基于互补型集成经验模态分解和遗传最小二乘支持向量机的交通流量预测模型
2020-07-14朱永强王小凡
朱永强,王小凡
(青岛理工大学机械与汽车工程学院,青岛 266520)
随着中国汽车制造技术成熟以及道路网建设规划逐步完善,汽车保有率迅速上升,也增加了对城市交通进行控制与规划的需求,而精准的交通流预测是相关研究的重要基础,如何准确地预测交通流量也引起了越来越多学者的关注,提出包括指数平滑模型[1]、数据序列模型[2]、回归分析法[3]等方法。但传统预测方法大多应用线性模型,而目前的交通流由于自身的复杂性以及非线性等特征并不适用,因此近年来开始提出用混合模型来增加预测可靠性。余林等[4]对交通信号序列采用经验模态分解,将分解后得到的分量经过分类后重新构造时间序列进行预测,结果表明组合模型优于传统的时间序列;曹成涛等[5]提出用粒子群算法来优化支持向量机中的相关参数提高预测精度;张朝元等[6]实验证明了支持向量机模型优于传统神经网络的预测效果。李松等[7]对传统的神经网络模型的参数进行优化,研究表明神经网络中的参数经过优化后能取得更好的预测效果。
上述研究中组合预测模型能够结合多种模型的优点,提高了模型预测精度,但研究多以算法优化支持向量机模型较多,而最小二乘支持向量机能够降低支持向量机的计算复杂程度,更适用于非线性问题求解;同时由于交通流量本身的非线性和复杂性,模型在表现数据的非平稳性存在局限,选取的训练样本也不能够完全反映数据特征,而经验模态分解虽然能够分解信号得到模态函数,但方法本身存在分解不稳定,容易产生模态混叠现象影响预测效果;另外组合模型大多以单一算法优化模型为主,直接用于不稳定的交通流数据预测波动较大。
针对目前预测模型存在的问题,结合当前中外研究趋势,提出一种基于互补型集成经验模态分解和遗传算法优化最小二乘支持向量机的组合预测模型,并运用于实际道路流量预测中,验证其是否具有比其他预测模型更优的预测效果和精度。
1 互补型集成经验模态分解
1.1 经验模态分解原理
经验模态分解(empirical mode decomposition,EMD)是由 Huang等[8]提出的,它适用于非线性、非平稳的信号处理。根据原始信号的局部特征,EMD将不同尺度的信号分解,并得到具有特征尺度的本征模态函数(intrinsic mode function,IMF)[9],因此将原始序列分解为本征模态函数和残余分量,即

(1)
式(1)中:m为IMFS的个数;ci(t)为第i个IMF;rm(t)为第m个残余分量。
1.2 互补型集成经验模态分解原理
虽然EMD能够处理非线性问题,但在分解过程仍存在模态混叠,随后刘莹等[10]提出互补型集成经验模态分解(complete ensemble empirical mode decomposition,CEEMD),在初始信号中加入正负成对形式的白噪声信号,不仅克服了EMD中的模态混叠现象,也能够消除重构信号中的残余辅助噪声,提高模型计算效率,具体步骤如下。
(1) 将n组白噪声加入原始信号中。

(2)
式(2)中:M1、M2表示为加入辅助白噪声之后的信号;S表示原始信号;N表示加入的辅助白噪声。
(2)EMD分解后每个信号得到一组IMF分量。
(3)多组分量取均值得到分解结果。

(3)
式(3)中:cj表示分解后最终得到的第j个IMF分量。
2 最小二乘支持向量机
传统的支持向量机(support vector machine,SVM)在处理小样本数据问题时具有优良的统计能力,Suykens等[11]进一步提出改进版支持向量机(least square support vector machine,LSSVM),使用一组线性方程组取代 SVM 的二次规划问题来解决函数估计,且将 SVM 的不等式约束变为 LSSVM 的等式约束,采用最小二乘线性系统作为模型的损失函数[12],大大地简化模型计算过程,提高运算速度。LSSVM将一个样本集D={(xi,yi) |i=1,2,…,N},其中xi∈Rn,yi∈R,通过使用一个非线性变换Ф(x)从原来的低维空间映射到高维空间,即将非线性函数转化为线性函数,构建最优回归函数,具体过程模型表示为
y(x)=ωTΦ(x)+b
(4)
式(4)中:ωT表示为空间权向量;b表示偏置量。
根据结构最小风险化的原则,目标函数和约束条件设置如下:

(5)
式(5)中:J为优化函数;γ为惩罚系数,且γ≥0;ei表示第i个误差变量。
定义引入朗格朗日函数

(6)
式(6)中:a为 Lagrange乘子。根据最优化理论中的KKT(karush-kuhn-tuche)条件使用Lagrange函数分别对上式中ω、b、ei、ai求偏导,结果汇总如下:

(7)
消除上式中的ω和e,可以得到如下矩阵方程:

(8)
式(8)中:s=[1,1,…,1]T;K=Ф(xi)TФ(xi);I表示单位矩阵;a= [a1,a2,…,al]T;b= [b1,b2,…,bl]T;y= [y1,y2,…,yl]T。
使用最小二乘法求出a和b得到LSSVM回归函数最终预测模型:

(9)
式(9)中:K(x,xi)表示核函数,选择结构简单并适用于非线性问题的径向基函数的作为核函数;σ>0,表示为核函数的待定宽度参数。
在LSSVM模型中,惩罚系数γ的选取将直接影响整个模型计算的复杂程度以及稳定情况,当γ设定较小,将导致模型训练更长,误差较大;而当γ取值过大则会导致模型训练过拟合。核函数的宽度参数σ控制整个函数的径向作用范围,σ的取值变小后拟合误差将会减少,但训练时间会延长。因此为提高LSSVM模型的预测精度,需要对两种参数进行优化得到最优解[13]。传统的参数优化方法是通过交叉验证法、穷尽搜索法等,这些方法虽能得到最优解但耗时较长且容易盲目选择,而遗传算法操作简单,收敛速度快同时具有更好的全局寻优能力,因此使用遗传算法对LSSVM模型参数进行优化后,将新得到的参数赋予训练,达到预设误差和迭代次数后结束网络训练,输出预测结果,以提高模型的预测能力。
3 遗传算法
遗传算法(genetic algorithm,GA)[14]主要是在计算模型中设定成生物自然地进化竞争的机制,编码模型中问题参数成染色体,模拟自然界中生物遗传的选择,交叉和突变过程,并根据健康状况保留具有良好适应值的优秀个体,在继续迭代的同时形成一个新的组,使得该组逐渐接近最优[15]。遗传算法具有自适应随机优化搜索,可以做到全局寻优,在最优化领域方面更加成熟,收敛速度和效果更好。
3.1 初始种群编码
传统二进制编码存在连续函数离散化的映射误差,实数编码更适合应用于多维数值问题,使得遗传算法更加接近待解问题空间,对于个体较多的神经网络,用实数对每个个体编码,获得初始种群。
3.2 适应度函数
个体适应度值是指预测输出与实际输出之间的误差绝对值和,即

(10)
式(10)中:n为网络输出节点数;yi为网络的第i个节点的实际值;oi为第i个节点的预测值;k为系数。
3.3 选择操作
对于大量数据个体,确定随机选择个体的概率与其适应度函数值成正比,遗传算法选择轮盘赌法选择概率如下:

(11)
式(11)中:Fi为第i个个体的适应度值;k为系数;N为种群个体数。
3.4 交叉操作
将上代中优秀的基因组合传递至下一代,随机选取一个基因位置作为交叉位置,组成新的个体,产生新的寻优空间:

(12)
式(12)中:akj指第k个染色体上位于j位置时的基因;alj表示第l个染色体上位于j位置时的基因;b是[0,1]间的随机数。
3.5 变异操作
选取第i个个体的第j个基因aij进行变异:

(13)

(14)
式中:r2为随机数;g为网络已迭代次数;Gmax为网络最多进化次数;amax、amin分别为基因aij的上界和下界;r为[0,1]间的随机数。
4 模型建立
针对交通流的非稳定性和非线性的特点,首先使用CEEMD对交通流进行分解,提高数据稳定性的同时还能减小分解的模态混叠现象,得到分量和残余分量,采用GA优化参数后的LSSVM模型对各个分量进行预测,最后叠加各分量预测值,模型流程如图1所示,具体实施步骤如下。

图1 模型预测流程图Fig.1 Flow chart of model prediction
(1) 使用C EEMD降低数据非平稳性,分解原始数据后得到若干分量。
(2) 对各分量使用GA-LSSVM模型分别进行预测。
(3) 将各分量预测结果叠加得到预测值。
(4) 分析预测结果误差。
5 实际预测及研究
选取美国加利福利亚州某道路2018年3月交通量数据为研究对象,选取每天早上8点至10点,采样周期5 min,共750组样本数据,将前650组数据作为训练数据,后100组作为测速数据,设置添加白噪声的标准偏差为0.4,原始数据分解后根据不同的频率得到9个本征模态函数IMFs分量,和1个残余分量,如图2所示。

图2 原始数据分解Fig.2 Decomposition of the original data
为了验证本文提出的互补型集成经验模态分解后基于遗传算法优化最小二乘支持向量机模型(CEEMD-GA-LSSVM)预测的准确性,另选取最小二乘支持向量机(LSSVM)、经验模态分解后最小二乘支持向量机(EMD-LSSVM)、互补型集成经验模态分解后最小二乘支持向量机(CEEMD-LSSVM)和经验模态分解后基于遗传算法优化最小二乘支持向量机(EMD-GA-LSVVM)共5种模型进行对比分析,从图3可以看出LSSVM、EMD-LSSVM两种模型预测值与实际值曲线偏离过多且波动较大。图4所示为CEEMD-LSSVM、EMD-GA-LSSVM与CEEMD-GA-LSSVM 3种模型预测值与实际值对比,可以看出,CEEMD-GA-LSSVM模型预测曲线更贴近实际值,具有较高的拟合度,预测效果明显高于另4种模型。

图3 EMD-LSSVM与LSSVM模型预测结果Fig.3 Predictions of EMD-LSSVM and LSSVM models

图4 CEEMD-GA-LSSVM、EMD-GA-LSSVM、CEEMD-LSSVM模型预测结果Fig.4 Predictions of CEEMD-GA-LSSVM、EMD-GA-LSSVM and CEEMD-LSSVM models
引入平均相对误差(mean absolute percentage error,MAPE)和均方根误差(root mean square error,RMSE)两种评价指标来更直观地反映出模型预测精度。
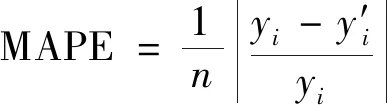
(15)

(16)
式中:n为样本数;yi为实际值;yi′为模型预测值。
表1中列出各模型的MAPE和RMSE,由表1可知单一的LSSVM模型预测误差最差,组合模型能够提高预测精度;CEEMD-LSSVM与EMD-LSSVM相比,前者的 MAPE和RMSE分别减小了4.23%和4.25%,说明CEEMD能够克服EMD的模态混叠现象,得到更有规律的分量,提高了预测精度;CEEMD-GA-LSSVM预测模型MAPE值为6.51%,RMSE值为8.29%,在所有模型中最优,且高于CEEMD-LSSVM,表明提出的模型能够汲取GA的寻优能力,更适用于预测。

表1 预测模型误差对比Table 1 Errors of different prediction models
6 结论
(1) CEEMD-GA-LSSVM模型预测误差均优于其余5种预测模型,MAPE为6.51%,RMSE为8.29%,CEEMD-GA-LSSVM模型预测值在所有对比模型中最接近实际值。
(2) 单一模型LSSVM预测MAPE为18.32%,在所有模型中预测效果最差,表明组合模型预测效果优于单一模型。
(3) CEEMD-LSSVM的预测误差10.04%优于EMD-LSSVM模型的14.27%,同样地也体现在CEEMD-GA-LSSVM和EMD-GA-LSSVM中,证明CEEMD能够克服EMD后出现模态混叠的现象,提高了预测精度,表明CEEMD比传统EMD更适用于预测模型。
(4) 通过对比CEEMD-LSSVM和CEEMD-GA-LSSVM,可以看出后者平均相对误差6.51%明显低于前者的10.04%,经过GA优化后的模型预测曲线比其他模型更加平稳,数据预测波动较少,该模型能够为交通流预测提供一定参考。
