顾及邻点变形因素的改进PSO-SVM模型大坝变形预测
2020-07-17袁志明李沛鸿刘小生
袁志明,李沛鸿,刘小生
(江西理工大学建筑与测绘工程学院,江西 赣州341000)
0 引 言
大坝变形的影响因素包括水压、气温和时效等因素[1],这些影响因素有着非稳定性、随机性和突变性等特点。 传统的预测方法存在诸多的局限性,时间序列方法要求符合正态分布;神经网络模型容易陷入收敛局部最小的缺陷[2]。 并且这些方法都属于单点数据的建模,没考虑到邻近监测点之间的相互影响,而实际监测情况中,监测点的变形趋势会受邻近监测点的影响,因此,预测模型的建立需要考虑监测点之间互扰性这一影响因素。
针对支持向量机 (Support Vector Machine,SVM) 模型存在的参数选择困难和拟合精度低问题[3],提出采用群智能优化算法对SVM 模型参数寻优的方法。 群智能优化算法包括粒子群算法(Particle Swarm Optimization, PSO)、鱼群算法和蚁群算法为主的三大寻优算法[4],其中鱼群算法收敛速度较慢、蚁群算法存在容易陷入局部最优和难以解决连续域等问题,而PSO 算法有着搜索效率高和收敛性能好的优点[5]。 因此,文中采用PSO 算法优化SVM 模型参数。PSO-SVM 模型已经成功应用于函数仿真实验、图像处理和分类预测等领域,单黎黎等[6]通过引入动量项改进PSO-SVM 模型,函数仿真实验的精度得到有效提高;毛耀宗等[7]提出的PSO-SVM 模型,在图像处理和分类预测实验中取得良好的处理精度,降低了原程序的运行时间。
PSO-SVM 算法仍然存在后期收敛速度慢和易陷入局部最优的问题,而现今,大多数学者针对粒子更新速度的改进采用固定参数设置的方法[8-9]。本文提出的引入标准柯西分布函数改进惯性权重取值是一种非固定参数的方法,能够依据算法搜索能力的需求适时地调整PSO-SVM 模型参数的数值。 并且组合一维小波分解函数,在保留有价值的边缘数据信息有效地去除样本数据的噪声。 此外改进的PSO-SVM (Improved PSO-SVM, IPSOSVM)模型考虑了邻近点这一变形因素,引入这一变形影响因子建立IPSO-SVM 模型,能对大坝形变做出及时预警,对于维护大坝安全运营有重要的意义。
1 基本原理
1.1 PSO 模型
粒子群优化算法来源于生物种群的行为特征[10],算法的粒子速度随着适应度值进行动态调整,从而完成粒子的寻优求解。 粒子在可解空间运动,通过比较个体极值和群体极值的适应度值与新粒子的适应度值来更新个体极值和群体极值的位置。
在 D 维空间中,有 n 个粒子的种群 X=(X1,X2,…,Xn),第i 个粒子表示为一个D 维的向量空间 X=[Xi1,Xi2,…,XiD]T,根据目标函数可以计算得到每个粒子位置Xi对应的适应度值。 第i 个粒子的速度为 Vi=[Vi1,Vi2,…,ViD]T,个体极值为 Pi=[Pi1,Pi2,…,PiD]T,其种群的全局极值为 Pg=[Pg1,Pg2,…,PgD]T。 粒子群的更新公式为:
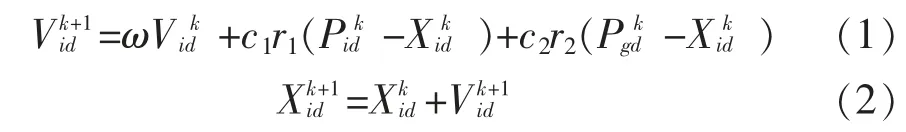
其中,ω 是惯性权重;k 为迭代次数;Vid为粒子速度;c1和 c2是加速度因子;r1和 r2是在[0,1]之间的随机数。 需要将位置和速度定义在[-Xmax,Xmax][-Vmax,Vmax]之间,防止粒子的盲目搜索。
1.2 SVM 模型
对给定的样本数据进行分类,为使分类的精准度更高,需要通过某种衡量方式确定一条最好的决策边界,称为最大边界[11]。决策边界见图1。

图1 决策边界示意
以寻找最大边界为目的的衡量方式叫作最大间隔分类器,其目标函数可以定义为同时满足一些条件,根据间隔的定义为:

其中,ω 是分类超平面的法线;b 是分类超平面的点到超平面的距离。 它导出的是约束条件,几何间隔的定义如下:
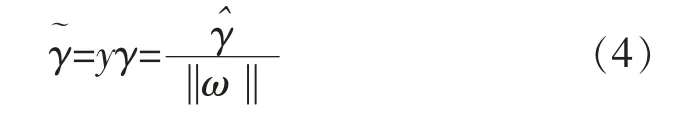
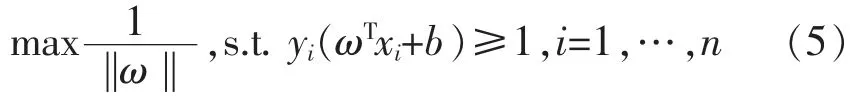
在约束条件 yi(ωTxi+b)≥1,i=1,…,n,最大化1/‖ω‖的值,1/‖ω‖就是几何间隔。 求 1/2‖ω‖2的最小值,其目标函数等价如下:

通过给每个约束条件加上一个拉格朗日乘子α 来定义拉格朗日函数为:

将拉格朗日函数 L(ω,b,α)分别对 ω 和 b 求偏导[10],并将偏导得到的式子代入原式可得:

1.3 PSO-SVM 模型
PSO-SVM 模型结构[12]包括:①初始化粒子群,设定终止条件和权重因子;②采用适应度函数计算粒子的适应度值,选取最优适应度值粒子的个体极值作为最初的全局极值;③依据迭代公式更新粒子的速度和位置; ④计算迭代后粒子的适应度值,若优于个体极值则更新个体极值;⑤比较更新后的个体极值和全局极值,若个体极值更优则更新全局极值;⑥输出最优解,得到最佳的参数组合来构建最优模型。
1) PSO-SVM 模型参数的初始化包括粒子种群规模、初始速度、学习因子和权重因子,一般设置种群规模为20~40。
2) 粒子寻优过程中,粒子适应度函数是粒子个体优劣的度量依据,模型通过适应度函数来评定SVM 模型的泛化能力和准确率。
3) 计算粒子个体的适应度值fi、种群个体最优解 fi(Pbest)和全局最优解 fi(gbest)。 若粒子个体适应度值小于种群个体最优解,则更新全局极值fi(gbest);若种群个体最优解小于全局最优解,则更新全局最优解 fi(gbest)。
4) 满足终止条件后,将全局最优粒子对应的σ 和C 作为最优参数用于PSO-SVM 模型的建立。
2 改进算法研究
2.1 顾及邻近点因素模型的样本输入
大坝形变不仅仅受时效等因素影响,实际监测项目中,每个监测点变形都不是独立存在的,受其他监测点的影响,同时也影响着其他监测点。 因此,本文为研究邻近点对模型的影响,选取某大坝的变形监测数据,通过相关性分析的方法,选取大坝位移形变的一组相邻的3 个监测点的监测数据,作为模型的输入数据,数据量为从2016 年4 月12 日至9 月25 日的 150 期数据。 3 个地表位移监测点 DBW1、DBW2、DBW3相关性系数见表 1。

表1 三邻近地表位移监测点相关性
由表1 可得,3 个监测点位移形变的相关系数大于0.9,DBW1和邻近点之间存在强相关性,因此本文将监测点之间的互扰性作为影响元素引入预测模型中,研究该因素对IPSO-SVM 模型的影响情况。其数据样本如表2(选取前5 期作为数据展示)所示。

表2 顾及邻近点的样本输入项
选取一组邻近监测点数据和时间序列作为训练样本的输入项,建立邻近点这一因素驱动下的IPSO-SVM 模型,来预测监测点DBW1的变形情况。 其中表2 列出了训练样本输入项 (时间序列X1,以及邻近点因素 X2,X3,X4)。
2.2 改进的PSO-SVM 模型
改进的PSO-SVM 模型引入标准的柯西分布密度函数优化模型的惯性权重,采用多尺度一维的小波分解函数对样本数据进行误差序列的剔除,选取3-fold 交叉验证方法进行最佳参数的求解。 改进预测模型结构设计包括:①引入标准柯西分布公式对惯性权重的取值进行改进; ②小波分析剔除样本数据的噪声序列;③确定适应度函数;④初始化种群和速度; ⑤计算适应度函数及适应度标定;⑥速度更新和个体更新;⑦输出最优解。流程如图2 所示。

图2 IPSO-SVM 模型的结构流程
1) 惯性权重 w 是平衡 PSO-SVM 模型全局和局部搜索能力的一个重要参数,针对PSO-SVM 模型惯性权重w 为定值这一缺陷,引入标准的柯西分布密度函数对惯性权重w 进行改进。IPSO-SVM 模型其初始权值随粒子位置的初始值x 变化而变化,柯西分布密度函数可以在算法初期可以增大w的值,提高PSO-SVM 模型欠缺的全局搜索能力;在算法后期会适当减小w 的值,解决PSO-SVM模型局部搜索能力欠缺的问题。 其惯性权重w 公式为:

2) 针对大坝变形的样本数据随机性和非平稳性的特点[13],本文采用多尺度一维的小波分解函数进行数据的去噪,该方法是对原始数据地近似最优估计,适应性广泛[14]。 小波分解函数的阈值选取为[C,L]=wavedec(y,3,′sym4′),其中 C 为分解结构变量;L 为样本数据长度变量;y 为样本数据,分解层数是3 次,小波类型为sym4。 经过3 次分解后,得到平滑数据细节分量,尺度为1 时细节分量没有明显的周期性,尺度为2 时细节分量周期的幅度很小,尺度为3 时细节分量周期满足精度要求。 此时小波多尺度傅里叶时频分析法3 次分解平滑信号,其数据如图3 所示。
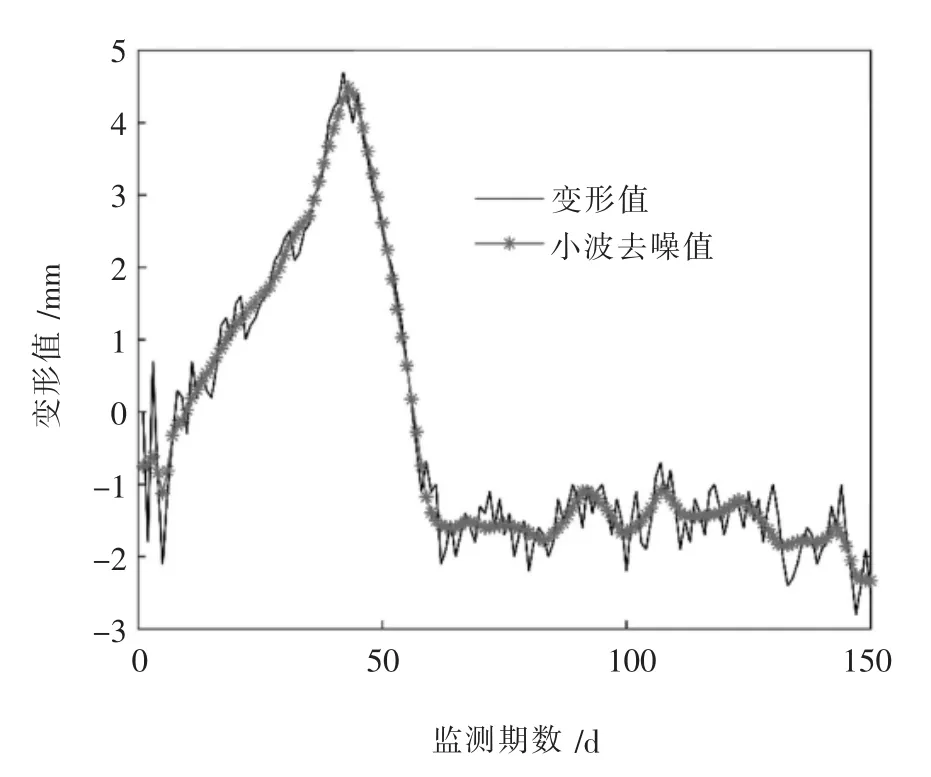
图3 小波分析后大坝变形数据
PSO 优化算法可以得到更优的参数估计,小波分解函数可以对样本局部特征进行分析,保留有用的边缘信息,并将原始数据分解为平滑信号和误差序列。其中小波分解后的拟合曲线的误差平方和为26.25 mm2。
3) 随机初始化粒子位置和粒子速度后,模型需要评估迭代产生的连续解后进行下一步的迭代,并根据适应度函数计算粒子适应度值。由于初始粒子是随机的,所以粒子群运动的过程是客观性的;并且粒子群每次更新的位置和速度都需要进行评估,符合条件后方可进行下一步迭代,因此能保证粒子群在空间运动的合理性。 其中包括设置PSO算法的运行参数,包括迭代次数和种群规模,以及个体和速度的最大最小值。
采用交叉验证的思路[15]可以使SVM 模型在能避免欠学习的情况下得到最优参数。K-CV(K-fold Cross Validation, K-CV)方法可以有效避免欠学习和过学习的状态,所得结果可靠性强。因此,本文采用3-CV 交叉验证方法进行最佳参数的选取,将样本数据集平均分为3 组,选取其中的2 组样本数据作为训练集,剩余数据作为验证数据规定c 和g 的定义域,利用3-CV 方法选取该训练集下的最高分类准确率。 若存在多组最高分类准确率的情况,则取c 值最小的那组c 和g 作为最佳的参数;如果对应着多组c 值最小的c 值和g 值,选取搜到的第一组数值作为参数。
4) 迭代寻优,首先进行粒子位置和速度的更新,然后根据新粒子的适应度值进行个体极值和群体极值的更新。其中粒子群优化算法的最大迭代次数为100,一般情况下,为保证粒子群充分搜索解空间需要设置种群规模为20~40。 由于大坝变形模型是一个复杂而特定类别的问题,本文粒子群优化模型的种群规模选定为100。
5) 最优解计算,yi(ωTxi+b)≥1,i=1,…,n,为约束条件,目标函数为:

利用拉格朗日乘子法[14]对ω 和b 求偏导,求解最优解,求解公式如下:
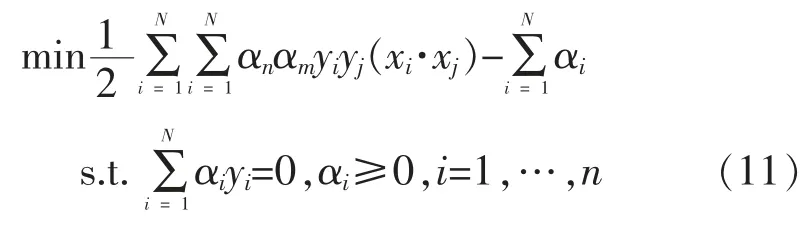

图4 不同样本数据量下各模型的预测精度对比
3 实例分析
3.1 顾及邻近点因素的改进PSO-SVM 模型研究
通过2.1 小节的相关性分析情况可得,3 个监测点相关性系数大于0.9,说明地表位移的3 个监测点变形发展都不是独立的。 因此,构建顾及邻近点变形因素的IPSO-SVM 预测模型,设计了20 期数据的短期预测、50 期数据的中短期预测及150 期数据的长期预测实验。模型精度评定采用均方根误差(RMSE),并且,加入大坝变形预测常用的BP 神经网络模型与3 种不同的PSO-SVM 模型进行对比,研究样本数据量和顾及邻近点对BP 模型和改进PSO-SVM 模型预测效果的影响,预测精度效果对比如图4 所示。
如图4 所示,在20 期短期样本数据下,引入邻近点变形因素的各模型都得到优化,且预测精度有所提高,其中PSO-SVM 模型和IPSO-SVM 模型预测精度提高最为明显;在中短期样本数据下,PSOSVM 模型和IPSO-SVM 模型预测精度都优于BP模型。而引入邻近点这一因素的各模型在中长期样本下,预测效果均不佳,其中,顾及邻近点的PSOSVM 模型和IPSO-SVM 模型预测效果较差。 各模型均方根误差对比见表3。

表3 3 种样本数据量下各模型的均方根误差对比
由表3 可知,BP 神经网络模型预测精度低于PSO-SVM 等模型的预测精度,引入邻近点因素的BP 模型在中短期样本情况下预测精度有所提高。3种不同数据量的情况下,IPSO-SVM 模型较PSOSVM 模型都有预测精度上的提高,在中长期的预测精度提高最为明显。 在短期数据量的情况下,顾及邻近点的模型较PSO-SVM 模型和IPSO-SVM模型都有预测精度的提高,其中,顾及邻近点的IPSO-SVM 模型预测效果最好。 在中长期数据量的情况下,顾及邻近点的模型预测效果不佳,尤其在长期数据量的情况下,预测效果不适用于变形监测领域。 由表3 和图4 的精度分析可得,顾及邻近监测点变形因素的IPSO-SVM 模型,适用于变形监测的短期预测,不适用于中长期数据预测;而IPSOSVM 模型,适用于中长期数据量的变形监测,改进模型预测精度较优。
本文为再次验证模型的适应性,将短期、中期和长期样本数据的期数调整为30、60、120 期,进行验证性研究实验。模型的均方根误差对比见表4。
由表4 数据可知,改变样本数据预测效果与表3所得结论一致,引入邻近点因素的3 种模型较原模型在短期样本数据下预测精度最优,而在中长期样本数据下预测效果不佳。为验证IPSO-SVM 算法在长期样本下模型的适应性,本文设计了150 期样本下IPSO-SVM 模型的对比实验。
3.2 改进的PSO-SVM 模型研究
选取大坝变形监测点DBW1的150 期样本数据,建立 SVM 模型、PSO-SVM 和 IPSO-SVM 模型,分析IPSO-SVM 模型的优化性能。 选取前90%的样本数据作为训练数据,剩余10%的样本数据作为检验数据。 结果见表5。

表4 改变样本数据量下各模型的均方根误差对比

表5 3 种模型预测结果对比 单位:mm
由表5 可知,IPSO-SVM 模型预测精度最优,预测结果的残差保持在 0.09 mm 以内。 SVM 模型残差最大值为1.3953 mm,部分预测值偏差较大;PSO-SVM 模型残差最大值为1.1874 mm,较SVM模型预测精度一定幅度的提高,PSO 算法能够对SVM 的参数进行自动寻优,从而达到提高预测精度的效果;IPSO-SVM 残差最大值为-0.0857 mm,较SVM 模型和PSO-SVM 模型预测精度有较大幅度的提高。IPSO-SVM 采用标准的柯西分布密度函数优化了模型的惯性权重,通过小波分析减小了样本数据的噪声,并且对SVM 模型参数进行寻优求解,从而达到大幅度提高预测精度的效果。 预测结果对比如图5 所示。

图5 3 种模型预测结果对比
由图 5 可以看出,IPSO-SVM 模型和 PSOSVM 模型预测结果精度远优于SVM 模型预测精度,2 个模型的预测结果也更加接近真实值的趋势。 IPSO-SVM 模型预测结果精度较PSO-SVM 模型也有着一定程度的提高,其预测趋势与真实变形值的变化趋势保持一致。此时IPSO-SVM 模型的最佳惩罚参数c=2.1325,核函数σ=0.01,最佳核函数参数g=3.2504。 3 种模型的预测结果:SVM 模型的均方根误差为0.617 mm,PSO-SVM 模型的均方根误差为0.513 mm,IPSO-SVM 模型的均方根误差为0.061 mm。 其中,本文提出IPSO-SVM 模型预测性能最优,预测值趋势和真实值变化吻合的最好,预测结果精度远优于SVM 模型和PSO-SVM 模型。精度评定对比见表6。

表6 3 种模型精度评定对比
为综合评定 3 种模型的预测性能,选取RMSE 和 MAE 两个指标进行模型的评定。 基于IPSO-SVM 模型在 RMSE 和 MAE 两项精度评定指标上远优于 SVM 模型和 PSO-SVM 模型,RMSE 精度从 0.617 mm 提高到 0.061 mm,MAE精度从0.503 mm 提高到 0.059 mm。 与 PSO-SVM模型相比,RMSE 和 MAE 两项指标分别提高了88%和 85%。 由表 5 和表 6 可知,IPSO-SVM 模型中,小波分析能够剔除样本数据的噪声,柯西分布密度函数能够优化PSO-SVM 模型的惯性权重,改进模型具有较高的预测精度和可信度,证明了IPSO-SVM 模型在大坝变形预测的有效性。
4 结 论
本文采用多尺度一维小波分解函数对样本数据进行去噪处理,引入标准的柯西分布密度函数优化惯性权重,从而建立了IPSO-SVM 预测模型,分别进行了顾及邻近监测点的模型分析,以及长期监测数据情况下的改进模型分析。实例分析表明:
1) 短期数据量的情况下,顾及邻近点的模型较标准的BP 模型、PSO-SVM 模型和 IPSO-SVM模型预测精度有显著的提高;在中长期数据量的情况下,顾及邻近点的模型预测效果较差,预测效果不能满足变形监测的精度要求。而IPSO-SVM 模型拟合和预测精度最优,更加适用于中长期数据量的变形监测。
2) 在进行了顾及邻近监测点的模型研究后,设计了150 期监测数据情况下的改进模型分析。 采用非线性小波变换阈值法进行样本数据的去噪,采用3-CV 交叉验证方法进行最佳参数的选取,引入标准的柯西分布密度函数优化PSO-SVM 模型的惯性权重,建立IPSO-SVM 模型。 改进模型克服了预测精度低及容易陷入局部最优解的缺点,大幅度地提升了传统SVM 模型的预测精度,与 PSO-SVM 模型预测精度相比 RMSE 和 MAE分别提高了88%和85%,改进预测结果的RMSE为 0.061 mm,MAE 为 0.059 mm。通过 3 种模型对比分析结果表明,本文的改进模型预测精度最高,为大坝变形研究提供新的思路,具有一定的参考价值。
