面向信息系统跨平台轻量应用的汉字编码转换程序①
2020-07-25葛光富
葛光富
(中国电子科技集团公司第二十八研究所,南京 210007)
引言
在我国的信息系统工程应用中,顺应国际化时代的发展,各类新运用的工具和软件的汉字编码大多采用了全球共享通用的Unicode字符集,该字符集目前能够涵盖世界上主要语言的符号和文字.而在指挥控制、网络安全、公共交通等业务领域方面,现役信息系统的汉字编码包括有GB2312、GBK 以及GB18030等,为兼容与已有系统的互译互操作,故按照国际化要求新开发的信息系统在相当的一段时间内,仍会面临着上述编码形式的汉字编码转换需求[1-4].
综合军民用市场,有着大量的计算处理设备用于搭建各型信息系统,但这些设备却部署着种类多样、复杂不一的操作系统运行环境.尤其是嵌入式设备更为突出,如车载终端的VxWorks (美国风河)、ReWorks(电科32所)等,便携终端的Android(美国谷歌)、WinCE (美国微软)、AOS (深圳华为)、SyberOS (北京元心)等.因此,为降低系统开发维护成本、提升行业企业效益,用于支撑应用跨操作系统平台快速移植改造的汉字编码转换技术,成为信息系统软件服务平台统筹规划中的必要考虑因素.
要进行汉字编码转换,对于Linux/类Linux系统上的软件,利用GNU (GNU is Not Unix,指的是一个自由软件工程项目)的libconv库即可实现.该库支持包括世界主流语系在内的字符集区域标准与国家标准编码间的互转,但是这对于计算处理资源受限的嵌入式终端而言,资源占用就显得有点庞大,且不利于移植改造应用到各类操作系统尤其是国产化操作系统.因此研究一种支持信息系统内部以及信息系统间通用的轻量化、可适用、易维护的汉字编码转换方法,是在跨操作系统平台应用实践中急需解决的问题.
本文利用Windows7 记事本工具,进一步研究[5-7]开发出一种面向信息系统跨平台轻量应用的汉字编码转换程序,能够提供有效的汉字编码转换接口,用于与已有信息系统的如文本、信息的汉字交互处理,支撑新开发信息系统的快速构建开通.
1 常用汉字编码
汉字编码指的是为汉字设计的一种便于输入电子计算机的代码,是解决汉字能够进入计算机的关键.国标码,全名国家标准代码,是我国的常用汉字编码集,目前主要有GB2312、GBK、GB18030三种.另外,UTF-8因能够与ASCII兼容而作为优先采用的国际字符编码,也涵盖了汉字的编码.
1.1 GB2312编码
GB2312-80编码是我国第一个汉字编码国家标准,共收录汉字6763个,同时收录了682个非汉字全角字符.它对收录的每个字符采用两个字节表示,其编码范围为0xA1A1到0xFEFE,首字节在0xA1与0xFE之间,尾字节在0xA1与0xFE之间.其中0xB0A1到0xF7FE为汉字的编码范围,0xA1A1到0xA9FE为非汉字字符的编码范围,其他为空白区.
1.2 GBK编码[5]
GBK全称《汉字内码扩展规范》,是在GB2312标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从0x8140到0xFEFE,首字节在0x81与0xFE之间,尾字节在0x40与0xFE之间且不为0x7F,总共23 940个码位,收录了21 003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1 中的全部中日韩汉字,并包含了BIG5编码中的所有汉字.GBK编码空间组成如表1所示.

表1 GBK编码空间组成
1.3 UTF-8编码[6]
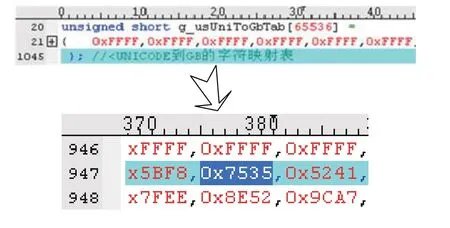
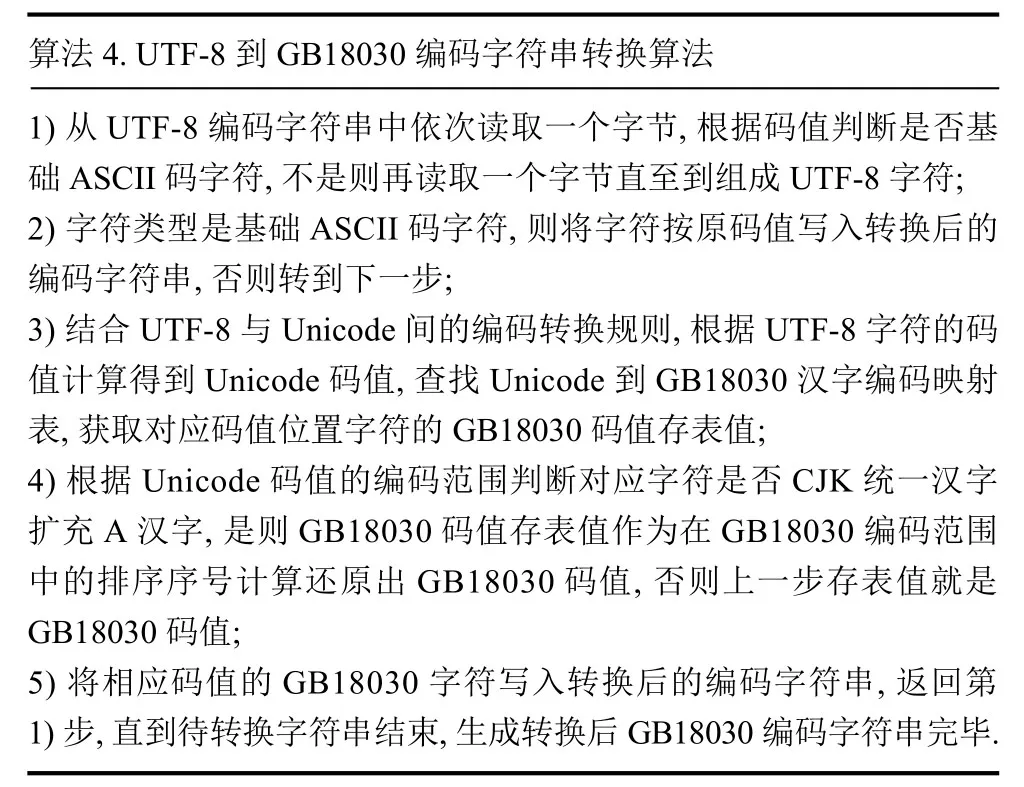
UTF-8是一种针对Unicode[7]字符集的可变长度字符编码,所有的字符均使用1到6个字节进行编码,是一种前缀码.在只包含1个字节的UTF-8编码中,其最高位置0,其余的7个二进制位用来对字符进行编码;在含n(1 表2 UTF-8与Unicode编码对照表 GB18030-2000《信息交换用汉字编码字符集基本集的扩充》,是我国计算机系统必须遵循的基础性标准之一.它是GBK的取代版本,在其基础上增加了6530个CJK(中日韩)统一汉字扩充A的汉字(由4字节表示:第1字节0x81~0x82,第2字节0x30~0x39,第3字节0x81~0xFE,第4字节0x30~0x39,共占用了25 200个码位). 因GB18030 能够前向兼容GBK、GB2312,基于这一特点,适应性选取GB18030与UTF-8间的编码转换来轻量应用支撑信息系统的汉字编码互处理需求,同时使用通用的C/C++语言,分析与设计出一种面向信息系统跨平台轻量应用的汉字编码转换程序. 要进行GB18030与UTF-8间的汉字编码转换,就必须利用GB18030和Unicode间的汉字字符码值映射关系,以及Unicode和UTF-8间的国际字符编码转换规则,故首先要制作GB18030与Unicode间的汉字编码映射表. GB18030编码中,GBK 汉字字符由2个字节表示,CJK统一汉字扩充A的汉字字符由4个字节表示;与其对应的Unicode标准字符集中,GBK、CJK统一汉字扩充A的汉字字符编码占用2个字节大小的空间.两者之间的汉字字符编码存在一一映射的关系,可以通过编制汉字字符编码相互映射的表来进行转换. GB18030与Unicode编码映射表在互联网上百度文库、CSDN 社区等处能够找到部分缺漏不全的字符编码对照,但在软件程序中使用还是需要经过二次加工制作成为可识别的代码语言.而本文在Windows7系统平台上,利用记事本工具和编写转换过程应用程序来辅助生成代码语言的汉字编码映射表,具体的实现方法为: 1)根据1.2和1.4 小节中GBK、CJK统一汉字扩充A的汉字编码空间组成说明,编写执行GB18030编码全汉字生成程序,将全部有效的编码汉字按照码值从低到高依次保存到一个文本文件GB.txt 中; 2)在使用记事本方式打开GB.txt文件后,将打开的文件另存为Unicode编码的新文件Uni.txt 中; 3)编写执行GB18030与Unicode编码映射表生成程序,对照GB.txt与Uni.txt文件,以C语言可识别代码的数组形式生成GB18030与Unicode间的汉字编码映射表,以支持两者编码的快速映射查找.映射表生成算法设计如算法1和算法2. 算法1.GB18030到Unicode 汉字编码映射表生成算法1)创建GB18030到Unicode 汉字编码映射表,其中数组支持存放元素65 536个,数组元素下标能够一一对应GB18030 汉字字符码值,数组元素数值为2个字节大小存储的Unicode 汉字字符码值,初始化映射表元素值为代表无效映射的0xFFFF;2)从Uni.txt文件中依次取得两个字节组成汉字字符,获取汉字字符的Unicode 码值;3)从GB.txt文件中依次取得两个字节,根据两个字节的码值范围判断是否GBK 汉字字符,不是则再取得两个字节组成4个字节的CJK统一汉字扩充A的汉字字符,获取汉字字符的GB18030 码值;4)计算汉字字符的G B 1 8 0 3 0 码值在按照码值从低到高的GB18030编码范围中的排序序号(如GBK 汉字的尾字节占用191个码位,故0x8140 对应序号为0,0x8240 对应序号为191,依次类推,直到CJK统一汉字扩充A,也按照同样规则计算),该序号为Unicode 码值的存放位置;5)将汉字字符的Unicode 码值,存放到汉字编码映射表中对应的位置;6)返回第2)步,直到文件结束,生成GB18030到Unicode 汉字编码映射表完毕. 算法2.Unicode到GB18030 汉字编码映射表生成算法1)创建Unicode到GB18030 汉字编码映射表,其中数组支持存放元素65 536个,数组元素下标为Unicode 汉字字符码值,数组元素数值为2个字节大小存储并能够一一对应GB18030 汉字字符码值,初始化映射表元素值为代表无效映射的0xFFFF;2)从GB.txt文件中依次取得两个字节,根据两个字节的码值范围判断是否GBK 汉字字符,不是则再取得两个字节组成4个字节的CJK统一汉字扩充A的汉字字符,获取汉字字符的GB18030 码值;3)汉字字符是CJK统一汉字扩充A 汉字,则计算汉字字符的GB18030 码值在按照码值从低到高的GB18030编码范围中的排序序号(如GBK 汉字总计占用24 066个码位,结合CJK统一汉字扩充A 汉字的尾字节占用10个码位,故0x81308130 对应序号为24 066,0x81308230 对应序号为24 076,依次类推),该序号为GB18030 码值存表值,GBK字符的GB18030 码值存表值直接使用原值;4)从Uni.txt文件中依次取得两个字节组成汉字字符,根据该汉字字符的Unicode 码值,获取汉字字符的Unicode 码值,该码值为GB18030 码值相对值的存放位置;5)将汉字的GB18030 码值存表值,存放到汉字编码映射表中对应的位置;6)返回第2)步,直到文件结束,生成Unicode到GB18030 汉字编码映射表完毕. GB18030和Unicode间的汉字编码映射表(如汉字“科”—0xC6BF/0x79D1)代码语言示例如图1所示,映射表总计1024行,每行64个码值映射元素,其中值为0xFFFF 表明当前位置对应的GB18030编码为无效编码. 有了汉字编码映射表,就可以结合UTF-8与Unicode的编码转换规则,实现字符串GB18030与UTF-8编码形式间的转换,具体的转换程序设计见后续小节中描述. 图1 Unicode到GB18030编码映射表 将GB18030编码字符串(含英文、数字等基础ASCII 码字符,其码值范围为0x0到0x7F)转换到UTF-8编码的算法如算法3. 算法3.GB18030到UTF-8编码字符串转换算法1)从GB18030编码字符串中依次读取一个字节,根据码值判断是否基础ASCII 码字符,不是则再读取一个字节组成两个字节后判断是否GBK 汉字字符,不是则再读取两个字节组成4个字节的CJK统一汉字扩充A的汉字字符;2)字符类型是基础ASCII 码字符,则将字符按原码值作为UTF-8字符写入转换后的编码字符串,否则转到下一步;3)根据汉字字符的码值,计算字符在按照码值从低到高的GB18030编码范围中的排序序号,查找GB18030到Unicode 汉字编码映射表,获取对应序号位置字符的Unicode 码值;4)结合表2中体现的UTF-8与Unicode间的编码转换规则,根据汉字字符的Unicode 码值计算得到字符的UTF-8编码码值,将相应码值的UTF-8字符写入转换后的编码字符串;5)返回第1)步,直到待转换字符串结束,生成转换后UTF-8编码字符串完毕. GB18030到UTF-8编码字符串转换利用接口函数g2u()实现,关键代码如下: 将UTF-8编码字符串转换到GB18030编码的算法如算法4. 算法4.UTF-8到GB18030编码字符串转换算法1)从UTF-8编码字符串中依次读取一个字节,根据码值判断是否基础ASCII 码字符,不是则再读取一个字节直至到组成UTF-8字符;2)字符类型是基础ASCII 码字符,则将字符按原码值写入转换后的编码字符串,否则转到下一步;3)结合UTF-8与Unicode间的编码转换规则,根据UTF-8字符的码值计算得到Unicode 码值,查找Unicode到GB18030 汉字编码映射表,获取对应码值位置字符的GB18030 码值存表值;4)根据Unicode 码值的编码范围判断对应字符是否CJK统一汉字扩充A 汉字,是则GB18030 码值存表值作为在GB18030编码范围中的排序序号计算还原出GB18030 码值,否则上一步存表值就是GB18030 码值;5)将相应码值的GB18030字符写入转换后的编码字符串,返回第1)步,直到待转换字符串结束,生成转换后GB18030编码字符串完毕. UTF-8到GB18030编码字符串转换利用接口函数u2g()实现,关键代码如下: 本文方法实现的汉字编码转换程序,以动态库的形式提供,适用于GTK、Tilcon、Element-UI、QT 等界面库的信息系统软件开发,并已成功运用于多型含装甲车载嵌入式、单兵移动便携信息处理终端的陆军业务信息系统中.这些信息系统中,配套工具开发的前端展现界面(如图2所示)的汉字编码类型大多数固定为UTF-8编码,为兼容与已有系统如文本、协议的汉字交互处理,后端服务处理采用的中文编码形式为GB18030或GBK.上述汉字编码转换程序不仅可以更轻量地应用于各类业务信息系统,而且利于信息系统间的软件部件甚至整件的快速改造移植.这些都能够为提高信息系统的资源利用率以及降低系统的开发维护成本,起着积极的作用. 图2 某装甲车载平台GTK 开发的前端界面示例 本文立足于为信息系统的处理终端尤其是嵌入式终端提供轻量化的跨平台通用汉字编码转换手段,论述了常用汉字编码的基本原理、编码对照关系.同时,给出了面向跨平台轻量应用的编码转换方案,这套方案已成功地在多型嵌入式如单兵业务信息系统中得到应用[8],且也能适用于其他信息系统[9].
1.4 GB18030编码
2 汉字编码转换程序分析与设计
2.1 GB18030与Unicode编码映射表制作


2.2 GB18030与Unicode编码字符串转换





3 程序应用实例

4 结束语
