安全态势感知系统中K-Means算法的并行化研究
2020-07-21江佳希谢颖华
江佳希,谢颖华
(东华大学 信息科学与技术学院,上海201620)
0 引言
随着大数据时代的来临,SQL注入攻击、XSS攻击等网络安全事件层见叠出,给网络安全带来了巨大的挑战。日志记录着设备运行状态,各种安全事件都会在系统中留下日志记录,通过对日志进行分析,可以挖掘重要信息,实时掌握网络安全状况,既可做到事前防护,又可做到事后追本溯源及责任追查。
本文设计的安全态势感知系统将采集到的日志文件送至分布式文件系统HDFS进行存储,在Hadoop架构上将改进的K-Means算法和MapReduce高效的并行计算能力相结合,对存储的日志进行聚类和分析。安全态势感知系统可以实时监控网络安全态势,实现日志分析追责,有效地减少网络安全事故的发生。系统采用高可用部署模式,具有可靠、易拓展、易维护以及可视化的特点[1]。
1 系统总体架构及工作原理
1.1 总体架构
基于Hadoop大数据架构的安全态势感知系统通过对安全日志的实时分析,可以对网络安全环境实现实时监测。针对现存威胁,系统以实时和统计的方式对安全告警进行展现,针对未知威胁,系统从外部威胁和脆弱性两个方面进行预警。
安全态势平台的总体软件架构由数据层、分析层、展示层三部分组成。数据层处于整个系统框架的底层,主要完成的是数据源的采集与存储,将不同来源的日志切成大小相同的数据片后送到各个节点。分析层调用Map和Reduce函数库将任务进行拆分作并行计算,结合K-Means聚类算法进行聚类结果分析。在展示层,用户可以用Hive语句查询结构化的数据,对于非结构化的数据,可以用MapReduce进行分析[2]。系统架构图如图1所示。
1.2 系统工作原理
安全态势感知系统包含四个模块,分别是数据采集、数据处理、安全分析以及态势呈现模块。系统的功能模块图如图2所示。
数据采集模块用Flume采集器收集系统日志,利用web+ssh获取采集程序的状态,将不同数据来源的日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统HDFS中,实现各种网络设备、安全设备、服务器、应用服务等设备的日志采集,在HDFS底层,对日志进行切片,一般默认切片大小为64 MB,存放至不同的数据节点。数据处理模块采用kafka集群,对采集到的数据进行预处理,预处理过程中首先对数据进行清洗过滤,通过指定过滤规则,将重复数据、噪声点以及不合理的数据从数据集中去除,然后对异构原始数据作格式统一处理,最后补齐字段、做数据标准化等处理,并将标准数据加载到HDFS系统中。安全分析模块是安全态势感知系统的核心,通过制定风险模型,对预处理后的数据集进行聚类和分析,将并行化编程模型MapReduce与改进的K-Means聚类算法相结合,完成对日志的聚类分析并形成追责证据链,可以识别恶意扫描、SQL注入攻击、XSS攻击等威胁事件在内的多类安全事件。态势呈现模块呈现将安全数据按各种场景分析之后得出的结果,利用各类图表直观地展现数据分析结果[3]。
2 K-Means算法及其改进
2.1 K-Means算法
K均值聚类算法(K-Means Clustering Algorithm)由James MacQueen在1967年提出,基于相似度和距离这两个方面的技术已经非常成熟,而且由于实现简单、收敛速度快,K-Means算法常用于日志挖掘。K-Means算法的主要思想是将用户与服务器交互的各维数据作为特征进行聚类,对一部分非数值类型的特征需要进行转化和标记,使其适用于与质心之间的距离的计算[4]。传统的K-Means算法将用户的数据集O和K值作为输入,随机自动选取K个聚类中心,通过距离计算将数据点划分到离它最近的聚类中心所在的簇,直至收敛,输出K个簇。算法描述如下:
(1)输入 K值和数据集 O。
(2)从数据集O中选取K个值作为初始聚类中心,记为 X1,X1,…,XK,选取方式为随机选取。
(3)将已经被选为聚类中心的点从数据集中去除,新的数据集记为 O1。
(4)对于 O1中的数据点,计算其到K个初始聚类中心的欧式距离,按照就近原则将数据点划分到距离最近的簇中。
(5)K个簇初步划分完成后,计算簇内均值,记为新的聚类中心,重新计算数据点到中心点的距离,进行新一轮的划分,直至通过准则函数判断聚类中心点收敛,聚类停止,否则迭代更新中心点。
(6)输出 K个类簇。
2.2 改进K-Means算法
安全态势感知系统要实现实时告警和威胁预测功能,要求算法具有可伸缩性,不管是处理小数据集还是大数据集,都要具有高效的特点。同时,安全态势感知系统要求算法准确率高,对于干扰点能准确识别并去除[5]。
传统的K-Means算法采用单机部署,执行效率低下,且K-Means的性能与聚类中心的位置关系很密切,初始聚类中心的选择极大程度地影响聚类效果。由于传统K-Means算法在选取初始聚类中心的随意性,假如将孤立点选为聚类中心,聚类准确性会大打折扣,同时算法循环迭代次数也会增多,且少量的孤立点会使得类内均值计算出现大的偏差。
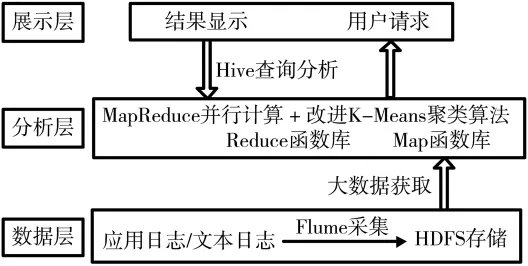
图1 系统架构图
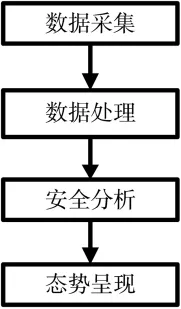
图2 功能模块图
针对K-Means在数据处理方面的缺陷,本文提出一种改进K-Means算法。新算法在去除孤立点干扰、寻找合适的聚类中心、判断中心点收敛的方式等方面做出了改进,改善了传统K-Means算法耗时长、执行效率低等问题[6]。改进后的算法流程图如图3所示。

图3 改进K-Means算法流程图
改进K-Means算法描述如下:
(1)设数据集中数据量为 m,定义 Ai为数据点到数据集中其他点的距离之和,计算公式如下:


扫描数据集,寻找符合 Ai>min Ai+的数据点,由于数据点距离和远远大于均值,将其认为是孤立点,从数据集中去除。min Ai为距离和的最小值,数据点到数据集中其他点的距离和越小,证明该点周围聚集的数据点越多,即密度越大。记去除孤立点后得到的新的数据集为P,新数据集中的数据量记为q。
(3)将符合Ai<-min Ai且距 X1最远的数据点 X2作为第二个聚类中心,确保X2和 X1来自于两个不同的簇,同时将X2从集合P中去除。此处将符合Ai<-min Ai的数据点定义为高密度点。
(4)在高密度区域,即符合 Ai<min Ai条件的数据集中寻找与前两个数据点距离之和最远的数据点X3作为第三个聚类中心,并将X3从P集合中删除。
(5)依次类推,在高密度区域寻找与已确定的簇中心距离之和最大的数据点,同时将这些点从集合P中去除,直到K个聚类中心搜寻完毕。
(6)对于P中剩余的数据点,分别计算其到K个中心的欧式距离,根据就近划分原则将数据点都划分到离它最近的簇中。
(8)各个饱和类簇分别计算簇内各个维度的算术平均值,形成新的聚类中心。
(9)计算新一轮迭代和上一轮迭代的DBI指标值,分别用 DBIn和 DBIo表示,若 DBIn<DBIo,则开始新一轮的迭代,直到 DBIn>DBIo为止。DBI计算方式如下:
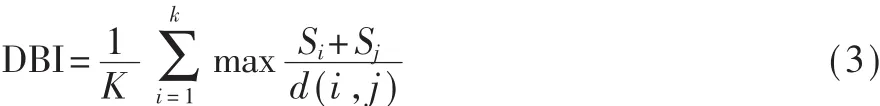
其中,Si代表第i个聚类中数据点与聚类中心的标准误差,Si越小代表类内相似度越高。d(i,j)代表聚类中心之间的欧式距离,d(i,j)越大代表类间距离越大,类间相似度越低。DBI可以描述聚类效果,DBI的值越小,代表类内相似度高,且类间相似度低,聚类效果越好[7]。
2.3 改进算法的并行化实现
MapReduce编程模型由谷歌提出,可以对大规模的数据集作并行运算。改进后的K-Means算法的迭代过程主要有两个步骤:(1)将数据集中的数据点进行分类;(2)计算中心点。由于数据点运算时完全独立,互不干扰,且计算中所用的公共变量不多,可采用MapReduce并行计算编程模型实现,一次迭代为一个任务,由 Map函数、Combine函数、Reduce函数实现,Map函数主要用于计算距离,对数据集中的数据点进行分类,Combine函数对Map函数输出的键对值进行合并预处理,Reduce函数以Combine函数的输出作为输入,负责重新计算中心点,判断是否符合阈值条件,不符合则开始新一轮的迭代[8]。实现过程如下:
(1)数据初始化,将日志文件进行 n维切片,将大小相同的数据块存入HDFS。
(2)将切片和副本送至对应的数据节点。
(3)节点调用Map函数提取出数据块,计算距离和,选择初始聚类中心,计算点到聚类中心的距离,得到K个聚类中心。
(4)前一阶段函数Map的结果进入combine阶段进行归并处理,为Reduce函数提供标准化输入。
(5)Reduce函数对输入的候选聚类中心计算新一轮迭代和上一轮迭代的DBI指标值,若DBIn<DBIo则开始新一轮的迭代,直到 DBIn>DBIo为止,判定中心点收敛,任务结束,否则,更新中心点并且开始新一轮的迭代。
MapReduce并行化流程图如图4所示。
3 实验结果与分析
为了体现改进K-Means算法的有效性和准确性,本文采用了传统的K-Means算法和改进后的并行K-Means算法对同一组数据集进行聚类。实验数据来自于某安全态势感知网站90天的日志文件,总计4.5 GB大小。日志在处理之前,需先经过标准化处理。例如,原始日志格式为:time:2019-12-15_13:42:30;danger_degree:1;breaking_sighn:0;event:[50193]某某入侵攻击;src_addr:192.168.10.244;src_port:138;dst_addr:192.168.10.255;dst_port:138;proto:UDP.NETBIOSDGM;user:xiaoming。
经过标准化、过滤、补齐、关联标签等流程后,日志数据如表 1所示[9]。
3.1 算法有效性验证
衡量改进后K-Means算法有效性的重要指标是观察算法的迭代次数和准确率相较于优化前有无改进。准确率=×100%,代表放入聚类簇中的数据点个数占数据 总数的比例。分别使用传统的K-Means算法和优化后的K-Means算法进行实验,结果如图 5、图 6所示。
从图5可以看出,由于采用MapReduce并行化架构,对于同一数据集,改进后的算法迭代次数少于传统K-Means算法,随着数据量的增大,优势更明显。
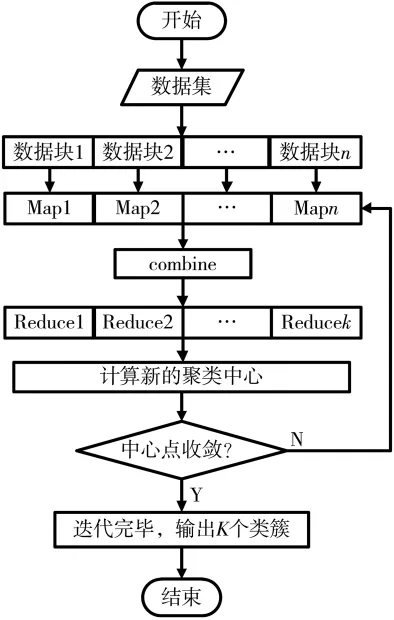
图4 MapReduce并行化处理流程
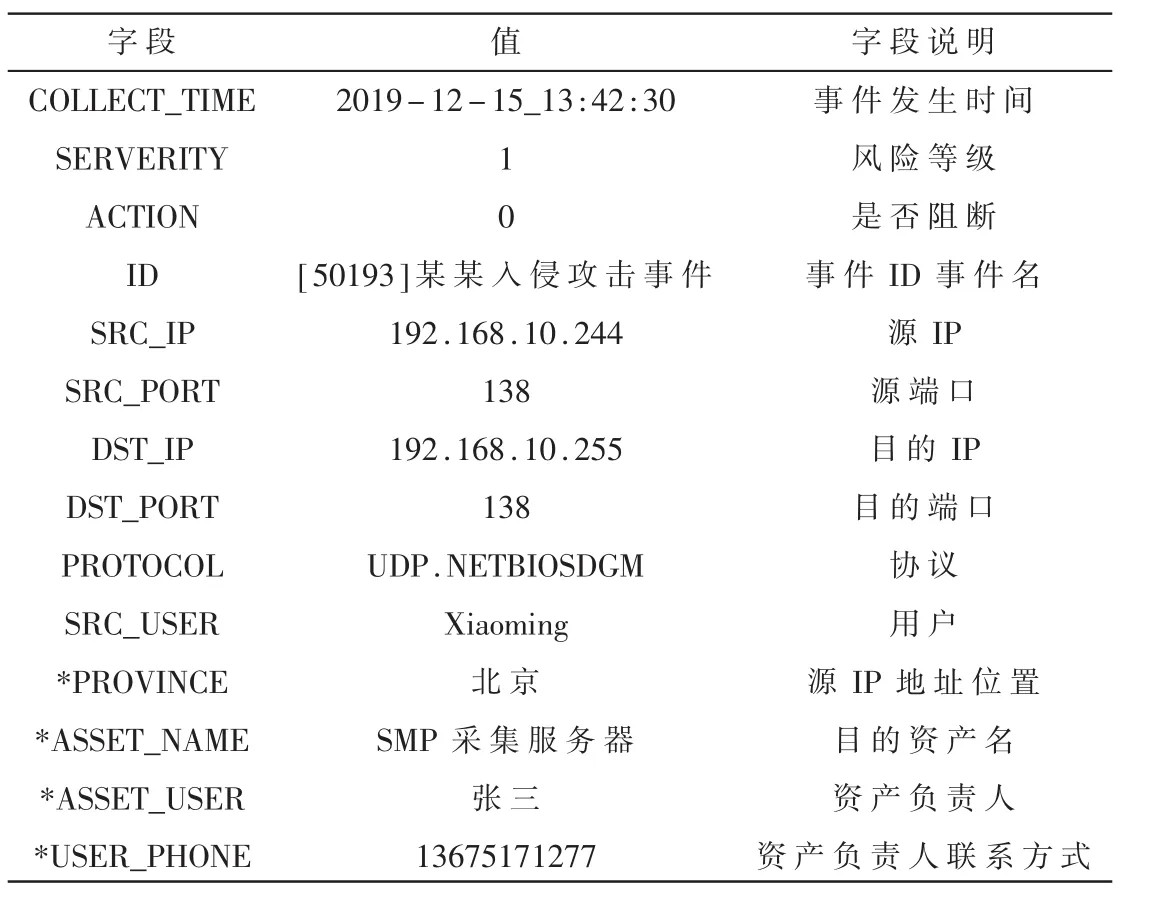
表1 预处理后的日志数据
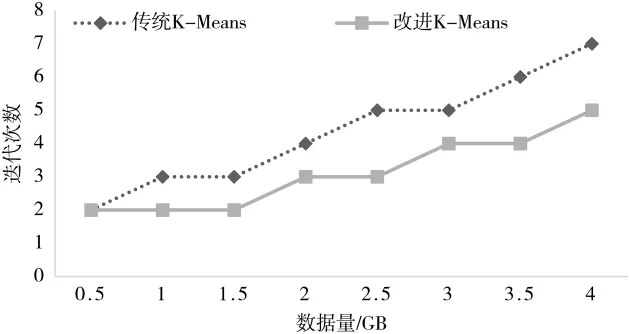
图5 传统K-Means算法与改进的K-Means算法迭代次数对比
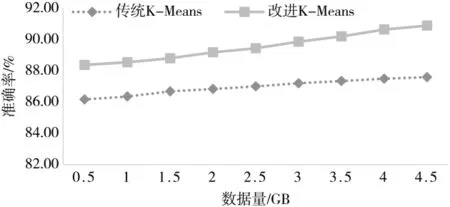
图6 传统K-Means算法与改进的K-Means算法准确率对比
从图6可以看出,改进后的K-Means算法准确率有所提升,有更多数据点被正确划分到类簇中,聚类效果更佳。
3.2 算法时间验证
算法聚类时间是另一个衡量算法性能的重要指标,针对同一数据集,算法耗时越短代表执行效率越高。本文将并行K-Means优化算法和串行传统K-Means算法在聚类时间上进行了对比,改变数据集的大小进行实验。实验结果如图7所示。
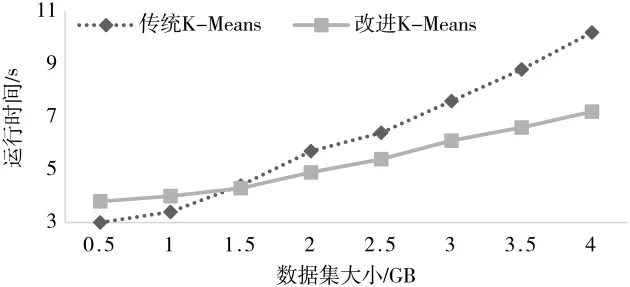
图7 传统K-Means算法与改进的K-Means算法聚类时间对比
由图7可以看出,当数据量较小时,传统K-Means算法稍快于改进并行K-Means算法,随着数据量增大到1.5 GB时,改进算法运行时间开始比传统算法短,且随着数据集的增大,优势越来越明显。产生这种现象的原因是当数据量较小时,改进K-Means算法采用了MapReduce并行架构,较传统串行算法更耗时,随着数据量的增大,改进算法对数据片进行并行处理的优势显现出来,算法运行时间大大缩短,证明了改进K-Means并行算法更适用于大数据处理[10]。
4 结论
本文提出的改进K-Means算法克服了传统K-Means算法在寻找初始聚类中心的随机性,克服了孤立点对聚类效果的影响,降低了算法时间开销,提升了执行效率,并基于MapReduce实现了并行化,使其适应于大数据处理要求。通过实验,证明了新算法在有效性和时间复杂度方面都优于传统K-Means算法。基于该算法实现的日志追责系统具有可靠性高、可拓展性强、执行效率高等优点,有一定的实用价值。
