一种改进的协同表示算法在人脸识别中的应用
2020-07-14董林鹭林国军赵良军石小仕薛智爽
董林鹭,林国军,赵良军,石小仕,薛智爽,黄 慧
(1.四川轻化工大学自动化与信息工程学院,四川自贡643000;2.四川轻化工大学计算机学院,四川自贡643000)
人脸识别技术快速发展,在生活和工作中得到了大量应用,样本采集过程中受到人脸光照、遮挡、和训练样本过少等因素影响,提高人脸在非理想条件下的识别率,仍然是目前研究热点. 实际工程中,样本数量足够多时,可弥补遮挡、光照等不利因素影响[1-2]. 训练样本较少时,只能通过改进人脸识别算法增加人脸识别率. 因此,众多学者提出了不同的识别分类算法,将同类样本表示为线性相关的线性表示分类器[3](Linear Regression Classification,LRC). 利用训练样本图像的稀疏线性组合表示测试样本图像的稀疏表示分类器(Sparse Representaion based Classification, SRC)[4]、Zhang 等人[5]提出的协同表示分类(Collaborative Representation based Classification, CRC)使用正则最小二乘法,识别速度极大地满足实际工程的要求.
Wu 等人[6]提出(PC)2A 调节不同参数获得虚拟人脸,徐勇等人[7]提出利用原始样本生成镜像和对称样本,分别与原始样本权值融合提高识别率. 徐艳[8]提出原始样融合虚拟平均脸和虚拟对称脸构成新的训练样本,利用模糊决策方法进行分类. 基于协同表示分类器的优点,许多学者提出了改进的协同表示分类器算法,主要思想是利用原始样本构造虚拟样本增加人脸特征. 项晓丽[9]利用原始样本与镜像样本权值融合,采用协同表示分类器识别取得较好的识别率. 杨明中[10]利用原始样本与对称样本权值融合再利用协同表示分类器识别来提高识别率. 由于生成的虚拟样本相互关联的纹理受到光照的影响改变了原有的信息,本文提出一种类似平均脸的方法对虚拟样本进行处理,增强虚拟样本相互关联的纹理信息以提高识别率.
1 构造虚拟样本与纹理增强处理
1.1 生成虚拟样本
在小样本问题上,用原始人脸图像生成虚拟样本来提高识别率是一种快捷且有效的方法. 以原始人脸图像生成水平镜像图像和左轴对称图像的原理为例,水平镜像虚拟样本生成原理是以人脸图像的中轴线为中心,像素点的行位置保持不变,列位置从左到右相互交换,将原始人脸图像中像素点位置定义为f(x1,y1),用M、N分别表示该矩阵的行与列,f(x2,y2)表示镜像处理后得到的像素点位置. 表达式如下:

左轴对称虚拟样本的原理与水平镜像的生成原理相似,区别在于将中轴线右半部分的像素值归零得 到f′(x1,y1),再 对f′(x1,y1) 镜 像 处 理 得 到f′(x2,y2),最后将f′(x1,y1)与f′(x2,y2)相加得到左轴对称图f(x3,y3).
1.2 协同表示算法特纹理特征提取能力的增强处理
设镜像虚拟样本图像f(x2,y2)是个整体变量F(x),x表示虚拟样本图像内的灰度值. 同样,设纹理增强后的图像f*(x2,y2)是个整体变量F(y),y表示纹理增强后图像内的灰度值. 增强过程满足y=T(x).
T(x)的求解过程如下:
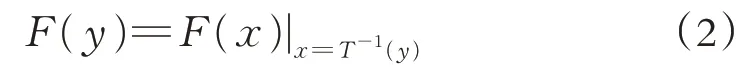
式(2)中,T-1(y)是T(x)的反函数. 对上式两边y同时求导,得:
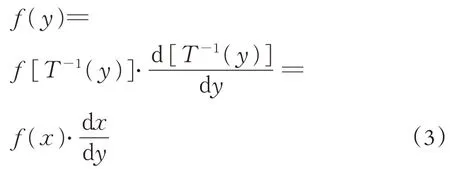
将f(x)、f(y)的结果代入(3)式中得:

整理得:
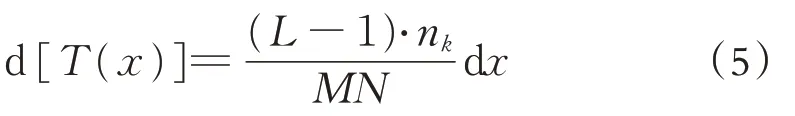
同时对两边x积分,得到增强纹理的关系式:

2 协同表示分类器
设有c类训练样本,每类训练样本由不同表情、姿态和光照共n幅人脸组成,可得训练样本的集Xi=[xi1,…,xin](i=1,2,…,c),s表 示 某 测 试 样本,可得s=Xα.
α的求解过程如下:
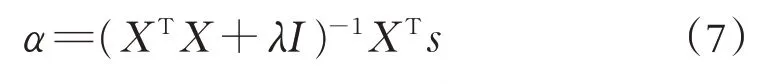
式(7)中,λ表示正则项系数,I表示单位矩阵.
利用系数α求出第i类训练样本与测试样本s的重构误差:
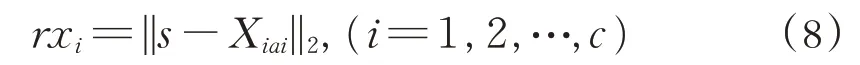
同理,根据协同表示分类,求得轴对称样本、镜像样本和本文增强纹理样本的第i类训练样本与测试样本的重构误差:

3 权值融合
上述协同表示分类器的重构误差有4组,对该4组重构误差加权融合,得到最终的分类的识别结果,根据文献[9][10]可得,原始样本与轴对称样本和原样本与镜像样本两两融合效果优于三者融合. 本文算法同样对两种增强纹理信息后的虚拟样本图像两两与原始样本融合,其重构误差分别是rxi、ryi、rzi、rμi,对后三种重构误差分别与原始样本的重构误差rxi加权融合得到最终的重构误差ryi2、rzi2、rμi2:
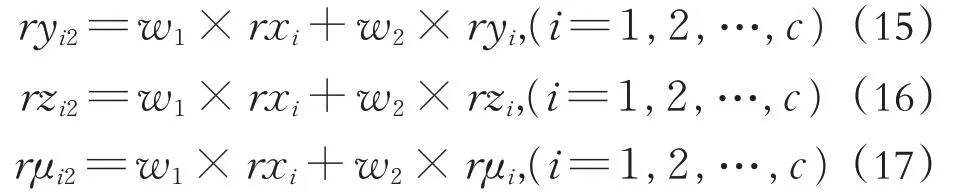
其中,w1、w2分别表示原始样本与虚拟样本融合时的权值,满足w1+w2=1. 实验结果由最终重构误差进行分类识别.
4 实验结果分析
在Yale、ORL 和FERET 人脸数据库上进行实验,Yale 人脸数据库包含15 个人,每人有11 张不同表情和光照的人脸图像,共165张;ORL人脸数据库包含40个人,每人有10张不同姿态和表情的人脸图像,共400 张,本文选用的FERET 人脸数据库包含200 个人,每人有7 张不同光照、表情和姿态的人脸图像,共1 400 幅图像. 实验前对人脸数据库进行灰度处理. 随机选择人脸库中每个人的其中一幅人脸图作为训练样本,剩余人脸图像作为测试样本,并对协同表示算法、文献[9]算法、文献[10]算法和本文算法进行对比实验.部分人脸样本如图1所示.
表1 是分别选取Yale、ORL、FERET 人脸库第1、2、3 幅人脸图像为单训练样本,其余人脸图像作为测试样本得到的识别结果.
由表1 可知,不同权值融合对识别的影响非常大,本文算法在Yale 人脸库中不同权值融合后其识别率处于高位,在ORL、FERET 人脸库中原始样本重构误差比例较高时,识别率处于高位,文献[9]算法、文献[10]算法在ORL、FERET 人脸数据库中,对比本文算法,部分小组识别率处于高位. 结果表示本文算法能有效地提高识别率.

图1 三种人脸库中的部分人脸样本Fig.1 Partial face samples from three face databases
在Yale 人脸数据库中,本文算法除第3 幅人脸作为训练样本且权值为0.5时的识别率没处于高位,其余权值融合识别率都处于小组高位,较原始样本高7.33% ~17.33%,比文献[9]算法高2.67% ~3.33%,比文献[10]算法高2.00% ~8.66%. 对于姿态变化丰富的ORL 人脸数据库,本文算法在第1 幅人脸图像作为训练样本时的识别率处于高位,提高2.5%;在第2 幅人脸图像作为样本时识别率最高是文献[10]算法其次是本文算法,最次是文献[9]算法;在第3幅人脸图像作为训练样本时识别率最高时文献[9]算法其次是本文算法,文献[10]算法提升效果最次. 因此,对于ORL人脸数据库,表中算法各有所长.在人数众多的FERET 人脸数据库中,本文算法在部分小组识别率没达到高位,但提升效果最高的识别率都是由本文算法得到. 较原始样本提高4.5% ~13.0%,文献[9]算法较原始样本提高3.17% ~12.08%,文献[10]算法较原始样本提高1.67% ~2.92%. 实验结果表明,本文算法在总体上对识别率的提高最优.
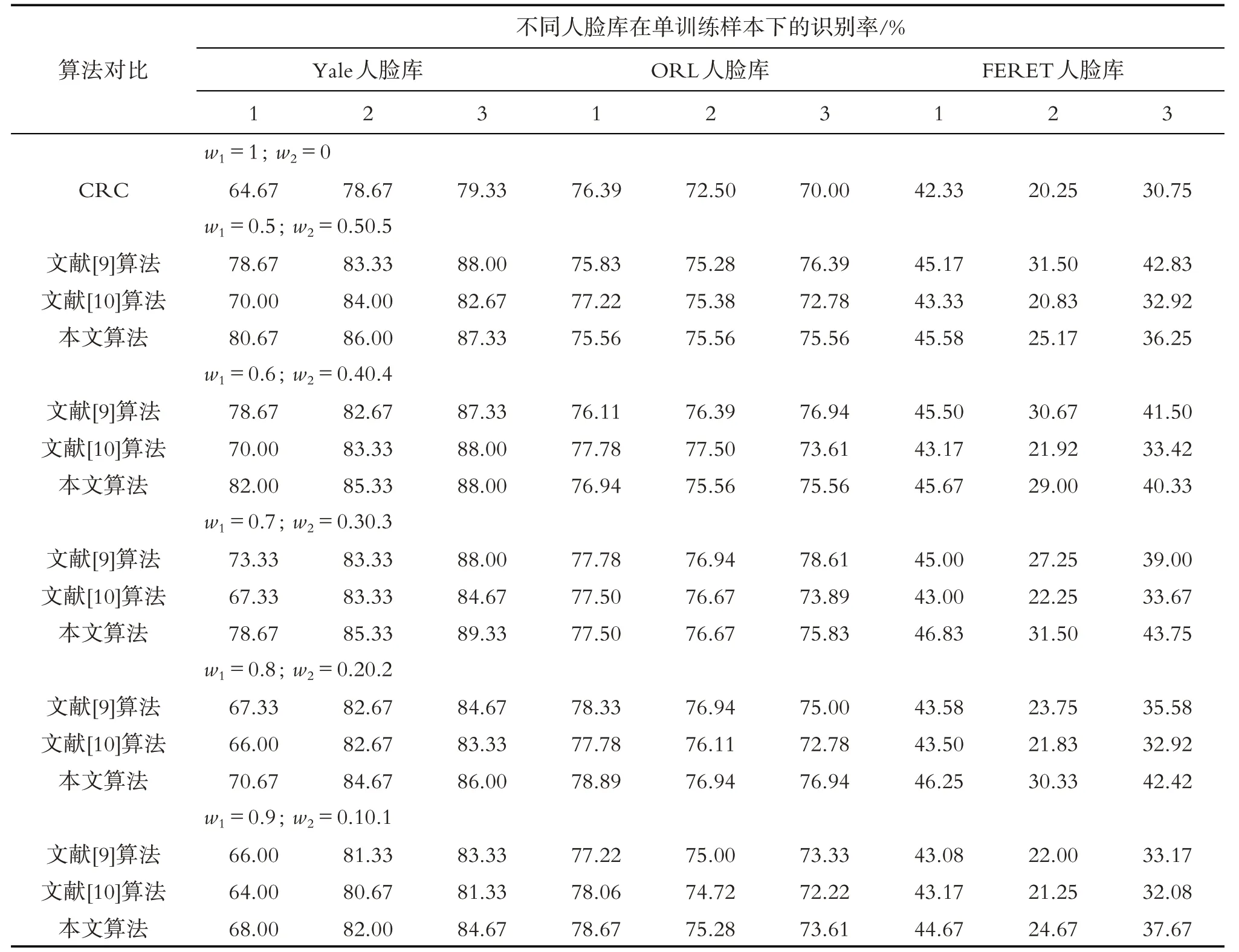
表1 在Yale、ORL、FERET人脸库中的单样本识别结果Table 1 The results of single sample recognition in Yale,ORL,FERET face database
5 总结
影响人脸识别率的因素包含了表情、姿态、光照、遮挡、样本数量过少,当训练样本过少甚至是单样本时,对识别率影响最大. 只有通过单样本人脸来构造虚拟样本,增加训练样本数量. 对一些人脸数据库仅靠虚拟样本无法有效提高识别率. 许多学者将虚拟训练样本与原始样本融合,以提高识别率. 研究发现,生成虚拟样本的相互关联纹理信息,常因光照等因素影响而无法有效地提高识别率. 于是提出增强虚拟样本相互关联纹理信息的协同表示算法,改善因训练样本过少,甚至单样本情况下识别率过低的问题. 但本文算法从实验结果可以看出,对于姿态变化较大的人脸图像的识别率,提升效果不够理想,这将成为本算法接下来的研究方向.
