一种基于深度学习的中文图像描述模型
2020-07-18郭淑涛赵德新
郭淑涛,赵德新
(天津理工大学计算机科学与工程学院,天津300384)
深度神经网络在计算机视觉、自然语言处理、多媒体分析等多方领域被广泛使用并取得了突出的效果,展现出优异的学习能力和表达能力,同样的,深度神经网络可以应用于图像描述任务.图像描述任务作为跨学科跨领域的交叉研究问题,实质就是使计算机能够自动的对图片生成一句描述性文字,这对人来说很容易,对机器来说却很有挑战性.计算机需要提取图像的物体特征、空间联系、语义关系等信息,生成人类可读的清晰表达出图像内容的句子,并力求句子准确、通顺.一直以来,在图像内容和语义解释之间建立合理的联系被认为是一种弥合语义鸿沟的有效方式[1],图像描述任务就是试图建立这种合理的联系.当前该任务主流的研究方向是如何将图像生成英文描述,显然,这项研究不应该受到语言限制,中文作为世界上使用人数最多的一种语言,有着广泛的使用人群,因此,中文图像描述的研究很有必要性.
鉴于神经网络成功应用于图像分析领域,所以,基于神经网络的图像描述成为目前主流的研究方法,其中大多数都是利用编码器和解码器结构,卷积神经网络convolutional neural network(CNN)充当编码器,编码器负责图像视觉特征的提取,循环神经网络recurrent neural network(RNN)充当解码器,解码器负责句子的生成.Vinyals[2]等人提出了用端到端的方式系统解决图像描述任务,并发布了Google NIC模型. Jia[3]等人提出了一种拓展的长短时记忆网络gLSTM,从图像中提取语义信息作为图像的额外补偿输入到每个gLSTM 的单元中,gLSTM 取代LSTM生成最终的描述.Xu[4]等人提出了注意力机制,该机制能够提取最显著的图像特征,更好的表达图像的细节,使得最终生成的描述句子更准确.刘泽宇[5]等人在编码器端采用了CNN 网络结构Ineption-v3[6]来提取图像的视觉特征,同时构建一个小的CNN 网络结构生成图像的多标签关键词,解码器端用LSTM生成图像的描述.Rennie[7]等人加入强化学习机制,提高了神经网络的学习能力,生成了准确的描述句子.Yang[8]等人在LSTM 生成句子描述的过程中加入了表示情感的词汇,生成的句子更富有情感.之前的工作中,已经提出了一种多模态神经网络模型[9],该模型在编码器端采用了CNN 网络Ineption-v3 提取图像的视觉特征,提出了ATTssd 来补充图像属性信息,提出了CNNm 来补充序列生成时丢失的重要信息.此次,采用了比Ineption-v3 更复杂的CNN 网络Inception-v4 和Inception-ResNet-v2[10],它们融合了注意力机制来降低卷积过程的损失,得到更好的图像视觉特征,提出了记忆助手来解决RNN 生成序列时信息丢失的问题.
1 多模态神经网络模型
提出的多模态神经网络模型是由编码器和解码器组成,如图1 所示,编码器采用CNN,具体是Inceptionv4 和Inception-ResNet-v2,章节1.1 将会介绍这两种CNN 网络结构. 解码器采用的是循环神经网络(RNN),RNN 具体使用的是LSTM 和GRU,章节1.2将会介绍这两种RNN 网络结构.在RNN 预测每一个单词的过程中,注意力机制重新计算图像中显著位置的权重并聚焦于图像中相应的区域,重新计算的权重将输入到RNN 中,这有利于提取更细节的图像视觉特征.在RNN 预测每一个单词的过程中,记忆助手将关键的单词信息填充到RNN 中,引导RNN生成更好的句子.

图1 多模态神经网络模型Fig.1 Multi-modal neural network model
1.1 编码器
编码器采用的CNN 来提取图像的视觉特征,我们的CNN 采用的是Inception-v4 和Inception-ResNetv2,Inception-v4 是在Ineption-v3 的基础上发展得来的,改善了Ineption-v3 的模型结构,是inception 模型的进一步发展,实验证明Inception-v4 比较于Ineption-v3 对单帧图像的识别能力更强,因此采用了Inception-v4 进行实验.由于残差网络模型ResNet[11]优异的表现,Inception-ResNet-v2 借鉴了ResNet 的设计思想,是一种在Inception-v3 的基础上改进并提出的CNN 模型结构,该模型提取图片的纹理信息和细节更完善.Inception-v4 和Inception-ResNet-v2 模型大体上沿用上Ineption-v3 的思想,采用小的卷积核来代替大的卷积核,这种替代保持感受野的范围的同时减少了参数量,反而不会导致表达损失. 同时,在模型当中广泛添加非线性激活函数来提高模型的性能.采用迁移学习的方法,两种模型在大规模数据集ImageNet 上得到预训练的模型参数.对图像固定缩放、随机裁剪、水平翻转,得到229×299 的3通道图像.
1.2 解码器
解码器结构采用的是LSTM 和GRU,它们能够有效的避免传统循环神经网络(RNN)的梯度消失和梯度爆炸,有效解决了信息传输过程中长期依赖的问题,确保了信息在长过程传输中不丢失. GRU 是LSTM 的变体,GRU 结构比LSTM 更加简单,但是对于信息的捕获能力却很强,GRU 将输入门和遗忘门融合调整为更新门,将细胞状态和隐藏状态混合,复位门控制当前状态中哪些部分用于计算下一个目标状态,更新门更新相应的信息.在中文图像描述的过程中,注意力机制需要关注编码器提取的图像的内容和解码器生成的中文词语信息,并依据输入的图像内容和序列生成的中文词语信息预测下一个中文词语信息,并聚焦于该图像所在区域. 采用的是soft-attention[4],它和复杂的CNN 网络可以更好地把握图像的细节. 解码器端是生成句子描述的关键,在LSTM 和GRU 生成描述的过程中,往往会丢失重要的词信息,从而导致生成的序列不准确,因此提出了记忆助手,在RNN 生成词信息的过程中,记忆助手会加入关键的词信息,引导生成更好的句子.
2 记忆助手
在RNN 生成序列的时候,随着RNN 时间片的增长,梯度误差在反向传播过程中会逐渐消失,从而导致后续时间片生成的单词缺乏先前的信息引导,这也会导致预测的单词不准确,甚至生成的整个序列有错误. 为了解决这一问题,在RNN 做每一个单词预测时,记忆助手会提取当前图像的重要的序列特征,并将这些特征加入RNN 每一个单词预测的过程中,引导RNN 生成更加准确的句子.在RNN 做每一个单词的预测时引入记忆助手,记忆助手提供16个重要的词信息填充到循环神经网络中.

图2 记忆助手用于提取序列特征Fig.2 Memory aid used to extract sequence features
受到记忆网络[12]的启发,提出的记忆助手提取序列特征.如图2 所示,记忆助手需要建立两个记忆插槽(memory slot),分别是输入插槽(input memory slot)和输出插槽(output memory slot).针对一句话中的序列x0,x1…xi通过嵌入层A 处理后得到一个嵌入矩阵A(大小为嵌入层维度× 词表长度),序列x0,x1…xi通过嵌入层B 处理后得到一个嵌入矩阵B(大小为嵌入层维度× 词表长度),输入插槽和输出插槽分别经过全连接层和激活层处理. 使用Mi,Mo区分输入插槽和输出插槽,使用i,o作为上标区分输入和输出.

两个记忆插槽的最大存储长度定为d= 16,最终输入插槽Mi和输出插槽Mo的定义如下:
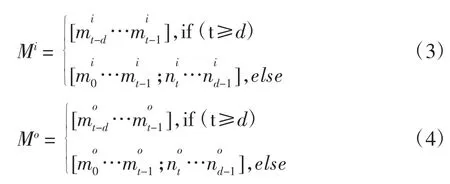
当t≥d时,输入的句子将会被裁剪成只保留后16 个词向量的句子.当t 当前时间片的输入词向量xt经过一层全连接层和激活层转换成内部状态inst: Wins∈R512×512,bins∈R512×512,输入插槽Mi和inst矩阵相乘后,经softmax 函数得到中间状态u,u是概率向量,表示输入插槽中不同词向量的重要程度.u和输出插槽Mo按照元素相乘()重新调整输出插槽的每一列. 其中,Msum∈Rd×512,利用时间卷积层[13]对序列数据提取特征.时间卷积层定义为: 一共经过5 个时间卷积层,卷积核h大小依次为5,5,4,3,3. 然后,增加一个多模态融合层,它融合了当前词向量xt、记忆助手提取的句子特征表达和注意力机制得到的图像向量ATTt,多模态融合层的公式表达如下: 当前时刻的词向量xt和直接相加,再连接ATTt,然后经tanh 函数激活.采用“⊕”表示不同数据间的连接操作. 接下来是实验部分,采用多种实验指标来进行衡量. 本文采用的AI CHALLENGER 数据集[14]是2017年提出的人为标注的大规模中文数据集,其中,训练集有21 万张图片,验证集有3 万张图片,测试集有3万张图片,数据集的质和量都完全超过其他中文数据集,大规模的数据集使得实验的准确度和可信度更高.如上图3 所示,A、B、C 图中句子较长,语言准确完整,5 句话的描述相近,都能准确的表达出图像内容. 在实验过程中,使用的操作系统是Ubuntu18.04 LTS,使用的显卡是NVIDIA 1080 Ti,使用的深度学习框架是Pytorch,使用的中文分词工具是结巴分词. AI CHALLENGER 数据集词汇表大小为8 564,词汇表中添加 图3 中文数据集示例Fig.3 Example of Chinese data set 本文一共采用了7 种指标衡量中文描述生成结果的质量. BLEU[15]:常用来当作机器翻译的评价指标,能够分析机器生成语句和参考语句间的N 元文法准确率.METEOR:利用单精度的加权调和平均数和单字召回率的方法改善BLEU 指标存在的问题.ROUGE-L:通过比较召回率的相似度来度量指标,不足之处是该算法的N 元文法要求是连续的.CIDEr:通过共识评价指标,是一种特别的图像描述评价指标,具有重要参考价值.在表1 中,用B@1,2,3,4 指代BLEU-1,2,3,4,Rouge 指代ROUGE-L,Incepv4 指代Inception-v4,Incepresv2 指代Inception-ResNet-v2,ATT 指代注意力机制,MA 指代记忆助手. 如表1 所示,Baseline[14]是官方公布的在AI CHALLENGER 数据集的各项指标,提出的基于注意力和记忆助手的多模态神经网络模型取得最好的实验效果,其他的4 种不同子模型组成的网络模型也都提高了各项实验指标. 通过对比实验,发现当CNN 结构同是采用Inception-v4 时,LSTM 的表现要稍微好于GRU,推测对图像描述这一任务LSTM 的效果比GRU 要更好. 当RNN 结构同是采用LSTM 时,Inception-v4 和Inception-ResNet-v2 的实验指标基本相同.虽然Inception-ResNet-v2 比Inception-v4 结构复杂,网络深度深,但对图像描述任务来说,二者提取图像视觉特征的能力大致相同. 如图5 的展示,发现Inception-ResNet-v2 提取的细节信息更多,Inception-v4 提取的宏观特征更好. 当CNN 为Inception-ResNet-v2 时,加入注意力机制(ATT)后,Inception-ResNet-v2+LSTM+ATT 的神经网络模型取得比Inception-ResNet-v2 + LSTM 更好的实验效果.当加入记忆助手(MA)后,Inception-ResNet-v2+LSTM+ATT+MA 进一步提升了各项实验指标. 如下图4 所示,图中的黑色字体为原数据集上的中文描述,图中的彩色字体为不同的实验模型生成的句子. 显然,Inception-v4 + LSTM 比Inception-v4 +GRU 生成的句子更长,语言更加准确细腻.Inception-ResNet-v2+LSTM 和Inception-v4+LSTM 生成的句子长短相近,但是图像细节表达的更多.加入注意力机制(ATT)后生成的句子更准确通顺,例如:A 图中去掉了繁琐的不准确的描述,加入了两个人、椅子、电脑等关键信息,B 图中能够识别处图中有4 个人,而不是3 个人,C 图的细节表达很好,能够识别出一群人,但是却将帽子认成了头盔,加入记忆助手后,语句表达更加饱满,图像细节描述的更完善,A 图中能识别出深色上衣、浅色上衣、桌子,B 图中点出白色衣服、裙子,C 图中识别出了帽子,而没有识别成头盔. 表1 AI CHALLENGER 数据集上各模型的指标Tab.1 AI CHALLENGER evaluation indicators for models on datasets 图4 实验模型生成的中文描述Fig.4 Chinese image caption of experimental model generation 本文提出了一种自动生成图像中文描述的多模态神经网络模型,并提出了记忆助手来解决循环神经网络生成序列时信息丢失的问题,实验指标显著提升,生成的句子更准确,语言表达更饱满,不同的子模型组成的多模态神经网络模型同样提高了实验指标.


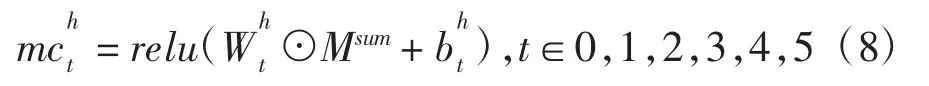

3 实验过程

4 实验结果


5 结 论
