基于3D 深度卷积神经网络依据MRI 生成伪CT 的研究
2020-07-16营影超付东山王伟
营影超,付东山,王伟
(天津医科大学肿瘤医院放疗科,国家肿瘤临床医学研究中心,天津市“肿瘤防治”重点实验室,天津市恶性肿瘤临床医学研究中心,天津300060)
计算机断层扫描(computed tomography, CT)成像作为放射治疗的主要基准图像,可以准确的显示患者的轮廓信息,但是CT 的低软组织对比度、电离辐射使其在临床上的应用受到一定限制。随着磁共振成像(magnetic resonance imaging,MRI)在放疗领域起着越来越重要的作用,将MRI 单独用于放射治疗逐渐成为研究重点[1]。MRI 较CT 具有无电离辐射、软组织对比度高等优势,并能提供区分不同组织或器官的多种序列图像。由于MRI 与电子密度(electron density,ED)无关,因此不能直接用于剂量计算和基于X 线的患者摆位验证[2]。
为了解决该问题,研究人员提出了多种预测方法。容积密度分配的方法通过手动或半自动分割技术分割各组织,对其分配不同的ED 获得合成CT(synthetic CT, sCT)或伪CT(pseudo CT, pCT)[3-4]。该方法简单粗糙,工作量较大,且预测精度不佳。基于图谱的方法对匹配的MRI 和CT 图谱库采用可变形配准方法生成pCT,但是对于特殊解剖结构的患者(如组织缺失或外科植入物),该方法会受到限制[5-8]。基于体素和基于图谱混合的方法,将体素强度和可变形配准过程的几何信息共同用于pCT的生成。虽然额外的强度信息有效的减小了配准误差,但是配准过程中依然需要注意解剖结构的影响[9]。随着计算机技术的不断提高,深度学习得到快速发展。Han 等[10]提出了采用深度卷积神经网络(deep convolutional neural network, DCNN)基于MRI 重建pCT 的方法,较前述方法均有较大改进。但是由于缺乏图像的上下层信息,在骨骼和空气的转换上仍有较大误差,需进一步改善。
本文采用3D DCNN 模型,在2D 模型的基础上结合上下层图像的信息,通过编码和解码两部分训练模型。编码部分主要通过卷积和池化处理获取图像特征,解码部分的上采样和卷积处理主要将图像从粗分辨率恢复为细分辨率,并恢复图像的大小,从而获取重建图像。通过13 个病例的分析,比较2D DCNN、3D DCNN 两种算法的平均绝对误差(mean absolute error,MAE)、均方根误差(root mean squared error,RMSE)和结构相似度(structural similarity index,SSIM)。
1 资料与方法
1.1 数据的获取和预处理 本文所采用的数据来源于华山医院射波刀治疗中心,共采集20例患者头部的CT 和MRI,其中MRI 的体素大小有0.625×0.625×3 mm3、0.4688×0.4688×3 mm3等,扫描范围有512×512×38、512×512×48、512×512×50 等。CT 的体素大小有0.468×0.468×3 mm3、0.488×0.488×1 mm3、0.549×0.549×1 mm3等,CT 的扫描范围有512×512×220、512×512×240、512×512×217 等,通过筛选,去除层数过少的患者,其中13 个患者的图像可用,由于模型输入需保证为2n,所以将所用数据进行切片统一处理,选用MRI 数据中的32 个切片,即512×512×32。
每个患者的CT 与MRI 需经过偏置场校准[11]和刚性配准处理,确保两者在同一解剖位置。为了获取更好的pCT,还需进行掩模处理,将MR 图像的头部区域从背景区域中分离,采用大津阈值法[12]获取初步提取区域,随后采用形态学闭运算填充各个部位的间隙,获得最大连通区域,图1 a、b 为原始MRI和掩模图像。
在放射治疗过程中,患者通常使用头架进行位置固定,但是在进行CT 扫描时,头架会在CT 图像中显示出来,为了避免其对模型造成影响,笔者根据MRI 提取的掩模区域,去除CT 中的头架,图1 c、d为原始CT 图像和去除头架后的原始CT 图像。
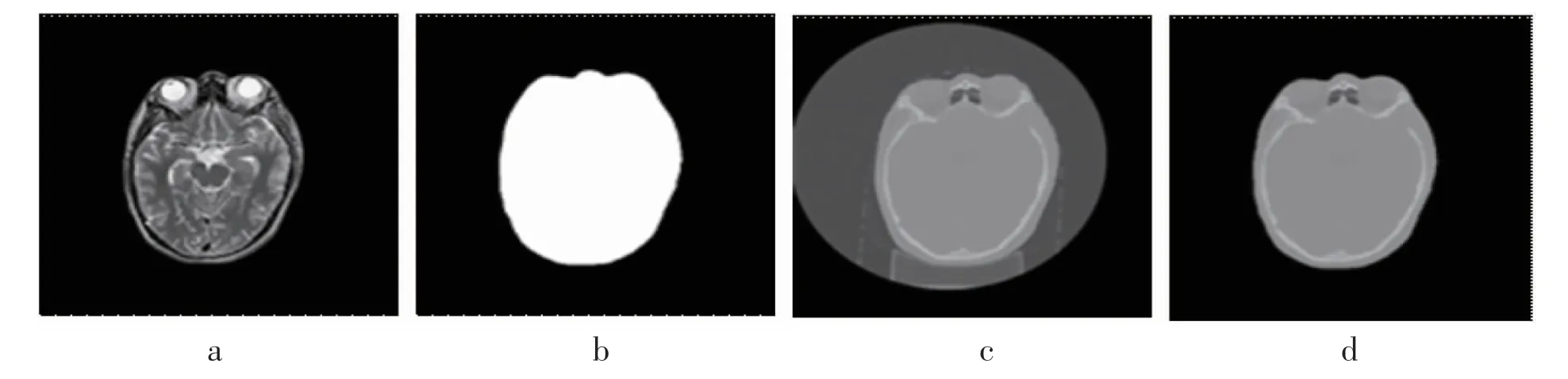
图1 图像数据预处理Fig 1 Image data pre-processing
由于图像过大,网络模型需要训练的参数过多,电脑显存受到限制,所以又对数据做了进一步处理。首先将图像进行裁剪,提取最小感兴趣区域,再将其进行归一化处理,然后把图像大小改为256×256×32。
1.2 3 D 深度卷积神经网络算法(DCNN) 3D DCNN算法流程图如图2 所示。
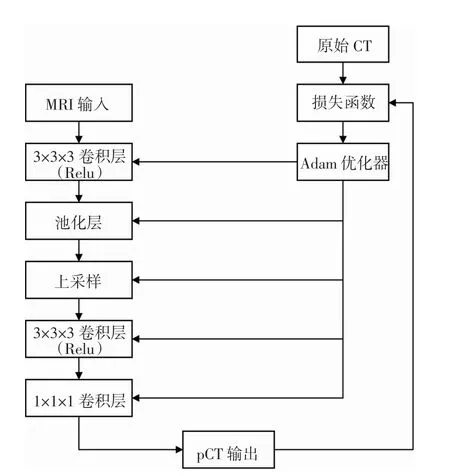
图2 DCNN 算法流程图Fig 2 Flowchart of DCNN algorithm
DCNN 模型主要由卷积层、池化层组成。卷积层主要由多个特征面组成,每个特征面通过3×3×3 卷积核与上一层的局部区域相连,通过卷积操作进行特征提取,随着网络深度的增加,所提取的特征从简单向复杂方向转变。随后将卷积所得结果传递给不饱和非线性Relu 函数:

其中x 为输入,f(x)为输出。对于Relu 而言,若输入大于0,则输出与输入相等,否则输出为0,可以过滤掉极其不明显的特征,不仅改善了模型的泛化能力,而且进一步克服梯度消失问题,也加快了收敛速度[13]。卷积层之后为池化层,它同样由多个特征面组成,每个特征面唯一对应卷积层的一个特征面,从而该层的特征面个数不会发生改变。池化层可以被认为有二次提取特征的作用,通过降低特征面的分辨率来获得具有空间不变性的特征[13],上采样层的作用主要是通过插值方法逐步恢复图像的细节和大小,进一步通过卷积处理获得最终预测结果,采用MAE 作为损失函数:
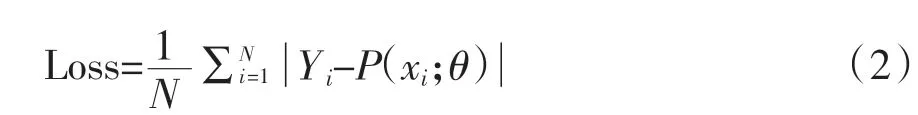
其中Yi为真实CT 图像,P 为预测图像,xi为对应的MRI 图像,θ 为网络学习参数对所得误差应用Adam 随机优化函数进行反向传播,进一步对参数优化处理[14]。
1.3 DCNN 模型 本文采用19 层卷积层、池化层和上采样层交织的端到端的神经网络架构,如图3所示,浅绿色块表示MRI 输入,红色块表示最大池化层,蓝色块表示卷积层,白色块表示下采样层中的卷积层,黄色块表示上采样层,紫色块表示pCT输出,特征图的数量在方块上面标注。编码器由多个3×3×3 卷积核进行特征提取,采用局部连接和权值共享加深网络有效的降低网络复杂度,减少训练参数的数目。随后通过最大池化层对特征进行二次提取,并将特征图的大小减小1 倍,起到减少计算量和内存消耗的作用。解码器通过上采样层逐步恢复图像的细节和大小,联合处理将编码器的特征图与解码器的特征图结合,使网络更容易重建图像的细节。
网络还应用批标准化(batch normalization,BN)对每个卷积层的输出进行标准化处理,保证网络的输入输出具有相同的统计分布,减少网络中内部协变量偏移,避免深层网络梯度消失或梯度爆炸,同时加快了模型的收敛速度,减少了参数初始化的要求[15]。在实验中初始学习率设为0.001,最大迭代次数设为6000 次。本研究是基于Keras 框架进行网络搭建,实现模型的训练与评估,使用NVIDIA Quadro P5000 进行GPU 加速。
2 结果
本文采用留一交叉验证(leave-one-out cross validation,LOOCV)的方法训练模型。选择13 份样本中的12 份作为训练集,训练模型,剩下1 份样本作为测试集,测试模型的准确性。此过程的模型训练和验证重复13 次。在本次实验中,3D DCNN 模型训练时间大约为9 h,预测时间大约为2 s,2D DCNN 模型训练时间约为5 h,预测时间大约为18 s。3D DCNN 模型训练时间较长,但预测时间短。
2.1 pCT 与原始CT 的定性比较 对2D DCNN、3D DCNN 两种方法预测pCT 与原始CT 进行定性比较。首先,取其中1 次实验结果作为例子,比较pCT与原始CT 的图像质量,如图4、图5、图6 所示,第1列为原始CT,第2 列为pCTs,其中第1 行为3D DCNN的结果,第2 行为2D DCNN 的结果;第3 列为pCT和原始CT 的差异图,其中第1 行为3D DCNN 的结果,第2 行为2D DCNN 的结果。
2.2 pCT 与原始CT 的定量比较 采用MAE、RMSE 和SSIM 对2D DCNN 和3D DCNN 结果进行定量比较,验证pCT 的准确性,进一步评价pCT 和原始CT 的一致性。MAE、RMSE 和SSIM 的数学表达式为:
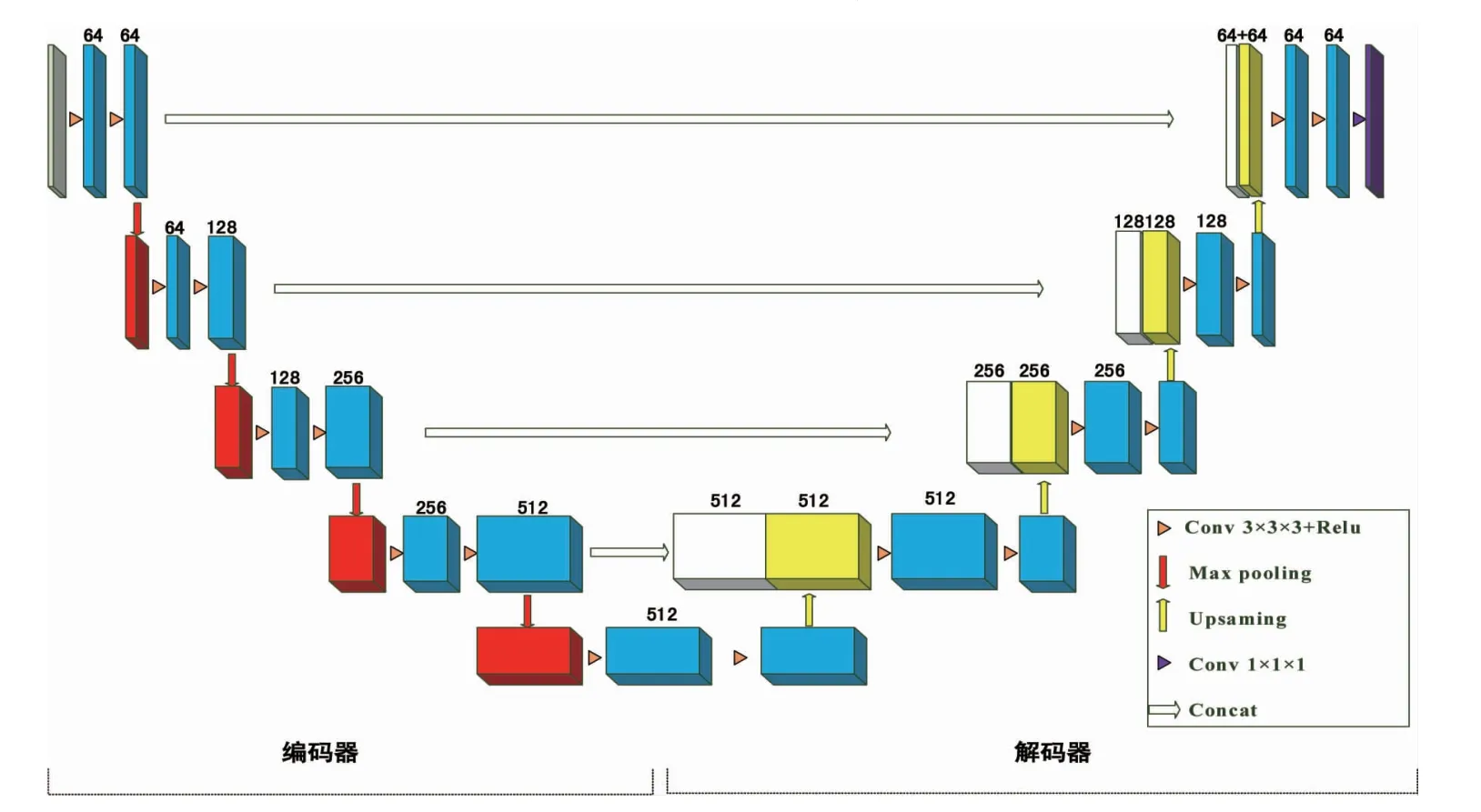
图3 3D DCNN 框架Fig 3 Architecture of 3D DCNN model
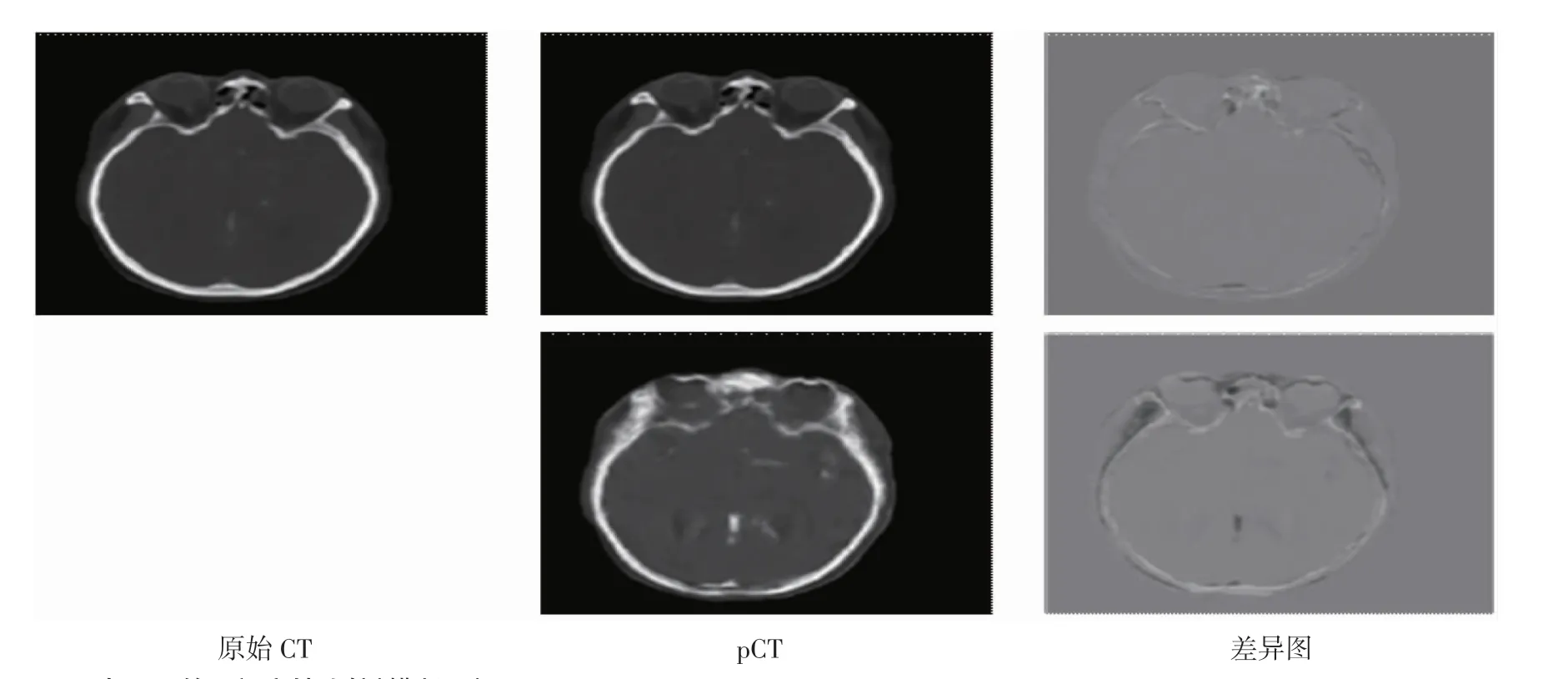
图4 pCT 与CT 的目视定性比较(横断面)Fig 4 Visual qualitative comparison of pCT and CT(cross section)
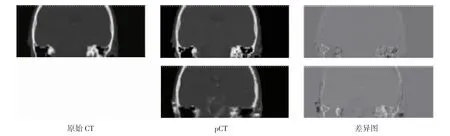
图5 pCT 与CT 的目视定性比较(冠状面)Fig 5 Visual qualitative comparison of pCT and CT(coronal plane)
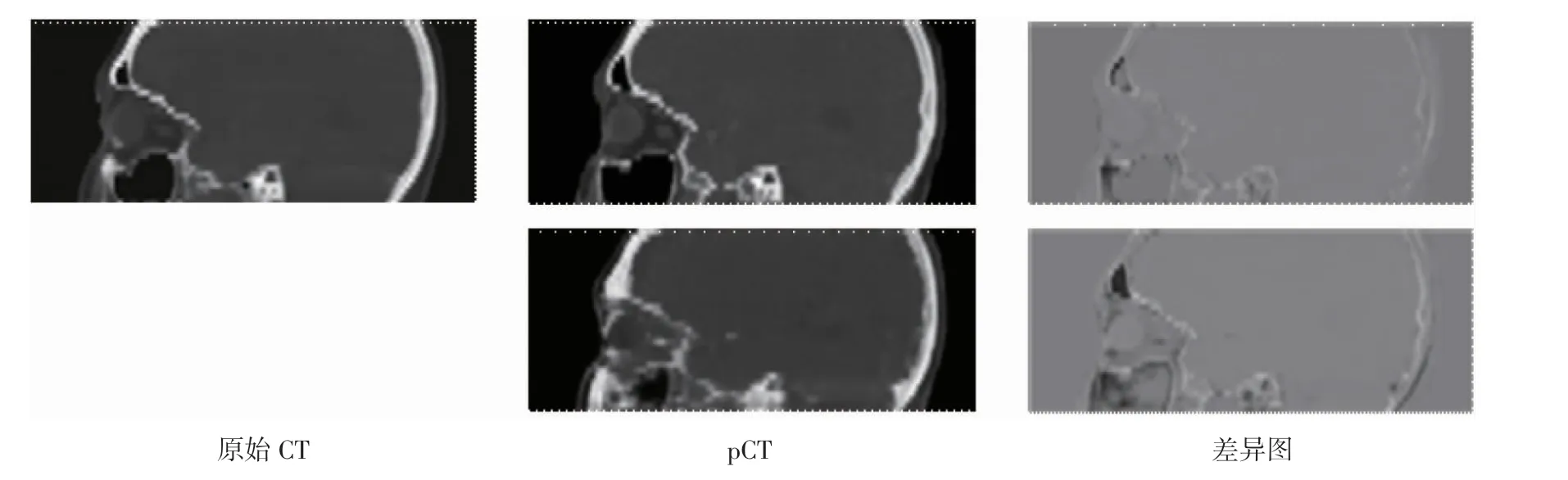
图6 pCT 与CT 的目视定性比较(矢状面)Fig 6 Visual qualitative comparison of pCT and CT(sagittal plane)
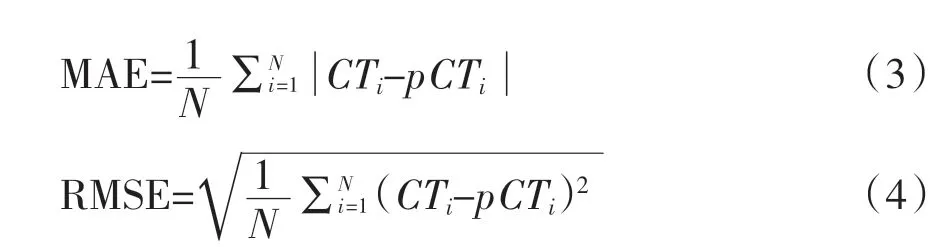
其中N 为像素的个数,CTi和pCTi分别是原始CT 与pCT 的像素值。
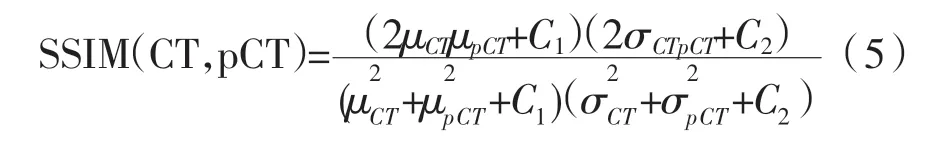
其中μCT为CT 的平均值,μpCT为pCT 的平均值,为CT 的的方差为pCT 的方差,σCTpCT为CT和pCT 的协方差。C1=(k1L)2,C2=(k2L)2为常数,L 为像素值的动态范围,k1为0.01,k2为0.03。
表1 列出了13例患者两种算法的MAE、RMSE和SSIM。其中3D DCNN 预测结果的MAE 都小于2D DCNN 预测结果的MAE;3D DCNN 的RMSE 都小于2D DCNN 的RMSE;除此之外,3D DCNN 的SSIM 都大于2D DCNN 的SSIM,表明3D DCNN 算法得到的pCT 的准确性更高。
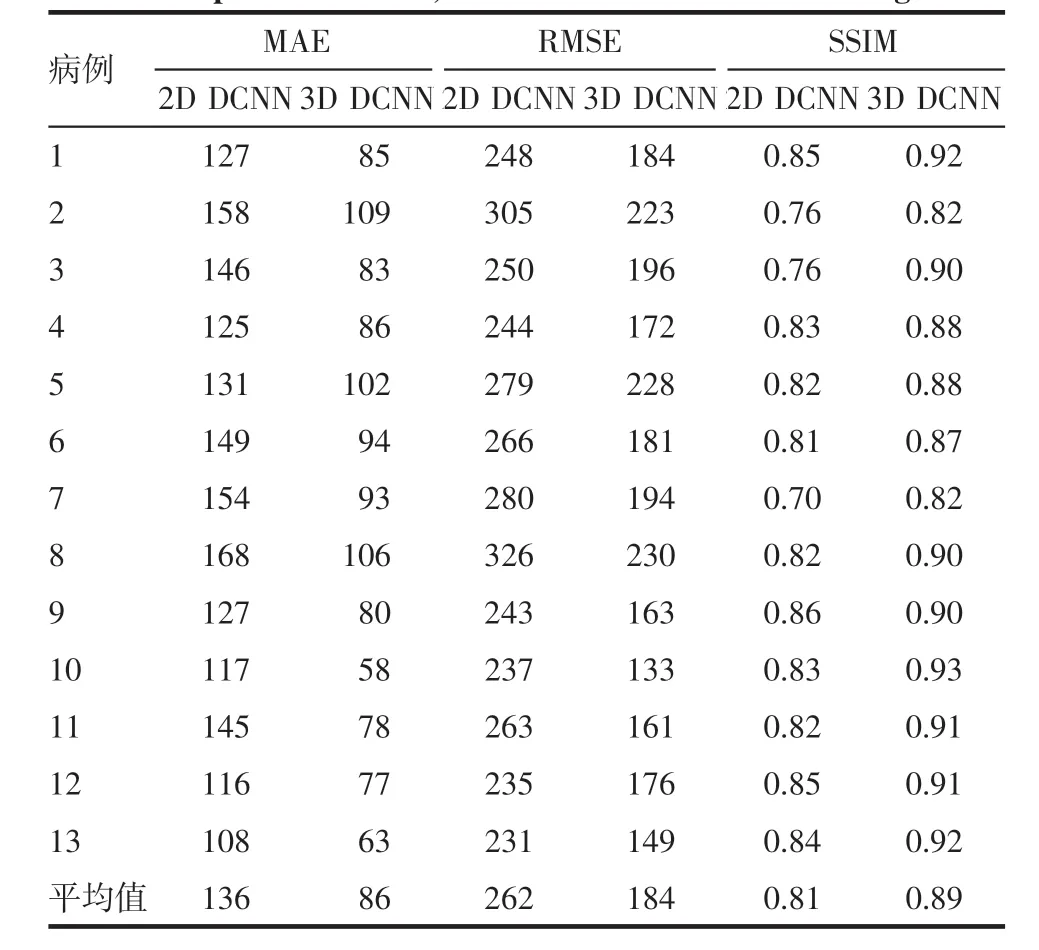
表1 两种算法的MAE、RMSE 和SSIM 比较Tab 1 Comparison of MAE,RMSE and SSIM between two algorithms
3 讨论
本文提出的基于3D DCNN 的算法结合图像层与层之间的信息,既分析了单张图像的空间特征,还结合了该层图像的上下层图像的特征,相比于2D DCNN 可以获得更准确、更全面的图像信息,从而得到精确的结果。基于13例患者的CT 和MRI数据,将2D DCNN、3D DCNN 两种方法的预测结果进行对照比较,本文提出的3D DCNN 算法的平均MAE 为86 HU,小于2D DCNN 的136 HU,3D DCNN的平均RMSE 为184HU,也小于2DDCNN 的262HU,除此之外,3D DCNN 算法的平均SSIM 为0.89,高于2D DCNN 算法的0.81。因此3D DCNN 算法的精度要高于2D DCNN 算法,所获得预测图像更接近于真实图像。
容积密度分配的方法使用手动或半自动分割技术,人工工作量大[3-4]。而基于图谱法对配准精度要求较高,而且有时会因为配准困难造成sCT 颅骨和硬脑膜区域出现较大误差[10,16]。虽然基于体素和基于图谱的混合方法提高了pCT 的预测精度,但是复杂度明显提高。对于2D DCNN 算法,依次对一张张图像进行处理,虽然其运行速度相比于3D DCNN快,但是在骨骼、软组织和空气的误转换仍有较大误差,而3D DCNN 将图像上下层结合,共同用于训练,利用了图像层与层之间特征的相关性,不仅提高了预测精度,而且明显解决了误转换问题。
通过有限的临床数据验证,表明3D DCNN 算法的精确性和鲁棒性优于2D DCNN 算法,结果显示生成的pCT 图像质量满足MRI 单独用于放射治疗的要求。本研究下一步工作将该算法结合临床实践,用于剂量分布计算和基于X 线图像引导的患者摆位验证,进一步验证该方法的临床应用可行性,还可以将该pCT 生成方法从头部延伸至其他解剖部位。
