一种基于规则与句法合成的层次化语句分析识别算法
2020-07-18贾继康邵玉斌杜庆治
贾继康, 邵玉斌, 龙 华, 杜庆治
(昆明理工大学 信息工程与自动化学院, 昆明 650500)
自然语言处理(natural language processing, NLP)目前已广泛集成到Web和移动应用程序中, 实现了人与计算机之间的自然交互, 内容包括语音合成与识别、 机器翻译、 句法分析等. 句法分析作为自然语言处理中的关键技术之一已被广泛应用, 如文本校对、 句型识别、 词义消岐等[1]. 句法分析的基本任务是确定句子所包含的句法单位及这些句法单位之间的依存关系, 句法分析器分为自顶向下和自底向上分析器. 自顶向下分析器从顶部到底部(树根、 文法的开始符号到叶子、 语言的终结符号)为输入的符号串建立分析树, 自底向上分析器是根据形式文法的重写规则, 自叶子开始逐级向上归约, 直到构造出表示句子结构的推导树为止.
层次句法分析是一种典型的自底向上分析方法. Abney等[2]提出的组块概念是句法分析的先驱; Ramshaw等[3]在组块分析中增加了{B,I,O}标记概念, 促进了句法分析的发展; Ratnaparkhi[4]提出了最大熵模型的句法分析器, 奠定了层次句法分析的基础; Pascale等[5]将最大熵模型应用于中文句法分析, 实现了基于字的统计句法分析器. 句法分析与句式结构的研究密不可分, 但多数研究都是探讨汉语的句子结构格局, 对将句式研究成果应用到信息处理中的研究报道较少, 这主要是因为中文信息处理中句子结构的形式化处理在很大程度上模糊了汉语的句式结构, 因此很难从句法树结构中获取句式结构. 目前, 针对语言句式的研究多数采用字类、 句式搭配或特征词等方法.
从句式的角度, 无论修饰结合、 还是语言独立成句, 在字、 词或语块角度实现的句法研究, 都有一定的局限性, 仅能解决局部问题, 不能做到对整个句子实现层次性的分析. 因此, 本文提出一种基于规则与句法合成的层次化语句分析识别算法, 该算法以句式识别框架为基础, 以二、 三词元结合的层次化语句分析模型为前提, 使用具有代表性的人民日报作为数据集, 进行目标测试. 测试结果表明, 该算法既保留了二、 三词元的规则特性, 又对规则库进行了更全面地融合, 有效提高了层次化语句分析的准确度, 进一步提升了句式识别的精度, 验证了算法的适用性和有效性.
1 基于规则与句法合成的语句分解识别算法
1.1 系统框架
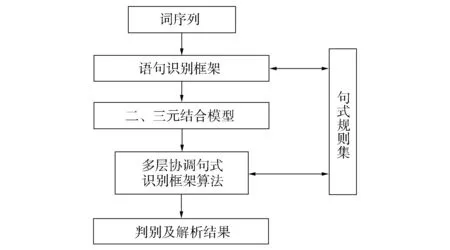
图1 语句分析识别系统框架
本文使用已处理好带有正确词性标注的海量数据集作为输入语料, 如图1所示, 依次经过语句识别框架, 二、 三元相结合语句分析模型和多层协调的句式识别算法, 根据语句识别框架与句式识别规则库匹配, 按定义好的正确句式规则模板识别是否为一个句子; 判别是否需要二、 三元结合模型对句子层次化解析、 合成; 二、 三元模型获取的结果经过多层协调句式识别算法, 最终输出判别及解析结果.
1.2 基于统计和规则并举的词性标注
采用汉语词性标记集, 共99个(22个一类, 66个二类, 11个三类)[6]. 为了句式识别的高效性及文中所涉及规则模板制定的简易、 合理性, 将表1中细分(pos2)所示的词性标记集简化为粗记(pos1)表示, 最后实现语料标注.

表1 词性标识简化
由于句法分析的第一步都基于词性标注, 因此词性标注的优劣直接影响实验结果的精确度. 本文以现有规则和统计方法相结合的词性标注概念为基础, 实现词性最优标注. 假设字符串序列W={w1w2w3…wi-1wiwi+1…wn},M={m1m2m3…mi-1mimi+1…mn}, 其中:W表示由n个词元有序组合成的句子;M是W对应的词性序列; 字符wi表示W的第i个词元, 最终wi将具有表1中pos1的词性之一. 例如: (wi|mi)表示wi的词性为mi.
由于汉语词具有多类词性, 因此根据汉语词性标记集可对一个词进行多种词性划分, 而考虑到生词的词性标注在统计方法中通常通过合理处理词汇的发射概率解决, 从而词性标注问题即转化为求条件概率P(M/W)中最大的M, 即

(1)
其中:W′={w1,w2,…,wi}表示待选词元序列;M′={m1,m2,…,mi}表示与W′相对应的词性序列. 由条件概率公式可得:
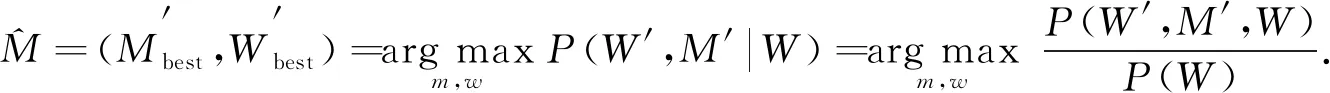
(2)
其中P(W)与M′,W′无关, 为常数, 故可省略, 即可简化为
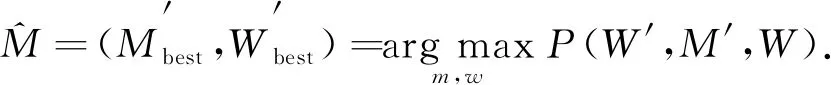
(3)
由于W′和W是子属关系, 进一步可得
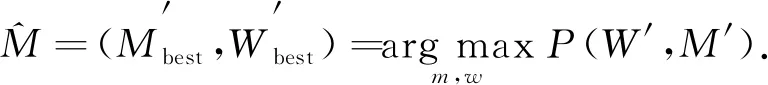
(4)
由式(4)可知, 计算概率P(W′,M′)是分词和词性标注问题的关键, 根据一阶Markov的性质[7]可得:
其中:P(mi|mi-1)为隐含Markov模型(HMM)中的状态转移概率;P(wi|ti)为词汇的发射概率. 由于海量语料中含有大量的生词, 假设词汇序列W中有生词xj, 其词性可标注为mj, 根据HMM的假设,xj的词性mj由wj的词性mj-1决定, 则
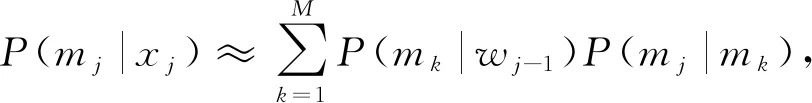
(6)
其中M为词性种类的数目. 根据Bayes公式, 词汇的发射概率为

(7)
将式(6)代入式(7), 可得
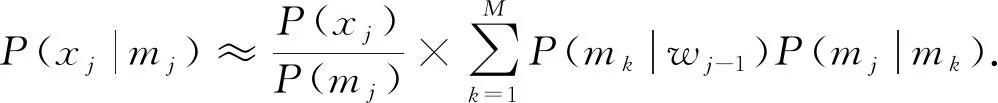
(8)
对式(7)中的各概率值采用最大似然估计, 可得
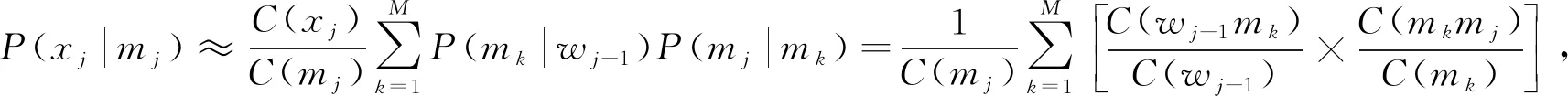
(9)
其中:C(mj),C(mk),C(wj-1)分别为词性mj,mk和词wj-1在训练语料中出现的次数;C(mkmj),C(wj-1mk)分别为词性串mkmj和wj-1mk同时出现的次数. 经过上述处理可更精准地对语句实现词性标注.
1.3 句式识别框架及规则模板构建
基于中文句子结构的分类有主谓句(动词谓语句式表、 形容词谓语句式表、 主谓谓语句、 名词谓语句)和非主谓句(无主语、 独语句), 为了验证算法的可行性, 以现代汉语八百词中给出的动词谓语句式表作为构建规则依据[8]. 表2为识别框架规则库, 其中model1列构建了78条规则, 每行字符串作为一个规则独立体.
由于句式表自身特点导致规则串长度不一, 因此为实现句子在系统中更快、 更高精度地被识别, 用快速排序方法对字符向量进行升序排序, 最终可得如表2中model2所示的规则模板. 为了验证最终结果, 根据动词谓语句式中给出的句式结构, 提炼出如表2所示的句式规则库. 在规则库的基础上构建句式识别框架.

表2 识别框架规则库
如当字符串W={她|r唱过|v女高音|n}时, 分别对应的词性为{r,v,n}. 而当序号为2时, model2={r,v,n}, 从而在规则扫描过程中会被成功匹配. 因此, 从语句中提炼出的句式规则能很好地用于句式检错中. 在规则集的基础上构建句式识别框架, 如图2所示. 由图2可见, 训练语料首先被词性标注, 然后利用句式识别算法和句式规则库进行交互匹配, 最终输出识别结果.
1.4 二、 三元语句层次化分析模型
1.4.1 合成规则的构建 为实现句法合成规则制定的有效性、 简易性, 所有词性类别都在给定的词性标注集中以表1中的pos1表示法作为简易化词性识别标记, 最终得到由词和词性组成的词元串W为
W={w1|m1,w2|m2,…,wi-1|mi-1,wi|mi,wi+1|mi+1,…,wn|mn},
词元串w1w2w3…wi-1wiwi+1…wn中的{wi,wi+1}为W中相邻的两个词, 记为一个二元组Ti, 所在位置不可颠倒, 即{wi,wi+1}≠{wi+1,wi}. 同理, 将{wj-1,wj,wj+1}记为一个三元组Tj, 其中i,j⊆n. 根据语法形式的合理性对现代汉语句子组织信息原则及现代汉语语法进行研究, 并对汉语句法分析进行解读, 通过表1所示的词性标记集与语法和统计得出的语言规则相结合, 实现如表3所示的二、 三元句法合成规则的构建. 其中:mi-1,mi,mi+1分别表示对应词的词性; “*”表示无, 即当前行为一个二元句法合成规则;hc_m表示Ti或Tj是合成词的词性.

表3 二、 三元句法合成规则
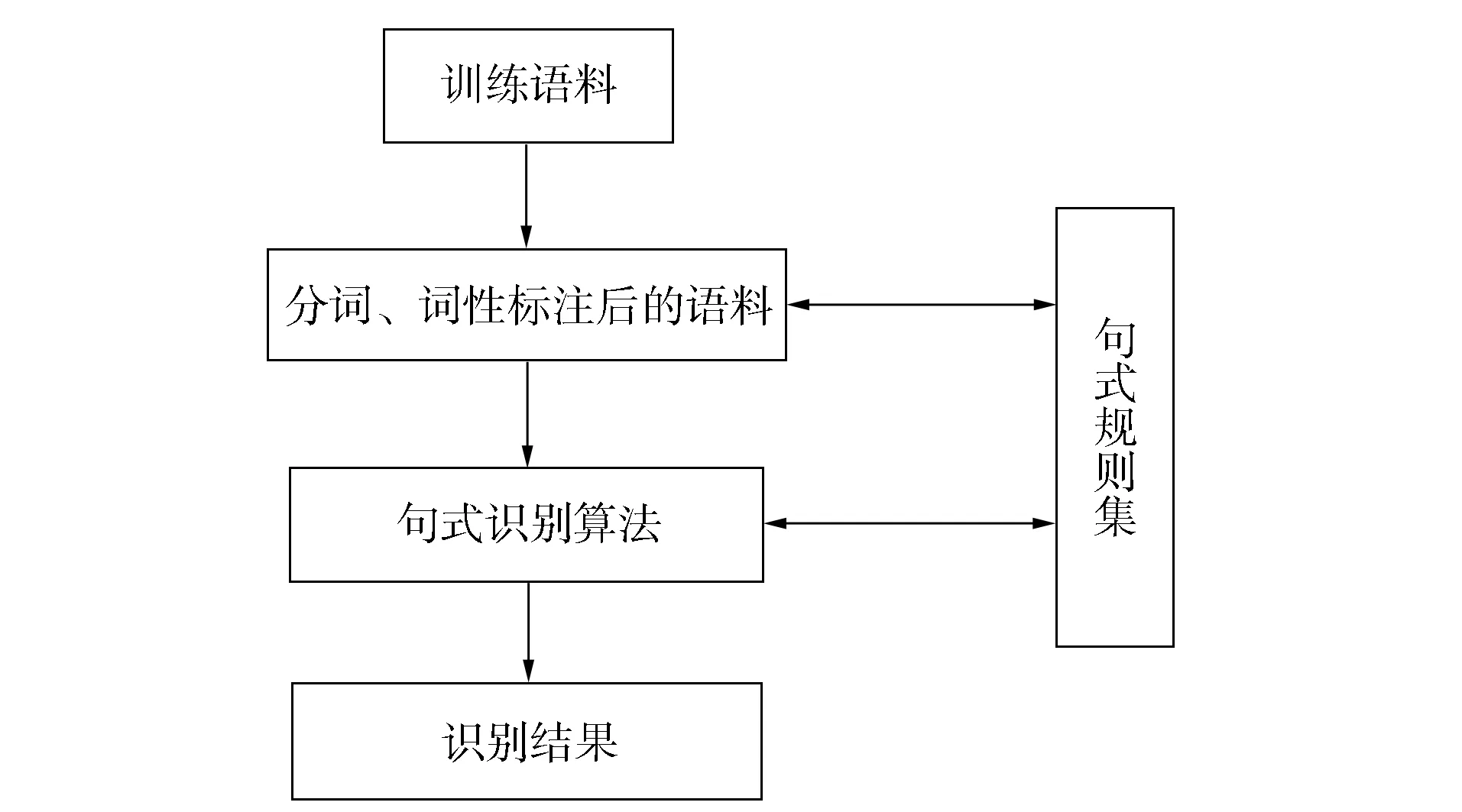
图2 句式识别框架
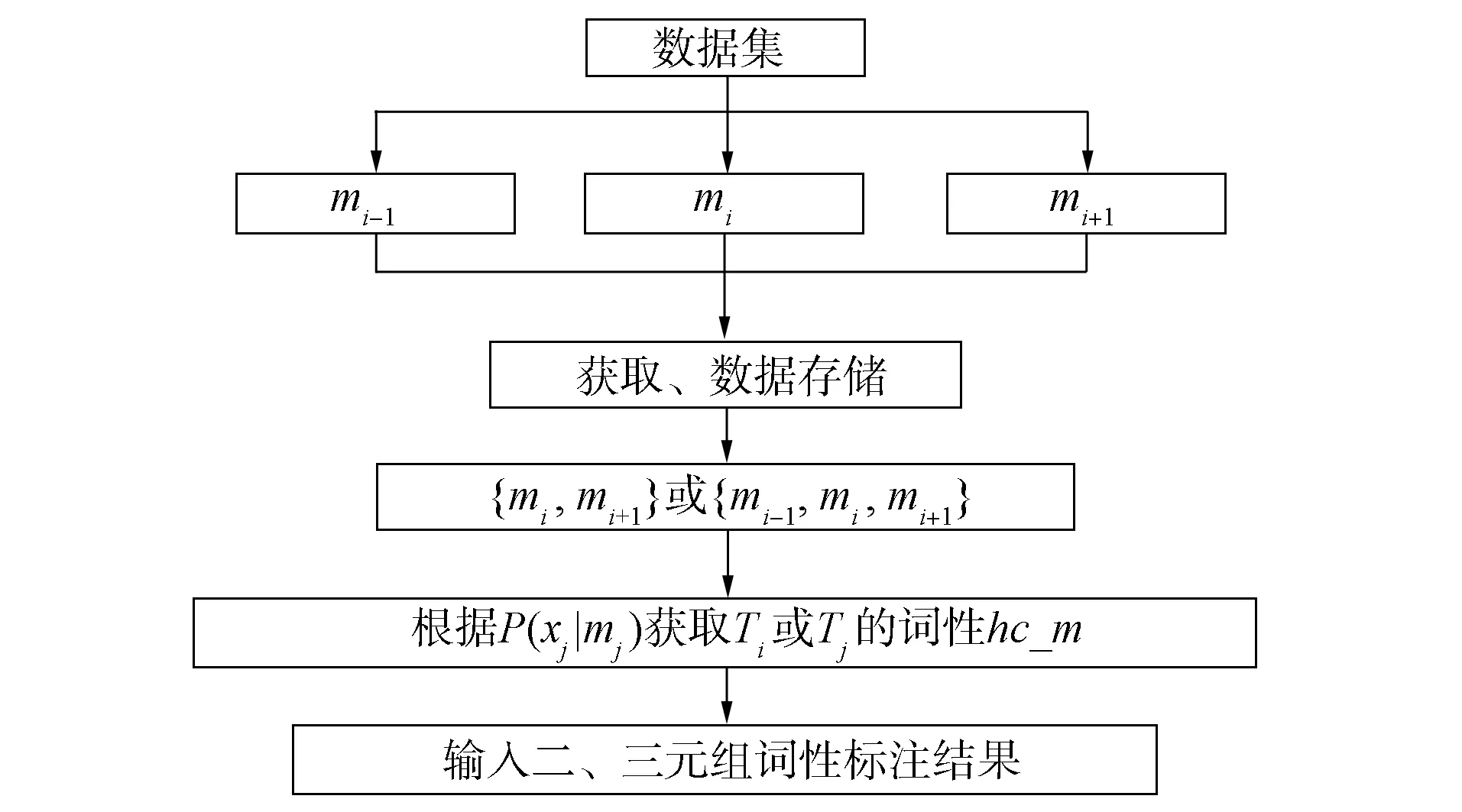
图3 二、 三元规则匹配示意图
图3描述了如何根据表3合成规则库文件实现词串中由{mi,mi+1}或{mi-1,mi,mi+1}匹配合成得到hc_m. 根据图3, 获取当前Ti或Tj的词性, 如序号为3时,mi-1=v,mi=u,mi+1=n, 则hc_m=n. 即根据{mi-1,mi,mi+1}或{mi,mi+1}满足句法合成规则:
Ti={mi,mi+1},Tj={mj-1,mj,mj+1},
Mhc_m=P(xi|mi)={mi,mi+1}或Mhc_m=P(xj|mj)={mj-1,mj,mj+1},
(10)
其中Mhc_m为词单元Ti或Tj的词性合成结果. 词单元Ti或Tj合成一个新词并具有新的词性, 记为
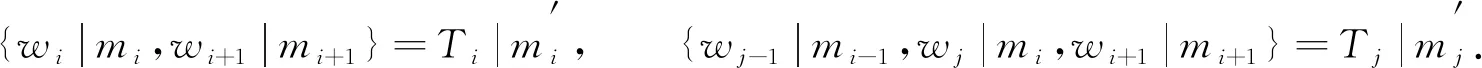
(11)
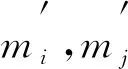
1.4.2 二、 三元层次化分析 输入句子的字串序列W={w1|m1,w2|m2,…,wi|mi,…,wj|mj,…,wn|mn}, 层次化分析满足:
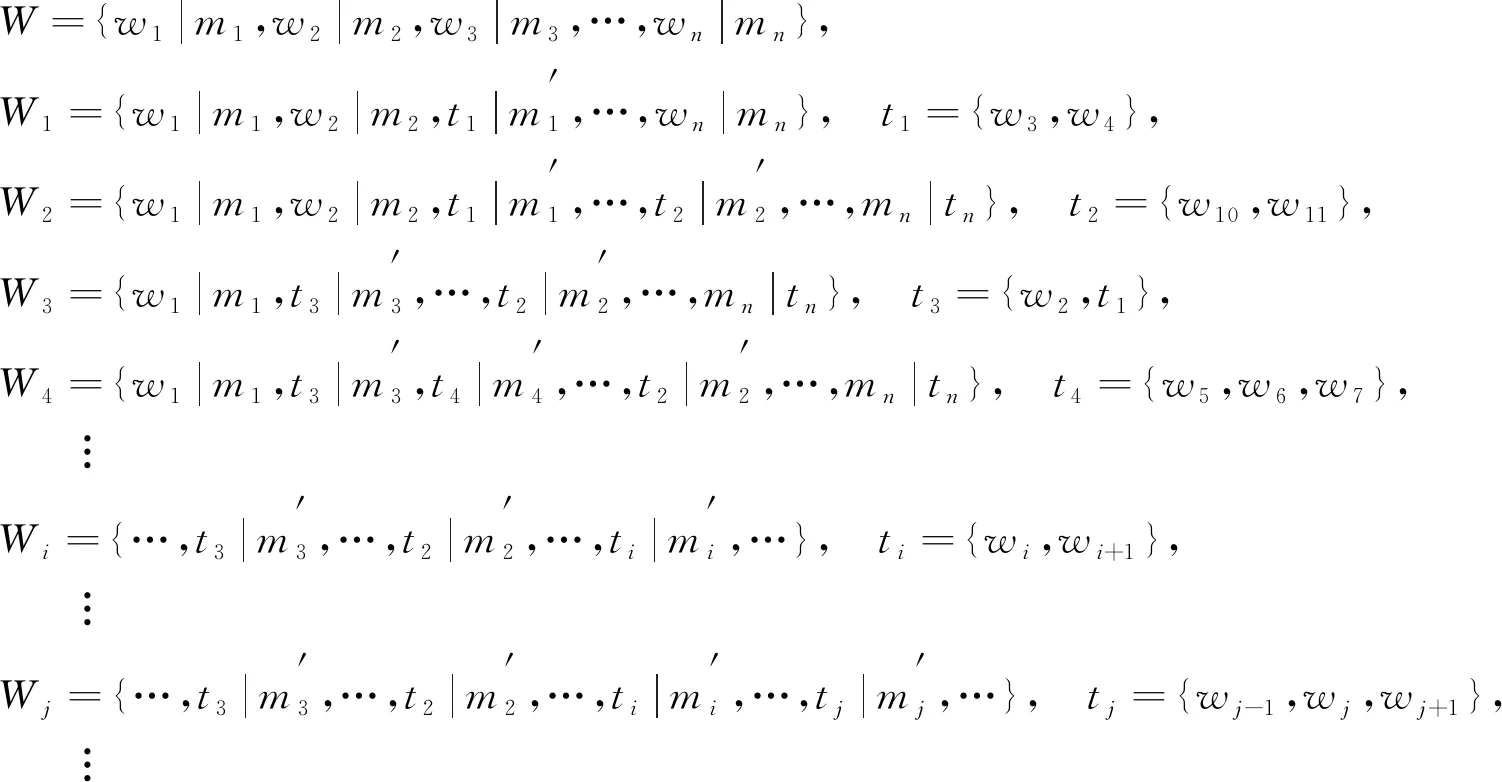
(12)
在层次化分析过程中按倒序的原则实现规则库匹配合成, 并非根据下标i或j升序的方式得到ti或tj.ti或tj可能还会再与相邻字符wi实现匹配, 直至规则库中无可匹配为止.
按照W′={wn|mn,wn-1|mn-1,…,wi|mi,…,w1|m1}的顺序扫描W′实现:
式(13)是对式(12)的一个分析合成解释, 表示根据表3中的句法合成规则, 按倒序原则对W′和规则库中所对应的词性进行交互, 实现规则匹配. 若倒序过程与规则库中的hc_m属性相同, 则输出第i/j次合成句子成分结果Wi或Wj. 在Wi,Wj基础上, 有
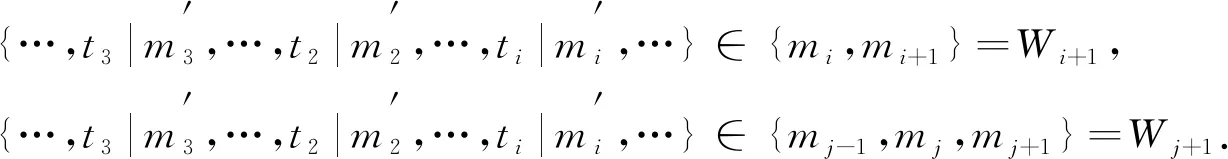
(14)
在最新合成句子成分结果Wi/Wj的基础上, 继续进行规则交互输出Wi+1/Wj+1, 其中Wi/Wj为第i/j(i,j⊆n)次合成句子成分结果,Wi+1/Wj+1是通过在Wi/Wj合成的基础上再次根据表3的合成规则按图3所述匹配方式实现合成, 直到无规则可匹配则合成结束. 例如, 字符串:
W={中国|n的|u改革|v开放|v和|c现代化|v建设|v继续|v向前|v迈进|v},
其中, “|”前为词, “|”后为其对应的词性. “v”和“v”可进行匹配合成, 根据扫描规则, “向前”和“迈进”可成功匹配为“向前迈进|v”, 如式(12)中的W1; 继续由后向前的原则进行扫描, 实现“继续|v”和“向前迈进|v”进行匹配结合, 得到“继续向前迈进|v”, 如式(12)中的W2; 同理, 依次循环, 得到Wi={我们的|n改革开放|v和|c现代化建设继续向前迈进|v}, 继续获得“改革开放|v”, “和|c”以及“现代化建设继续向前迈进|v”进行组合而成“改革开放和现代化建设继续向前迈进|v”, 如式(12)中的Wj; 直至最后得到“我们的改革开放和现代化建设继续向前迈进|s”, 具有“s”的标志或已无可匹配的规则, 从而层次化解析达到最优即结束.
1.4.3 层次化语句分析算法 基于现代汉语语法研究中对层次分析法的思想以及在汉语上对句法分析和规则的研究, 进而通过由语法和统计得出的语言分析规则实现层次化语法算法. 本文首次提出了二、 三词元相结合模型, 实现层次化语句分析算法, 其流程如图4所示.
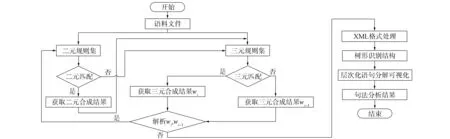
图4 层次化语句分析算法流程
算法步骤如下:
1) 读取语句W={w1|m1,w2|m2,w3|m3,…,wi|mi,…,wn|mn};
2) 按照wi+1wi顺序遍历二、 三元规则文本;
3) 将W和规则进行匹配;
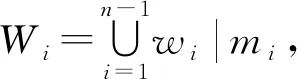
5) 若二元规则与W不匹配, 则按照mi+1,mi,mi-1倒序方式与三元规则匹配;
7) 若三元规则不符合匹配, 则输出Wi-1或Wj-1, 其中Wi-1/Wj-1表示上一步合成的结果;
8) 继续判断是否可继续分解Wi/Wj/Wi-1/Wj-1;
9) 循环第步骤2)~8);
10) 合成结果转换为能被识别的XML格式形式;
11) 将XML格式实现为可识别为目录树形结构;
12) 语句层次化分解可视化.
在层次化语句分解过程中, 利用分词和词性标注模型对句子的词序列获取当前最新词性并实现标注, 例如:
S={小明|n和|c小|a贾|n欢乐|a地|u骑|v小蓝|n车|n去|v呈贡区|n饭店|n吃|v锅包肉|n}.
图5为具体的层次化分过程. 经过层次化语句分解后, 将得到的Wi/Wj最终转化为能被识别的树形结构格式, 进而实现语句解析可视化结果, 如图6所示.
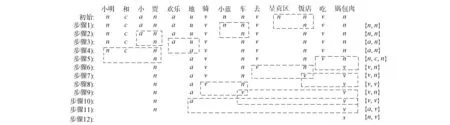
图5 语句分解示例
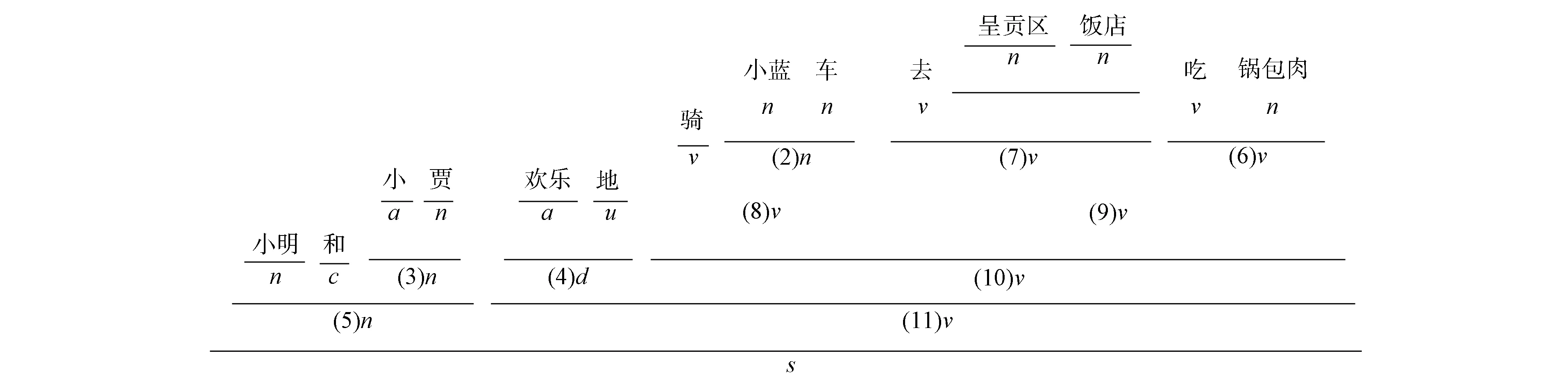
图6 层次化语句解析可视化示例
1.5 基于多层协调的句式识别算法
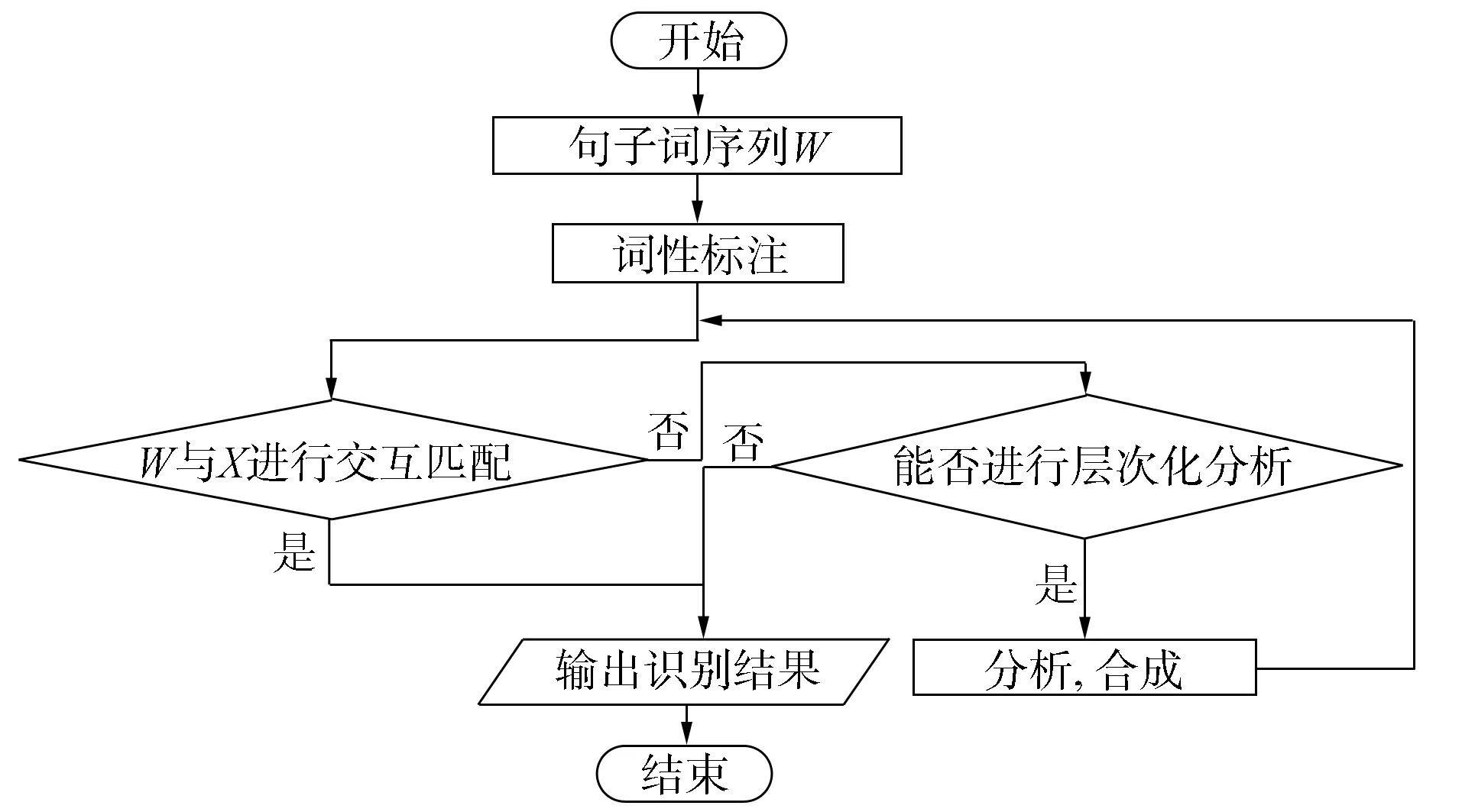
图7 多层协调句式识别算法流程
句法分析中, 针对句式的研究通常只从句子中的搭配关系、 特定句式框架、 特定字符等说明其方法的作用, 但在针对一个完整的字符串序列时, 这些方法将不再适用. 本文提出的句式识别算法解决了该类问题, 算法流程如图7所示, 其中X表示句式识别框架及规则模板的构建, 即W在句式识别框架中通过规则模板能否匹配成功, 如果匹配失败, 则W通过二、 三元语句分析实现层次化合成. 算法流程如下:
1) 输入句子词序列W;
2) 对W词性标注;
3) 利用规则模板实现与W交互匹配, 其中W⊆X当且仅当Vwi∈W⟹wi∈X;
4) 若步骤3)中W能与X匹配成功, 则成功输出识别结果;
5) 若步骤3)中W与X无法匹配, 则W通过二、 三元语句分析模型实现W的层次化合成;
6) 循环步骤3)~6);
7) 输出分析合成识别结果.
2 实验结果与分析
为验证本文方法的有效性, 在汉语数据集上进行测评实验.
2.1 实验设置
为验证实验结果的可靠性, 本文选择1998年1月份的人民日报进行测试, 对语料按每个“!”、 “?”或“。”作为一句划分. 在操作过程中分别使用9 000,11 000,13 000句作为测试集, 对测试集进行等差形式的叠加. 此外, 本文采用传统的精确率(P)、 召回率(R)和F1值作为实验结果的评价标准, 其中:

(15)
其中平均召回率R和平均F1值的获取采用与平均精确率同样的方法.
2.2 结果分析
为测试层次化语句识别算法的效果, 分别只在语句识别算法A和基于层次化模型的语句识别算法B下实现测试, 实验结果列于表4. 由表4可见, 在模型A和B中, 精确率、 召回率都随测试条数的增加而呈现升序, 证明了语句识别算法的可行性. 实验结果导致未能成功识别的主要原因如下:
1) 由于在句式识别框架中, 规则模板的制定只从单一的动词谓语句式表获取, 规则制定不全面, 所以导致在句子识别过程中不能更多地识别;
2) 根据语言规则, 在二、 三元语句层次化分析中规则库的建立不完善, 所以导致在语句层次化分析、 合成过程中覆盖不全面;
3) 由于语料处理的不规范, 在层次化分析规则库中, 语料与规则库不能成功匹配, 所以导致句子分析、 合成难度增大, 从而未能成功合成;
4) 由于在设定“!”、 “?”或“。”作为一句划分时, 未能概括全面导致每句过长, 句式识别规则库中与之无法匹配, 所以导致句子不能识别.
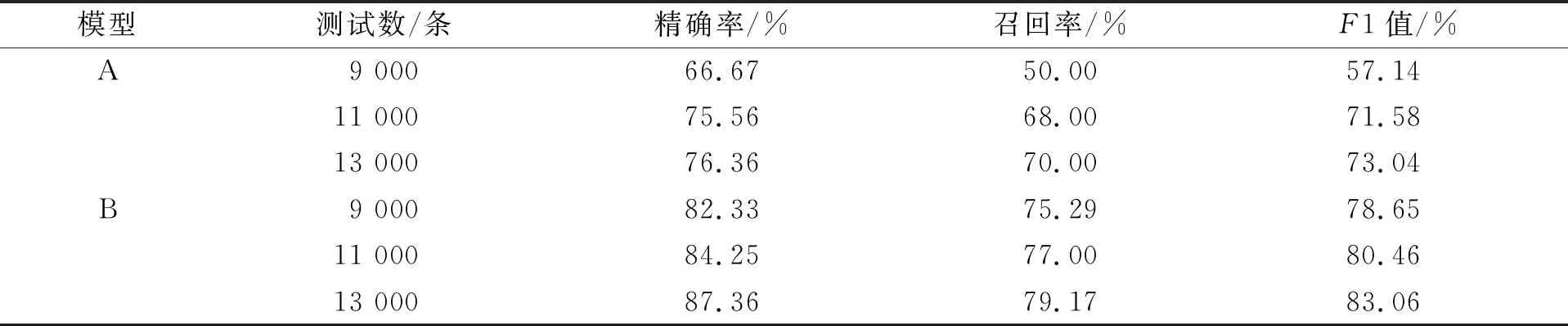
表4 语句识别算法实验结果
在模型A中, 平均精确率、 平均召回率分别为72.86%和62.67%; 在模型B中, 平均精确率、 平均召回率分别为84.65%和77.15%. 可见模型B的平均精确率比模型A的平均精确率高, 表明语句识别算法合理、 有效, 层次化语句分析中只要规则足够合理、 全面, 就能更好地达到语句分析识别算法的精度.
综上所述, 针对在自然语言研究中, 基于句法的发展受汉语自身特点限制的问题, 本文基于较有代表性的人民日报语料, 通过由语法和统计得出的语言规则实现了中文的语句分析和识别, 使层次化语句分析识别的平均精确率、 平均召回率分别达84.65%和77.15%, 效果较理想.
