海量数据下广义线性模型参数的聚合估计算法研究
2020-07-23陈少东李志强
陈少东,李志强
(北京化工大学 数理学院,北京 100029)
一、引言
Nelder和Wedderburn等在研究指数族分布时引入广义线性模型[1]。该模型涵盖了许多常用的统计模型,如:经典线性模型、对数线性模型、Logistic模型和Probit模型等。广义线性模型既可用于刻画连续型数据,也可用于刻画计数数据、属性数据等离散型数据,因此广泛应用于生物学、医学、经济学以及社会科学等领域。
广义线性模型的参数估计方法及其性质已经得到了深入地研究。然而,随着数据采集技术的迅猛发展,可用于分析的数据呈现海量化趋势。传统的估计方法在解决海量数据下模型的参数估计问题时常常会遇到计算机存储空间不足等问题,因此,有必要探究新的算法来解决海量数据下广义线性模型的参数估计问题。
分治算法是当前解决海量数据下统计模型参数估计问题的主流方法之一,该算法采用分而治之的思想,首先将原始海量数据集划分为若干方便处理的小数据集,然后在每块小数据集上构造统计量将数据进行压缩,最后构造一个聚合算法将每块小数据集上的统计量聚合成海量数据集上的估计结果。分治算法可以解决模型实现过程中将所有数据一次性加载到内存中而带来的内存溢出问题。由于在每块小数据集的数据压缩过程中,数据块之间是独立进行的,所以该算法不仅适用于单机实现,也适用于并行实现。在实现时采用常用的海量数据处理工具Hadoop、Spark即可轻松实现并行。目前已有一些基于Hadoop和Spark的算法研究[2-4],这些研究结果都表明集群计算能有效提高计算效率。
分治算法已广泛应用于许多海量数据统计模型研究。其中,方方等研究了海量数据下基于分治算法的线性模型和广义线性模型的模型平均算法[5];Lin和Xi等提出了一种基于分治算法的海量数据非线性估计方程的估计思想,其处理步骤为[6]:首先将海量数据集划分为K块子集,然后在每块子集上基于估计方程将原始数据进行压缩,最后通过构造聚合估计方程把每块数据的压缩信息有效的结合起来,从而得到模型系数的聚合估计。
然而,针对海量数据广义线性模型的估计及其统计推断还有待于进一步深入研究。事实上,方方等[5]提出的平均估计难以进行有效的统计推断;而Lin和Xi仅研究了具有典则连接函数时聚合估计结果的渐近性质,并不适用于一般的广义线性模型。因此海量数据下具有一般连接函数的广义线性模型的估计算法与统计推断还有待于进一步研究。
本文将Lin和Xi提出的非线性聚合估计方法推广到具有一般连接函数的广义线性模型的估计算法之中,提出了模型系数的聚合拟似然估计算法。首先,将整个数据集划分为单机可处理的子数据集;其次,基于拟似然估计方程和Newton-Raphson算法的公式,将每块子数据集压缩为部分低阶统计量进行保存;然后根据保存的统计量和逼近的拟似然函数可构造出聚合估计方程;最后求解得到聚合拟似然估计。该方法避免了在估计时使用全部数据进行迭代计算,从而有效地克服了传统估计方法在海量数据下带来的计算机存储空间不足等问题。由于聚合拟似然估计方程把每块子数据的压缩信息有效的结合起来,所以得到的聚合估计要比仅对每块数据的估计结果做简单的算术平均更能有效地利用样本数据信息。而且根据定理1可以看出,当子数据集的数量控制在一定范围内时,聚合拟似然估计与基于全部数据得到的拟似然估计是渐近等价的,因此可以得到良好的统计性质。模拟结果表明,聚合拟似然估计算法不仅在解决存储空间不足的同时提高了计算效率,而且有效地应用于集群计算中。
二、广义线性模型及其估计方法
若随机变量Y的概率分布或概率密度函数满足如下形式:
其中a(·),b(·),c(·)为已知函数,θ称为典则参数(Canonical Parameter),φ称为扩散参数(Dispersion Parameter),则称Y服从指数族分布。
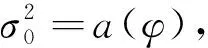
设(Yi,Xi),Xi∈Rp,i=1,2,…,N,为来自(Y,X)的独立样本,对于给定的X=xi,若满足:
(1)条件密度函数f(yi|X=xi)服从指数族分布;
(2)设μi=E(yi|X=xi)为yi的数学期望,若存在已知的单调、可微函数g(·)满足:
这里β∈Rp为未知参数,g称为连接函数,则称(Y,X)服从广义线性模型[7]。
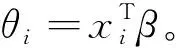
在广义线性模型的建模过程中,常用的连接函数有[7]:
(1)恒等函数
g(μ)=μ,(μ∈R)
(2)对数函数
g(μ)=lnμ,(μ>0)
(3)Logistic函数
g(μ)=ln(μ/(1-μ)),(0<μ<1)
(4)Probit函数
g(μ)=Φ-1(μ),(0<μ<1)
(5)重对数函数
g(μ)=ln(-lnμ),(μ>0)
(6)互补重对数函数
g(μ)=ln(-ln(1-μ)),(0<μ<1)
其中,Φ为标准正态分布的累积函数。针对某个具体的广义线性模型,绝大部分都是非典则连接函数,因此其在海量数据下的估计方法与统计推断更具有一般性。
为了估计模型的未知参数β,将对数似然函数关于β求导可得到估计方程:
(1)
利用以上表达式,当Y的指数族分布未知时,通常采用以下的拟似然估计方程方法。
设Q(μ,x)为拟似然函数[7],满足条件:
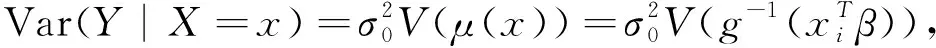

=GTV-1(Y-g*)=0
(2)
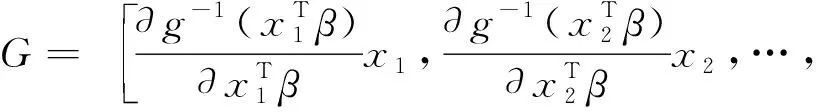
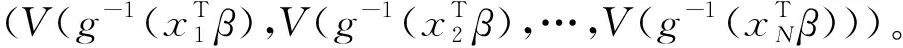
(3)
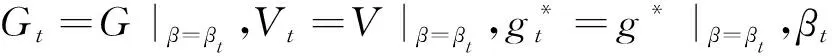
Newton-Raphson算法在求解过程中,每一步迭代需使用全部观测数据,在观测数N很大时,可能存在内存不足等问题,因此有必要在海量数据情形下对该算法进行改进。
三、海量数据下的拟似然方程估计算法
(一)AQMLE算法
现给出聚合估计方程方法的思想。首先基于全部数据的拟似然估计方程为:
(4)
(5)
(6)
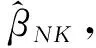
(7)
(8)
(二)AQMLE算法实现
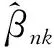
AQMLE算法的计算量主要在数据压缩步骤,而对于每一块子数据集,因为在数据压缩步骤没有数据块与数据块之间的通信问题,所以很适合通过并行算法实现。在海量数据下,Hadoop与Spark是常用的处理工具,这些工具以集群的方式来完成海量数据的计算问题。
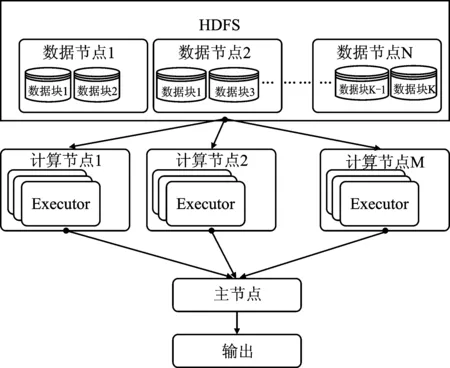
图1 并行计算流程
四、AQMLE估计的渐近性质
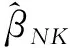
条件1.均值函数g-1(·)三阶连续可导且一阶导不为零;
条件2.方差函数V(·)>0且二阶连续可导;
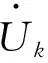
条件4.x为固定设计且一致有界;
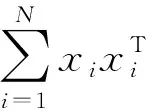
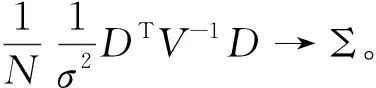
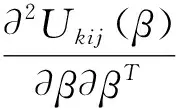
(9)
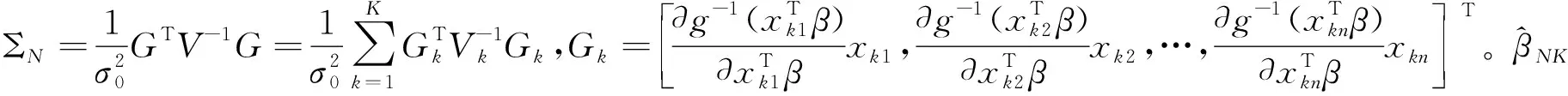
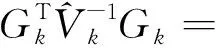
(10)
注:当广义线性模型(1)中的连接函数为典则连接函数,根据指数族分布和广义线性模型的定义可知,模型的条件数学期望、方差函数满足以下条件:
(11)
通过直接计算可证:
因此拟似然估计方程(4)可简化为:
(12)
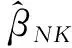
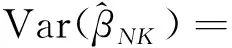
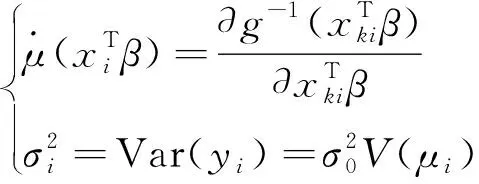
结合式(11),通过直接计算可得:
再由式(12)可知,对于具有典则连接函数的广义线性模型,本文定理2的结论可简化为与Lin和Xi定理5.2一致的结论。
五、数值模拟
本节对AQMLE算法进行模拟检验,以检验算法的有效性。模拟分为两个部分,第一部分是在普通单机环境下,AQMLE算法的结果分析;第二部分是在普通单机组成的Spark集群下,AQMLE算法的结果分析。有效性将从时间消耗与估计精度两个角度来衡量。模拟时,我们选择了常用的两点分布,设yi|xi~b(1,pi),其中pi可以通过以下两种方式来建模:
(1)在典则连接下,有Logistic模型:
i=1,2,…,N
(2)在非典则连接下,选择Probit模型:
其中Φ(·)为标准正态分布的累积函数。下面用本文所提出估计方法分别对上述两个模型进行模拟计算,并通过计算结果分析估计方法的有效性。
(一)单机计算
在单机情况下,取数据量N=3×106,β0的维数为32,分块数K在1到300之间,自变量独立同分布,服从标准正态分布。本次实验在Ubuntu16.0.4操作系统下使用Python3.7.0完成,所有实验重复50次取平均值作为最终结果。
表1(a)和表1(b)给出的是算法在不同分块数K下的计算时间和估计偏差结果。首先关注计算效率部分,从表中可以看出,两个模型计算消耗的时间都随着K的增大先下降后趋于稳定。当K=1时,计算消耗的时间最多,在K=10时,计算速度有显著提升,而当K继续增大时,由于分块计算本身会带来程序的开销,所以计算效率不再上升,会逐渐趋于稳定状态。在Logistic模型中,算法将计算效率提升了30%左右,而Probit模型的计算效率提升了20%左右。
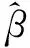
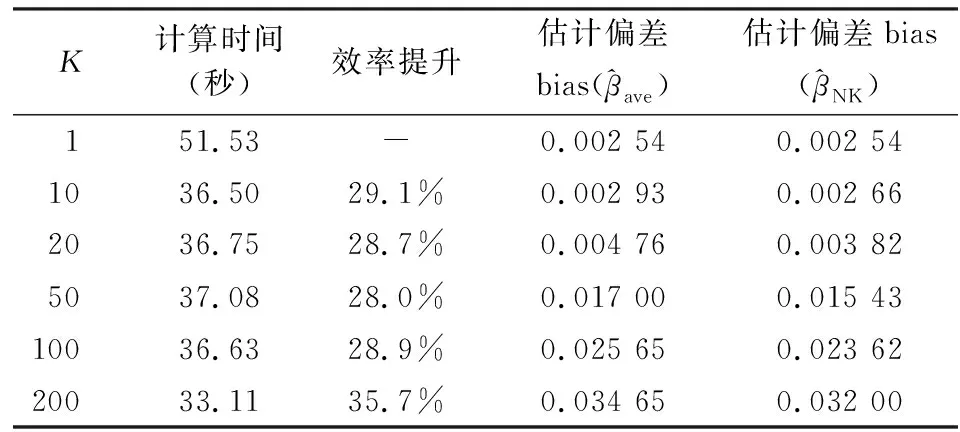
表1(a) Logistic模型在单机环境下取不同K的试验结果
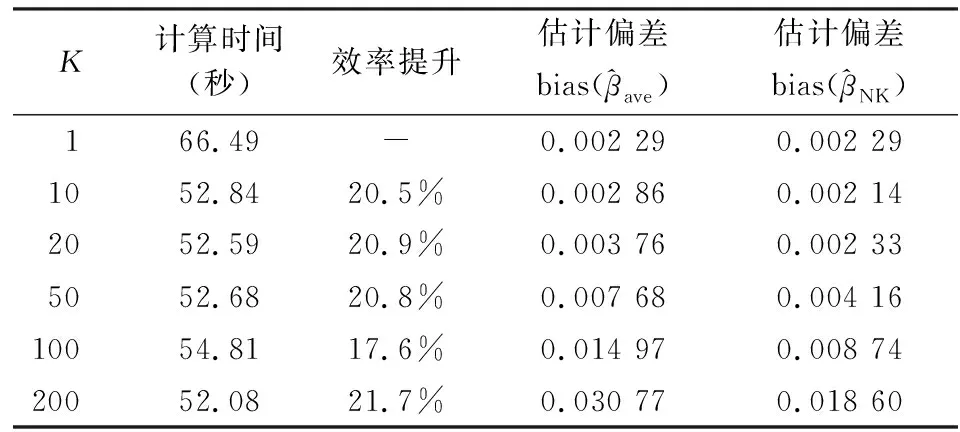
表1(b) Probit模型在单机环境下取不同K的试验结果

表2 不同K下随机抽样估计优势比例表
(二)集群计算
在实际中,面对GB甚至是TB级别的数据量时,数据可能是以分布式的方式存储在多台计算机上的。幸运的是,本文的AQMLE方法在分布式框架上的实现是简单的。这部分我们将在Spark计算框架下进行模拟。
本次实验使用的模型及数据规模仍与单机计算时一致。实验在Ubuntu16.0.4下通过4台普通计算机组成的Spark集群来完成,计算环境为Python3.7.0、Hadoop2.7.7及Spark2.3.2。其中,计算节点的配置为3.40GHzCPU、4G内存、8核。
表3展示的是Spark集群下的计算结果,该表给出了不同分块数下Logistic模型和Probit模型的计算时间。如表所示,两个模型的实验结果大致相同:计算消耗的时间先有一个下降趋势,然后趋于稳定。当分块数K取值过小时,由于部分计算资源被闲置,会导致计算时间略高。但是,之后随着计算资源的充分利用,计算时间逐渐下降,此时集群的计算效率明显优于单机环境。
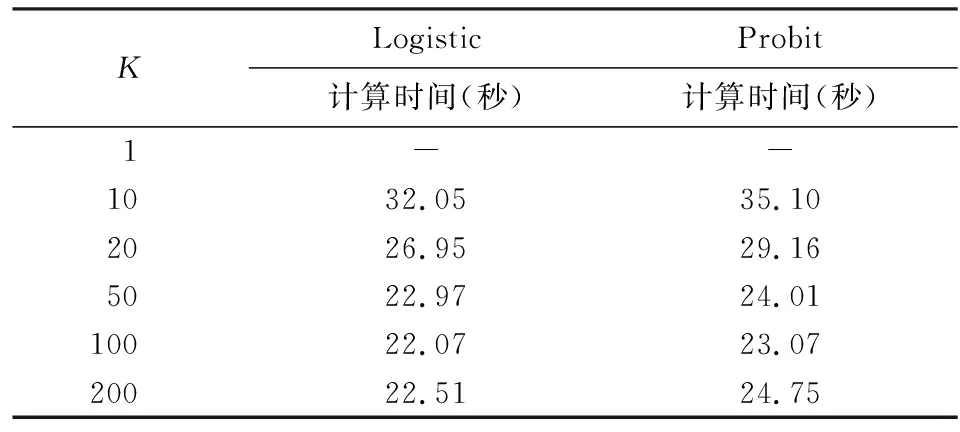
表3 集群环境下实验结果
六、实证分析
本节,我们使用来自UCI数据库的SUSY数据集(http://archive.ics.uci.edu/ml/datasets/SUSY)建立Probit分类器,以此来检验AQMLE算法在实际应用中的可行性和有效性。SUSY数据集是一个超对称粒子数据集,在高能物理领域非常受欢迎,由P.Baldi等首次使用[9]。该数据集共包含500万个样本,每个样本有18个特征及1个标签,具体数据可通过UCI数据库下载。该分类任务是为了判断通过撞机碰撞后产生的粒子是否是感兴趣的粒子。数据中前8个特征由加速器中的粒子测量仪测量得到,后10个特征是物理学家构建的用于提高分类准确率的组合特征。
本次实证分析分别基于前8个特征(记为lo-level)、后10个特征(记为hi-level)以及所有特征(记为lo+hi-level)构建Probit分类器,并用前450万条数据做训练集,后50万条数据做测试集。我们选择机器学习常用的ROC(Receiver Operating Characteristic)曲线来刻画得到的Probit分类器的性能,并用AUC值(Area Under the Curve)作为评价指标来进行结果分析。通过对K取K=1,20,…,100,200进行比较,发现基于上述三组特征构建的Probit分类器的分类效果并不受K取值的影响,同一组特征构建的Probit分类器在不同K值下的AUC值是一样的,结果如表4示。该结果进一步表明AQMLE算法在处理海量数据的问题上是可行。

表4 不同特征下分类器的AUC值

图2 ROC曲线图
从图2中我们可以看到仅使用lo-level特征训练的分类器比仅使用hi-level特征训练的分类器的效果要差得多。然而,仅使用hi-level特征训练的分类器比使用lo+hi-level特征训练的分类器具有更弱的性能。这表明了基于lo-level特征构建的Probit分类器没有足够的能力识别标签,而基于hi-level特征构建的Probit分类器很大程度上提高了识别标签的能力,但hi-level特征也丢失了lo-level特征中部分可用于解释标签的信息,该实验符合Baldi P等(2014)中给出的结论。
七、结论
本文提出了一种基于分治算法和Newton-Raphson迭代算法的方法用于处理海量数据下的拟似然估计问题,目的在于解决海量数据参数估计带来的存储问题和计算效率问题。首先,将整个数据集随机划分成K块,基于Newton-Raphson算法将每块子数据集通过构造统计量的方式进行压缩并保存;然后基于保存的统计量导出整个数据集的聚合估计,记为AQMLE。分治算法符合并行计算的思想,因此AQMLE算法适用于超大规模的并行化问题。本文证明了当K以一定速度趋于无穷时,基于AQMLE算法得到的估计结果仍具有渐近正态性。模拟与实证分析表明,AQMLE算法在解决计算过程中的存储问题的同时提高了计算效率,且估计结果要优于随机抽样和平均方法,而基于集群的实现方法可进一步提高计算效率,因此,本文的工作可为海量数据下的模型参数估计问题提供一些参考。
