基于改进卷积神经网络的短文本分类模型
2020-07-18高云龙
高云龙, 吴 川, 朱 明
(1. 中国科学院 长春光学精密机械与物理研究所, 长春 130033;2. 中国科学院 航空光学成像与测量重点实验室, 长春 130033)
文本挖掘是自然语言处理领域中一项较重要的任务, 涉及机器翻译、 智能问答等许多领域[1]. 短文本数据反映了个体对生活方式的总结及社会现象的评论等, 常蕴含丰富的普遍规律. 不同于传统长文本, 短文本有显著的特点[2]: 1) 文本长度短; 2) 特征较稀疏; 3) 文本格式不统一. 短文本的特点使其通常不能提供足够的上下文信息, 从而使许多基于词频、 字同现的机器学习模型不能有效地提取短文本特征, 进而限制了传统的机器学习算法在短文本分类问题上的应用[3]. 本文将现有的短文本分类算法分为两类: 基于传统语义分析的短文本分类算法和基于深度神经网络的短文本分类算法. 前者常通过外部语义信息库丰富短文本的特征表示. 在WordNet[4]同义词数据库中, 每个同义词集合都表示一个基本的语义概念. Chen等[5]提出了多粒度主题模型用于精确描述短文本, 首先在通用数据集中采用LDA(latent dirichlet allocation)算法[6]提取N组主题集T, 再从主题集T中选择一个子集构成多粒度的主题空间, 将短文本的词特征与主题特征融合成新的短文本特征表示, 最后利用支持向量机(SVM)分类器获取较好的分类效果; Sun等[7]提出了一种基于TNG(topic N-gram)的特征扩展方法, 首先该方法可同时推断出词的分布式表示及每个主题下短语的分布式表示, 并由此构建特征扩展库, 然后基于所提取的原始特征, 对短文本的主题趋势进行推理, 并根据主题趋势在特征扩展库中选择相应的候选词汇与短语, 最后将选择结果作为短文本数据特征的扩充, 并通过LDA与SVM算法得到了较好的分类效果; Heap等[8]通过使用通用及专用的词向量模型丰富由Bag-of-words模型[9]对低频词汇所生成的词向量, 从而提高了多类别短文本的分类精度. 而基于深度神经网络的分类算法更关注于解决短文本的分布式表示及特征的无监督获取能力, 在短文本分类问题中取得了较好的效果. 随着深度学习模型在图像挖掘[10]、 语音识别[11]等领域的广泛应用, 如何利用深度模型处理文本挖掘问题受到广泛关注. Kim[12]提出了一个基于卷积神经网络(CNN)处理句子分类问题的模型, 该模型将句子视为词的序列, 并利用预先训练好的词的分布式表示作为模型输入, 此外, 还按输入词向量的不同将模型分为4种变型, 其中双道词向量输入模型普遍取得了较好的分类效果; Kalchbrenner等[13]提出了一种基于动态的卷积神经网络模型DCNN, 并应用到句子分类问题中, 在卷积层提出了一种广义卷积, 可充分保留句子边缘词汇的特征信息, 在池化层根据卷积层节点的数量定义一种全局的动态K-Max策略, 从而动态地确定池化层保留的特征数量, DCNN模型可处理变长的语料数据, 具有较强的泛化能力; Zhang等[14]构建了短文本的字符分布式表示模型, 并通过实验结果验证了模型的有效性. 基于神经网络的短文本分类模型通常不需要语言的句法、 语法等先验信息, 因此在不同类型的数据集或不同的语言中都表现出了良好的扩展性和有效性.
基于此, 本文提出一种基于改进卷积神经网络的短文本分类模型ICNNSTCM. 该模型构造了短文本语料多种不同的分布式表示: 1) 字符级特征表示和词汇级表示, 并作为分类模型ICNNSTCM的双道输入, 词汇级分布式表示同时作为模型的参数进行调优; 2) 提取短文本中包含的实体, 在标准知识库中检索实体对应的概念集, 并提出CToST学习策略计算概念与短文本之间的关联强度, 从而构成短文本的概念特征表示. 在全连接层增加稀疏自编码策略, 即通过非监督学习一个近似恒等的转换函数, 利用稀疏性限制保证网络层多数节点处于被抑制的状态, 在降低模型复杂度的同时提高模型的泛化能力. 本文模型和相关实验均基于Python语言及TensorFlow框架实现, 通过与其他几种短文本分类模型进行对比, 实验结果表明, ICNNSTCM可更好地提取短文本数据的特征, 具有较高的分类精度.
1 模型构建
图1为基于改进卷积神经网络的短文本分类模型ICNNSTCM的框架. 采用不同的学习策略分别构建短文本的分布式表示, 并作为模型的多通道输入. 构造字符级分布式表示即将短文本视为字符的序列, 从而捕获短文本的粒子字信息; 词汇级分布式表示, 即词向量, 其几何关系常作为词汇间语义关系的高级抽象; 概念级分布式表示, 利用标准知识库提取短文本的概念特征, 并以此作为模型先验知识, 丰富语料表征能力的同时提高了模型参数调优的效率; 通过不同窗口的卷积核与3种分布式表示分别进行卷积运算, 提取卷积层节点的数字特征; 池化层采用K-Max Pooling保留卷积层节点最大的K个特征, 并合并为一个一维的长特征序列; 在两个全连接层之间增加稀疏自编码学习策略, 高层特征通过与分类器相连, 从而预测输入短文本的类别.
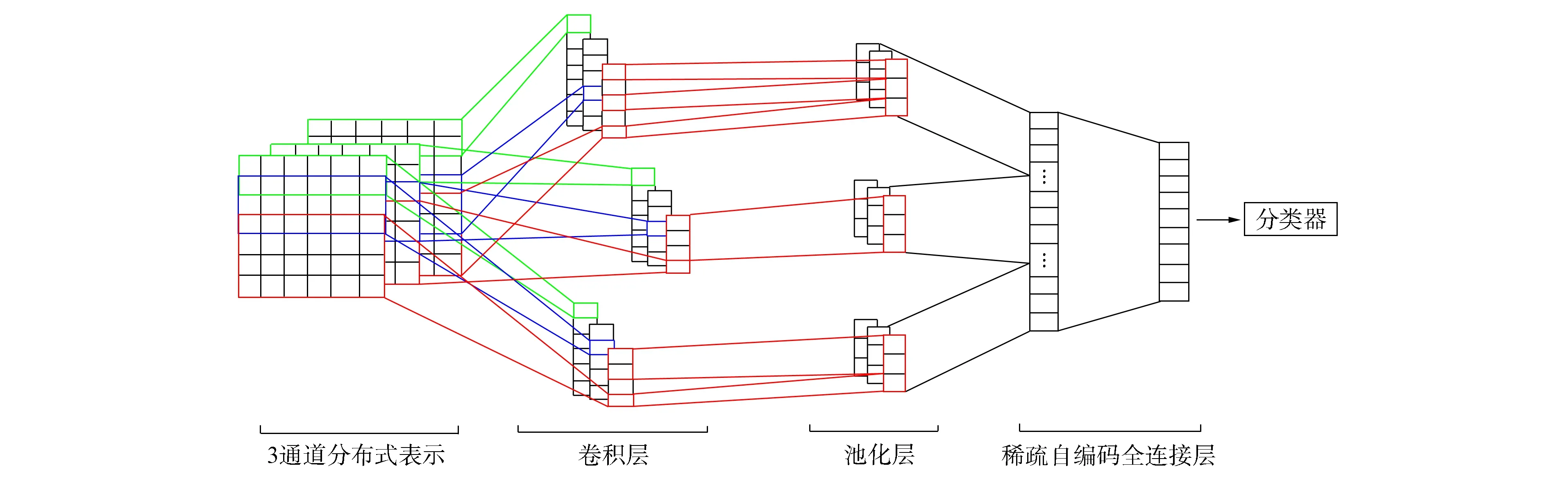
图1 ICNNSTCM模型结构
1.1 字符级分布式表示
通过将输入短文本视为字符的序列, 并利用该语言下长度为m的字母表Ω对字符进行编码量化, 从而实现短文本数据字符级分布式表示的构建. 考虑到字符数量远小于该语言下词汇的总量, 因此采用字符级分布式表示在一定程度上可降低模型的计算复杂度. 基于Bag-of-words编码方式的思想, 将每个字符视为一个词汇, 从而得到每个字符的编码; 对不包含在字母表Ω中的字符, 简单地将其编码为零向量. 对于长度为l个字符的短文本, 通过以上处理可得到其维度为l×m的字符分布式表示. 本文使用的字母表Ω包含68个字符: 26个英文小写字符, 10个数字字符及32个其他字符.
1.2 概念级分布式表示
概念特征分布式表示将短文本视为互相关联的实体构成的集合, 对于集合中的每个实体, 通过检索外部标准知识库, 可获取其对应的概念, 从而更好地实现分类任务. 例如短文本ST1: “Rihanna is a super star.”, 其中名词实体“Rihanna”对应的概念为“Singer”, 因此, 分类器更倾向于将ST1归类为“娱乐”类别中. 此外, 实体通常对应多个不同的概念, 从而具有较大的歧义性. 例如短文本ST2: “She is eating an apple”, 对于名词实体“apple”, 可得到概念“Phone”和“Apple”, 显然对于ST2, “Phone”不是一个正确的概念.
为更好地描述概念与短文本之间的关联强度, 本文提出了CToST学习策略. 对元素个数为m的概念集C={c1,c2,…,cm}, 其对应的词向量可表示为CV∈m×d, 短文本ST对应的词向量表示为ST∈st×d, 其中:d为词向量维度;st为短文本ST中词的个数. 则概念ci与短文本ST的关联强度值可表示为
corri=g(W(CVi·ST)T+b),
(1)
其中:g为非线性函数; 参数W∈st,b∈st.
进一步, 为规范化关联强度值, 本文采用Softmax算子作用于式(1), 最终的关键强度值可表示为
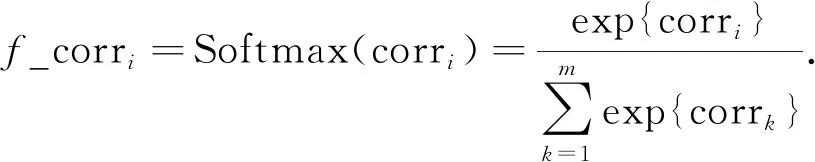
(2)

1.3 稀疏自编码策略

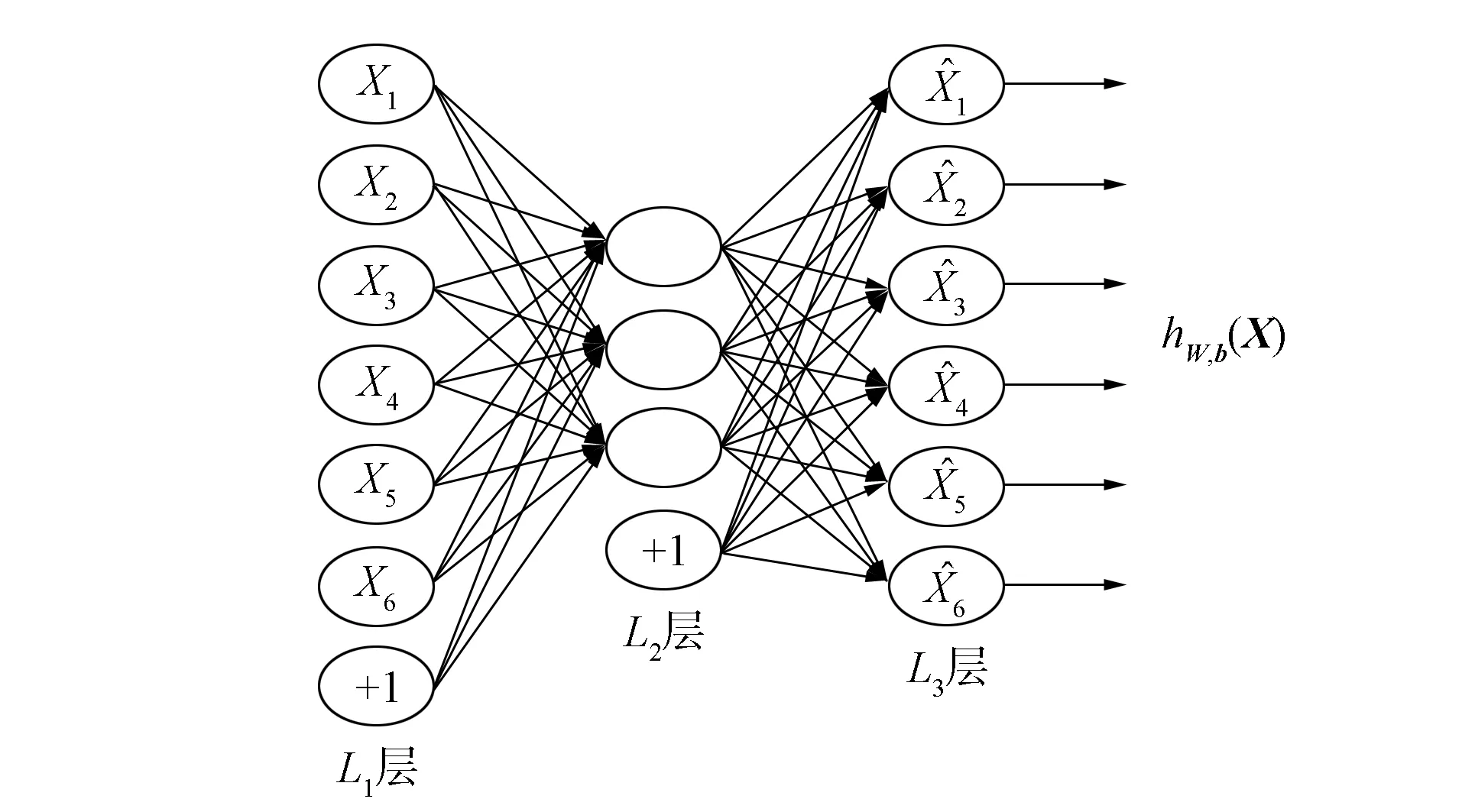
图2 稀疏自编码全连接层
令a(1)=X作为输入层的激活值, 则在给定第n层的激活值后, 第(n+1)层的激活值可按下式获得:
z(n+1)=W(n)a(n)+b(n),
(3)
a(n+1)=f(z(n+1)),
(4)
其中f为非线性激活函数.

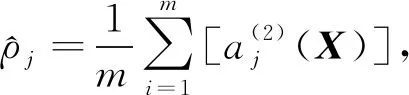
(5)

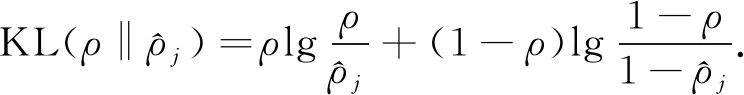
(6)
令J(W,b)表示全连接网络的目标函数, 则增加稀疏性约束后网络的优化函数为
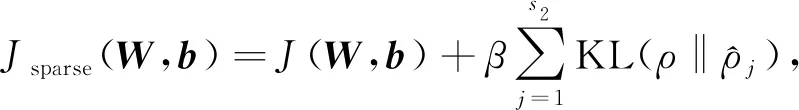
(7)
其中s2表示L2层中节点的个数.
1.4 算法描述
算法1稀疏自编码算法.
输入: 池化层输出特征向量X;
输出:L2自编码层参数, 包括权重矩阵W1、 偏置b1、L2层输出特征向量a(2);
初始化: 随机设置L2,L3层权重矩阵W1,W2和偏置b1,b2;
步骤1) 设迭代次数iter=0;
步骤2) 根据式(3)和式(4)计算L2,L3层激活值a(2),a(3);
步骤3)hW,b(X)=a(3);
步骤4)J(W,b)=‖hW,b(X)-X‖2;
步骤6) 根据式(6)计算相对熵;
步骤7) 根据式(7)计算Jsparse(W,b);
步骤8) 误差反向传播优化参数fine-tuning;
步骤9) iter++;
步骤10) 如果iter<1 000, 则返回步骤2).
1.5 模型实现
本文的模型、 相关实验均基于Python语言及TensorFlow框架实现, 并可以同时支持CPU和GPU. 模型参数的选取: 短文本包含字符的长度l=512, 对于长度超出512个字符的短文本将被丢弃, 字符级分布式表示采用One-Hot编码; 词向量采用Word2vec工具, 并基于Python库Gensim API实现, 词向量维度值d=200; 非线性函数g选取Softmax; 卷积核宽度width为3,4,5, 并分别对应100个卷积节点; 卷积层及全连接层非线性激活函数f选取Sigmod; 稀疏性参数ρ=0.1; 第二个全连接层中节点的个数s2=1 024; batch_size=50, 迭代次数epochs=25; 分类器选择Softmax模型, 模型训练采用Adam优化算法.
2 实验分析
2.1 数据集
实验采用的标准短文本语料库均可通过下列开源网站获得:
1) MRD(http://www.cs.cornell.edu/people/pabo/movie-review-data)影片评论数据集, 其中每个句子是用户对影片的一条评论, 有正、 反面两种属性标签;
2) SST(http://nlp.stanford.edu/sentiment/)情感分析数据集, 是MRD数据集的扩展, 共有5种属性标签, 分别为very positive,positive,neutral,negative,very negative;
3) TREC(http://cogcomp.cs.illinois.edu/Data/QA/QC/)问题属性分析数据集, 问题类别共有6种(about person,location,numeric information,etc), 将问题与类别进行匹配;
4) CR(http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html)顾客意见数据集, 是关于商品正、 反面的二元分类数据集.
短文本数据集的相关信息及参数列于表1, 其中:C为目标类别数;L为平均句子长度;N为数据集规模; |V|为词汇量规模; Test为测试机规模; CV为十折交叉验证拆分数据集.

表1 数据集的参数
2.2 卷积核宽度对模型的影响
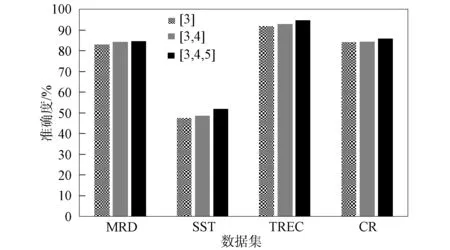
图3 不同宽度组合对分类精度的影响
卷积层是卷积神经网络中最重要的结构, 通过卷积核与输入数据的局部感受野进行卷积运算, 提取数字特征. 卷积核的维度对所提取特征的粒度有影响, 进而影响模型的分类精度.
组合不同窗口大小的卷积核, 并在短文本数据集上进行分类实验, 结果如图3所示, 其中: [3]表示卷积核的宽度为3, 即一次卷积过程可覆盖3个词汇或者字符; [3,4]表示卷积层含有宽度分别为3,4的卷积核组合; [3,4,5]表示卷积层含有宽度分别为3,4,5的卷积核组合. 由图3可见, 随着窗口组合数的增加, 卷积层可提取不同粒度的特征, 从而学习到更丰富的抽象特征表示, 进而提高了分类精度. 当固定窗口组合数时, 通过改变卷积核的宽度进行实验, 结果列于表2. 由表2可见, 在卷积核宽度组合为[3,4,5]时, 模型取得了分类精度的极值.

表2 卷积核宽度对分类精度的影响
2.3 池化层K值选取对模型的影响
ICNNSTCM模型池化层采用K-Max策略选择卷积层较大的K个特征值, 并保留其相对顺序.K值选取对模型泛化误差的影响如图4所示. 由图4可见,K值选取通常与短文本数据的平均长度有关, 对平均词汇长度为18,19,20的数据集SST,CR,MRD,K=15时模型取得的泛化误差值最低, 而对平均词汇长度为10的数据集TREC,K=8时模型的分类精度最高. 当K值较低时, 模型通常不能保留足够多的特征信息, 而当K值较大时, 模型通常表现为过拟合状态, 从而均导致模型的分类精度较低.

图4 K值对模型泛化误差的影响
2.4 概念特征表示对模型的影响
本文在短文本字符级和词汇级分布式表示的基础上提出了概念级分布式表示, 利用外部标准知识库为模型增加先验知识, 进一步丰富了短文本的特征描述. ICNNSTCM模型在不同通道输入情况下的分类精度结果列于表3. ICNNSTCM-2模型采用2通道输入, 即短文本的字符级和词汇级分布式表示, 而ICNNSTCM-3模型则增加了短文本的概念特征分布式表示. 由表3可见, 利用先验知识为模型增加概念特征表示, 在一定程度上可提高分类的精确度; 此外, 采用不同的外部标准知识库对模型分类精度也存在一定的影响, 知识库YAGO[15]整体上优于FreeBase[16].

表3 概念分布式表示对模型分类精度的影响
2.5 稀疏性对模型的影响
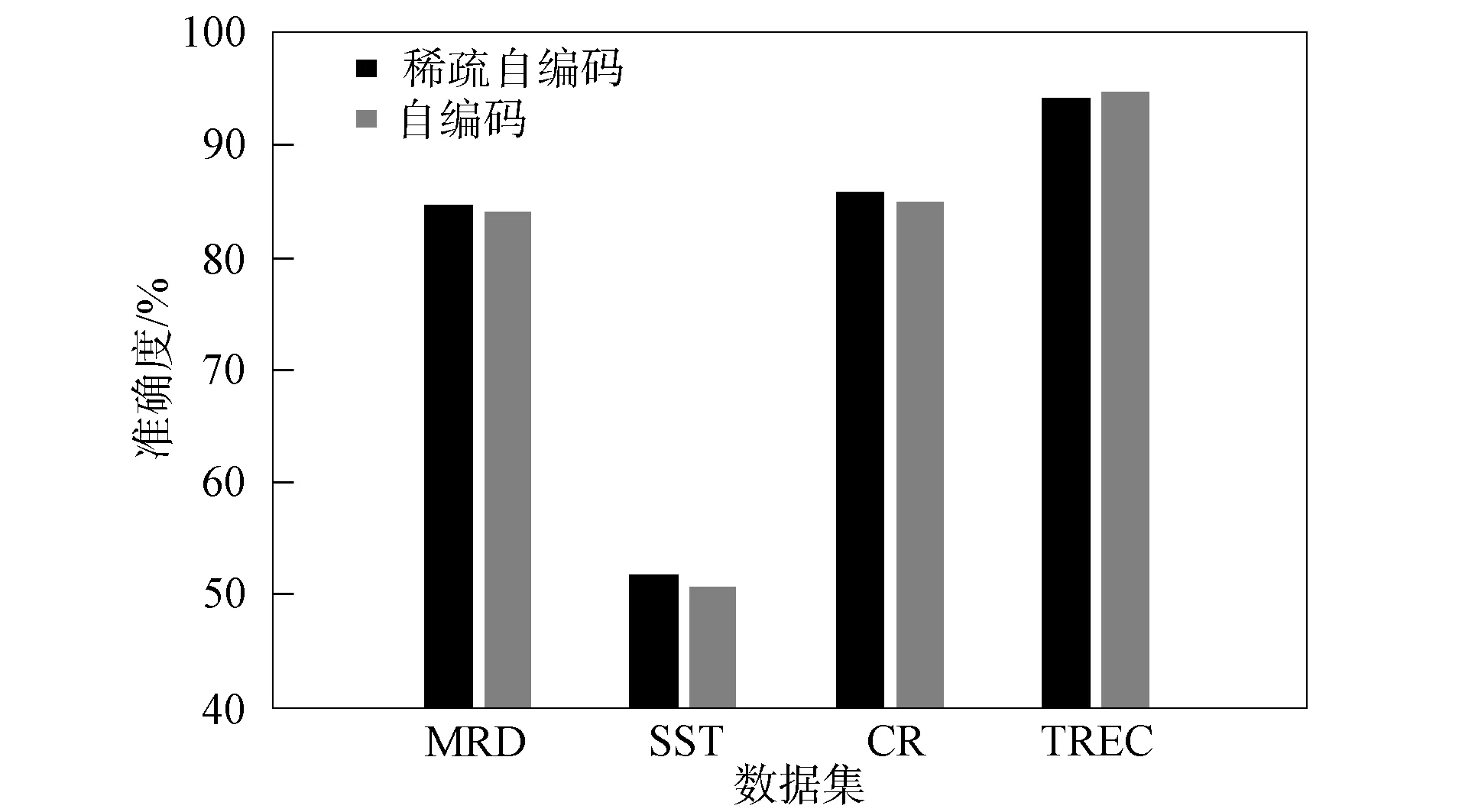
图5 稀疏性对模型分类精度的影响
好的特征具有可区分性[17]. 为进一步减少特征表示的冗余信息, 通过在ICNNSTCM模型自编码层增加稀疏性约束, 以获取输入数据的低维空间表示. 本文对稀疏性概念解释为: 对于激活函数Sigmod, 神经元输出接近1时表示该节点被激活, 输出接近0时表示该节点被抑制, 且同一时刻自编码层大部分节点处于被抑制状态. 稀疏性对模型的影响如图5所示. 由图5可见, 稀疏特征表示的有效性通常与短文本数据的平均长度有关, 对平均词汇长度为18,19,20的数据集SST,CR,MRD, 增加稀疏自编码层可有效降低分类模型的泛化误差, 而对平均词汇长度为10的数据集TREC, 由于语料的冗余特征较少, 增加稀疏约束导致模型无法提取足够多的特征信息, 从而降低了模型的分类精度.
2.6 ICNNSTCM模型的两种变型
ICNNSTCM模型采用字符级、 词汇级和概念级分布式表示作为多通道输入, 针对词汇级分布式表示, 即词向量是否作为模型优化的参数, 本文将模型分为如下两种变型.
1) ICNNSTCM-static: 词向量在模型训练过程中保持不变, 不作为模型调参的变量;
2) ICNNSTCM-dynamic: 词向量在模型训练过程中进行调优, 作为模型调参的变量.
在MRD数据集上, 本文统计了两种变型在迭代调优中泛化误差下降及分类精度上升的收敛过程, 分别如图6和图7所示. 由图6和图7可见: 由于ICNNSTCM-static在训练过程中优化的参数较少, 故其收敛速度高于ICNNSTCM-dynamic模型. 此外, 通过使用与分类问题相关的数据集对词向量进行调优, 可提高词向量对数据集的表征能力, 从而提高了模型的分类精度.
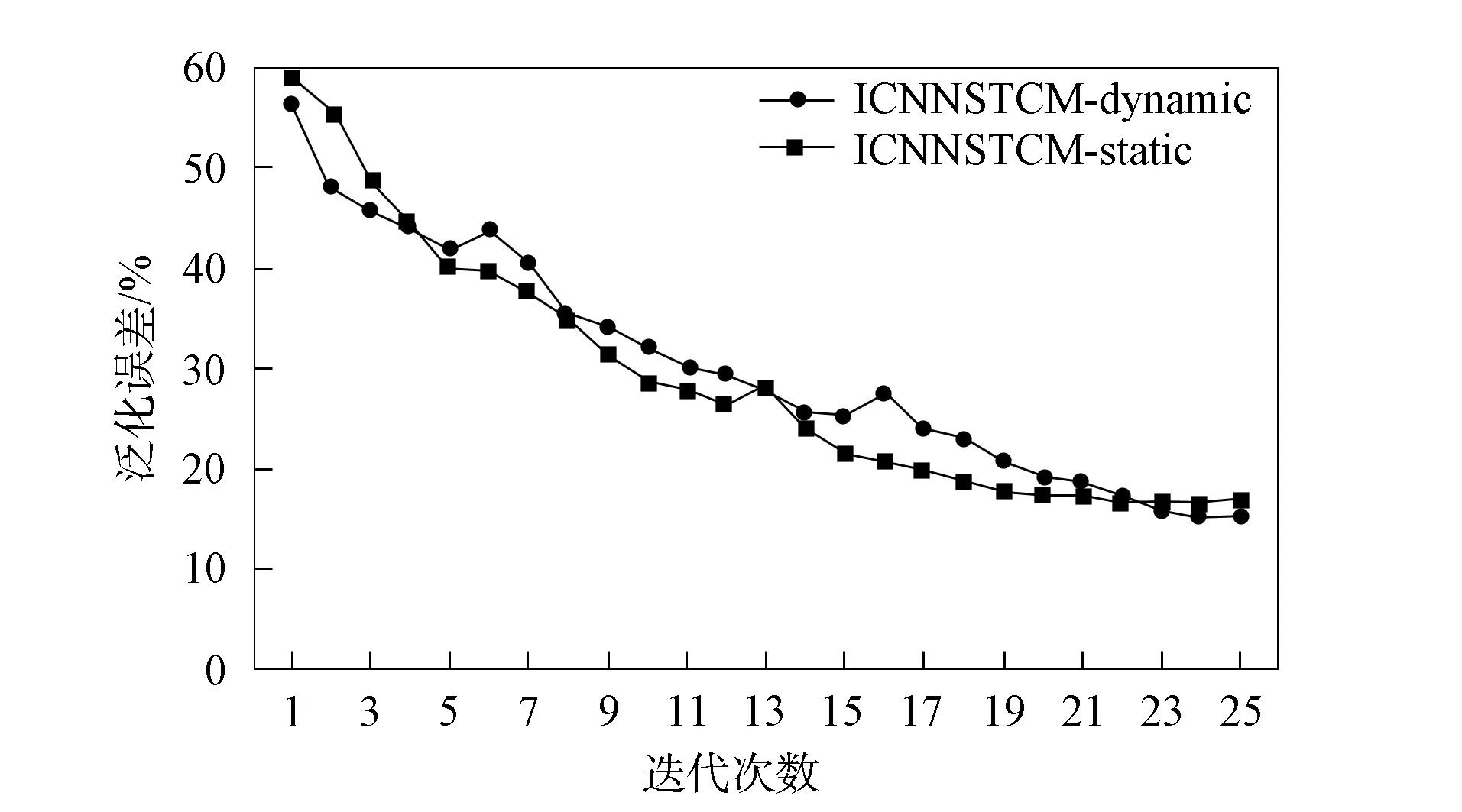
图6 两种模型泛化误差下降速度对比

图7 两种模型分类精度上升速度对比
2.7 对比实验
下面通过与几种成熟的短文本分类模型进行对比, 验证ICNNSTCM模型的有效性, 实验结果列于表4. ICNNSTCM采用多通道分布式输入, 充分提取不同粒度的数字特征, 并通过使用与分类问题相关的数据集对词向量进行调优, 提高了对于输入短文本的表示能力. 此外, 在全连接层增加的稀疏自编码策略, 在利用近似恒等关系保持特征有效性不变的情况下, 通过组合所提取的特征, 进一步学习输入数据内部的相关性. 实验结果表明, ICNNSTCM模型在数据集上均取得了较理想的分类效果, 实验结果优于目前已有的大部分分类模型.
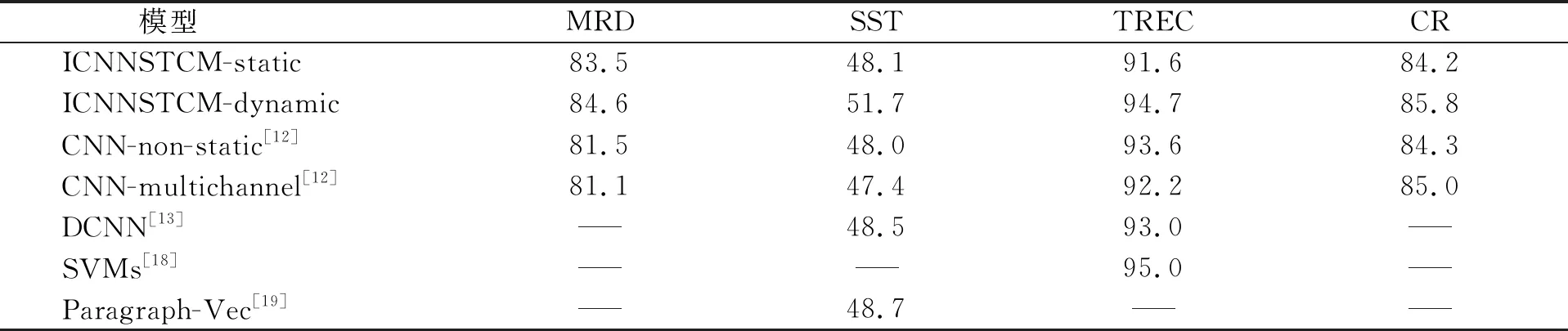
表4 ICNNSTCM模型与其他模型性能对比
综上所述, 本文提出了一种ICNNSTCM模型, 并通过相关实验证明了ICNNSTCM模型在处理短文本分类问题上的有效性.
