基于Spark的SKA1-MID自校准管线分布计算实现*
2020-07-24李秋虹
戴 伟,汪 森,李秋虹,邓 辉 ,梅 盈,王 锋,
(1. 昆明理工大学云南省计算机技术应用重点实验室,云南 昆明 650051;2. 复旦大学,上海 210000;3. 广州大学天体物理中心,广东 广州 510006)
为了进一步开展当前重大科学问题如暗物质和暗能量、黑洞和致密天体、宇宙起源、天体起源以及宇宙生命起源等研究工作的需要,科学家提出了平方千米阵列项目[1-2],并成为国际上即将建造的最大综合孔径射电望远镜[3],得到全球天文学家的重点关注。平方千米阵列建在澳大利亚、南非及南部非洲8个国家的无线电宁静区,其接收面积可达1 km2,频率覆盖50 MHz~20 GHz。平方千米阵列作为下一代射电望远镜,具有极高的灵敏度(比央斯基甚大阵(Jansky Very Large Array, JVLA)灵敏度提高50倍,搜寻速度提高10 000倍),以千千米的基线获得极高的空间分辨率,以纳秒级的采样获得精细的时间结构,以10 Pb/s的速率产生超越全球互联网总量的数据。以宽视场、多波束、高动态、高分辨和大数据为核心概念的平方千米阵列将颠覆射电天文学的传统研究手段,给天文学研究带来革命性全新的理念。
平方千米阵列高分辨率、高灵敏度、高动态范围和宽视场等新特性,给数据处理带来了前所未有的挑战。平方千米阵列的巨大规模和复杂程度远远超出了现有射电天文望远镜阵列,全规模运行的平方千米阵列产生的海量数据需要10亿亿次/秒的处理能力,是目前世界上最快的超级计算机神威太湖之光处理能力(0.9亿亿次/秒)的10倍。考虑到计算效率和软件执行效率(目前天文软件在超算平台上的执行效率普遍在10%,甚至更低),实际需求将大大超出这个理论估算[4]。
为了充分利用计算资源,确保数据处理流程的可靠性,近5年来,平方千米阵列的科学数据处理器(Science Data Processor, SDP)一直在研究与测试执行框架(Execution Framework, EF)技术,以期找到满足未来发展要求、性能突出的执行框架技术。其中,除了本文作者所在项目组参与的DALiuGE等相关工作[5-6]以外,也一直在研讨商用执行框架如Spark[7-8],ASK[9]的可用性。本文针对这方面的工作,细致讨论了Spark执行框架在未来平方千米阵列科学数据处理中的可用性。
1 研究动机与需求
1.1 研究动机
Spark于2009年诞生于加州大学伯克利分校AMPLab,已经成为Apache软件基金会旗下的顶级开源项目。相对于MapReduce上的批量计算、迭代型计算以及基于Hive的SQL查询,Spark可以带来上百倍的性能提升。目前Spark的生态系统日趋完善,Spark SQL的发布、Hive on Spark项目的启动以及大量大数据公司对Spark全栈的支持,让Spark的数据分析范式更加丰富。Spark与Hadoop的MapReduce计算框架类似,但相对MapReduce而言,Spark的特点更为突出,如具有可伸缩、基于内存计算等特性,可以直接读写Hadoop上任何格式的数据,在进行批处理时更加高效,延迟更低。目前已经成为轻量级大数据快速处理的统一平台。这其中,弹性分布式数据集(Resilient Distributed Datasets, RDD)是Spark的核心,弹性分布式数据集是一种分布式的内存抽象,表示一个只读的记录分区的集合。特别需要关注的是, Spark是基于内存计算的大数据并行计算框架,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。这对于当前平方千米阵列科学数据处理来说,基于全内存与廉价集群的方式非常有吸引力。
算法参考库(1)https://github.com/SKA-ScienceDataProcessor/algorithm-reference-library是由射电天文科学家Tim Cornwell领衔开发的射电干涉阵数据处理算法验证库,用于为后续平方千米阵列的数据处理提供算法验证。目前,算法参考库基于Python语言,已经实现了射电干涉阵处理的主要算法,全部程序开源,供射电干涉阵数据处理参考使用。自2018年平方千米阵列完成主要工作包的关键设计评估,进入桥接阶段后,算法参考库已经成为系统学习、研究平方千米阵列数据处理的基础参考库。
针对平方千米阵列一期中频阵可见度校准问题,当前的算法参考库中,实现了一个全串行的MID1 ICAL管线,分为预测、校准、反馈、去卷积4部分。MID1 ICAL管线的特点如下:
(1)逻辑任务同时具有数据密集型和计算密集型的特性;
(2)逻辑任务之间存在数据依赖,且任务之间通讯量巨大;
(3)需要多次迭代完成,并且两次迭代之间数据需要大量更新;
(4)现有存储条件无法长时间保留原始数据,需要在一个观测周期内完成管线的执行。
为了满足平方千米阵列后续建设工作,如何将这样的串行代码移植到分布计算框架下,并分析其实现方法和性能变化,深入了解不同算法在分布计算框架下的实现方式与性能评价,对于后续科学数据处理有重要作用,这也正是平方千米阵列桥接阶段的工作重点,需求非常迫切。
1.2 处理需求
平方千米阵列一期中频有197个天线,最大基线长度120 km。低频有130 000个天线,最长基线长度40 km。预计平方千米阵列一期的数据注入速度约为2 TB/s。为进行实验与性能分析,本文以中频天线设计指标为基础,定义基线数19 306个,8 192个通道,每个通道宽度800 MHz,4个极化以及36个采样时间,总计算任务28 800个。
在未来的系统部署中,成像管线(Imaging Pipeline)和非成像管线(Non-Imaging Pipeline)是其中的两个重点。成像管线包括可见度函数接收、可见度函数预处理、实时校准、快速成像、瞬变源候选体检测、数据缓冲等。非成像管线包括接收脉冲星守时特性文件、脉冲星候选体接收、瞬变观测缓冲、脉冲星守时处理等。从当前平方千米阵列的建设看,这些管线的研制是整个数据处理系统的核心。本文讨论的管线,是实时校准管线的一个关键部分。
2 软件实现与关键技术
2.1 代码基本流程
图1给出了成像和校准管线单一通道对应的逻辑任务,将这样的逻辑任务由串行转为分布计算,最关键的是将原来可以紧耦合的功能转变为松散耦合的模块。重点说明Reppre_ifft和Degrid功能部分和Pharotpre_dft_sumvis功能部分。
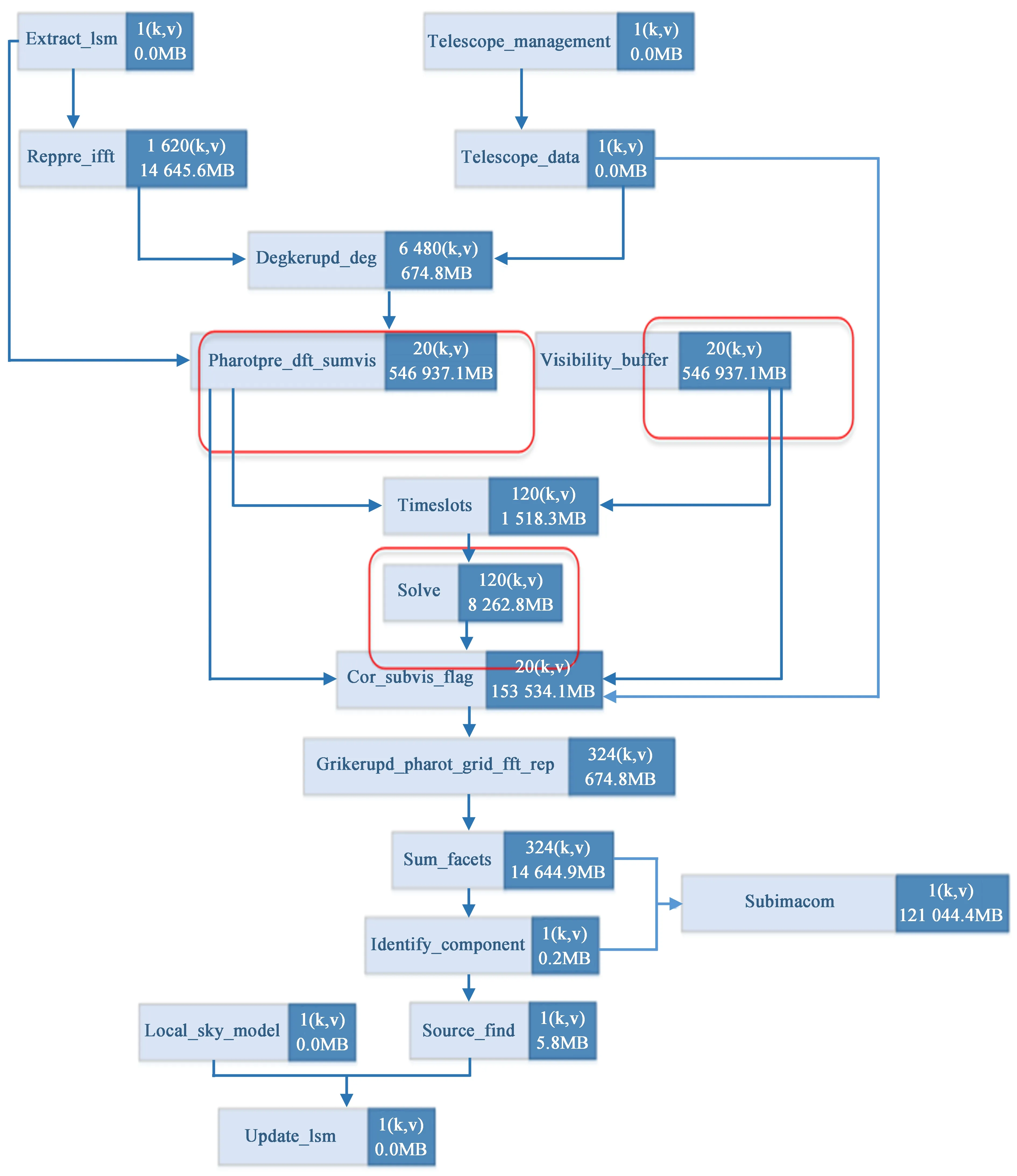
图1 MID1 ICAL管线单一通道对应的逻辑任务,括号内是需要处理的数据量
2.2 Reppre_ifft和Degrid代码实现
Reppre_ifft和Degrid阶段是根据局部天空模型,预测观测天空的可见数据,开发中利用了算法参考库函数。这一部分并行的实现方法是对频段、分片、时间片等进行数据分片。最终对于MID1 ICAL管线,采用以单个频段(不同频段可以并行处理)分拆任务的方法实现分布并行计算,Reppre_ifft任务和Degrid任务的关系如图2。
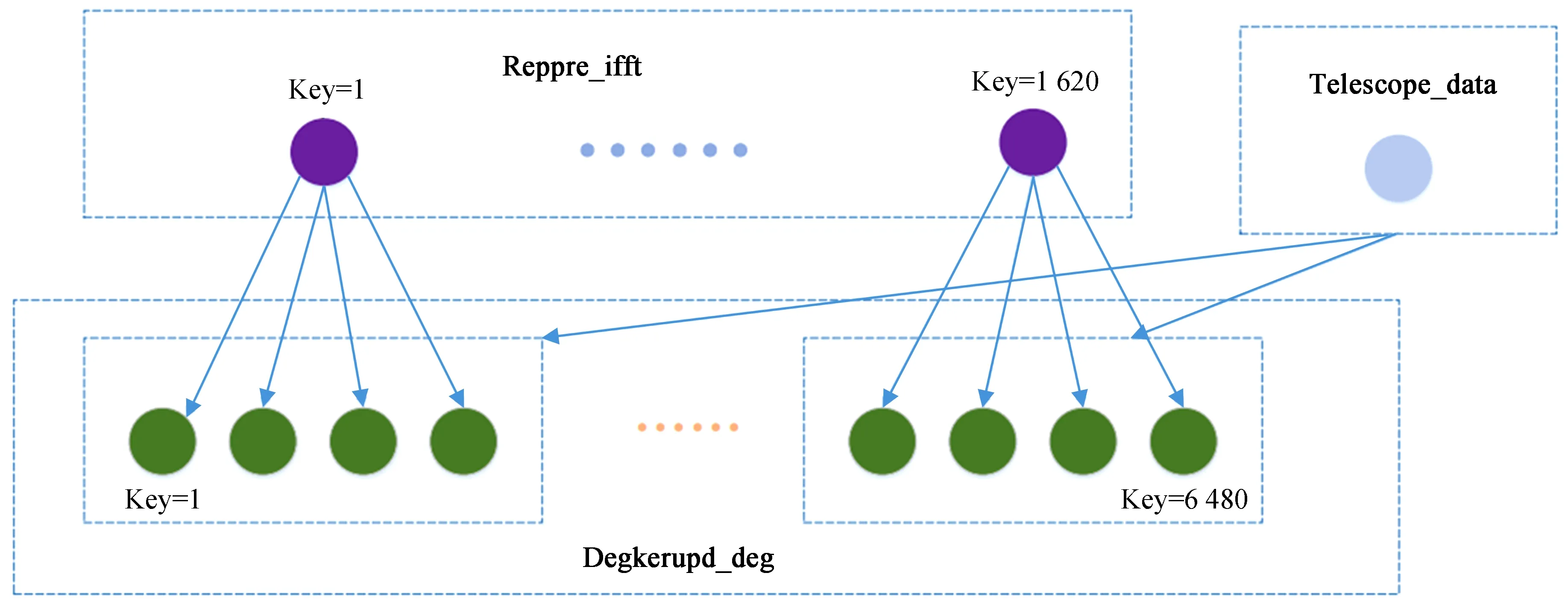
图2 Degkerupd_deg阶段任务依赖关系图Fig.2 The dependency diagram in Degkerupd_deg phase
Reppre_ifft阶段主要是对图像类和Skycomponent的处理,整个过程的输入是图像和Skycomponent,输出是图像,并送入下一阶段。代码基本调用过程包括:
(1)arl/skycomponent/operations/insert_skycomponent:将skycomponent中的信息按照nchan和npol两个轴插入到图像,关联函数包括:insert_function_sinc, insert_function_L, insert_function_pswf, insert_function_array;
(2)arl/fourier_transforms/fft_support/fft:对图像进行傅里叶变换;
(3)arl/image/operations/reproject_image:将切片后的图像按照新的世界坐标系统进行重投影;
(4)arl/image/iterators/raster_iter:Image的切片函数
Degrid阶段主要是对图像中的数据进行卷积,具体卷积的过程和可见度数据相关,并将结果放入本来为空的Visibility类的Data属性中。
在卷积之前,图像先被填充到切片之前的大小,即在它的周围填充0。然后整个矩阵再和前一步在get_kernelist中得到的griding correction function做一个点对点的乘法,对得到的结果再做快速傅里叶变换,就得到了通道化的图像,这个通道化的图像接下来将被卷积。
在分布执行后,最终用以下方法合并Reppre_ifft和Degrid任务。
sc.parallelize(initset).flatMap(ix=>reppre_ifft_degrid_kernel(ix, broads_input_telescope_data, broadcast_lsm))
这里initset是六元组(beam, major_loop, frequency, time, facet, polarisation)。
2.3 Pharotpre_dft_sumvis
为了避免RDD Pharotpre_dft_sumvis的一个
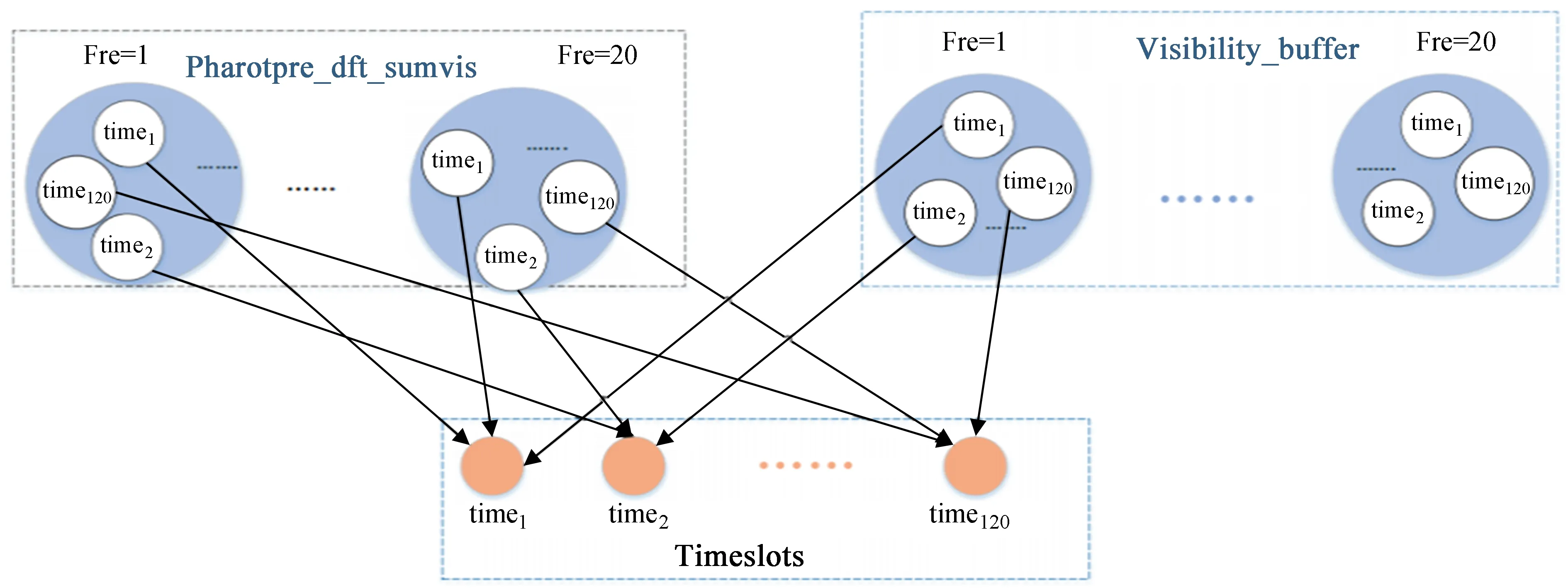
图3 时间槽阶段任务依赖关系图Fig.3 The dependency diagram in Timeslots phase
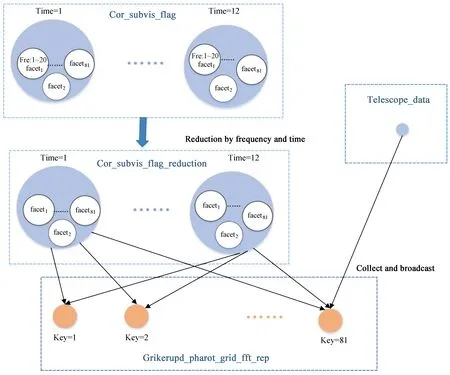
图4 grikerupd_rep阶段任务依赖关系图Fig.4 The dependency diagram in grikerupd_rep phase
平方千米阵列管线的每个任务输入输出大小以及计算量都是确定的。能够准确计算出每个任务具体的输入输出数据、中间数据的大小, 以及每个任务的计算量,对于分布式计算的任务调度具有指导意义。管线数据建模的依据是对每一个管线中的逻辑任务,通过分析所采用算法的复杂度,并且计算输入输出的大小。
3 系统部署与测试
3.1 环境配置
测试中采用3套不同配置的集群作为测试环境,集群1包括1个节点,该节点配备1.5 TB内存,中央处理器为80核,每个核主频为2.2 GHz。集群2包括4个节点,每个节点配备64 GB内存,中央处理器为8核,每个核主频为1.8 GHz。软件系统中Spark的版本为2.0,JDK版本为1.8。
3.2 性能测试
本文分别对单机串行程序和基于Spark的程序进行了测试,串行程序完全在集群1的高配环境中完成,最终的执行时间见图5。
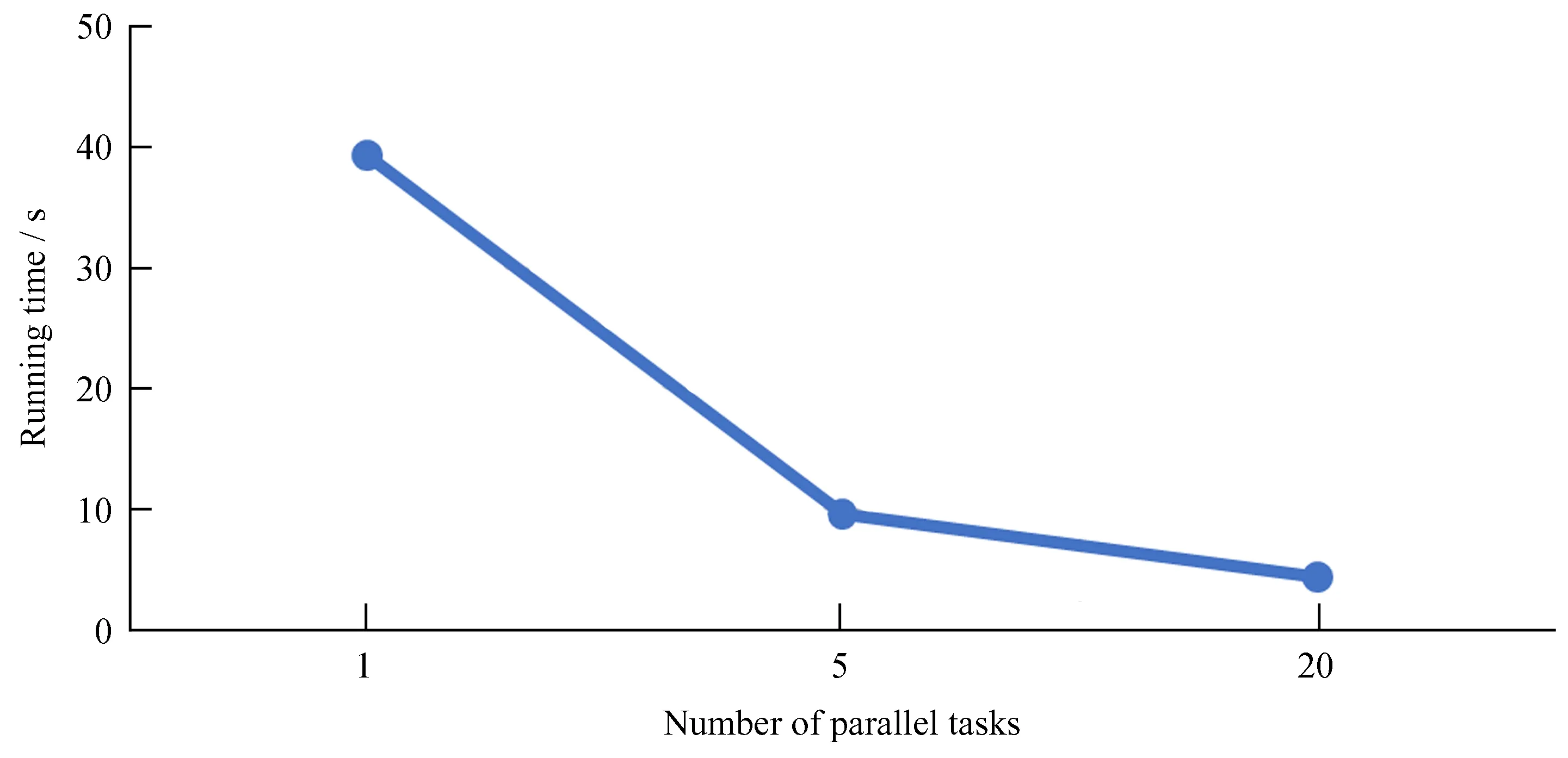
图5 性能对比示意图,在3个进程数下执行的时间对比Fig.5 The contrast diagram of execution time elapse with 3 different process number
4 结论与未来工作
Spark是当前工业界最流行的分布式执行框架之一。实验表明,基于Spark构建平方千米阵列的分布式执行框架是有可能的,但Spark存在一些很实际的困难,具体说明如下:
(1)Spark考虑更多的是数据密集型,它的任务调度和资源管理目前只支持中央处理器,需要更改其任务调度和资源管理代码来支持混合计算任务的调度。研究发现,Spark性能瓶颈在于数据的连接操作,Spark的 “cogroup” 需要对几个大的数据集进行排序操作,产生大量的节点通讯。另外,弹性分布式数据集链过长,内存不能及时释放,Spark内存不足时,数据需要写到磁盘,序列化与反序列化耗费大量时间。Spark cogroup和groupByKeys需要排序操作,耗费大量内存。从这方面看,Spark要满足平方千米阵列的建设要求存在较多待改进的地方。未来可以在如下几方面继续进行性能优化:
1)增大内存。Spark内存不足时,数据需要写到磁盘,序列化与反序列化耗费大量时间。Spark的cogroup操作需要内存排序,耗费内存资源;
2)利用分布式缓存系统替换cogroup操作;
3)利用分布式缓存系统存储部分弹性分布式数据集的内容,打破长弹性分布式数据集链,及时释放内存资源;
4)利用Spark的Partitioning操作代替cogroup, Partitioning可以做到数据重组。同时设计分区函数,较少连接操作。根据射电数据处理的特点,在预测阶段,设计根据频率的分区函数,需要将同一频段的可见度数据聚集在一起,按照频段进行分区,可以避免连接操作。在去卷积阶段,设计根据分片的分区函数,避免连接操作。
(2) Spark的数据划分性能存在严重缺陷,数据划分是MapReduce框架中的一个特定的phase(分阶段),介于Map phase和Reduce phase之间,当映射的输出结果要被规约使用时,输出结果需要按key哈希,并且分发到每一个Reducer,这个过程就是数据划分。由于数据划分涉及磁盘的读写和网络的传输,因此,数据划分性能的高低直接影响整个程序的运行效率。针对天文海量数据处理的要求,Spark的数据划分的性能显然满足不了要求。拟采用内存数据库代替数据划分的相关操作,可以进一步提高Spark的并行计算性能。这是后续研究的重点。
