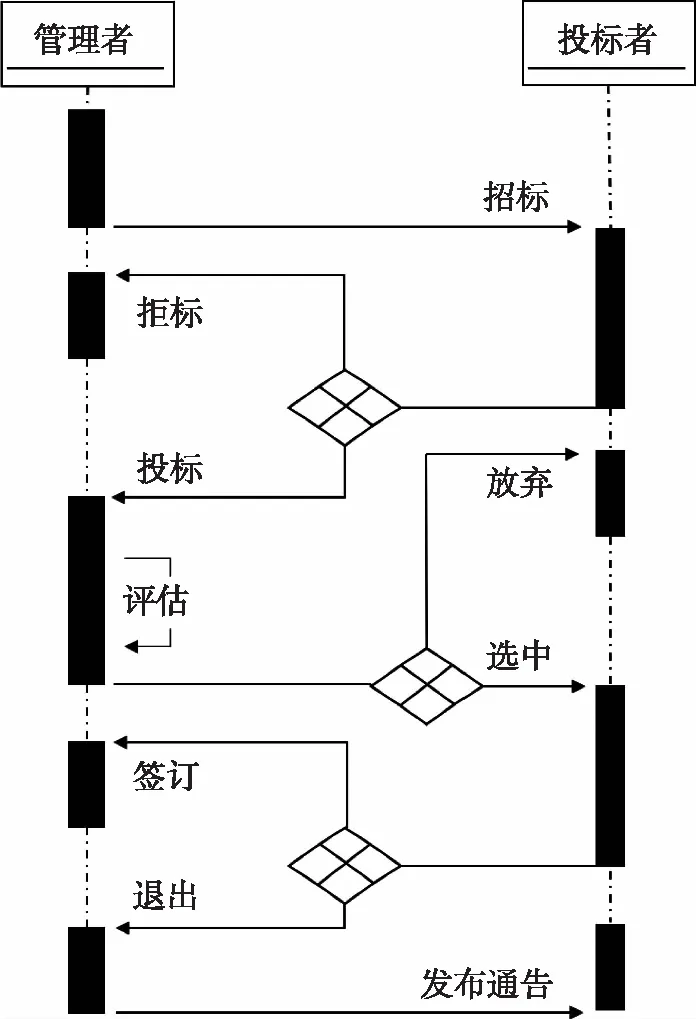
图1 合同网协议UML时序图
2 基于迭代寻优策略合同网协议的任务分配算法
2.1 任务描述
经典合同网协议中,中标的是单一的个体,导致中标的智能体承担庞杂的任务造成过载情况。假设待迁移任务满足文献[8]中部分任务分解原则,即待分解任务本身具有可分解的多层抽象结构;分解之后的子任务应尽可能保持独立。基于任务分解的策略,将复杂的任务分解为多个具有高并行度的子任务,将其分发到多个智能体,使体系中负载更加均衡。
本文使用二元组
任务需求向量T定义为式(1),Tq表示智能体承担第q个子任务需要的能力大小,值越大,代表此任务需求越高。
(1)
任务带来的负载向量L定义为
(2)
式中,Lq表示承担第q个子任务会带来的负载,值越大代表带来负载越重。
2.2 智能体描述
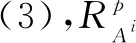
(3)
(4)
智能体信任度向量α定义为式(5),αi表示指挥中心对Ai的信任度,表征Ai过去完成任务的情况。信任度越高,表示智能体过去完成任务情况越好。
(5)
任务完成后,根据完成情况根据式(6)更新信任度。
(6)
式中,αaward和αpenalty分别为奖惩因子,都为常数,通常满足αaward≪αpenalty。
2.3 智能体欺骗行为描述
Alision R.Panission[9]等将智能体的欺骗行为分为三类:撒谎、废话、诡计。撒谎是智能体对某事的虚假陈述,目的是使其他智能体得到与事实相反的结论。废话是指智能体通信过程中通过释放大量冗余数据,使其他智能体无法得到需要的有效信息。诡计是一个更复杂的过程,通过诱导其他智能体利用先验知识和推理能力自发得出某些错误结论,实现其更深层次的阴谋。
本文研究的重点是智能体的撒谎行为。在集中式作战体系中,某智能体在执行作战任务时被敌摧毁,侦察单元检查其负载的任务信息后上传到指挥中心。在各智能体数据未知的情况下,指挥中心通过与体系中其他智能体通信得到各项数据,在一定时间内将此任务迁移到匹配度最高的智能体,但承担任务意味着自身负载加重,智能体可能在通信过程中通过撒谎行为弱化自身,逃避任务。合同网协议下,具体的撒谎行为描述为:指挥中心将任务需求信息广播,若智能体自身状态能够承担任务,不会拒标(所有智能体拒标,任务处理流程将无法完成重构,体系面临崩溃的危险)。收到指挥中心的招标信息后,智能体以高于任务需求、低于自身能力之间的虚假数据投标,期望降低被选中的概率,指挥中心根据虚假数据选出的最优智能体可能与实际情况不符。本文假定欺骗行为的投标公式如下:

(7)

2.4 作战联盟组建
假定体系中智能体数目为N。指挥中心收到侦察单元的消息后,首先对将任务进行分解。然后以子任务需求作为招标信息向体系中所有智能体进行初次招标,筛选出能够承担子任务的n个智能体,组建作战联盟,为后续子任务分配奠定基础。智能体收到招标信息后,判断自身能力和负载状况,若满足式(8)条件,则向指挥中心投标,否则拒标。
(8)
上式意义为,智能体投标的条件是任一子任务下智能体对应的能力值不能低于任务需求,且承担任务后自身不会超载。
2.5 评价函数
指挥中心收到投标后,通过式(9)对智能体进行评价。
(9)
2.6 迭代寻优策略
在作战联盟组建完毕的基础上,迭代寻优策略表述为:指挥中心以智能体Ai投标信息中的能力值作为任务需求的招标信息,再次向其招标。当指挥中心再次招标时,由于存在全体拒标导致任务无法迁移的危险,智能体无法拒标,投标信息更新为高于此次招标数据低于真实数据的信息。随迭代进行,指挥中心得到的信息逐渐逼近智能体真实数据,直到某次指挥中心得到智能体真实信息。通过对比连续两次所有智能体投标信息,判定算法收敛(收敛标识con_var=1),通过式(9)计算出每个子任务对应智能体综合评价值,排序后得到最符合当前任务的智能体,据此生成全局最优的任务分配方案。算法收敛标识con_var计算公式由式(10)给出。

(10)

算法UML时序图如图2所示。
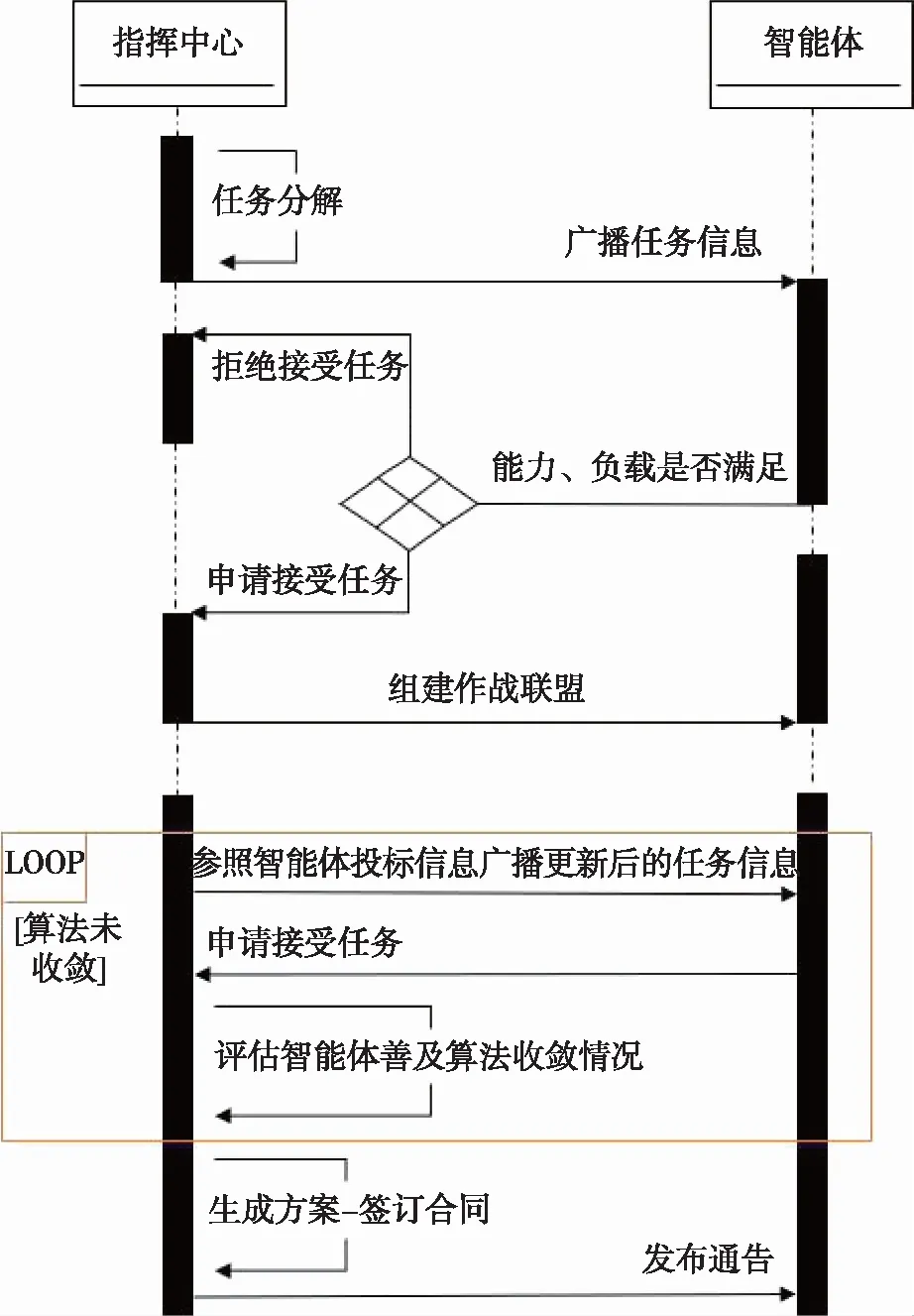
图2 基于改进合同网协议的任务分配算法UML时序图
3 算例分析
假定某作战体系由指挥中心和十一个智能体构成。作战过程中某智能体被摧毁,指挥中心需在一定时间内对任务迁移分配,将体系中原有任务流程重构。为简化分析,考虑智能体的欺骗行为为谎报能力的情况。基于Netlogo对体系建模,其包含元素如图3所示。

图3 作战体系元素示意图
图3中飞机区域为指挥中心,黄色三角为被摧毁智能体,蓝色三角为体系中正常运作的智能体,黑色三角为侦察单元。表1数据为体系中智能体的真实能力值,行表示不同的智能体,列表示每个智能体不同类型的能力。表2数据为各智能体与能力对应的五种不同类型的真实负载状况,行表示不同的智能体,列表示每个智能体不同类型的负载状况。由两表数据可知,A1-A9为蓝色智能体,A10为体系中的侦察单元,不接受任务的迁移。

表1 智能体真实能力值表

表2 智能体真实负载表
基于FIPA-ACL(Foundation For Intelli-gent Physical Agents-Agent Communacation Language)通信语言描述智能体间通信流程,算法的仿真过程如图4。图4中左半部分为体系模型:白色三角表示被摧毁的智能体,由黄色变为白色表示任务分配方案产生;粉色三角表示最优分配方案生成后即将承担任务的智能体;黑色三角依然为侦察单元。图中右侧监视窗口为各子任务迭代寻优的过程,air1_best到air_5best图中曲线表示由式(9)得到的对应子任务T1到T5的最优智能体评价值的迭代过程(初始化αi=0.5,λ1=λ2=0.5);con_var图中的曲线表示迭代过程收敛标识,曲线值为1代表前后两次迭代各子任务最优智能体信息一致,算法收敛,寻得全局最优解。

图4 Netlogo仿真过程
查询通信信息将通信数据绘制成折线图。图5中,最优智能体的评价值逐渐增大后稳定,表示有智能体隐藏了真实能力,但随迭代过程的进行,其投标信息逐渐逼近真实信息,最后以真实信息进行投标。第五次迭代、第六次迭代和真实信息重合,表示第五次迭代后已经得到了符合实际情况的最优任务分配方案。图6为智能体A1的投标信息中能力值的变化,各项投标能力值随迭代进行逐渐上升,第五次迭代后,投标信息不再变化,与真实能力值相符。
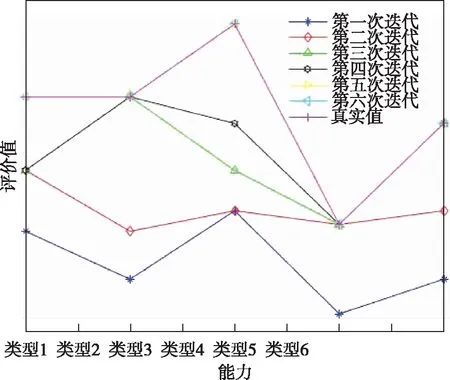
图5 子任务迭代寻优

图6 A1投标能力迭代
最优的任务分配方案在迭代过程不断更新。变化过程如图7所示。

图7 分配方案迭代过程
第一次智能体投标后,指挥中心依据收到的信息计算各智能体综合评价值,产生的分配方案为A9承担子任务T1,A6承担子任务T2和子任务T3,A1承担子任务T4,A5承担子任务T5,此时为欺骗行为下经典合同网协议生成的分配方案。五次迭代后,算法寻得符合实际情况的最优解,最终分配方案为A2、A6、A6、A5、A1依次承担五个子任务。
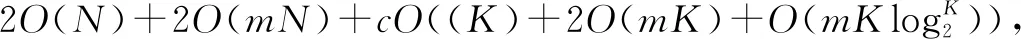
4 结束语
本文以战场态势重构中任务分配问题为研究背景,对多智能体协作过程中的欺骗行为进行了分析,以经典合同网协议为基础提出了一种欺骗行为下的任务分配算法。所提算法能在有限的迭代次数内收敛,得到与真实情况一致的全局最优分配方案。不足之处在于本文没有考虑更复杂的欺骗行为,下一步工作将从此处开展。
