深度协同过滤推荐模型研究
2020-07-13纪佳琪姜学东
纪佳琪 姜学东
(河北民族师范学院 河北 承德 067000)
0 引 言
随着大数据时代的到来,人们已经进入了信息爆炸时代,推荐系统对缓解信息过载问题起到了重要的作用,在电子商务、社交网络、在线新闻等领域得到了广泛应用。传统的推荐模型可以分为三类:协同过滤推荐模型、基于内容的推荐模型和混合推荐模型[1]。协同过滤推荐模型又可以分为基于用户的协同过滤模型、基于物品的协同过滤模型和基于矩阵分解的协同过滤模型。其中,基于矩阵分解的协同过滤模型以其较好的推荐效果得到了广泛的应用。其基本原理是把用户属性和物品属性分别映射到两个隐空间,使用两个隐向量来表示用户和物品,然后把这两个隐向量的内积作为用户对物品喜好程度的预测值。以此为基础,众多学者采用多种方法对其改进以增加性能,如与基于邻域的模型进行集成[2],考虑物品内容属性的主题模型[3]和基于知识的模型[4]等。然而由于矩阵分解中的内积操作是线性的,因此并不能很好地捕获用户和物品间复杂的交互信息,无法从根本上进一步提升推荐性能。
近些年,深度学习由于其强大的非线性表征能力,在计算机视觉[5-6]、语音识别[7]和自然语言处理[8]等领域获得了突破性进展。然而把深度学习应用到推荐系统领域的研究还处于起步阶段,并且这些研究主要是利用其对物品的文本描述信息[9]、音乐的声音信息[10]或图像信息[11]进行建模后再结合用户和物品的隐向量做内积操作,其本质仍是线性的,并没有很好地利用深度学习强大的非线性表征能力。
本文将使用深度学习技术对用户和物品的交互数据进行学习,建立一个深度协同过滤推荐模型。该模型是非线性的,使用了多层神经网络进行特征抽象后得出推荐结果。模型很好地将深度学习与协同过滤算法进行了结合,有效地提升了推荐系统的性能。
1 相关工作
在推荐系统研究领域,经常用到显式数据和隐式数据。使用显式数据的推荐算法一般用于评分预测,而使用隐式数据的推荐算法一般用于推荐排序(也叫Top-K推荐)。本文使用矩阵分解和深度学习技术对隐式数据进行建模。
1.1 矩阵分解模型
设|m|和|n|分别代表用户数和物品数,定义用户和物品的交互矩阵R∈R|m|×|n|。该矩阵可以来源于用户评分矩阵,对于有评分的项设为1,无评分的项设为0,见图1。
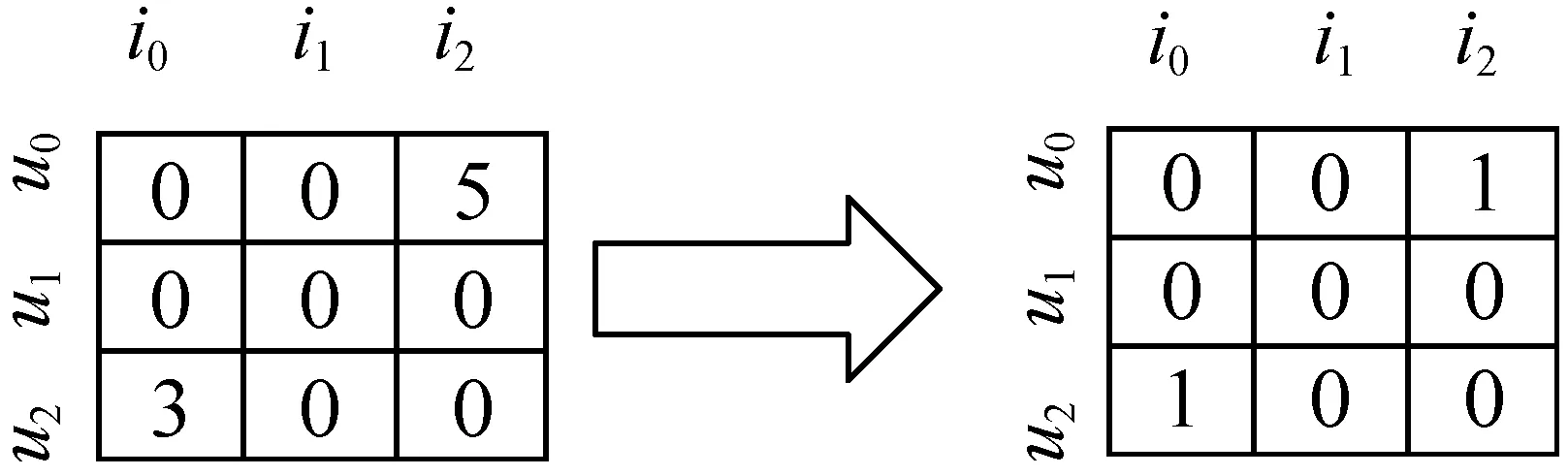
图1 用户评分矩阵的转换

(1)
式中:k表示隐空间的维度。矩阵分解模型假设隐空间中每个维度之间都是相互独立的,并且使用相同的权重进行线性组合,因此矩阵分解模型可以看作是隐向量等权重的线性组合模型。
1.2 深度学习
深度学习是在二十世纪五六十年代神经网络的基础上发展起来的,拥有输入层、隐藏层和输出层。当隐藏层数目很多时称为深度神经网络。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。随着对深度学习研究的进展,很多深度模型可以应用于推荐系统领域。Cheng等[12]利用多层感知机设计了一种深广学习(Wide&Deep Learning)模型,通过利用用户特征、情境特征和项目特征等多源异构数据进行收集App推荐,模型具有较高的记忆能力和泛化能力。Covington等[13]通过利用用户信息、情境信息、历史行为数据和项目的特征信息等多源异构数据,提出一种深度神经网络模型用于YouTube视频推荐。此外,还可以利用卷积神经网络进行音乐推荐[14],利用RNN进行新闻推荐[15],利用协同降噪自编码器进行Top-K推荐[16]等。
2 深度协同过滤推荐算法
本节将详细介绍深度协同过滤推荐算法(Deep Learning based Collaborative Filtering,DLCF)。首先给出整体架构,然后进行形式化表示,最后定义损失函数并给出训练方法。
2.1 整体架构
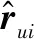
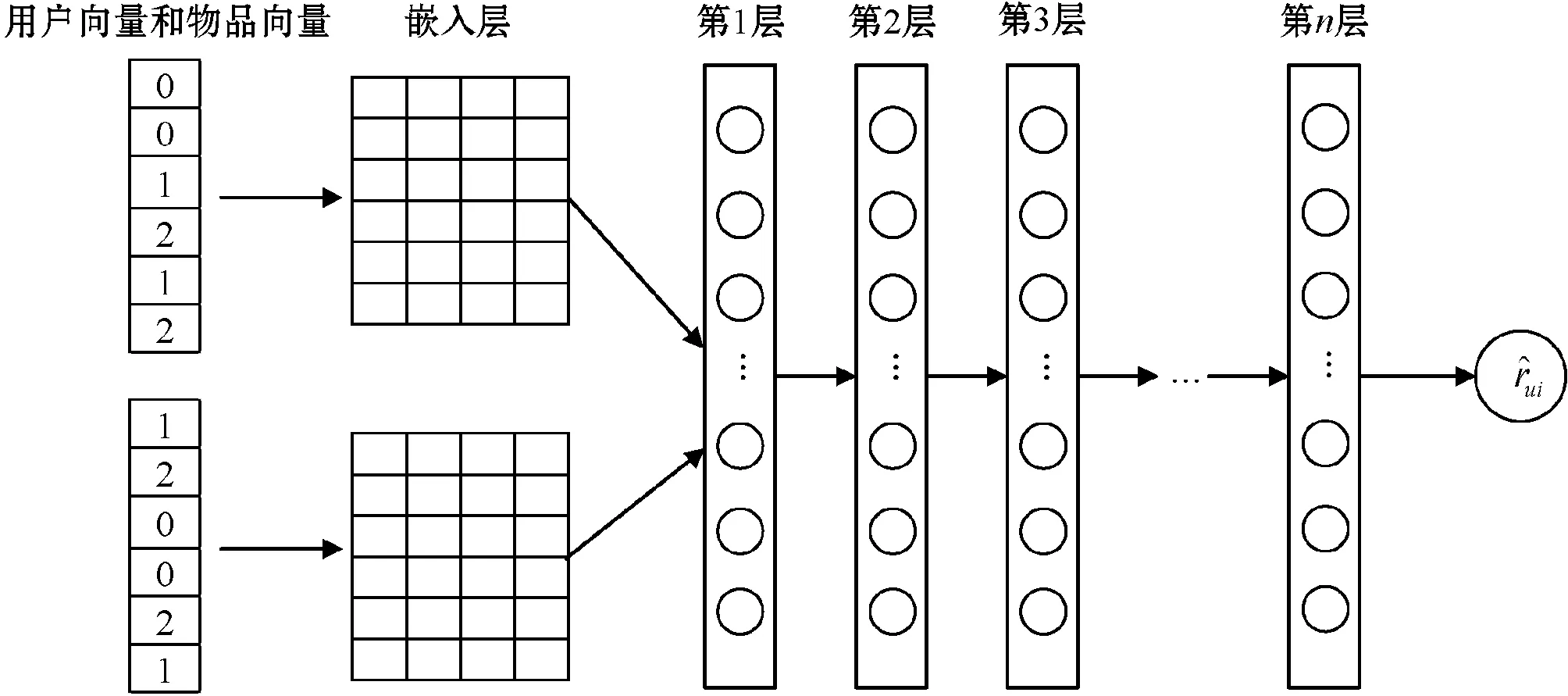
图2 DLCF整体网络架构
首先分别把用户和物品的交互矩阵R转换为用户向量、物品向量和标签向量,其转换过程如图3所示。其中用户向量和物品向量是神经网络的输入,标签值用来和预测值做损失计算。然而由于R是|m|×|n|维的,因此用户向量和物品向量的维度也是|m|×|n|维的,而这个维度过大,从而计算开销过大。为了解决这个问题,本文将采用抽样方法对负例进行抽取,即在R中抽取一定比例为0的值进入训练数据。图4模拟了抽取过程,其负例抽取的比例是正例的2倍。采用这样的抽样方法很好地解决了数据稀疏性所带来的问题。

图3 R转换为用户向量、物品向量和标签向量
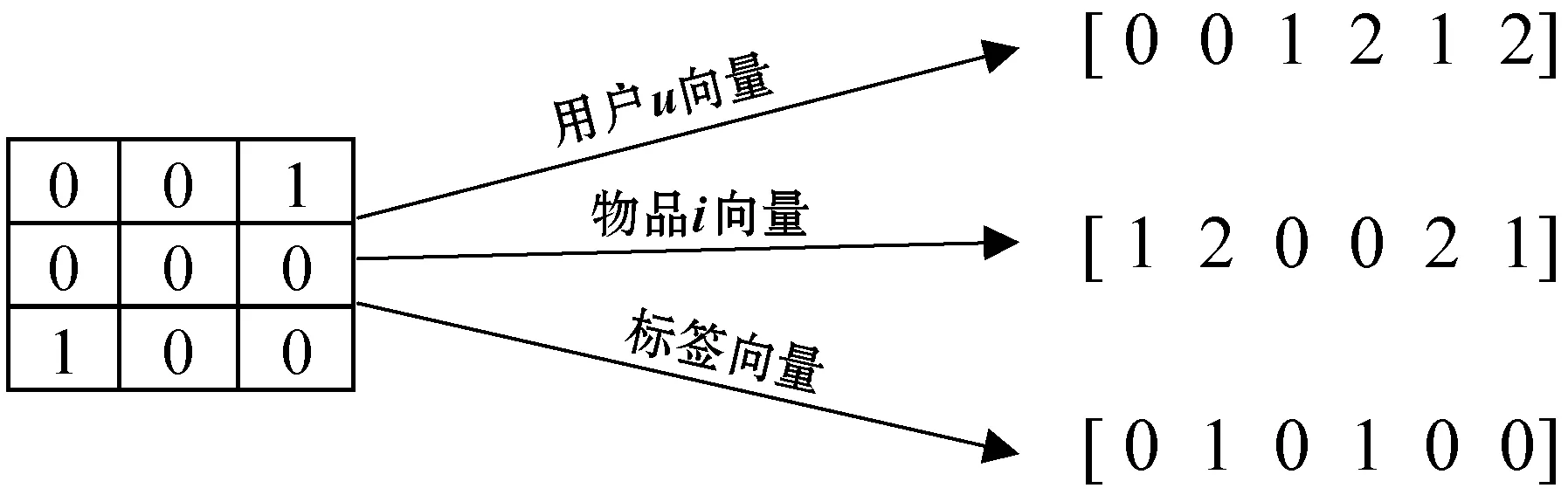
图4 对数据采样,负例数量是正例的2倍
2.2 形式化表示
2.1节所述的网络架构,可以形式化地表示如下:
(2)
式中:P∈Rm×k、Q∈Rn×k分别表示用户隐空间和物品隐空间(对应图2中的嵌入层矩阵);Θ是模型参数,本文使用的是深度神经网络,因此Θ就是各网络层参数。由此f函数可以表示为:
f(Pu,Qi|P,Q,Θ)=gout(gn(…g2g1(wTx+b)))
(3)
式中:gn表示第n层网络;gout表示应用某一激活函数(如Sigmoid)后得到的预测结果。
2.3 模型学习
(4)
式中:R+表示训练数据中的正例(即值为1的数据),R-表示训练数据中的负例(但不是全部,如2.1节所述是按一定比例进行采样)。
定义了损失函数后,就可以形式化地表示本文提出的深度神经网络结构。该架构具有较高的灵活性,通过非线性学习pu和qi的内在交互关系进而得到预测结果:
(5)
式中:wi、bi分别表示第i层的权重、偏置;对于激活函数ai,可以选择Sigmoid函数、tanh函数和ReLU函数。Sigmoid函数存在饱和区问题[17],即在曲线平缓处产生梯度消失问题及当输出值接近0或1时学习停止,从而影响推荐效果。tanh函数虽然可以在一定程度上缓解上述问题,但是无法从根本上避免,因为它可以看作是Sigmoid函数的重新缩放(tanh(x)=2sigmoid(2x)-1)。ReLU函数是一个性能良好的函数并且不存在饱和区问题,因此我们选用ReLU作为激活函数。σ是输出层的激活函数,由于我们的输出结果要映射到[0,1]区间,因此选用Sigmoid函数。
3 实 验
本文使用Keras进行模型编程实现,模型运行在ubuntu系统上。首先通过实验确定模型的超参数,然后再与其他基线算法进行比较分析。
3.1 数据集
本实验使用了两个公开的数据集:MovieLens和Book-Crossing。MovieLens数据集广泛应用于对协同过滤推荐模型的评价,实验中使用的是MovieLens-10m,它包含一百多万的评分数据并且每个用户至少存在20条评分记录。由于它是显式数据集,因此我们需要对其进行预处理,把它转换成隐式数据集,转换方法是对于有评分的项用1表示(无论评多少分),否则用0表示。Book-Crossing数据集是Cai-Nicolas Ziegler博士使用爬虫程序从Book-Crossing图书社区爬取的图书评分数据。由于原始数据很大,并且有的用户对物品的评分数目很少,因此数据非常稀疏。为此首先抽取用户至少存在20条评分记录的数据,然后再把这些数据转换为隐式数据。表1列出了预处理后2个数据集的详细信息。

表1 MovieLens和Book-Crossing数据集详情
3.2 评价指标
为了评价模型性能,使用了十折交叉验证,即把数据分割成10个子集,1个子集被保留作为验证模型的数据,其他9个子集用来训练。交叉验证重复10次,每个子集验证一次,取10次的平均值作为最终的结果。使用命中率(Hit Ratio,HR)和归一化折损累积增益(Normalized Discounted Cumulative Gain,NDCG)作为评价指标。在HR和NDCG后加@K符号表示推荐列表长度是K时(即做Top-K推荐),HR和NDCG的值。HR的计算公式如下:
(6)
式中:分子表示每个用户Top-K列表中出现在测试集中的个数总和,分母表示测试集大小。NDCG的计算公式如下:
(7)
式中:reli表示在第i个位置时的“等级关联性”,一般可以用0/1处理,如果该位置的物品在测试集合中,则reli=1,否则为0。分母是归一化系数,|REL|表示按照相关性从大到小的顺序排序,取前k个组成的集合。
3.3 超参数设置
如2.1节所述,我们在训练阶段需要采样一定的负例,本文采取的方法是在每一轮迭代过程中采样5倍于正例的负例,这些负例和所有正例作为训练数据。使用Adam的优化方法,batch-size设置为256,学习率设置为0.000 4。实验的重点是要确定神经网络的层数,以及每层中神经元的个数,为此我们分别选取3至8层不同网络结构进行实验(固定每层神经元个数都为8),结果如表2所示。
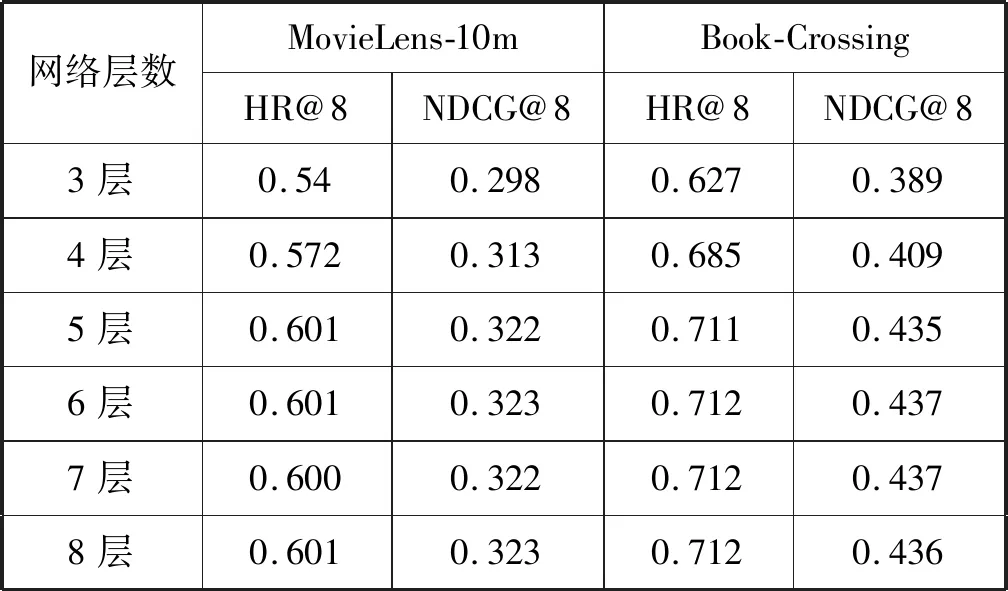
表2 不同网络层数下HR和NDCG值
从表2可以看出,无论是MovieLens-10m还是Book-Crossing数据集,当网络层数从3增长到5时,HR和NDCG值都有明显的增长趋势,此时网络层数的增加有助于推荐效果的提升。当网络层数为7、8时,HR和NDCG不再增加,甚至略有降低,说明无限地增加网络层数并不能无限制地提升推荐效果。当网络层数为6时,虽然HR和NDCG都在增加,但增幅不大。虽然本实验中具有6层网络比具有5层网推荐效果略有提升,但考虑到网络层数越多计算量越大,权衡计算量与推荐效果后,我们把网络层数设置为5。
接下来考虑每个网络层中神经元的个数。大量实验表明,沿着网络正向传播的方向每层神经元个数递减的设置方式有利于性能的提高。给出5种神经元个数不同的设置方法,其结果见表3。[32,16,8,4,2]表示每层神经元的个数分别是32、16、8、4、2,以此类推。
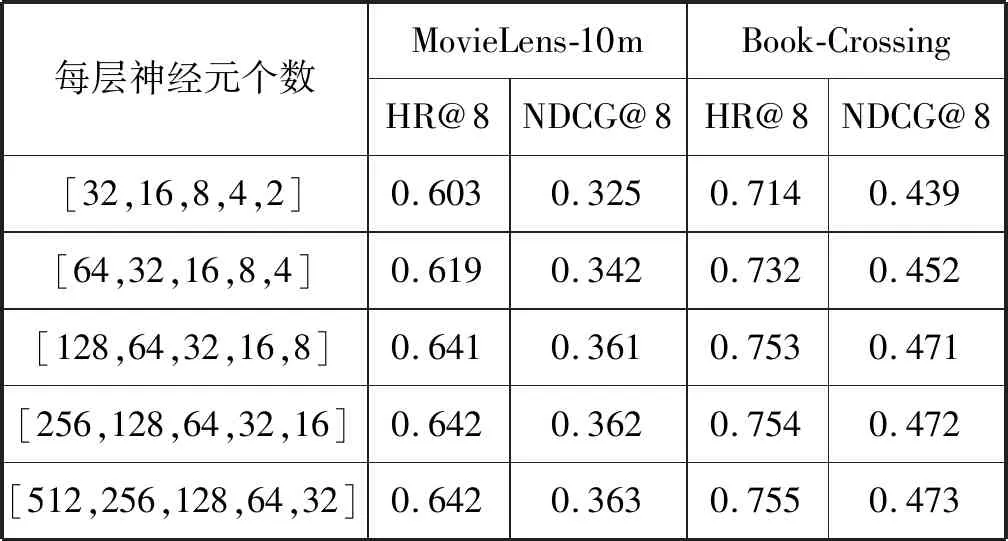
表3 不同神经元个数下HR和NDCG值
从表3中可以看出,随着每层神经元个数的增加,HR和NDCG总体呈上升趋势,但是在神经元为[128,64,32,16,8]后,即使神经元个数增加了,HR和NDCG上升量却不大,但计算开销量却成倍增加。因此权衡计算量与推荐效果后我们选择[128,64,32,16,8]作为每层的神经元个数。
通过上述实验,我们确立了模型超参数,其汇总见表4。后面的对比实验都是基于这些超参数得出的实验结果。

表4 模型超参数汇总
3.4 对比实验
为了验证本文模型的有效性,与以下基线模型进行了对比实验。
(1) Item-based Collaborative Filtering[18]:基于物品的协同过滤模型,该模型目前在工业界有着广泛的应用,也是最早基于协同过滤推荐算法的模型之一。
(2) IRCD-CCS[19]:该模型把深度学习方法和协同过滤方法相结合,使用显式数据解决物品评分问题,其经过显式数据转换为隐式数据后也能用于Top-K推荐。
(3) eALS[20]:一种使用矩阵分解对隐式数据进行建模的方法,该方法根据物品的流行度对缺失数据赋予不同的权重,然后使用加权平方作为损失函数进行训练,取得了良好效果。
图5显示了4种模型分别在2个数据集上HR@K和NDCG@K的值(K取值从1到10)。可以看出,本文模型DLCF无论在哪个数据集上都远好于其他3个模型。这主要是因为基于物品的协同过滤其本质是线性的,无法对复杂的交互进行建模。IRCD-CCS虽然使用SDAE方法进行非线性建模,但相比本文模型其层次不够深,无法深层次地进行特征抽取。本文使用了深度神经网络,能够更好地进行深度建模,取得良好的推荐效果。

(a) MovieLens-10M HR@K
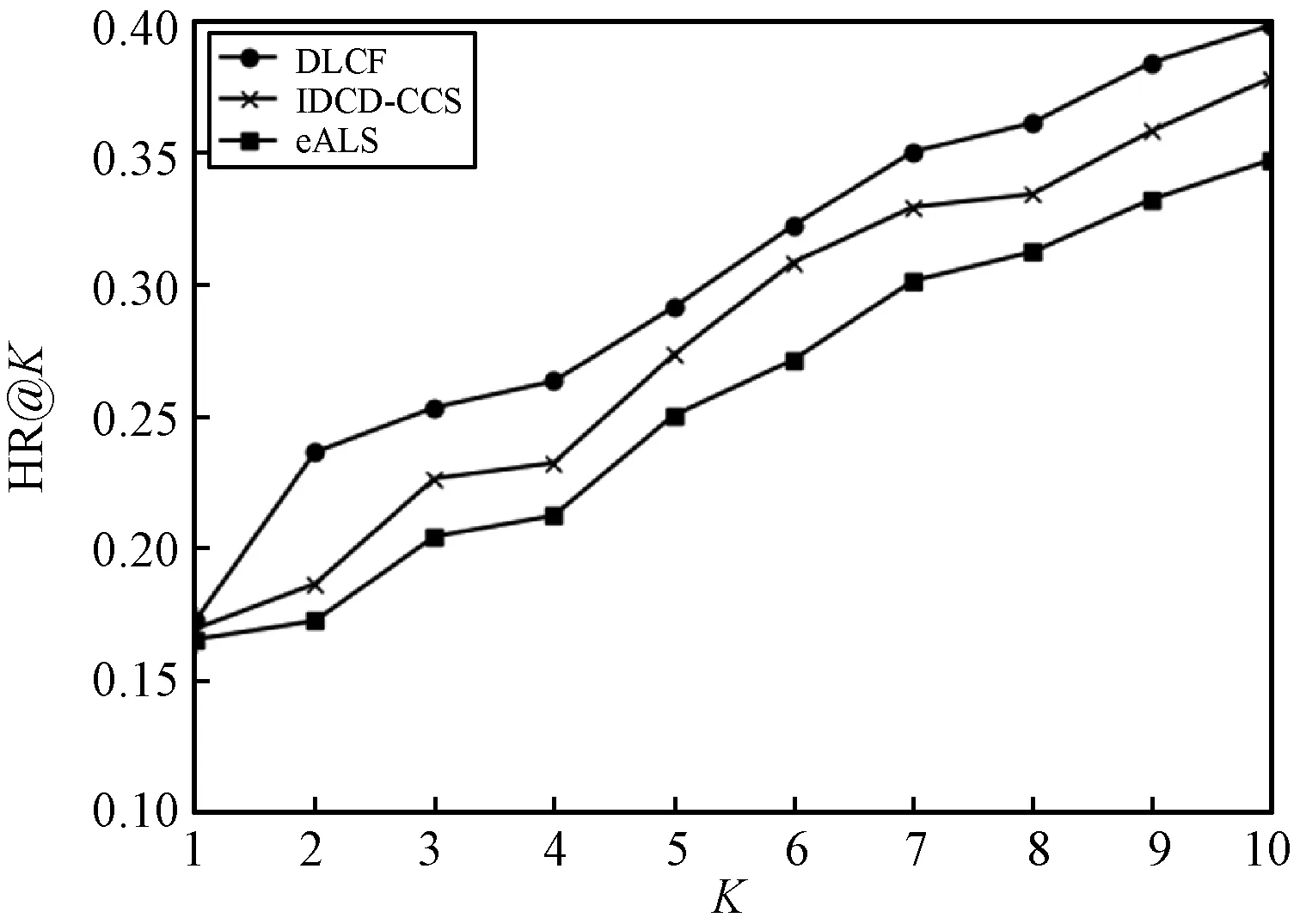
(b) MovieLens-10M NDCG@K
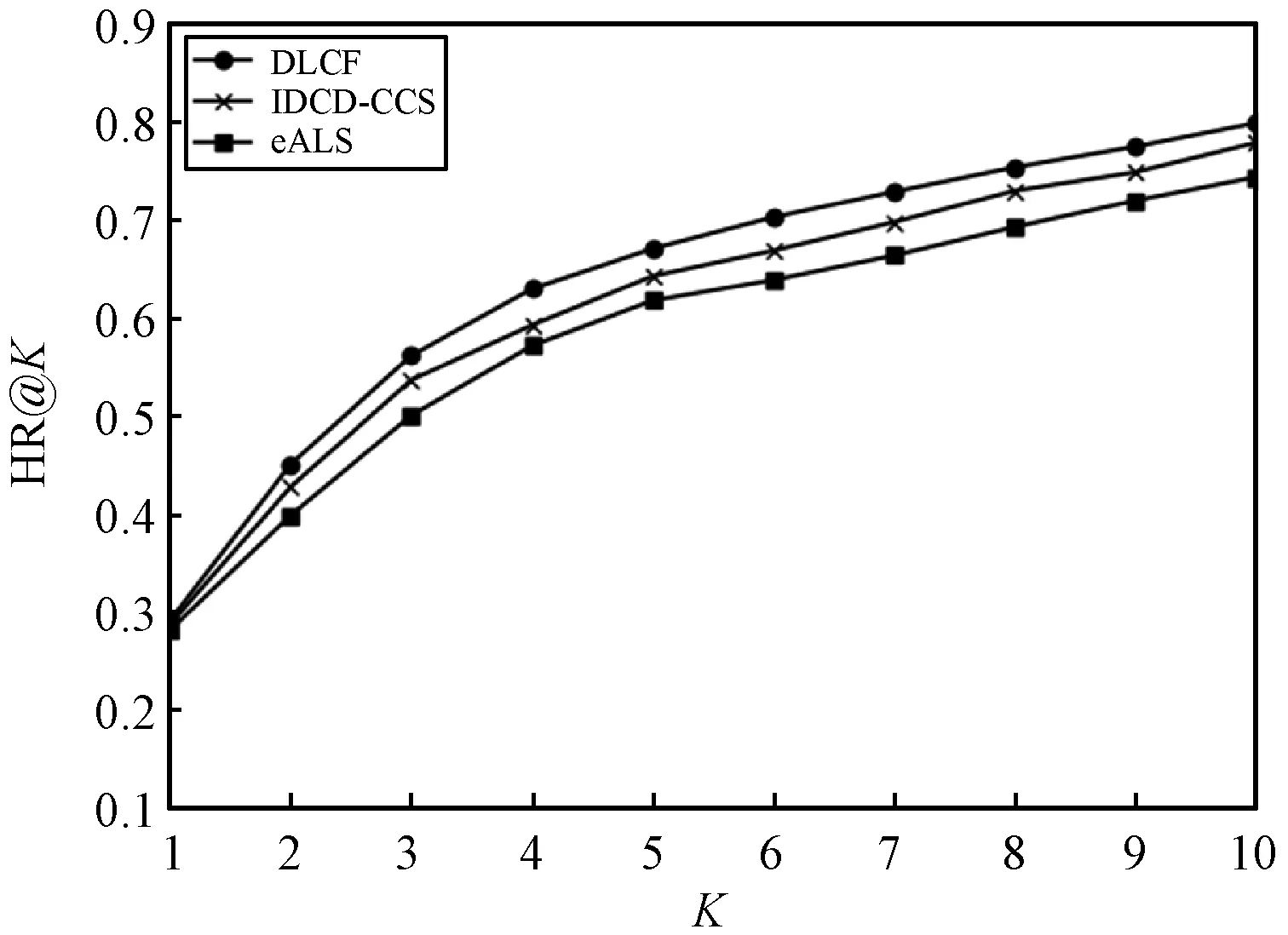
(c) Book-Crossing HR@K
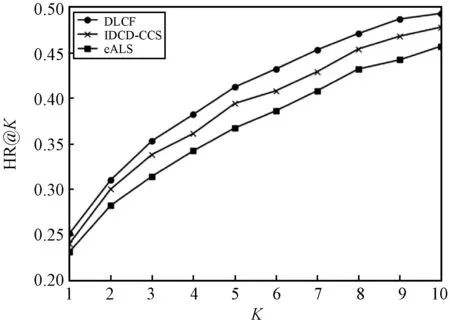
(d) Book-Crossing NDCG@K图5 当K从1到10时模型在2个数据集上HR和NDCG值
4 结 语
本文把深度学习技术与协同过滤推荐算法进行了结合,设计了使用深度神经网络的协同过滤推荐模型,该模型能够深度地非线性学习用户和物品间的内在联系,从而产生较好的推荐结果。下一步将继续关注深度学习在推荐系统中的应用,把物品的属性特征(如:描述、评论、标签等)通过深度学习技术学习后作为输入特征引入到推荐模型中来,从而产生更好的推荐结果。
