基于条件信息卷积生成对抗网络的图像识别
2020-07-17林蔚天
李 鑫,焦 斌,林蔚天
1.上海电机学院 电气学院,上海 201306
2.上海电机学院 继续教育学院,上海 200240
1 引言
生成对抗网络(Generative Adversarial Network,GAN)是Goodfellow等在2014年提出的一种生成模型[1],该生成模型与传统生成模型的区别在于其包含了生成网络和判别网络两部分,生成网络和判别网络是一种对抗博弈的关系[2]。GAN思想源于零和博弈,当一方的利益增加时,另一方的利益就会随之减少。引用到生成对抗网络中,生成网络利用输入的初始数据经过数据拟合生成尽量逼真的数据,而判别网络的作用是将拟合生成的“假数据”和“真实数据”进行对比,最终判别生成数据的真实性,同时生成网络继续利用判别网络的结果优化生成网络各项参数,最终两个网络实现纳什均衡[3]。图像识别现有方法如卷积神经网络(Convolutional Neural Networks,CNN)等已经有很高的识别率,但这些方法依赖大量数据并且收敛速度较慢[4]。本文结合条件生成对抗网络、信息最大化生成对抗网络与深度卷积网络提出带有条件的信息最大化深度卷积生成对抗网络模型(Conditional-Info-DCGAN,C-Info-DCGAN),利用该模型提取的特征用于图像识别。实验结果表明,该方法能够提高训练收敛速度,并有效提高图像识别的准确率。
2 生成对抗网络原理
生成式对抗网络是一种深度学习模型,是近年来无监督学习最具前景的方法之一。基本模型是通过框架中两个模块:生成模型(Generative Model,G)和判别模型(Discriminative Model,D)的互相博弈学习生成以假乱真的数据样本[5]。原始生成对抗网络中的两个模型不一定是神经网络,只要是能够达到生成数据和判断真伪功能的网络都可以,但是经过长期大量的实验,把深度神经网络作为G和D是最常见且效果最好的。GAN运行过程中,首先给生成网络一个随机噪声数据x作为输入值,通过G生成尽量像真实数据的“假数据”G(z),判别网络负责判别生成数据的真假,并把判别结果反馈给生成网络,G以此来优化网络参数,最终生成让判别网络判断不出真假的数据。GAN的流程图如图1所示[6]。
GAN核心原理的算法描述如下:
在生成网络给定的情况下,优化判别网络和判别网络是一个二分类模型,训练过程如式(1)所示:
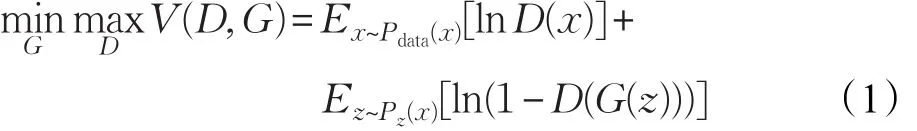
式中,x表示真实样本;z表示输入生成模型中的随机噪声;D(x)表示判别模型判断输入样本为真实样本的概率;G(z)表示生成模型接受随机噪声后生成的样本;Pdata(x)表示真实数据分布;Pz(z)表示生成数据分布。判别模型的目的是能够准确判断出输入样本的真实性,也就是使D(x)无限接近1,D(G(z))无限接近于0,此时V(D,G)变大,即求maxD。生成模型的目的是生成更接近真实的样本,也就是使D(G(z))无限接近于1,此时V(D,G)变小,即求 minG[7]。
GAN相对于其他生成网络能够产生更好的数据样本,但是其还存在许多问题亟待解决,比如GAN模型训练难以达到稳定、生成网络和判别网络难以达到纳什均衡等。
3 改进生成对抗网络设计
为了应对原始GAN难以稳定等问题,近些年许多学者在其基础上进行了改进与优化,其中条件生成对抗网络和信息最大化生成对抗网络在解决原始网络存在的部分问题中具有很大贡献。
3.1 条件生成对抗网络
条件生成对抗网络(Condition al Generative Adversarial Nets,CGAN)是在GAN的基础上加上了条件信息,如果生成网络和判别网络都适用于某些额外的条件c,例如类别标签,那么可以通过将c附加到输入层中输入到生成器和判别网络中进行调节,可以指导数据生成过程。CGAN把纯无监督的GAN变成有监督模型的一种改进,这种改进被证明非常有效,并广泛应用于后续的工作中[8]。
在生成网络中,输入噪声的同时输入相应条件c,而真实数据x和条件c作为判别网络的输入。其目标函数V(D,G)如式(2)所示:

生成网络和判别网络都增加了额外信息,在生成模型中,噪声z和条件信息y构成隐层表征,对抗训练框架在隐层表征的组成方式方面相当灵活。
3.2 信息最大化生成对抗网络
InfoGAN发布于NIPS2016,解决了控制生成数据语义特征的问题,GAN模型使用不受任何限制的噪声信号z作为输入,因此生成网络只能以一种高度混乱的方式使用噪声,导致噪声z中独立的维度与数据的语义特征不对应[9]。InfoGAN提供了解决方案,即分解输入噪声为两个部分。其中,z作为不可压缩的噪声源,c作为潜在的部分,对数据分布潜在结构进行导向,而生成器输出为G(z,c)。原始GAN模型中相当于通过公式忽视了输入类别信息c,本文方法提出c和G(z,c)之间应该有高度共同的特征。其目标函数V(D,G)如式(3)所示:
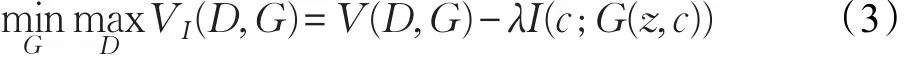
3.3 改进生成对抗网络
在图像识别技术领域,缺少训练样本、图像分类识别率低等问题亟待解决,而生成对抗网络是解决这些问题的一个热门方向[10],但是现有的网络模型还难以很好地解决这些问题,因此,本文基于现有的GAN网络,提出了一种条件信息最大化生成对抗网络(C-Info-GAN),该网络模型能够很好地解决图像识别领域的问题[11]。

图2 C-Info-GAN结构图
C-Info-GAN模型还是基于生成网络和判别网络相互博弈的思想,但是生成网络的输入不仅是噪声信号,而是包括三部分,噪声数据、潜在隐含信息、类别信息,三者组合作为生成网络的初始输入,输出“假数据”G(z,c,l);判别网络的输入包括两部分,一部分是生成的“假数据”,另一部分是包含类别信息的真实数据,判别网络通过对两个输入进行对比处理,判断生成数据的真假,并将判断结果的损失值反馈给生成网络和判别网络,优化网络各项参数。
除此之外,为了更好地利用类别信息和潜在隐含信息,增加一个Q网络,该网络与判别网络的权值共享,输入数据为G(z,c,l),利用Q网络的深度卷积网络和相适应的判别器,完成对类别信息和潜在隐含信息的分类处理,并将两者的损失值反馈给生成网络和判别网络,以此不断优化,最终生成以假乱真的样本数据。当模型训练完成之后,为了实现图像识别同时简化网络结构的目的,还是以Q网络作为图像识别网络,将生成数据按照一定比例补充到原始训练数据集中,对原始数据进行数据增强,随着补充数据量的增加,识别网络的准确率也会增加。C-Info-GAN的结构图如图2所示。
3.4 深度卷积生成对抗网络
深度卷积生成对抗网络(DCGAN)主要是在生成网络和判别网络中引入深度卷积的结构,从而利用深度卷积网络的强大特征提取能力来提升整体模型的效果[12]。
相较于原始GAN,DCGAN具有很多特点:
(1)在生成网络中使用反卷积网络实现将输入数据生成“假数据”的功能,在判别网络中用卷积层代替池化层,并搭配合适的分类判别器。
(2)在网络模型中,对于各个卷积层均采用批量归一化,这样使得初始化差问题得以解决,并保持网络的传播梯度,防止过拟合的现象。
(3)将卷积层作为生成网络和判别网络的输出层,提高模型稳定性,但是却减弱模型训练的速度。
(4)生成网络输出层的激活函数使用Tanh函数,剩下的网络使用ReLU激活函数;而判别网络中均使用LeakyReLU激活函数[13]。
4 基于条件信息深度卷积生成对抗网络的图像识别
本文基于CGAN、InfoGAN和DCGAN网络模型,结合为应对图像识别领域的问题所做出的改进,设计出基于条件信息深度卷积生成对抗网络(C-Info-DCGAN)模型,增加类别信息和潜在隐含信息作为输入,并利用深度卷积网络提高模型的特征提取能力,同时增加Q网络完成对类别信息和潜在隐含信息的处理。
4.1 C-Info-DCGAN模型结构
C-Info-DCGAN的生成网络结构如图3所示,此处以MNIST数据集的28×28像素图像为例,输入数据由三部分组成,包括100维的满足高斯分布的随机噪声、10维的类别标签数据和10维潜在的隐含信息数据,其中10维类别信息表示0~9的10种手写数字类别,10维隐含信息表示具有先验概率分布的连续随机变量,描述手写数字的粗细、大小、长短等特征,三者连接在一起组成120维的输入数据,接着利用两个全连接层,依次将输入数据扩展到1 044维和6 292维,然后为了适应接下来的反卷积网络,将数据重置为(7,7,148)的三维张量,之后利用两层反卷积层,将数据依次处理成(14,14,84)和(28,28,1)的三维张量,其中反卷积网络的卷积核为4×4,步长为2,最后输出(28,28,1)的生成数据。另外,与一般CGAN不同的是,为了加强类别信息和潜在隐含信息在训练过程中的引导作用,在全连接层和反卷积层中这两者并没有参与运算,例如:100+10+10维的输入,经过全连接层的处理并重置输出为(7,7,128)+(1,1,20)=(7,7,148)。
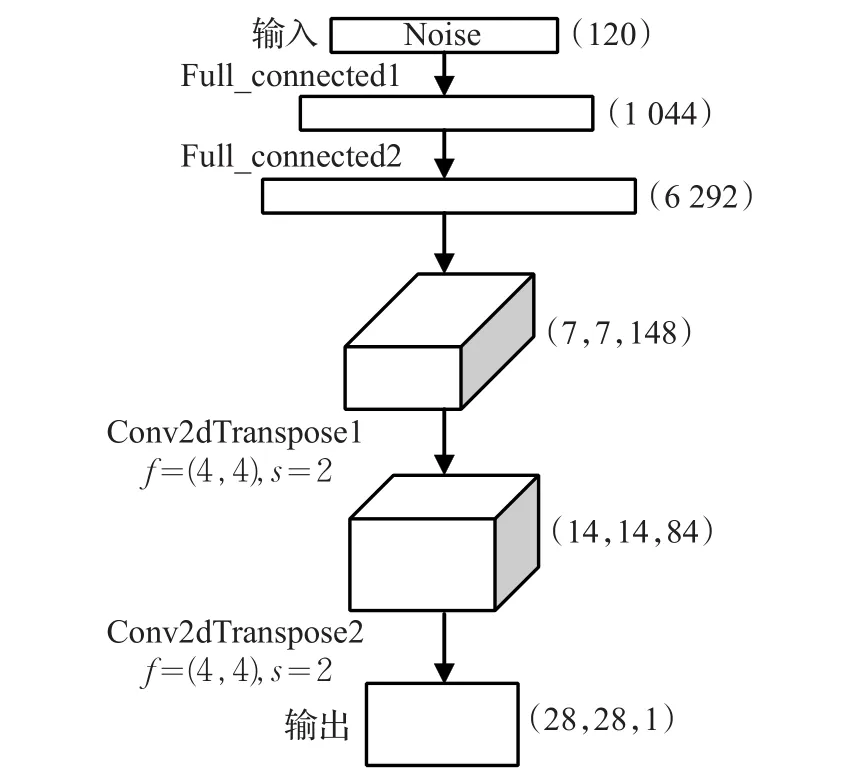
图3 C-Info-DCGAN生成网络结构图
C-Info-DCGAN的判别网络结构如图4所示,整体结构相当于生成网络的逆过程,其中输入包括生成的“假数据”和带有类别信息的真实数据,利用判别网络对其分别处理。以MNIST数据集为例,输入28×28像素的图像,然后利用两层卷积层依次输出为(14,14,64)、(7,7,128)的三维张量,其中卷积核为4×4步长为2;接着经过两个全连接层将数据分别变成1 024维和100维,激活函数均使用Leaky_ReLU,最终输出就是判断输入值真假的结果,具体网络模型参数如表1所示。

图4 C-Info-DCGAN判别网络结构图
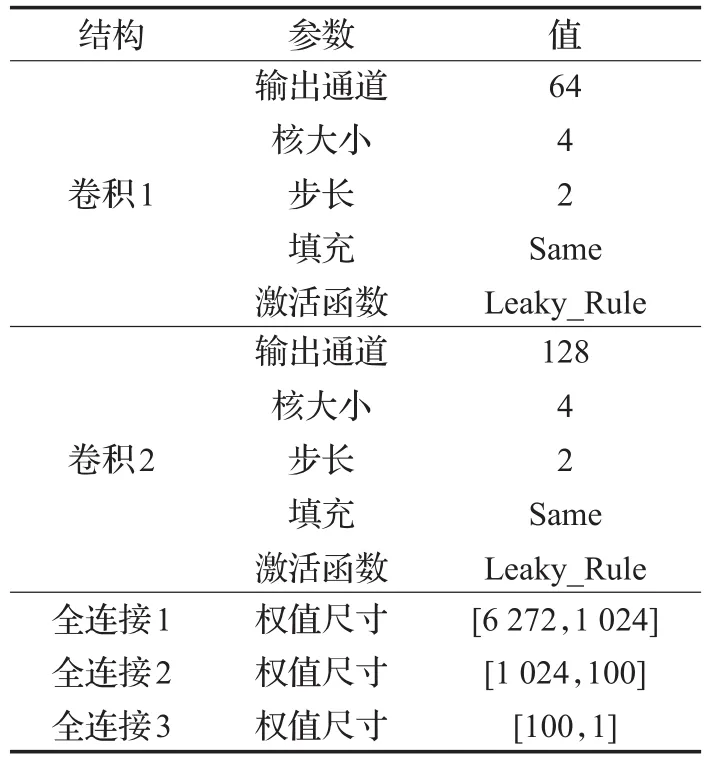
表1 判别网络模型参数
除了生成网络和判别网络之外,本文设计的模型中还加入了一个Q网络,该网络中除了输出层以外的网络结构均与判别网络进行权值共享,输入数据是生成的包含类别信息和潜在隐含信息的“假数据”,在Q网络的最后一层利用分类器,对类别信息和隐含信息进行分类处理,输出(2,10)的数据,其中包含10维的类别信息和10维的潜在隐含信息。Q网络的结构图如图5所示。

图5 Q网络的结构图
4.2 基于C-Info-DCGAN模型训练和图像识别
loss_dr表示判别网络正确判断真实数据类别的准确率,loss_df则是成功判断生成数据类别的准确率,判别网络损失值loss_disc取这两者的平均值。生成网络的损失值为自己输出的假数据让它在判别网络中为真,定义为loss_g。在Q网络中还有一部分损失函数,包括隐含信息的重构与初始隐含信息的误差loss_con、真实的标签与输入真实样本判别出的标签交叉损失loss_cr、真实的标签与输入生成数据判别出的标签交叉损失loss_cf,其中类别信息总损失loss_class取loss_cr和loss_cf的平均值。定义好后创建两个优化器,将它们放到对应的优化器中。生成网络损失函数Loss_G如式(4)所示。判别网络和Q网络损失函数Loss_D,Q如式(5)所示,其中m表示批量处理的样本数量,gen_f表示生成样本判别结果,y_real表示判别为真的标准结果,y_fake表示判别为假的标准结果,class_f表示对生成数据的分类结果,class_r表示对真实数据的分类结果,y表示真实数据的类别信息,con_f表示生成数据的隐含信息结果,z_con表示初始化的隐含信息,disc_f表示对生成数据的判别结果,disc_r表示对真实数据的判别结果,损失函数主要利用sigmoid的交叉熵思想。
Loss_G=loss_g+loss_class+loss_con=


将判别网络的学习率设为0.000 01,将生成网络的学习率设为0.000 1,这使得生成器有更快的进化速度来模拟真实数据,优化采用Adam方法。为了保持对抗训练的平衡性,模型将判别网络和生成网络的更新速度比设置为1∶2,防止训练梯度消失[14]。
本文将训练好的C-Info-DCGAN应用到图像识别领域中,选取Q网络的部分结构(去除输出层),并进行参数微调,在最后一个全连接层输出n维数据(n为数据集类别数),然后再利用Softmax分类器完成分类识别[15]。与一般图像分类方法不同的是,输入的数据集并不是直接进行分类处理,而是经过基于C-Info-DCGAN模型的预训练,使得在进行图像识别的时候,除了有真实样本外还有模型训练生成的足够以假乱真的“假数据”做支撑,起到数据增强的作用,从而获得更多的图像特征,实现更高的分类识别率。
5 实验结果与分析
本文实验环境为Intel®CoreTMi5-3230M CPU@2.6 GHz处理器,12.0 GHz运行内存(RAM),NVIDIAGeForceGT 740MGPU,整体模型是在Python的框架中利用TensorFlow平台进行编程实现,实验使用MNIST手写数字集和CIFAR-10彩色图片数据集。
5.1 MNIST实验
MNIST手写数字集中包含60 000张图片,10个类别(0~9共10个数字),每类别包含6 000张图片(5 000个训练样本,1 000个测试样本),每张图片为28×28像素的二值图像[16]。
5.1.1 MNIST生成样本
实验中使用Adam模型优化,判别网络的学习率设为0.000 01,生成网络的学习率设为0.000 1,在生成网络和判别网络的每一个卷积层之后均使用批量归一化操作,可以防止训练时梯度消失,每一批次有64个样本,其中训练迭代次数与模型损失函数的关系如图6~9所示。
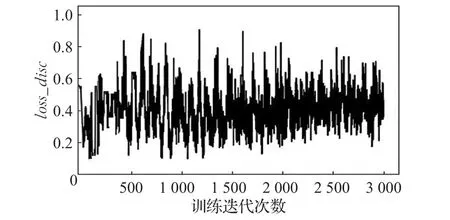
图6 MNIST数据集中loss_disc变化趋势

图7 MNIST数据集中loss_g变化趋势
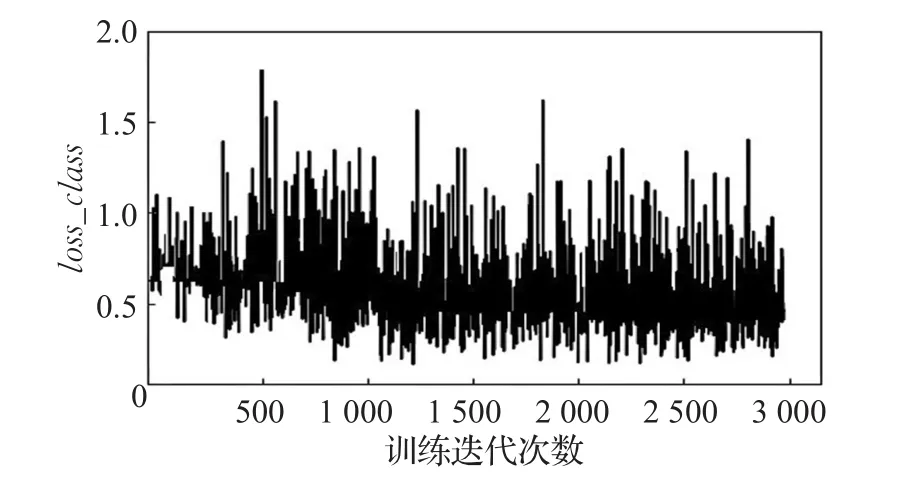
图8 MNIST数据集中loss_class变化趋势

图9 MNIST数据集中loss_con变化趋势
图6 中表示判别网络中正确判断真实数据类别和生成数据准确率的平均值loss_disc,随着训练迭代次数的递增而变化情况。可以从变化趋势图中看出,在训练初期判别网络的损失值较大模型不稳定,但是在训练1 000次之后损失值的均值稳定保持在0.4左右。图7表示生成网络的损失值loss_g,训练初期损失值相对稳定,随着不断训练损失值保持在1.25左右。
图8表示在Q网络中真实标签与输入真实样本判别的标签的交叉损失loss_cr和真实标签与输入生成样本判别的标签的交叉损失loss_cf的平均值loss_class,随着训练次数增加损失值稳定保持在0.5左右。图9表示潜在隐含信息损失值的变化趋势,整体变化趋势不明显,始终在1.5上下。总体来看,经过对抗训练判别网络、生成网络和Q网络损失值保持在一个稳定值。
图10表示在不同的训练迭代次数下生成网络所输出的“假数据”,图中可以看出,从刚开始杂乱无章的随机噪声到可以隐约看出数字形状,再到最后清楚显示手写数字图,表明本文设计的C-Info-DCGAN网络能够很好地完成数据生成与数据增强的任务。

图10 MNIST数据集生成样本对比
5.1.2 MNIST分类结果
本模型利用Q网络进行图像分类,选取学习率为0.000 2的Adam优化器,为了纵向对比本文设计的CInfo-DCGAN模型在图像识别方面的优势,实验另外训练了一个CNN模型作为对比,其中本文方法中生成数据与原始数据按照1∶2的比例进行数据增强,两种模型的类别信息损失值loss_class变化趋势图如图11所示。从图中可以看出随着迭代次数增加,CNN模型损失值变化表明该模型不稳定,而C-Info-DCGAN模型的损失值略有起伏,但基本上保持一个稳定值。这是由于本文提出的分类模型利用对抗训练能够有效地提取数据特征和数据最强,在其他条件相同的情况下,本文方法比CNN方法更快收敛且模型更稳定。

图11 MNIST数据集上loss_class变化趋势图
图12 表示Q网络中分类信息c和隐含信息l的准确率变化趋势,因为判别网络D和Q网络结构基本相同且共享各项参数,所以只选取Q网络的准确率,从图12中可以看出,随着迭代次数不断增加准确率也都不断增加,表示整个模型不断优化完善。

图12 MNIST上Q网络的l和c准确率变化趋势图
本文提出的方法具有数据增强功能,为了充分体现其价值,实验中将生成数据与原始数据按照不同比例组合作为训练数据集。不同比例下本文方法的识别准确率如表2所示。从表2中可以看出,随着生成数据在训练集中所占比例的增加,模型识别率也不断增加,说明本文方法确实可以达到增强数据和提高准确率的目的。

表2 不同补充数据比例下在MNIST上的识别率
除此之外,本实验还选取了在网络结构相似情况下基于SVM、PCA、CNN和RNN模型的图像识别,对比这些方法和本文方法在图像识别准确率方面的差别。各种方法在MNIST上的识别准确率对比如表3所示。从表3中可以看出,使用传统的机器学习方法SVM和PCA准确率可以达到92%左右,而CNN和RNN等深度学习方法准确率更高,可以达到94%~97%,而本文模型随着训练迭代的增加,图像识别的准确率可以稳定保持在98%左右。从以上的实验中可以看出本文方法的可行性与优势。
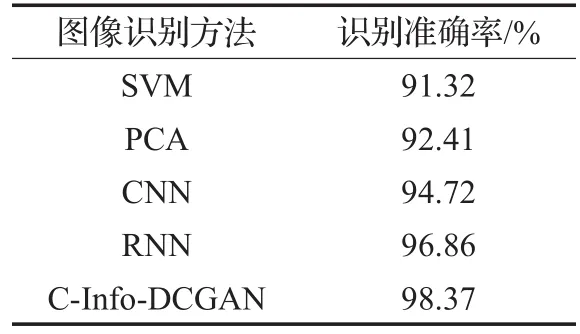
表3 不同方法在MNIST上的识别率
5.2 CIFAR-10实验
CIFAR-10数据集由10个类的60 000个32×32像素的彩色图像组成,其中包括50 000个训练图像和10 000个测试图像。因为是彩色图片集,所以每张样本是(32,32,3)的3通道彩色图[17]。
5.2.1 CIFAR-10生成样本
在CIFAR-10数据集上的实验,各项参数保持不变,图13表示判别网络中正确判断真实数据类别和生成数据准确率的平均值,整体趋势趋于平稳。虽然对抗训练导致变化趋势震荡严重,但是在训练达到1 000次之后损失值均值保持在一个固定值。图14表示生成网络输出的损失值,前期变化较大,后期整体变化趋势较平稳。图15和图16分别表示Q网络中类别信息和潜在隐含信息的损失值,整体趋势和判别网络的变化相似,前期变化不大,后期缓慢下降震荡严重但损失均值趋于平稳。

图13 CIFAR-10数据集中loss_disc变化趋势

图14 CIFAR-10数据集中loss_g变化趋势
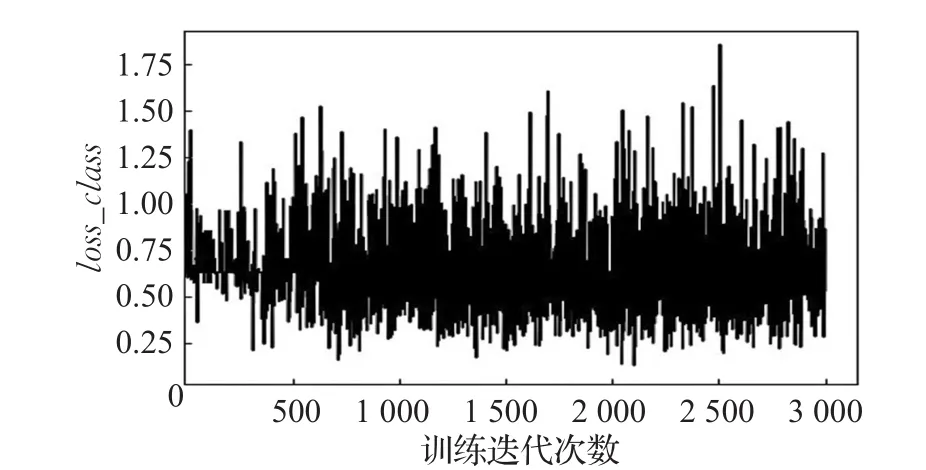
图15 CIFAR-10数据集中loss_class变化趋势

图16 CIFAR-10数据集中loss_con变化趋势
图17 表示在CIFAR-10数据集中不同迭代次数下实验生成样本的对比,可以看出从开始的杂乱无章,逐渐有了图形的轮廓,但是总体而言,生成效果比在MNIST数据集的生成效果差一些。
5.2.2 CIFAR-10分类结果

图17 CIFAR-10数据集的生成样本对比
在CIFAR-10数据集中同样是选取CNN模型与本文方法进行对比实验,本文方法中生成数据与原始数据还是按照1∶2的比例进行数据增强,图18表示在CIFAR-10数据集中CNN和C-Info-DCGAN两种方法损失值随着训练次数增加的变化趋势,可以看出两种方法的损失值都趋近于一个较小的稳定值,但是从训练的前半段可以看出CNN的起始损失值较大,且达到稳定的时间比本文方法要长,这主要是因为本文方法中训练样本是在对抗网络中预先处理,并把生成的样本作为补充数据提高训练速度。
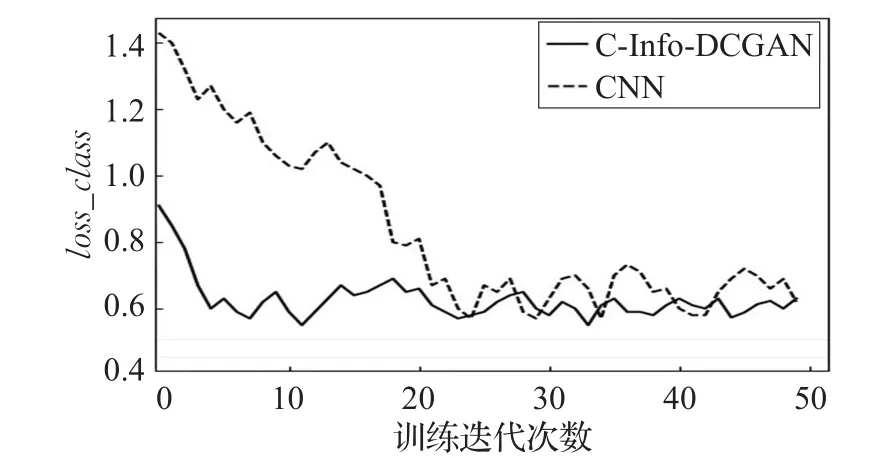
图18 CIFAR数据集上loss_class变化趋势
图19 表示这两种方法在图像分类准确性方面的表现,可以看出由于本文方法数据预先训练,所以分类训练开始的准确性就非常高,而CNN方法需要一段时间的训练来提升准确率,而且训练过程中模型不稳定,准确率变化较大。
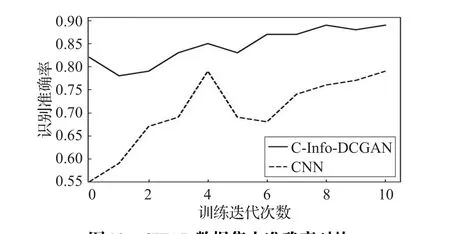
图19 CIFAR数据集上准确率对比
本实验中也将生成数据与原始数据按照不同比例组合作为训练数据集。不同比例下本文方法的识别准确率如表4所示。从表4与表2对比可以看出,在CIFAR中的准确率要低于MNIST数据集,但是准确率依然是随着生成数据在训练集中所占比例的增加而增加。

表4 不同补充数据比例下在CIFAR上的识别率
除此之外,本实验中同样选取了一些传统的图像识别方法与本文方法进行分类准确性对比,从表5与表3对比看出,因为CIFAR-10上图片的复杂性,导致准确率相对低一些,但是纵向比较各种方法的准确性发现,本文方法的准确率依然可达88%,说明本文方法在更加复杂样本中的表现依然具有很大的优势与可行性。

表5 各种方法在CIFAR上的准确率对比
6 结束语
本文基于条件生成对抗网络和信息最大化生成对抗网络,提出了改进的带有条件信息最大化生成对抗网络(C-Info-GAN),充分发挥类别信息和潜在隐含信息对对抗训练的引导作用,从而加速训练和提高生成数据的准确性。同时在网络结构中结合深度卷积网络,加强网络对特征提取的能力,从而提出能够用于图像识别的C-Info-DCGAN方法。为了验证该方法的可行性,本文通过在MNIST和CIFAR数据集上进行仿真实验。实验结果表明,相对于传统的图像分类方法,本文方法提高模型的收敛速度,在分类准确率方面也具有明显优势,所以证明本文提出的带有条件的信息最大化深度卷积生成对抗网络在图像识别领域具有可行性,接下来将针对模型训练后期对抗训练导致的震荡问题进行深入研究。
