关于迁移学习中的负迁移方向研究
2020-07-27李永盛何佳洲赵国清刘义海
李永盛,何佳洲,赵国清,刘义海
(江苏自动化研究所,江苏 连云港 222061)
迁移学习能高效准确地处理小样本数据得到广泛地研究和使用。传统机器学习要求有大量的新数据,同时必须满足新旧数据同分布。这种要求是非常苛刻的,在实际应用中,企业面临的是如何处理小数据,并且往往也无法满足新旧数据同分布的条件。此时企业面临一个难题,该如何使用旧数据和新数据。与传统机器学习相比,迁移学习可以允许两个新旧数据之间有较大的差异,并且在新标注数据较少情况下,它仍然可以获得良好效果[1]。
1 迁移学习
简单地说,将在旧领域上的知识运用到新领域上,帮助新领域进行训练学习,这就是迁移学习。通常,把旧领域叫作源域,用字母Ds来表示;把新领域叫作目标域[2],用字母DT来表示。源任务是指机器已经掌握的相对于新任务不同的数据集,用字母Ts表示;目标任务是指机器要学习的新任务的数据集,用字母TT表示。Pan J等人[3]根据两领域间相似度,分成归纳迁移学习、无监督迁移学习和直推式迁移学习,如表1所示。Lu等人[4]根据迁移学习技术的发展,将迁移学习分为四类:基于神经网络的迁移学习、基于贝叶斯的迁移学习、模糊转移学习和基于计算智能的迁移学习。

表1 传统学习与迁移学习的对比
迁移学习是近些年来的研究热点之一,目前已在较多方面取得研究进展。Dai等人[5]针对文本处理问题,提出了一种基于聚类的分类算法,在共享相同词特征的不同领域之间,进行知识迁移,提高了传统学习算法的分类性能。Zhu等人[6]在图像处理方面,提出了一种异构迁移学习方法,把图像上的标签信息作为图像和文本之间的桥梁,从而达到更好的图像分类效果。Zhou等人[7]在智能规划方面,提出了一种迁移学习框架TRAMP,通过建立目标域和源域之间的结构映射来迁移知识。宋鹏等人[8]在语音情感识别方面,提出一种基于特征迁移学习的跨库语音情感识别方法,通过最大均值差异嵌入MMD描述不同数据库之间的特征分布相似度,同时通过半监督判别分析方法SDA进行特征降维,实验表明能有效提高语音情感识别率。
2 负迁移
本文将负迁移定义为:已有的经验知识会影响新知识的学习。如何解决负迁移问题,是在研究迁移学习中不可回避的问题。在学者们研究工作的基础上[9-36],根据迁移学习的特点,把改善负迁移的方法分为三类。
1)增加有效的源域知识数量。迁移的有效知识经验越丰富,学习效果就会相对越好。因此,可以考虑通过综合更多有效的源域一起学习,进而改善迁移学习。本文中,介绍的方法是多源域数据学习[9-19]。
2)增加目标领域的样本数量。迁移学习就是为了解决小数据样本,但是由于训练学习样本数量少,会容易导致迁移失败。如果能够大量增加样本数量,那么就可以改善负迁移。本文中,主要介绍了两种方法,即多任务学习[20-24]和生成对抗网络学习[25-27]。
3)减少领域间的数据分布差异。数据分布差异大小是影响迁移学习的根本原因。通常认为,数据分布差异越大,负迁移现象就会越严重。解决数据分布差异问题,一方面通过度量领域间的相似性,选择数据分布差异小的源域;另一方面,可以将源域和目标域的数据,先进行一次特征提取,从而减少数据间的差异,然后再进行知识迁移。本文中,主要介绍了两种方法,即稀疏字典学习法[28-33]和图正则化迁移学习[34-36]。
3 研究负迁移的相关工作
3.1 多源领域数据学习
根据源领域的个数,迁移学习分为单个源领域和多源领域。单个源领域的经验知识总是有限的,有时不能足够有效地给予目标领域学习帮助,因此可以想到结合多个源领域的知识,帮助目标域完成任务,从而使得迁移学习结果变得更加可靠。
根据Sun等人[9]的研究,可以将多源域迁移学习划分为两大类。1)将不同源域训练学习得到的分类器进行加权组合,典型算法有MCC-SVM算法[10]和A-SVM算法[11];2)进一步考虑对无标签目标数据的利用,典型算法有DAM[12]和DSM[13]等。
近几年,学者们进行了许多关于多源域的迁移学习研究。Yao等人[14]提出了两个新算法MultiSource-TrAdaBoost和 TaskTrAdaBoost,实验结果表明随着源域数量的增加,负迁移大大减少。Gao等人[15]提出了一种多模型局部结构映射方案,根据目标样本的分布特性来设置来自多个源领域的学习模型的权重。Luo等人[16-17]提出了一致性正则化框架,进一步地挖掘多源域数据的内部信息。季鼎承等人[18]提出了基于域与样例平衡的多源迁移学习方法,其思想是把域和样例两个层面进行双加权平衡,然后加入到迁移学习的目标函数中。刘振等人[19]提出了一种基于多重相似性的多源域迁移学习方法,先从域-域和样本-域这两个层面刻画目标域和多个源域的相关性,然后根据平滑性流形假设,实现从源域到目标域的知识迁移。
3.2 增加目标领域的样本数量
3.2.1 多任务学习
在单任务学习中,如果用于训练的样本数据数量有限,则容易出现泛化能力差的结果。1994 年, Caruana[20]提出了多任务学习。多任务学习的前提是假设不同任务的样本数据具有相似性,而单任务学习只使用了单个任务的样本数据,那么多任务学习使用了它们所有的样本数据,等于扩大了训练数据集,并且还可以平均多任务之间各自的噪声差异,大大提高了泛化能力。由于多任务学习的目的不一定都一样,所以不能简单地视为合并成一个新任务,它本质上是属于多任务联合学习。图1显示的参数共享机制是多任务深度学习中比较常见的一种方式。如果多个任务间有相关联的数据信息,那么多任务学习是有效的,反之会影响原来的学习效果。

图1 多任务深度学习中的参数共享机制
Ben-David 和 Schuler[21]研究了多任务学习中具有共同特征的相关任务集,提出了生成框模型以及误差界限。2005年,Carroll 和 Seppi等人[22]提出了度量任务相似性的指标,比如时间、策略覆盖、Q值和奖赏结构等。2008年,Mahmud 和 Ray[23]采用贝叶斯的观点来计算任务相似度,很好地解决了任务相似度的度量。Zheng等人[24]提出了一种多任务学习算法,先假设潜在特征空间的学习是相似的,采用交替优化方法进行迭代学习特征映射和设备的多任务回归模型,并证明了其有效性。
目前的多任务学习是狭义的,因为它们需要结合专业知识,来设计任务之间的信息交互迁移形式。而广义的多任务学习,应该是在数据差异性很大时,仍能实现有效迁移。
3.2.2 生成对抗网络学习
为了便于理解生成对抗网络学习,先举一个简单的例子。假设有一台印钞机负责生成假钞,同时另外一台验钞机负责鉴别钞票的真伪。若验钞机能鉴别出假钞,则印钞机进行修改;若验钞机鉴别假钞失败,则验钞机进行修改。如此往复循环,在两台机器的对抗中,印钞机的造假能力越来越高,验钞机的鉴别能力越来越强,最后形成的效果是印钞机可生成以假乱真的假钞。那么,由此联想到小样本数据问题,既然样本数量少是关键因素,那么能否有一个生成模型可以像印钞机生成假钞那样去伪造样本数据?基于这种对抗的学习思想,生成对抗网络便产生了。
生成对抗网络GAN,是由Goodfellow等人[25]提出的生成模型,如图2所示。
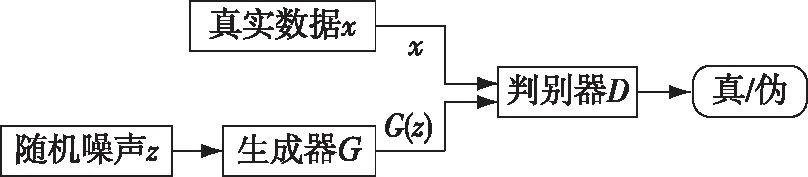
图2 生成对抗网络结构
GAN由生成器G和判别器D组成。把从某个分布中采样的随机噪声z作为生成器G的输入,生成器G努力拟合真实数据x的分布,期望能够欺骗判别器D。然后把真实数据x和生成数据G(z)一起输入判别器D,让判别器D区分样本数据来源于哪个部分。它们进行相互对抗学习,然后不停地迭代更新,直至达到判别器D无法准确地区分生成样本和真实样本为止。在此期间不需要做任何近似推理,也无须采样过程,它是直接进行新样本的采样。通过生成对抗网络学习,可以获得大量近似真实数据的样本,解决了如何生成有效样本数据的难题,从而弥补了目标领域中样本数据少的不足。另外,生成器不是简单地复制真实样本数据,由于它是从随机噪声产生的,所以也增加了生成样本的多样性。
臧文华[26]提出了两种对抗迁移学习算法。一种是基于残差的对抗迁移学习算法RAN,利用对抗的方法对齐两个域的特征,同时分类器能自适应,得到区分性更好的特征。另一种是基于特征和标签的联合分布对抗迁移学习算法FLAN,利用对抗学习匹配两个域之间的联合分布,增强了特征的区分性。满子健[27]将生成对抗网络GAN和变分自编码器VAE结合起来,利用迭代学习训练促使生成器去学习真实图像的数据分布,能明显改善生成图像的质量及多样性。
3.3 减少领域间的数据分布差异
3.3.1 稀疏字典学习法
稀疏表示理论,基于其优秀的数据特征表示能力和对数据特征的自动提取,在许多领域取到了较好的效果。稀疏字典是稀疏表示理论中的关键部分[28],直接影响稀疏编码的性能。
面临大数据时代,实现大规模数据的迁移是一件棘手的事情,因为海量的数据里面包含了大量的冗余信息,既含有有用信息也含有无用信息。而稀疏字典学习方法[29]可以将海量数据压缩为字典,那么字典代表了数据中最本质的基本信息,此时再进行知识的迁移就会变得容易。它先在目标领域的数据字典中找出判别性的原子,再根据初始目标聚类中心,从源领域中找出与目标判别性原子相似的特征知识,将其迁移到目标字典中,增强目标字典的判别性。若结合多源域学习,则可进一步降低负迁移的可能性。
学者们已经对稀疏字典学习方法进行了诸多研究。Chen等人[30]提出了一种基于深度卷积神经网络的视觉情感分类方法,是从网络照片的标签中自动挖掘原子信息,作为检测图像情感的有效统计线索,取得了显著效果。Wright等人[31]基于稀疏表示方法,提出了一种通用的基于图像的目标识别分类算法,为解决人脸识别中的特征选择问题提供了新的方法。Ma Y等人[32]详细介绍了稀疏信号表示和计算机实际之间的相互作用,并在自然图像分割方面进行应用,实验结果显示降低了错误率。崔鹏等人[33]结合稀疏编码和背景差分进行行人检测,提出了一种新的迁移学习框架,通过稀疏编码对所有样本进行权重分配,实验结果比其他传统方法取得了显著提高。
3.3.2 图正则化迁移学习
研究分析数据时,通常会得到数据的统计信息和几何信息。简单来讲,数据的统计信息[34]是指对数据的描述性统计,比如数据的样本均值或方差等。而数据的几何信息[35]与数据里面嵌入的流形有关,它是描述数据的内在分布。它们是从不同的角度来关注原始数据,在描述原始数据信息时具有相互补充的作用。所以将数据的统计信息和几何信息结合起来,可以提高潜在因子的平滑性,进而改善迁移学习。
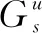
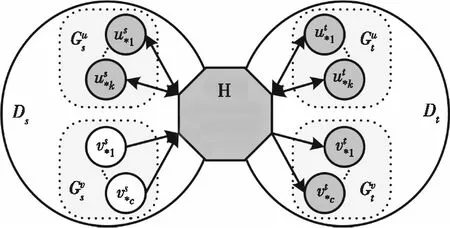
图3 图正则化联合矩阵分解框架
众所周知,非负矩阵分解技术[39](NMF)是处理多维数据的有效工具之一,在聚类处理方面有着极大地优势。而GTL,它是一种通用的模型框架,可以使用多种矩阵分解模型,如NMF和Semi-NMF[40],都能容易地集成到GTL框架中来解决迁移学习问题。另外,在每个领域内进行图正则化,可以保持各自领域内的几何流形结构不被领域外的知识结构破坏。
关于迁移学习,当源领域和目标领域的差异足够大时,Qiang Yang等人认为需要保留源域和目标域的几何结构。这样即使两领域间传递的公共因子相冲突,也不会破坏目标域的几何结构。在GTL[36]里,通过保留跨域的统计信息来提取共同的潜在因素,同时通过保留每个域的几何信息来细化潜在因素,从而缓解负迁移。
4 结束语
在实现对小数据集准确高效的学习方面,迁移学习有着天然的优势,是推动未来人工智能发展的重要技术,但负迁移的出现引起了学者们的广泛关注。在本文中为了解决负迁移问题,我们从源域、目标域、领域间数据分布差异三个方面展开分析,提出多源领域数据学习、增加目标领域的样本数量、减少领域间的数据分布差异等三个方向,并汇总了改善负迁移的相关研究工作。
随着对迁移学习的研究深入,下面方向在改善负迁移现象方面值得未来进一步研究。
1)寻找更好的度量领域间相似度的方法。在源域中无效数据样本的训练知识,在迁移时就会引起负迁移。通过相似度将源领域的数据划分为有效数据和无效数据,只把有效数据迁移到目标数据集中,增加目标数据集的数量,从而减弱负迁移。目前已经有人提出了一些相关算法,如Boosting算法[41]、TCSBoost算法[42]等,但这些算法都还有各自的局限。
2)多线索学习。之前考虑的迁移学习,大多是从一个源域到目标域,或者从多个源域到目标域,而忽视了对目标域数据的多方面研究。换个角度,是否可以考虑多线索地学习目标域的数据?根据集成学习思想,可以将最终的目标任务划分成若干个与目标任务相关的次任务,然后分别通过迁移学习得到每个次任务对应的单分类器,再通过权重策略将若干个单分类器整合得最终所需的目标任务的学习结果。罗娟等人[43]提出了基于迁移学习的多线索植物识别方法,先通过对植物的花、果、叶、株等进行学习得到四个单器官学习模型,然后通过组合这四个单器官学习模型得到植物最终的识别结果,实验证明识别准确率得到了显著提升。
3)多步传导式迁移学习。目前的迁移学习是指从领域A迁移到领域B,这是单步的迁移。而现实中有些迁移只能是先从领域A到领域C,再从领域C到领域B,它并不是简单地从领域A到领域B,而是多步传导的。由此可推,从源域到目标域的学习,是否也可以找到一个或多个中间层,使得它们既可以考虑到源域,又可以考虑到目标域?
4)层次型的迁移学习。卷积神经网络CNN最早由LeCun[44]提出,在此基础上,又陆续出现了AlexNet、ZF-Net、VGGNet、GoogleNet、ResNet、DenseNet[45]等。如今的深度学习,其神经网络可以多达几十层。经研究表明,卷积网络前几层提取的是基础特征,越往后提取的特征就越抽象。因此它表明不同层次的网络具有不同的迁移能力。在迁移源域的知识时,可以只迁移源域中前几层网络的卷积参数到目标域,而后面几层的网络参数通过小数据来训练学习得到。层次型的迁移学习已经在文本分类和图像识别方面获得了成功应用。
