基于注意力机制与空间金字塔池化的行人属性识别
2020-07-14
(太原理工大学 a. 机械与运载工程学院,b. 大数据学院,山西 太原 030024)
随着视频安全系统以及计算机技术的发展,行人属性识别已经被广泛地用来进行行人重识别[1-2]、面部识别[3]以及视频监控[4]等方面的研究。由于行人是视频监控中主要的监控对象,因此对行人属性进行精确的识别格外重要。
行人属性识别方法主要分为基于手工设计特征和基于深度学习2种方法,其中,传统基于手工设计特征的方法通过颜色和纹理提取方向梯度直方图(HOG)、局部二值模式(LBP)等特征向量,为每一个属性训练一个分类器,实现行人的多属性识别。Cao等[5]提取HOG特征,利用AdaBoost分类器识别行人属性;Zhu等[6]提取局部二值模式特征和HOG特征训练AdaBoost分类器进行属性识别;Chen等[7]用条件随机场或马尔可夫随机场方法,通过行人属性间的内在联系进一步提高行人属性识别的精度。这些方法都尝试训练一个鲁棒的行人属性识别模型,但该类方法手工设计特征的过程比较复杂,鲁棒性差,并且特征表达能力不足。
近几年来,一些学者将深度学习的方法应用于行人属性识别。Lin等[4]对Alexnet网络进行改进,提出一种多标签卷积神经网络DeepMar,该网络在一个统一的框架下预测多个属性,并且提出加权交叉熵损失函数解决数据不均衡问题。Liu等[8]提出长短期记忆(LSTM)模型,利用属性之间的相关性,将循环编码器框架引入行人属性识别中,提升行人属性识别精度。
虽然深度学习的方法与传统属性识别的方法相比具有较好的自适应能力和容错能力,但是此类方法都只关注行人的整体特征,而忽略了行人细粒度特征的识别和局部特征的提取。例如,如果想检测属性“打电话”,有效的特征应位于头、肩等小范围区域内,然而,现有的方法仅提取了全局特征[9-11],且对局部区域的语义特征提取效果较差。
针对以上问题,本文中提出了一种基于注意力机制与空间金字塔池化(SPP)[12]的行人属性识别方法,该方法通过注意力机制强化不同维度的特征来提升行人整体特征表达,并且加入空间金字塔池化操作,使得任意大小的特征图都能够转换成固定大小的特征向量,对输入的图像大小不再有所限制,更多地保留了图像信息。
1 方法
1.1 相关理论
1.1.1 Inception模型
Inception V3模型是Szegedy等[13]提出的一个图像分类网络模型。该模型包含3种不同的Inception模块,分别为Inception 1、Inception 2、Inception 3,模块结构如图1所示。每个Inception模型采用不同大小的卷积核进行多尺度特征提取,最后将提取到的特征进行融合。Inception 1模块使用2个3×3的卷积代替5×5的卷积;Inception 2模块使用1×3和3×1的卷积代替3×3的卷积;Inception 3模块使用1×7和7×1的卷积层代替7×7的卷积层,以减少网络参数,同时提升网络的特征表达能力。

图1 Inception模型结构
1.1.2 空间金字塔池化
空间金字塔池化由3个最大池化层组成,如图2所示。对于输入任意大小的特征图,3个最大池化层分别以大小为4×4、2×2和1×1的网格将特征图分为16、4、1块,然后在每个块上最大池化,提取相应特征。第1个池化层提取16维特征向量,第2个池化层提取4维特征向量,第3个池化层提取1维特征向量,最后将3个池化层提取的特征融合,得到16+4+1=21维特征向量,从而使任意大小特征图都能转化为21维的特征向量,全连接层不再对输入图像的大小有所限制。
在真实的视频监控领域,捕获到的行人图像尺寸不同,传统的方法在进行行人图像属性识别时,需要对图像进行缩放、裁剪,这样会导致图片信息丢失,从而降低了识别准确率。针对这个问题,本文中在全连接层前添加空间金字塔池化层,将不同大小的输入图像转换成固定大小的特征向量,以保留图像信息,提升模型的识别精度。

图2 空间金字塔池化结构
1.1.3 注意力机制
注意力机制是从图像特征信息中有选择地筛选出重要的特征信息,并对特征图进行逐像素点相乘,从而使重要的特征信息得到进一步加强。
注意力机制模块由一个卷积层和一个特征加强层组成,如图3所示。首先通过1×1的卷积对输入的特征进行降维,使其通道数降为8,筛选出重要特征信息,输出特征图αi(i=1,2,3),然后对特征图αi中每个像素点的值进行平方,强化特征图中的重要特征信息,计算公式为
γi=αi×αi,
(1)
式中γi为得到的特征图。

图3 注意力机制模块
图4为降维后注意力特征图。由图可以看出,降维后的特征图α3中每个通道包含行人不同属性的局部特征。杂乱的背景、不同的光照等因素使得行人属性很难有效地识别,通过降维处理,行人的特征可以被不同的注意力区域单独捕捉,然后添加注意力机制,强化每个通道中的局部特征,从而提升行人整体特征表达。
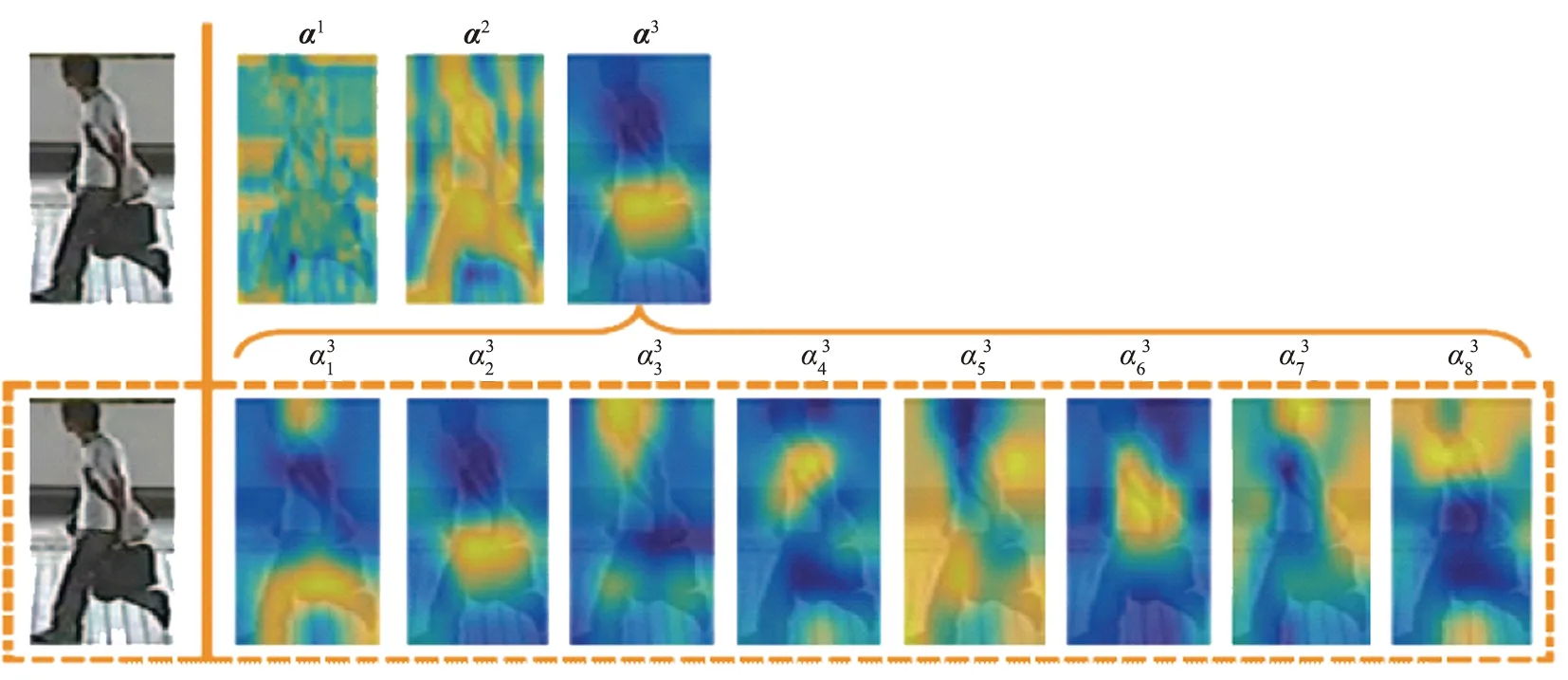
图4 降维后注意力特征图αi(i=1,2,3)
1.2 本文中提出的方法
针对视频监控领域中行人属性识别精度较低、细粒度特征难以识别的问题,本文中提出一种基于注意力机制与空间金字塔池化的特征提取网络结构AMS-NET。AMS-NET首先使用Inception V3模型中Inception 1、Inception 2、Inception 3模块提取特征,然后,通过注意力机制,强化特征表达,提高行人属性的识别精度。为了更多地保留图像信息,通过在全连接层前添加空间金字塔池化,将不同大小的输入图像转换成固定大小的特征向量,从而进一步提升网络特征表达能力。
AMS-NET的结构如图5所示,整个网络分为主网络MainNet和3个分支网络NET 1、NET 2和NET 3,其中Conv表示卷积层,Maxpooling为最大池化层,FC为全连接层,SPP为空间金字塔池化层。
主网络MainNet包括4个卷积层和2个池化层,Inception 1、Inception 2和Inception 3模块,SPP层,1个全连接层FC 0。

MainNet— 主网络;NET—分支网络;Conv—卷积层;Maxpooling—最大池化层;FC—全连接层;SPP—空间金字塔池化层。图5 基于注意力机制与空间金字塔池化卷积神经网络结构
4个卷积层和2个池化层对输入图像进行初步的特征提取,再输入到Inception 1、Inception 2和Inception 3模块进行下一步特征提取,接着通过SPP层,提取不同维度特征,最后将特征图输入全连接层FC 0。
3个分支网络NET 1、NET 2和NET 3将主网络中Inception 1、Inception 2和Inception 3模块的输出分别作为NET 1、NET 2和NET 3分支网络的输入。
NET 1分支网络中包括一个注意力机制模块、1个Inception 2模块、1个Inception 3模块和1个SPP层,主要用于进一步提取局部细节特征(边缘特征和纹理特征),NET 1的输出再进一步输入到全连接层FC 1。
NET 2分支网络包括1个注意力机制模块、1个Inception 3模块和1个SPP层,主要用于进一步提取全局特征,NET 2的输出再进一步输入到全连接层FC 2。
NET 3分支网络包括1个注意力机制模块和1个SPP层,主要用于进一步提取语义特征,NET 3的输出再进一步输入到全连接层FC 3。
AMS-NET的结构将主网络MainNet输出的特征与3个分支网络NET 1、NET 2和NET 3输出的特征进行融合,再输入全连接层FC 4。
最后将全连接层得到的特征通过Sigmod损失函数进行概率计算,得到行人属性预测标记,进行行人属性识别。
2 实验
2.1 数据集
本文中使用公开的行人属性数据集PETA[14]、PA-100K[15]和CUHK03[16]对提出的方法进行验证。PETA数据集中包括19 000幅行人图像,定义了65个属性。依照惯例,将数据集分为3个部分,其中9 500幅图像作为训练集,1 900幅图像作为验证集,7 600幅图像作为测试集。PA-100K数据集包括10万幅行人图像,26个属性,将数据集以8 ∶1 ∶1的比例分为训练集、验证集和测试集。CUHK03数据集包括13 164幅行人图像,本文中选取其中6 000幅图像作为训练集,1 500幅图像为作为测试集,标注了12个属性。
2.2 评价指标
对于行人属性识别算法,通常采用Deng等[14]提出的评估方式,将平均精度Am、准确率A、精确率P、召回率R以及P与R的调和均值F1共5个指标作为行人属性识别的评价标准。
2.3 实验内容
采用Keras框架,用随机梯度下降法训练网络,在训练过程中,考虑到数据集中样本数量有限,初始学习速率不宜设置过大,通过实验验证,将学习速率设置为0.001,学习速率每轮下降1/500,权重衰减设为0.000 4,可以保证网络快速收敛。对于数据集样本不均衡导致模型泛化能力较差的问题,本文中使用Sigmod交叉熵损失函数对每个属性使用不同权重。模型训练环境如下:Nvidia Tesla K40、11 GB显存、Centos 7.0操作系统、24 GB内存。在PETA和CUHK03数据集中输入的图像分辨率为96像素×96像素,在PA-100K数据集中输入的图像分辨率为60像素×60像素。
2.4 实验结果
本文中比较AMS-NET网络结构属性识别方法与目前最先进的几种方法在PETA、PA-100K、CUHK03数据集上的性能,其中6种基于卷积神经网络(CNN)的深度学习属性识别方法,如Hydraplus[15]、M-net[15]、DeepMar[4]、SR[17]、GAPAR[18]、Inception V2[19],3种基于手工设计特征的方法,如ELF-mm[20]、FC 7-mm[21]和FC 6-mm[21]。
表1为本文中提出的方法与ELF-mm、FC 7-mm、FC 6-mm以及DeepMar方法在PETA数据集上的比较结果。从表中数据可以看出,本文中提出的方法的Am、A、P、R和F1这5个评价指标分别达到了78.31%、72.50%、82.67%、79.66%、81.14%,与性能最优的DeepMar方法相比,Am、A、R和F1分别提升了2.59%、1.92%、3.43%、1.08%。由于PETA数据集中样本不均衡,因此本文中提出的方法在精确率方面略低于DeepMar方法。图6是PETA数据集中35个属性平均精度柱状图。
从图6可以看出,与DeepMar方法相比,本文中提出的方法在“格子衬衫”“标志”和“V领上衣”等细粒度属性识别上具有明显优势。
表2所示为本文中提出的方法与DeepMar、M-net、HP-net、SR、Inception V2、GAPAR方法在PA-100K数据集上的实验比较结果。从表中数据可看出,本文中提出的方法的Am、A、P、R和F1这5个评价指标分别达到了81.65%、80.12%、90.94%、84.94%、87.83%,与性能最优的GAPAR方法相比,Am、A、P、R和F1分别提升6.19%、5.59%、7.78%、2.15%、4.86%。

表1 不同方法在PETA数据集上的实验结果 %

图6 不同方法在PETA数据集上的平均精度柱状图

表2 不同方法在PA-100K数据集上的实验结果 %
图7所示为本文中提出的方法与M-net和DeepMar方法在实际视频监控下识别结果对比。可以看出,本文中提出的方法可以有效地识别行人多种属性,识别精度均高于其他2种方法,对于“戴眼镜”“短袖”和“上衣有标志”等细粒度属性具有最高的识别精度。

图7 不同方法在PA-100K数据集上的属性预测结果
表3所示为本文中提出的方法与Minicnn[22]、M-net和DeepMar方法在CUHK03数据集上的实验比较结果。从表中数据可以看出,本文中提出的方法的Am、A、P、R和F1这5个评价指标分别为81.25%、66.36%、66.01%、51.16%、57.65%。本文中提出的方法与Minicnn、M-net、DeepMar方法在CUHK03数据集上的平均精度柱状图如图8所示。从图中可以看出,在12个行人属性中,本文中提出的方法有9个属性达到了最高的识别精度,对于“手提包”“短头发”和“单肩包”等细粒度属性,本文中提出的方法都具有最高的识别准确率。
实验结果表明,传统的基于手工设计特征的方法特征表达能力不足,导致行人属性识别精度较低,而且大多数深度学习方法细粒度特征的识别能力有限,本文中提出的方法通过注意力机制强化不同维度的特征,提升了行人整体特征表达和网络的细粒度特征识别能力,与其他方法相比,具有更高的行人细粒度特征识别能力和行人属性识别精度。

表3 不同方法在CUHK03数据集上的实验结果 %

图8 不同方法在CUHK03数据集上的平均精度柱状图
3 结论
本文中提出了一种基于注意力机制与空间金字塔池化的行人属性识别方法。该方法通过注意力机制强化不同维度的特征,从而提升行人整体特征表达,同时,加入空间金字塔池化操作,使得任意大小的特征图都能够转换成固定大小的特征向量,对输入的图像尺寸不再有所限制,更多地保留了图像信息。相对于其他属性识别方法,本文中提出的方法可以提取到行人更高层的语义信息,受复杂环境的影响较小,具有更高的准确率。
本文中的研究较多地注重算法识别精度,而对实际应用场景中算法的运行时间没有过多考虑,因此,提高算法效率,减少算法运行时间是将来的重点研究方向之一。
