基于插值法的对抗攻击防御算法
2020-07-18范宇豪张铭凯夏仕冰
范宇豪 张铭凯 夏仕冰

摘 要:深度神经网络(DNN)在预测过程中会受到对抗攻击而输出错误的结果,因此研究具有防御能力的新型深度学习算法, 对于提高神经网络的鲁棒性和安全性有重要的价值。文章主要研究应对对抗样本攻击的被动防御方法,提出基于插值法的对抗攻击防御算法(Interpolation Defense Algorithm,IDA),实验结果表明,本算法可以提高神经网络对于对抗样本的识别率。
关键词:对抗样本;防御算法;插值算法;机器学习
中图分类号: TP309 文献标识码:A
Abstract: The deep neural network (DNN) will output wrong results in the process of prediction due to the adversarial attack. Therefore, it is of great value to study a new deep learning algorithm with defense capability to improve the robustness and security of the neural network. This paper mainly studies the passive defense method against adversarial attack, and proposes the Interpolation defense algorithm (hereinafter referred to as IDA) based on the Interpolation method. Experimental results show that the algorithm can improve the recognition rate of neural network against adversarial examples.
Key words: counter sample; defense algorithm; interpolation algorithm; machine learning
1 引言
近年来,深度学习在图像识别领域发展迅速,神经网络对一些特定数据集的识别能力已经超过了人类的水平,并且深度学习的快速学习能力可以给大数据领域的研究提供帮助。然而,近期研究表明,深度学习给人们生活带来方便的同时也存在一定的安全问题。对抗样本(Adversarial Examples)概念是Szegedy[1]等人在2014年首次提出,这一问题在神经网络内部普遍存在。例如,在人脸识别系统中,通过有目标的攻击来伪造面部信息,攻击者能够骗过识别系统,进行非法身份认证。在自动驾驶领域,如果交通指示牌被人为恶意篡改,会导致汽车的识别系统做出错误的判断从而造成交通事故。因此,如何提高深度神经网络的安全性成为我们迫切需要解决的问题。
面对毫无准备措施的神经网络,对抗样本的攻击效果显著,Szegedy[1]等人的文章表明只需要对样本进行细微的调整就导致模型以高置信度给出一个错误的输出,并且这种变化通常是像素级别,人工无法检查出这种差别,使得对抗攻击可以在人类不知不觉中完成。对抗样本的出现证明现有的深度学习模型具有脆弱性,同时让人们反思深度学习是否真正地学习到了深层次的信息。所以研究更加强大的防御方法是人工智能未来的重要发展方向。
2 相关工作
基于防御策略的不同, 目前对抗样本的防御方法主要分为两种[11]:
(1)被动防御:在已有的深度神经网络的基础上检验对抗样本(IDA属于此类);
(2)主动防御:通过提高深度神经网络的鲁棒性和健壮性,消除对抗样本对神经网络的判别结果的影响。本节中我们主要讨论几种主动防御策略。
2.1 网络蒸馏
网络蒸馏[2,3]最初是一种将知识从大型网络转移到小型网络以减小深层神经网络规模的方法。后来,Papernot等人[4]提出了一种运用网络蒸馏从深度神经网络中提取知识以提高神经网络的鲁棒性从而防御对抗性样本的思路。他们发现对抗攻击主要针对网络敏感度,并且证明使用高温Softmax可以有效地降低模型对微小扰动的敏感度。Papernot对网络蒸馏防御进行了测试,成功将JSMA攻击在MNIST和CIFAR-10数据集上的成功率分别降低到0.5%和5%。此外,网络蒸馏还可以提高神经网络的泛化能力。
2.2 对抗训练
对抗训练将对抗样本混合到原样本中作为深度神经网络的训练数据,这是提高神经网络泛化能力的方法之一。文献[5,6]的作者尝试在训练阶段的每一轮训练中都生成一定量的对抗样本,并将其混入训练集中进行训练。实验结果表明对抗训练可以提高深度神经网络的鲁棒性,可以为深度神经网络提供规则化[5],同时也可以提高神经网络的精度[7]。
2.3 分类器鲁棒
文献[7,8]的作者都设计了一种鲁棒性强的深度神经网络架构用来防御对抗样本。基于对抗样本的不确定性,Bradshaw等人[8]采用贝叶斯分类器来构造健壮的神经网络,用具有RBF核的高斯过程(GPs)来提供不确定性估计,并将所提出的神经网络命名为高斯过程混合深度神经网络(GPDNN)。实验结果表明,GPDNN的性能與普通DNN相当,并且具有更强的防御对抗样本的能力。文献[9]的作者观察到深度神经网络通常会将对抗样本判别为一小部分不正确的类别,作者通过将这部分不正确的类别划分为子类别,并将所有子类别的结果汇总,有效防止对抗样本被误分类。
3 基于插值法的对抗攻击防御算法
对抗样本的原理是通过给原样本添加噪声使神经网络受到干扰,因为人眼仍可以正常识别出对抗样本的内容,所以对抗样本内的有效信息仍然是保留的,因此我们只要把对抗样本的深层次信息挖掘出来就可以做到正确识别对抗样本。
在图像处理领域中,插值算法可以在图片缩小和放大过程中较好地保留图片信息,本文根据插值算法这一特性提出了对样本预先处理的算法。因为在神经网络未受攻击时对图片进行插值操作会损失图片内部的信息,致使样本识别率下降,所以在神经网络识别效率很低时,才对输入的样本进行插值缩小再插值还原,如果神经网络识别效率较高则保持神经网络的输出。通过比较不同插值法在图片处理中的表现,本文在缩小时使用基于像素区域算法,在恢复原尺寸时使用立方卷积插值算法,能够更好地提高处理后图片的识别准确率。
算法:基于插值法的对抗攻击防御算法(IDA)
(1)输入:X,model,Y;
(2)输出:model.predict;
(3) if model.evaluate(X,Y)>90%;
(4)返回model(X);
(5) else;
(6)基于像素区域插值算法对X进行缩小,生成img;
(7)立方卷積插值算法对img放大至输入尺寸,生成Xresize;
(8)返回model(Xresize)。
算法解释:
(1)X为输入的样本图像,Y为样本的真实类别标签,model为未加IDA的神经网络模型;
(2)model.predict为识别模型对于样本的识别率;
(3)当神经网络识别准确率在90%以上时说明未受到对抗攻击,执行第(4)步;
(4)返回神经网络模型识别原始图片的预测值;
(5)当神经网络识别准确率在90%以下时说明模型有可能受到对抗攻击,执行第(6)步;
(6)基于像素区域插值算法对样本进行插值缩放,生成img;
(7)立方卷积插值算法将上一步生成的img还原到原尺寸,生成Xresize;
(8)返回神经网络识别经过处理后的图片(Xresize)的预测值。
4 实验结果与分析
4.1 生成对抗样本
Captcha是基于Python语言的验证码生成库,它可以生成任意长度的数字和字符类验证码,本文采用此函数库来批量生成字母验证码用于深度学习模型的训练以及对抗样本的生成。参照现有图片分类任务中经典的深度学习模型VGG16,本文采用Captcha生成的20000张单通道4位字母验证码(大小写相同)训练带有八层卷积层的卷积神经网络(CNN)50轮。参照张嘉楠等人的文献[12],本文使用FGSM[9]、Bim-a[10]、Bim-b[10]对抗攻击算法生成验证码的对抗样本。
4.2 评价指标
在本实验中,评价样本的指标用神经网络识别率表示,识别率为样本真实类别的神经网络置信度,样本的神经网络识别率越高表示算法更不易受到攻击。
4.3 验证码防御算法展示
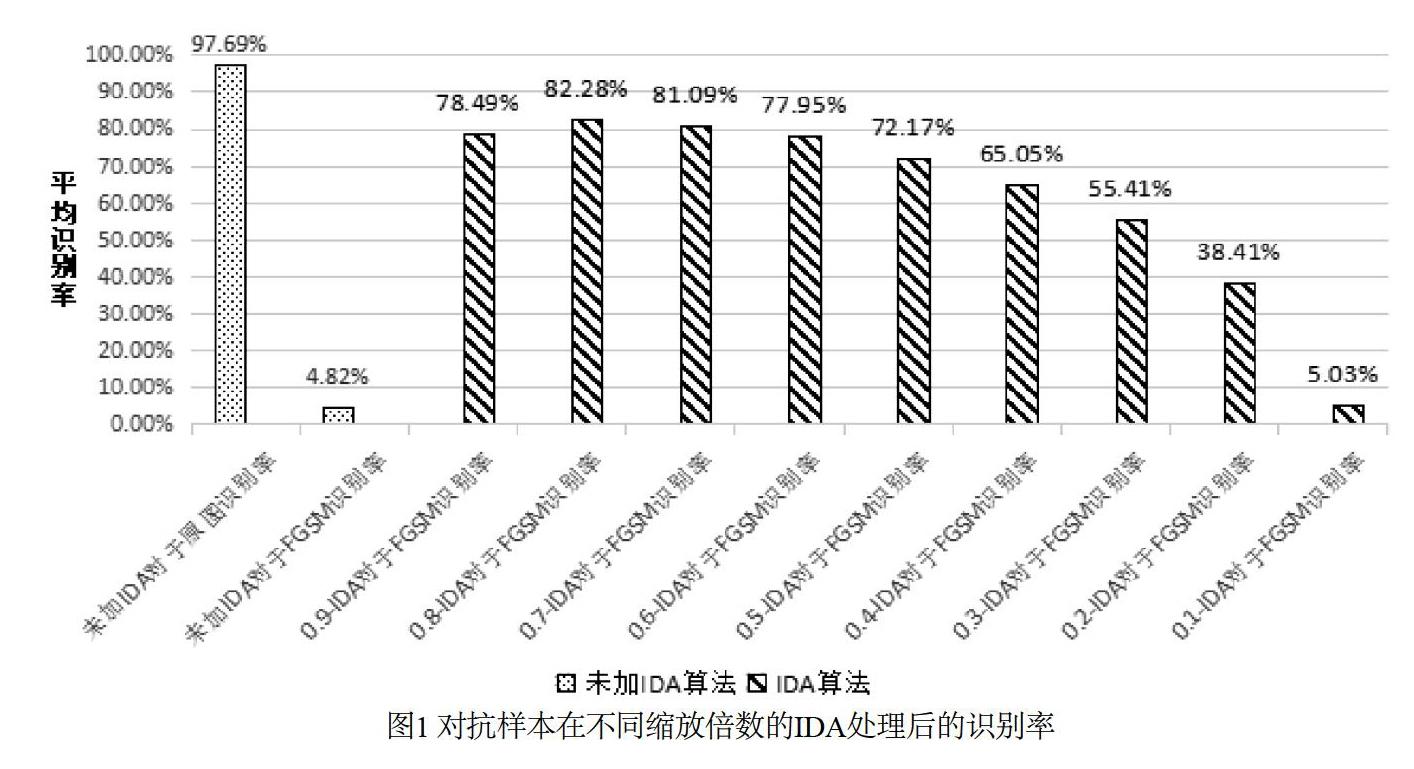
在图像缩小时本文选择基于像素区域插值算法,在恢复原尺寸时采用立方卷积插值算法,用卷积神经网络对100张对抗样本经过不同缩放倍数的IDA处理后得到的图片进行识别,无IDA算法处理的原始图片和无IDA算法处理的对抗样本识别作为对照,如图1所示。
图1的实验中,0.9-IDA指宽和高的缩放倍数均为0.9的IDA算法,FGSM指Fast Gradient Sign Method方法对抗攻击神经网络生成的对抗样本。实验数据表明,对抗攻击使得卷积神经网络的识别准确率从97.69%下降到4.82%,攻击效果明显。在采用插值算法对对抗样本进行处理后,神经网络的识别准确率得到了大幅度提高,并且在缩放倍数0.8到0.7的时候得到了最好的表现,分别是82.28%和81.09%。
图2的实验中,对抗样本由FGSM攻击生成。实验结果表明,75.5%的情况下IDA可将对抗样本识别率提升到95%之上,如图2中的FGSM攻击产生的对抗样本通过IDA方法处理后,神经网络的识别率从0.47% 提高到99.99%,并且IDA处理后的验证码可以被人眼识别。
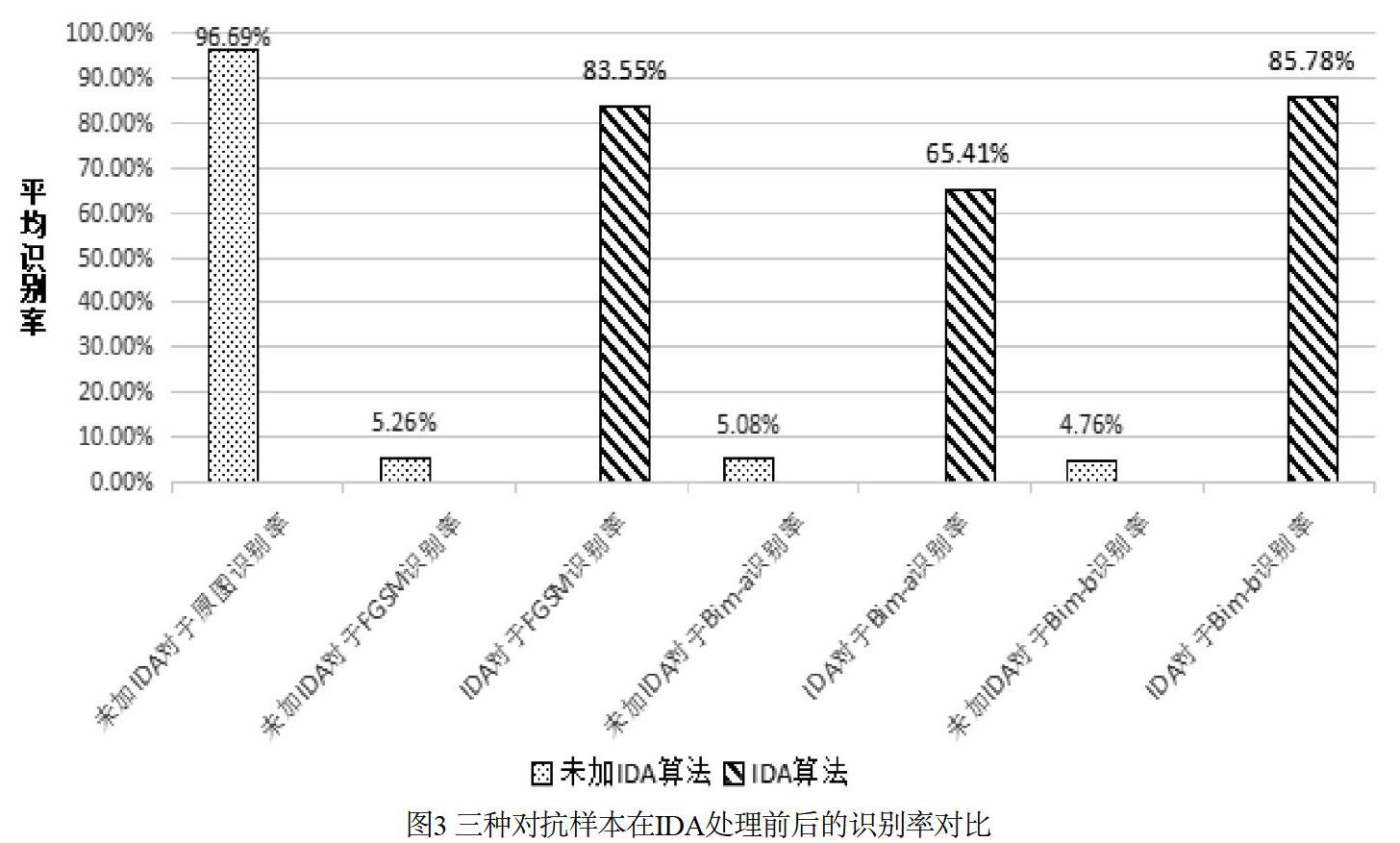
图3的实验中FGSM、Bim-a、Bim-b分别指Fast Gradient Sign Method、Basic Iterative Method-a和Basic Iterative Method-b对抗攻击方法生成的对抗样本,宽度缩小倍数是0.6,高度缩小倍数是0.8(经过测试这个比例效果较好),无IDA算法处理的原始图片和无IDA算法处理的三种对抗样本识别率作为对照。实验结果表明FGSM、BIM-a、BIM-b这三种白盒攻击生成的对抗样本在IDA操作之后的神经网络识别率都有提升。
5 结束语
插值法以往主要用于减少图像缩放过程中造成的失真,基于以上特性本文提出了基于插值法的对抗攻击防御算法(IDA),实验证明IDA能够提高神经网络对对抗样本的识别率,从不到5%提升到了80%,在特定情况下识别率不到1%提升到了99.99%,并且验证了该算法面对FGSM、BIM-a、BIM-b三种攻击均具有防御效果,证明IDA有助于提高深度学习的安全性。相较于蒸馏学习等主动防御模型,被动防御的IDA计算复杂度较低,训练时间较少,同时无须修改已有网络就可达到防御对抗攻击的目的,具有应用价值。
参考文献
[1] Szegedy, Christian, et al. Intriguing properties of neural networks. ICLR, abs/1312.6199, 2014b.
[2] Ba L J, Caruana R. Do Deep Nets Really Need to be Deep?[J]. 2013.
[3] Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network[J]. Computer Science, 2015.
[4] Papernot N , Mcdaniel P , Wu X , et al. Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks[J]. 2015.
[5] Goodfellow, Ian J, Shlens, Jonathon, Szegedy, Christian. Explaining and Harnessing Adversarial Examples[J]. Computer Science, 2014.
[6] Huang R, Xu B, Schuurmans D, et al. Learning with a Strong Adversary[J]. Computer Science, 2015.
[7] Wu Y, Bamman D, Russell S. Adversarial Training for Relation Extraction[C]. Conference on Empirical Methods in Natural Language Processing. 2017.
[8] Bradshaw J, Matthews, Ghahramani Z. Adversarial Examples, Uncertainty, and Transfer Testing Robustness in Gaussian Process Hybrid Deep Networks[J]. 2017.
[9] M. Abbasi, C. Gagné. Robustness to adversarial examples through an ensemble of specialists. In Proc. ICLRW, 2017.
[10] Kurakin, A, Goodfellow, I.J., and Bengio, S. Adversarial examples in the physical world. International Conference on Learning Representations, 2017.
[11] 張嘉楠,赵镇东,宣晶,常晓林.深度学习对抗样本的防御方法综述[J].网络空间安全, 2019, 10(8): 1.
[12] 张嘉楠,王逸翔,刘博,常晓林.深度学习的对抗攻击方法综述[J].网络空间安全, 2019, 10(7): 1.
