深度学习算法在金融消费者行为研究中的应用
2020-07-14郑浦阳
郑浦阳
(华东交通大学,江西 南昌 330013)
0 引言
最近几年,以第三方支付、网络借贷为代表的互联网金融服务在国内迅猛崛起,极大促进了我国金融消费市场的发展。金融消费市场的扩展推动了金融领域的发展繁荣,同时也为金融机构带来新的挑战。这种挑战来自两个方面:一方面是客户层面,当前金融产品在互联网金融的背景下,融资渠道更为便利,从而导致信用风险高,用户恶意违规手段不断更新,这对金融公司造成了潜在隐患。同时,当前的信贷审批流程相对落后,对个人信用风险的识别和控制能力一般,这也影响到金融公司产品销售的效率。以往对于金融消费者资质分析往往集中于消费者的收入情况、信贷历史等因素,很少通过消费行为来反馈金融消费者的金融素养,从而对金融消费者进行系统评价,本文从金融消费者的消费行为入手,通过大数据的获取和机器学习方法的应用,试图建立金融消费者“信用风险”与“消费行为”之间的映射关系,从而为进一步对金融消费者的金融素养评定提供依据。
1 描述性统计分析
1.1 数据来源和结构
本文的数据来源为深圳某金融服务平台,获取的数据部分字段经历“脱敏处理”,以保护用户隐私。数据包括用户的“消费情况”和“信用风险”两个层面,其中“信用风险”相关特征包括用户的还款行为等信誉表现状况。
该平台提供了2017年1月—2019年1月的信贷数据,包括训练样品12万条,测试样品1万条。数据共包含3部分:第一部分数据集(Master文件)是用户消费行为数据集,每个样本包含159个特征字段和1个是否违约的目标字段,主要为用户消费的具体类型,其中1个是否违约的目标字段,只要有违约记录则计为1,没有违约记录计为0。部分字段的名称和数量见表1所列;第二部分数据集(Consume time文件)是用户消费时间的数据集,包括4个字段,见表2所列;第三部分数据集(Habit_info文件)是表征用户消费习惯的数据集,包括3个字段。
由这3个数据文件可知特征变量共167个,预测是否违约的目标变量1个,为典型的二分类问题。特征变量在逻辑上与借款人的消费行为习惯有关,且数据量具有一定规模,满足了机器学习的一般需要。
1.2 描述性数据统计分析
1.2.1 消费类别统计(见表1)
收集到的消费项目,将159个字段分为9个类别,统计不同类别消费类型的具体消费比重。值得注意的是,单纯的统计消费额度是没有意义的,因为不同消费者的消费行为有较大差异,与自身经济能力有关。为了更好地表征消费行为这一特征,本文对每一个消费类别采用“该类别月消费数额/月消费总额”作为衡量特征。
本文获得的2个较为极端的案例,即月消费额超过10 000,和不足2 000的2个案例,二者之间的消费能力差异较大,但消费比重近似,这反映了二者在消费观念上相似性。值得注意的是,高消费者在娱乐类消费的比重较高,这与消费习惯有关,也与娱乐项目和基础生活花销在价值上的差异有关。本文从消费行为上重点提取的是表征“非理性消费”的特征,因此,消费能力偏低,娱乐类消费或者美妆类消费较高的特征更偏重于这一点。这与通常意义上认为的“消费不理性”的印象一致。
1.2.2 消费时间统计(见表2)
对消费时间的评估,更多的是反馈消费习惯的一方面特征。通常来说,集中在节假日、周末消费的群体往往有稳定的工作情况,这对他们履行金融义务,按期还款提供了便利。长假集中消费的群体往往有假日出行旅游的习惯,这一群体往往有较好的经济背景,通常情况下逾期还款的可能性不高。相反,发生在特殊时段(深夜),特殊日期(工作日)的大额消费往往可能是紧急情况下的“特殊消费”,或者是“失业群体”的零散消费,无论是紧急情况下的“特殊消费”,或者是“失业群体”的零散消费,当消费占据很大比重时,都有理由怀疑他们的经济能力是否可以支持按期还款,因此这一方面的特征在逻辑上与金融信用有关,可作为深度学习的输入层。
1.2.3 消费习惯统计(见表3)
用户的消费习惯是一个处理后的特征,用以更好地建立目标映射。其中,冲动消费指数:
Im_con=con_con/month
其中,Im_con为冲动消费指数;con_con指代连续消费次数,month为每月。其中con_con连续消费的定义为,在1 d时间内,同时进行5个类别(如表1)消费行为。一般来说,短时间内进行大量跨类别的消费,往往表征这个人在一定的消费环境和消费刺激下“冲动消费”行为,实际上这是一个表征“消费理性的特征”,不难认为,冲动消费的人更倾向于逾期还款,或者有较差的金融素养和金融行为。
消费集中指数的计算为:
Fo_con=Lar_amon/month
其中,Fo_con为消费集中指数;Lar_amon/month为1个月内大额消费的次数,其中大额消费定义为:消费额度超过该用户月平均消费总额度20%的消费行为(月平均消费为1年内的月平均水平)。
消费分布指数,指消费行为发生集中度,即用户在该月消费,集中在任何2个类别的消费超过本月消费总额度的60%,被认定为集中消费1次。
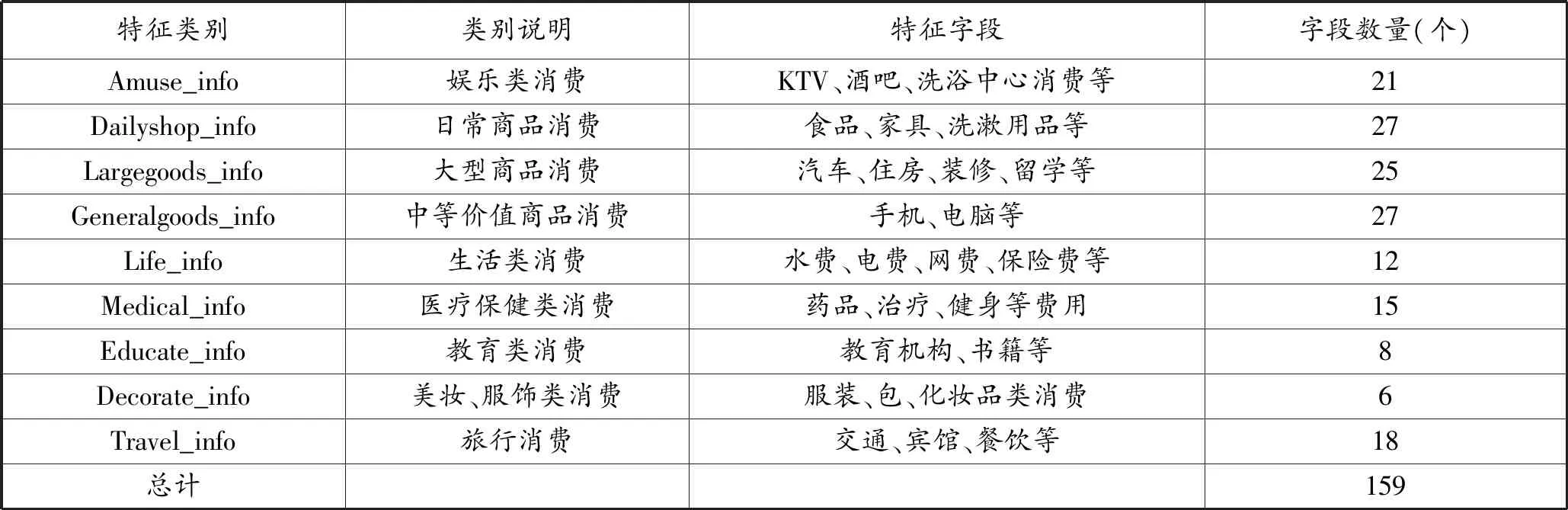
表1 消费类别统计

表2 消费时间统计

表3 消费习惯统计
2 基于机器学习的消费行为评估模型
通过描述性统计分析,对数据集的数据结构和部分字段内容有了逻辑上的认识。本章节将对消费者消费行为数据预处理、特征工程以及模型调优,建立消费行为-信贷素养预测模型,以达到识别信用风险的目的。
2.1 数据预处理
在现实的工业场景中,大部分的数据都是不规整、高缺失的“脏数据”,如不处理这种数据“噪声”就直接用于模型训练,效果往往大打折扣。本文通过数据清洗、数据集成以及数据变换等方法,结合具体业务逻辑对数据进行处理后,从而大幅减少数据噪声,提高训练分类器的性能和准确率。
2.1.1 缺失值处理
在处理数据的过程中,样本往往会含有缺失值。 这是由于顾客在消费过程中,其购买的商品信息或者具体的消费项目难以归类,在判别消费类型上有难度。此外,获得的数据库本身就存在数据不完整的问题。对缺失值的处理方面,首先对缺失率大于70%的数据进行删除,即Dailishop_和Traval_13,其中Traval_13项目数据的缺失与该金融产品及其绑定的旅行服务企业之间的数据交互问题有关。去除2个项目后,对剩余缺失值进行基于欧氏距离的插值处理。即参照拥有数据的样本数据,选取该特征大类下(如Travel特征大类)与该确实样本的其他未缺失特征平均欧氏距离最小的样本,选取改样本相应值作为缺失样本值的插值依据(如表4)。
2.1.2 单一值处理
所谓单一值,就是对各个样本来说,彼此之间相没有显著差异的值,即对目标预测没有意义的值,本文通过数据标准差来反映数据的波动情况,结果显示,在7个项目上,标准差小于0.1。即这一数据在各个样本之间的表现比较均一,包括“非商业医疗保险投入额度”,“消费发生的月份”等。值得注意的是,这些特征从逻辑上,本身就是与“消费素养”因素无关,也符合本文判断。
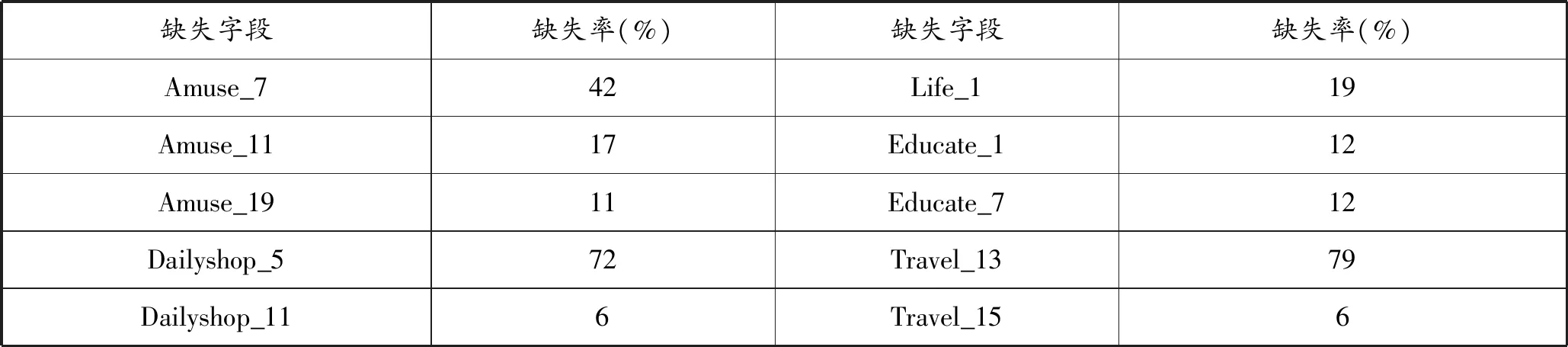
表4 缺失值情况统计
2.1.3 重要特征处理
在原始数据的训练过程中,本文采用基于树模型的LightGBM,用以输出各个特征的重要性。这一重要性特征的筛选对后续机器学习模型的约束有重要意义。具体过程如下:首先定义训练数据集D,定义集合D的经验熵为H(D),对于特征X,条件熵为H(D|X),则特征X的信息增益g(D,X)为H(D)与H(D|X)的差。值得注意的是,熵与条件熵之间的差值为“互信息”,训练数据集中类与特征的互信息就等价于决策树学习中的信息增益。获得的信息增益,往往反映特征的类群性,即信息增益越大,分类能力越强。通过比较信息增益,获得了重要性最高的10个特征。选取这10个特征与样本数据进行对比,剔除缺失该特征的样本。同时,对于重要性较低(<0.02)的特征进行删除。
2.2 特征工程
特征工程是指将原始数据转化为可直接进行训练的特征向量的过程。包括数据转换、特征提取、特征选择等方法。特征工程可以有效地简化数据处理的过程,通过建立判别特征来高效地进行机器学习。
2.2.1 消费时间统计
对于消费时间统计,本文收集了消费的月份、日期(星期几)、节假日、时间等特征,其中月份这一特征通过单一值分析过程已经被剔除,对于剩余的几个特征,本文发现,其中星期六、日可以和短假期合并为一个特征,即“三天以内假期”特征,对于长假期特征则保留。具体的消费时间,分成12个时段非常繁琐。由于通过数据分析,产生不良金融信用行为的样本在“9:00-17:00”的消费行为比较活跃,因此对于消费时间分为两类:“工作时间”和“非工作时间”,两类时间的主要划定依据为是否在“9:00-17:00时段”,尽管这一时段并不能完全代表“工作时间”。
2.2.2 相关性分析
高相关性特征即共线特征,表示特征变量之间高度相关。一般来说,2个相关性很高的特征没有必要作为2个独立的特征存在,从而造成“数据噪声”或者增加了数据处理难度。
皮尔逊相关系数用于衡量变量之间线性相关的程度,2个变量之间的皮尔逊相关系数的计算方法为2个变量之间的协方差和标准差的商:
ρ(X,Y)=Cov(X,Y)/σXσY
对于相关性>0.96的特征进行删除。共删除了6个特征。比如在1个月内购买大型消费品(商品房、汽车)这一类型的特征与消费集中特征,具有前者特征的样本往往也具有后者特征。因此这一类型特征可以去除,用消费集中特征代表即可。
2.2.3 数据标准化
为了对数值去量纲化,并能够让不同特征的数据进行比较。对数据进行标准化,采用最大值做商法,即对于样本特征值I,比较全部样本对应特征值,选取最大值做商,得出标准化值Istan,从而让所有样本数值在0~1浮动。可以保证输入值保持在一个相对较小的范围内,加快训练速度。同时,也可以避免因为输入值范围过大而使权重过大的情况。
Istan=I/Imax
3 机器学习算法建模
3.1 多模型对比
将以上预处理和特征工程后的数据划分为训练数据集和测试数据集,通过目前主流的机器学习算法,建立消费行为-信贷违约模型。
通过Python人工智能主流模型,利用相应数据包进行计算。其中逻辑回归模型使用SKLEARN机器学习库的LogisticRegression算法接口,读取已处理的结构化训练集和测试集,通过网格搜索穷举参数范围确定最优超参数,进行数据拟合。LightGBM、AdaBoost等模型使用Python专门的相应程序包。不同模型的计算结果中,主要关注Auc(Area Under Curve)参数,作为模型评估指标。通过对比可以得出,在使用的六种模型中,LightGBM的拟合效果最好,逻辑回归效果最差(如表5)。
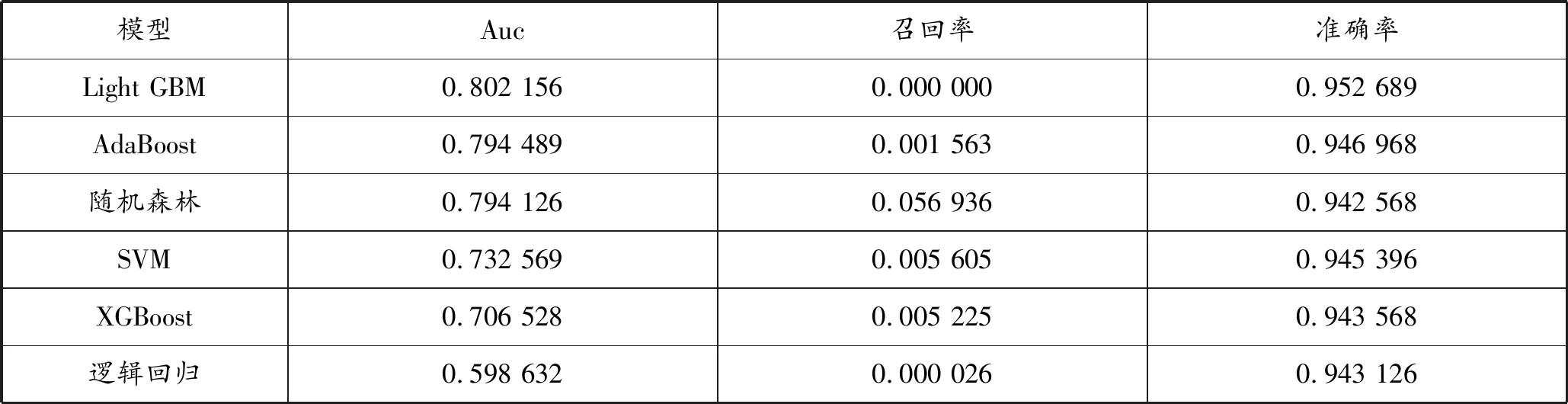
表5 不同模型评价对比
3.2 模型融合
为了进一步提高拟合效果,本文参照机器学习惯例,使用SKlearn投票机将逻辑回归、随机森林,SVM,XGBoost等6种模型融合,结合不同机器学习分类器,采用平均预测概率(软投票)来预测分类标签,提升分类效果。
软投票模型的Auc值为0.804568,略高于Light GBM模型,反映集成学习的融合方式效果较好。
3.3 消费行为与违约率关系
前述特征工程已经提取了对违约率产生较大影响的消费行为,基于树模型的LightBGM根据信息增益、基尼系数计算来返回特征重要性,也有助于反馈影响违约率的消费行为,本文展示了影响违约率的重要性前6指标,即消费行为呈现以下特征的用户更容易出现违约行为,以下消费行为可看作不良消费行为(如表6)。

表6 特征工程后的特征重要性
4 结论
4.1 融合模型拟合率更高
采用ACU值作为模型评估的指标,集成模型明显优于单一模型。单一模型中,LightBGM与AdaBoost具有良好的拟合效果,对用户消费行为的评估,采用融合模型有助于更准确地获得评估结果。
4.2 消费习惯影响超过消费类型
通过特征工程以及基于树模型的LightBGM根据信息增益、基尼系数计算来返回特征重要性,本文得出了影响到用户违约行为的不良消费行为,其中,本文自建的2个特征“冲动消费指数”和“消费集中指数”占据较高的两个重要性,而具体的消费项目影响程度相对较低。用户的消费习惯比消费类型更能反映用户的金融素养和违约风险。
4.3 模型具有一定的改良空间
本文根据平台用户使用的数据,通过集成模型在预测中的准确率可以达到94%,这反映模型还有一定的改良空间。更大的数据量以及对特征的优化,对模型的优化将有助于获得更加精准的预测结果。
