K12学习平台个性化学习资源推荐①
2020-07-25徐亚军
徐亚军,郭 俭
(苏州百智通信息技术有限公司,苏州 215000)
1 概述
近年来,随着在线教育和在线学习平台的不断发展,积累了海量的学习资源.这些学习资源极大地丰富了学生的选择,学生在平台中查阅的资源数量也越来越多,范围越来越广泛.然而在为学生带来便利的同时,也使学生需要花费更多的时间和精力去筛选符合自己学习需求的资源,因此“资源过载”和“学习迷航”现象越来越严重[1],而且平台资源数量众多,学生无法辨别资源的优劣,另外,由于学生的认知能力存在差异,导致不同学生的学习需求也是不同的.因此,如何能够为学生提供个性化的学习资源,提高在线课程的学习效率是在线教育面临的一大挑战[2].
在线学习系统积累了海量的与用户行为相关的数据,例如资源学习、资源收藏、交流讨论、资源分享等,隐含了大量有价值的信息.许多在线学习平台利用数据挖掘和人工智能技术,从这些用户数据中提取有价值的信息,从而为用户推荐可能感兴趣的学习资源[3].
苏州线上教育中心是2018年1月苏州市教育局面向K12教育领域推出的线上学习平台.平台以“全名师、全过程、全免费”为核心理念,统筹全市名优教师资源,通过个人电脑、手机、平板和电视等终端向全市师生提供“名师优质资源”、“名师在线直播”、“名师在线答疑”、“在线学习行为数据分析与智能引导”等教育服务[4],平台上线至今用户使用活跃,总登录人次已达到880.1万,日均登录2.1万人次;微课观看总数529万余人次,人均观看29.3次;初步形成了常态化的应用局面.然而,目前平台学习资源的推荐仅仅是按照浏览量推荐,推荐的准确性太低.
因此,本文通过对现有学习推荐系统进行梳理,针对K12在线学习平台的特点,提出了基于知识图谱的协同过滤推荐方法.本文基于学生学习资源的数据,充分利用数据间的关系,构建知识图谱,并在其基础上进行协同过滤推荐.
2 相关研究
近年来,学习资源的推荐逐渐成为在线教育领域的研究热点之一.陈池等对主流在线教育领域的大数据应用进行了研究总结和归纳[5],介绍了数据挖掘、学习分析和知识图谱等相关技术,并且描述了大数据应用的基本轮廓,为在线教育领域大数据的研发起到了指导性的作用,目前推荐系统的推荐方法一般分为三类:基于内容的推荐方法[6]、基于协同过滤的推荐方法[7-9]和混合推荐方法[10].其中基于协同过滤的推荐算法是应用最广泛的,并且引入了数据挖掘、机器学习、本体等概念或技术[11-14].目前针对基础教育的推荐系统较少,而基础教育的用户及数据有鲜明的特点,采用常用的推荐方法效果不好,张海东等[15]使用TFIDF算法提取课程和资源的内容特征,构建模型并计算资源之间的关系从而达到推荐的目的,但是太依赖于资源的标签.
本文针对K12在线教育平台的数据特点,采用基于知识图谱的协同过滤推荐方法.
3 基于知识图谱的协同过滤推荐
K12平台的主要用户-学生的学习具有周期性特点,基础教育学习平台都同步了学习场景,随着学习进度的推进,对某个知识点资源的需求会在几天之内迅速从零到达高峰,并且又在几天之内迅速恢复到零,所以知识点对推荐的准确率起到关键作用,而知识图谱具有紧密的知识相关性的特点,因此,知识图谱在扩展实体信息、强化实体之间的联系上具有天然的优势,可以为推荐系统提供准确而丰富的参考作用.在知识图谱中,实体中包含着丰富的属性信息,单个实体具有多个父实体,不是所有的父实体都适合被往下遍历.而知识图谱的属性信息恰好可以为推荐结果提供精确性、多样性与可解释性.
另外一个学校或者一个班级的教学进度是基本统一的,所以对于资源的推荐需要针对不同的学生有不同的权重,这样推荐会更加准确,协同过滤推荐有按照群体的喜好推荐的特点,所以本文采用协同过滤的推荐方法.
学习平台资源众多,单纯的推荐算法筛选计算的资源太多,严重影响推荐的效率和效果.基于特征的知识图谱的协同推荐,通过知识图谱筛选出最近学习的知识点的资源、最近同学学习的资源,从而大大减少推荐的资源数量,而且推荐的准确度也会更高.先知识图谱再协同过滤推荐,通过知识图谱,进行数据过滤,再采用协同过滤推荐方法,两者相结合,两者的可用信息可以互补,知识图谱可以帮助协同过滤推荐摆脱局部极小值;可以防止协同过滤推荐过拟合;可以提高协同过滤推荐的泛化能力.
在苏州线上教育中心平台,老师通过平台上传及共享资源,学生通过平台学习资源,平台与教育基础库对接,采集了老师和学生的基础信息,本文根据老师和学生的基础信息及学生学习的行为数据构建知识图谱,结合协同过滤推荐向学生推荐个性化的学习资源.首先利用知识图谱进行资源筛选,利用协同过滤推荐算法对筛选的资源进行排序推荐,给学生推荐个性化高质量的资源.
4 知识图谱构建
在学习平台中,学生学习资源的需求会随着教学进度周期性的变化,而老师在这个过程中起着主导作用,并且对于学生的情况,老师也是最清楚的,所以本文根据老师提供的相关经验,整理出知识图谱的节点及属性,下文将对节点及属性进行详细说明.
基础教育的知识点间具有较强的逻辑关系,我们称为“前置后导”关系,从图1中可以看出,学生学习了“10以内的数”,才会学习“10以内的加减法”或者“20以内的数”.所以知识点在资源推荐中很重要.因此本文将知识点作为知识图谱的实体,并且将知识点作为固定不变的实体.
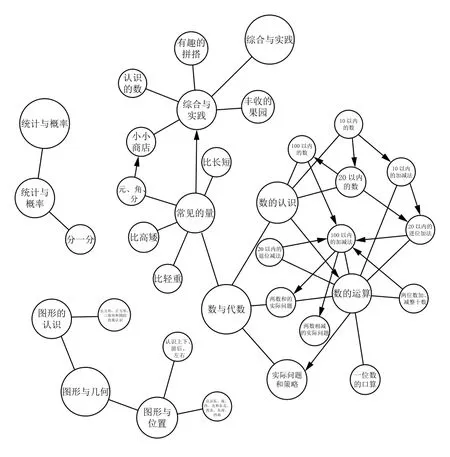
图1 知识点知识图谱
如图1所示,纯知识点构成的知识图谱;另外,资源是推荐的对象,所以将资源作为另一个实体,而知识点作为资源的属性;另外本文也将学生、班级、老师、学校作为知识图谱的实体,这些都是老师总结出的重要属性.
实体及三元组的结构如下:
1)资源:推荐实体;
2)知识点:资源的属性,与教学时间相关;
3)学生:推荐主体,协同过滤推荐用户;
4)班级:学生属性,协同过滤推荐参数;
5)老师:班级属性,协同过滤推荐参数;
6)学校:班级属性,协同过滤推荐参数.
综上所述,构建的知识图谱例子如图2所示.
由于K12教育具有周期性教学的特点,学生在某个日期进入平台,平台会根据日期计算出当前学习知识点,本文采用以下算法,将一学年的时间进行分割,按照表1计算一年时间里每天的半径值.
为方便计算,本文将一学年的知识点取值为0-1.0,每个知识点就得到相应的半径值,通过每天的半径值与知识点的半径值就可以计算出每天对应学习的知识点.本文取日期半径值对应的最近的3个知识点.通过知识点及用户从知识图谱中取相应的实体资源,包括最近知识点的资源,用户观看的资源,同班同学学习的资源,同校同学学习的资源,所属班级老师上传的资源.将这些资源作为协同过滤的输入.

图2 知识图谱

表1 时间取值对照表
5 协同过滤
经过知识图谱过滤的资源作为协同过滤的样本,推荐的实体是资源,而资源的观看,点赞,收藏作为用户对资源的评分,综合资源的知识点属性,同班同学,同校同学作为不同的权重综合计算出分数作为用户对资源的评价.
5.1 数据预处理
协同过滤推荐需要将学生对资源的打分作为推荐依据,而基础教育平台没有学生对资源的打分系统,而且平台的主要用户是中小学生,他们对资源的打分不完全客观.本文根据用户的行为记录,学生属性等数据计算出评价分数,本文将评价指数,知识点指数,协同指数3个指数作为学生对资源的评价分数.
5.1.1 评价指数
学生在观看资源后没有对资源的直接打分评价,所以本文综合学生对资源的观看,点赞,收藏等行为作为学生对资源的评分,例如如果学生观看视频在很短的时间内就关掉了视频,很大可能就是这个视频对学生用途不大,本文将这个行为作为负向评分,如果是负向评分本文就取值为0,另外学生在选择资源的时候带有倾向性,对于自己薄弱的知识点会更多的关注,并且会选择难度较低的资源,对于自己已经掌握的知识点会选择难度较高的资源.另外学生可以对选择的资源进行点赞或者收藏,所以点赞和收藏指标可以很好地表明学生对于资源的喜好,公式如下:

其中,w表示各个行为权重,fcollect、fgood表示是否收藏,点赞,值分别为1或者0.fview表示有效观看,如果观看时长超过了30%,fview=1,否则fview=0.
5.1.2 知识点指数
基础教育平台观看资源的热度与学习进度密切相关,本文取日期半径值临近的3个知识点的资源,并计算知识点指数,公式如下:
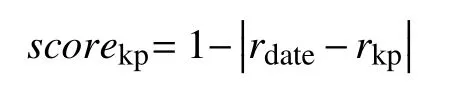
其中,rdate表示日期半径,rkp表示知识点半径.
5.1.3 协同指数
基础教育中,一个校的教学进度基本相似,而一个班就是一个教学进度,所以同班同学或者同校同学的观看资源作为协同指数,公式如下:
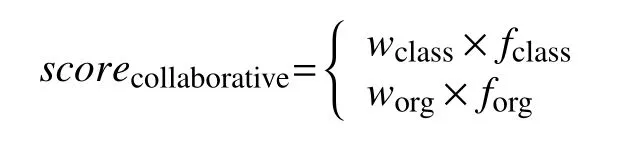
其中,w表示班级或者学校权重,f表示是否是同班同学或者同校同学,其值是1或者0.
综合上面3个指数,学生对资源的评分公式如下:
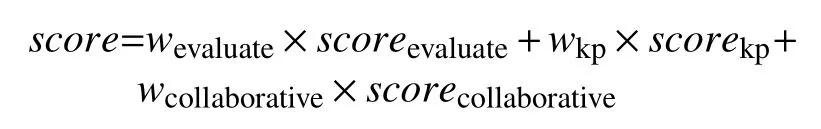
其中,score为各个指数的数值,w为各个指数的权重.
5.2 相似度计算
本文利用用户的协同过滤推荐资源,所以需要计算用户的相似度,本文对比常见的几种相似度算法,选择了斯皮尔曼等级相关系数计算方法.
欧几里德距离是计算空间中两个点的距离,利用欧式距离定义相似度,相似度没有考虑重叠数对结果的影响.
皮尔逊相关系数是反映两个变量线性相关程度的统计量,该方法也没考虑重叠数对结果的影响.
Cosine 相似度通过多维空间两点与所设定的点形成夹角的余弦值计算相似度,该算法对用户的绝对的数值不敏感.而本文中,用户对资源的喜好程度对推荐的准确性很关键,不同类型的学生对不同类型的资源需求不同,比如,对某个知识点掌握较好的学生会对难度较低的资源评价较低而掌握较差的学生对难度低的资源评价较高,所有Cosine 相似度不适合.
Tanimoto系数是Cosine 相似度的扩展,它不关心学生对资源的具体评分值是多少,它关心学生与资源之间是否存在关联关系.
综合本文对比,本文采用斯皮尔曼等级相关系数.假设两个随机变量分别为X、Y,它们的元素个数均为N,两个随即变量取的第i(1 ≤i≤N)个值分别用Xi、Yi表示.对X、Y进行排序(同时为升序或降序),得到两个元素排行集合x、y,其中元素xi、yi分别为Xi在X中的排行以及Yi在Y中的排行.将集合x、y中的元素对应相减得到一个排行差分集合d,其中di=xi−yi,1 ≤i≤N.随机变量X、Y之间的斯皮尔曼等级相关系数可以由x、y或者d计算得到,其计算方式如下所示:

通过实验证明斯皮尔曼等级相关系数推荐准确率是最高的.
5.3 协同过滤推荐
基于用户的协同过滤推荐主要分为3个步骤:
(1)从用户列表中获取当前学生Ui最相似的K个用户合集{U1,U2,···,Uk};
(2)从这K个学生集合排除Ui的偏好的资源,剩下的Item集合为{Item0,Item1,···,Itemn};
(3)对Item集合里每个Itemj计算Ui可能偏好的程度值pref(Ui,Itemj),并把Item按此数值从高到低排序,前N个Item推荐给用户Ui.
偏好程度值pref计算公式:
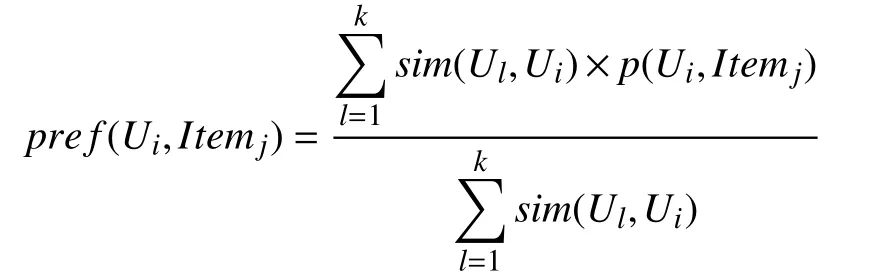
6 实验
本文采用采用离线测评的方法,将苏州线上教育中心运营数据分成训练集合和测试集,将2018年1月到2018年12月的数据构建基于知识点的知识图谱,然后对学生进行协同过滤推荐,将推荐结果与2019年1月到2019年6月的数据进行对比,计算出推荐的准确率和召回率.本文随机选取了使用量较多(观看记录超过1000条)的100位学生对其每周观看的资源进行预测.

实验主要测试协同过滤算法3个指数的权重及其指数下面分别的参数的权重.
综合调整,协同指数的各个参数权重取值如下:

而不同相似度算法的准确率如表2所示,根据对不同相似度算法的计算对比,斯皮尔曼等级相关系数的综合准确率最高.
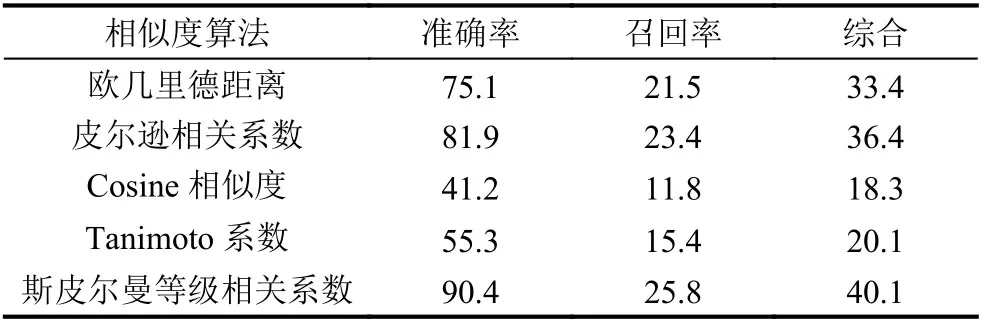
表2 相似度准确率对照表(单位:%)
7 结束语
本文在苏州线上教育中心学生学习视频的数据基础上,结合数据特点,提出了基于知识图谱的协同过滤推荐方法,实验证明该方法相对于按照热度的推荐方法准确率大幅度提高.
本文提出的方法虽然提高了资源推荐的准确率,但召回率有待提高,本文没有考虑学生的用户画像,对于学生个性化的需求没有考虑全面,需要日后对平台更多的数据进行分析,从而完善算法,提高推荐算法的召回率.
