克服小样本学习中灾难性遗忘方法研究
2020-07-13李文煜帅仁俊
李文煜 帅仁俊 郭 汉
(南京工业大学计算机科学与技术学院 江苏 南京 211816)
0 引 言
在将深度学习应用于更多实际问题的过程中,通常都会面临着样本数量不足的问题[1]。一般基于神经网络的图像分类方法耗费了极大的计算资源,消耗了大量的时间,海量的标记数据需要专业人员花费大量的精力、物力。基于这些原因,小样本学习成为一种有效降低数据成本的方法。小样本学习就是从少量样本中学习。以分类问题为例,每个类只有一幅或者是几幅样本作为训练集。人类是具有小样本学习能力的[2],如:给孩子们看一幅斑马的图片,再让他们从很多动物中选出斑马是没有问题的。但是传统的深度学习方法在每个类别的样本很少的情况下,并不能很好地处理这个问题。
神经网络是一种类似于人类大脑神经突出联接的结构进行信息处理的模型,它以一定的学习准则进行学习,但不具备记忆的能力。与人工神经网络形成鲜明对比的是人类和动物,哺乳动物的神经元之间具有突触,这能够保护先前学习到的知识不被遗忘。灾难性遗忘是指一旦神经网络学习了一种新的任务,就会遗忘之前学习的内容[3]。同一个神经网络为了学习新的任务,会通过改变权重使其越来越适应新的任务。根本原因是因为不同数据集的图像特征权重不同。当神经网络完成了新任务的学习,它对新任务会有很好的表现,但是对于之前学习过的任务,精度会大大降低。
微生物分类[4]在计算机领域的研究还面临诸多挑战,如像素图像数量严重不足,且需要大量的专业知识等。将小样本图像分类应用于微生物像素级的图像分类,只需少量的训练样本就能识别,从而大大降低分类成本。
针对上述问题,本文研究了小样本学习中克服灾难性遗忘的方法。通过最小化基于皮尔森相似度的CNN模型的分类损失[5],实现小样本分类;使用注意力机制设计了小样本分类权重生成器[6],使得新类的权重基于基类的权重,即将神经网络之前学习的内容运用到新的内容中,从而克服灾难性遗忘。
1 相关工作
目前有很多学者在小样本学习和灾难性遗忘方面进行研究。Snell等[7]提出了一种基于原型网络的小样本学习方法,原型网络通过学习一个度量空间,计算每个类的原型表示的距离从而执行分类。与其他研究小样本学习方法相比,原型网络提出了一种更加简单的归纳偏差,这种归纳偏差能够在有限的数据中取得较好的效果。文献[8]使用了布雷格曼散度来计算测试样例与原型之间的距离,相比欧几里得更有效。但是这种方法只能在特定的数据集上产生较好的效果。Vinyals等[9]提出了使用匹配网络进行小样本学习,使用加权平均的方法计算权重值,可实现快速学习,训练过程基于简单的机器学习规则:测试和训练条件相匹配。但是随着数据量的增多,计算开销会成倍地增加。Kirkpatrick等[10]提出了弹性权重固化算法,它是一种类似于人工神经网络突触固化的算法。当存在要学习的新任务时,网络参数通过先验进行调节,该先验来自先前学习过的任务,可以快速调节对新任务不重要的参数,而对于那些重要的参数改变的速度较慢。将小样本学习与解决灾难性遗忘相结合,可以得到效果更好的图片分类结果。Luo等[11]使用ANN训练SVM分类器,提出了两个新特征HOG和滤波强度,并通过实验表明这两种特征在水生病原体微生物数据集上是最具表现力的特征。该方法在相关数据集上具有针对性,取得了较高的准确率,但泛化性不好。
本文主要贡献如下:
1) 首次将注意力机制用于图片特征权重的生成,成功地使新类权重的生成基于基类权重,使神经网络不忘记训练的基类别,优化了性能。
2) 首次将皮尔森相似度用于特征表示与分类权重之间的相似程度计算,计算效果更好。
3) 在环境微生物(EMDS)数据集上的图像分类准确度超过了先前的方法。
2 理论基础和实验架构
2.1 符号说明
假设数据集N,训练集中样本的类别称为基类Nbase,测试集中样本的类别称为新类Nnovel,Nbase∩Nnovel=Φ,Nbase∪Nnovel=N。
(1)
式中:B表示Nbase中类别的总数;b表示第b类;Ib表示第b类样本的总数。
(2)
式中:N表示Nnovel中类别的总数;n表示第n类;In表示第n类样本的总数。对于输入的新类每个类别都只有少量的训练样本。
所有图像经过CNN提取的特征为H对应的权重集合为W,基类经过提取的特征为Hb(不包括新类的训练样本)对应的权重集合为Wb。在测试新类时,首先需要少量的新类样本作为训练集,其经过提取的特征为Hn,对应的权重集合为Wn。将Hb与Hn合成为一个集合Ht(对应的权重集合为Wt)代表所有训练样本的特征集合,用hj表示新类测试样本的特征集合。
2.2 注意力机制
本文将注意力机制与CNN识别模型相结合,能实现新类权重的生成基于基类权重。即允许程序间非常缓慢地、渐进地改变,总是保留学习新任务的空间,同时这种改变不会覆盖之前学习到的内容。注意力机制就是指有选择性地关注所有信息重要的那部分,同时忽略相对不重要的那部分信息。例如,人们在看视频时,只会关注画面中少量的重要信息,而不是每一帧都看得十分仔细。将注意力机制运用于新类权重的生成,实现了将先前学习的知识用于新任务的目标。
本文使用的注意力机制依赖于Encoder-Decoder框架[12],可以理解为“编码、存储、解码”这一流程,原始的Encoder-Decoder框架如图1所示。
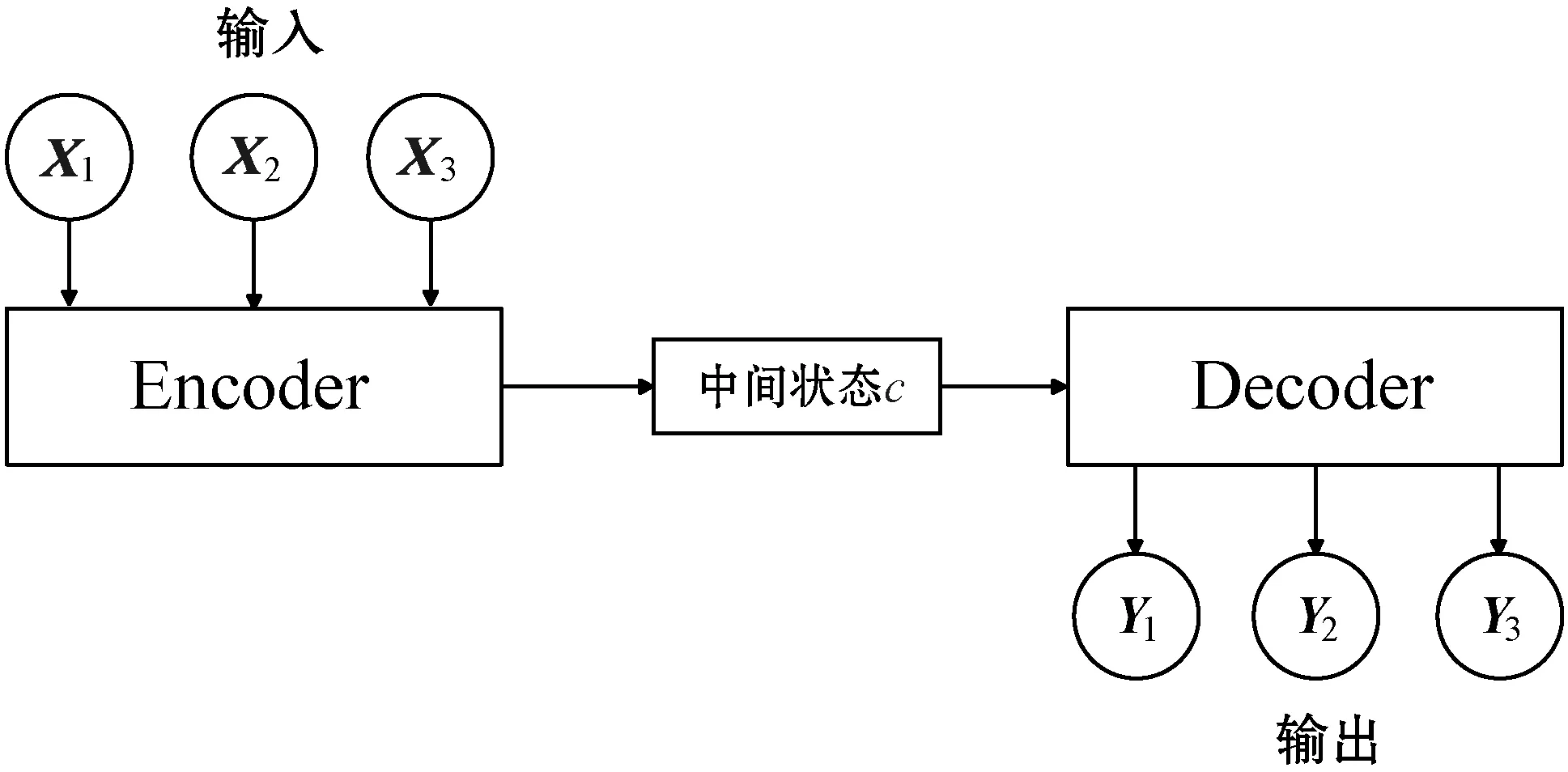
图1 原始的Encoder-Decoder框架图
对于图像分类Encoder-Decoder框架流程如下:
1) 输入图片的特征向量X,对其进行编码;
2) Encoder输出的中间状态c作为Decoder的输入;
3) Decoder输出解码后的内容。
由于单一的Encoder-Decoder框架并不能选择性地学习,也不能体现先前重要的特征对新类别的影响,所以在其基础上引入了注意力模型[13]。原理如图2所示。

图2 注意力机制模型原理图
图2中:X表示图像的输入值,CNN表示图像经过卷积神经网络提取特征,h表示经过特征提取后的特征,α表示权重,下标t,T表示第t时刻的第T个权重,S表示经过Decoder的输出状态,St表示第t时刻的输出状态,Y表示图片的标签即类型。
可以看出,经过注意力模型,在前一层的输出中使用权重筛选出和上下文相关的一部分,再采用加权平均的方法进行计算,将其结果作为模型的输出,这个输出又作为下一层的输入,从而让下一层关注于局部信息。注意力机制模型很好地继承了学习过的内容,即第t时刻的状态取决于本身的特征值和先前学习的状态。
2.3 实验架构
整体实验设计原理如图3所示,其描述了权重的迭代更新过程。
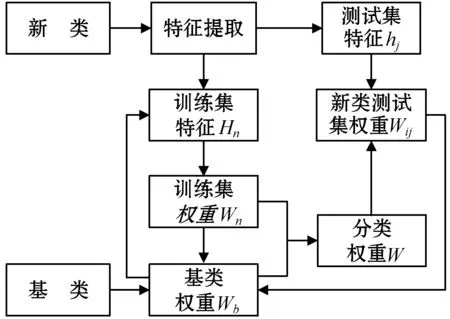
图3 实验设计原理图
克服灾难性遗忘的小样本图像分类算法的步骤如下:
1) 对基类提取特征,并生成基类权重集合Wb;
2) 对新类的测试集提取特征结合基类权重,通过小样本权重生成器生成训练集权重集合Wn;
3) 新类训练集权重集合Wn与基类权重集合Wb构成分类权重集合W;
受构造运动的影响,区内断裂构造相当发育,成群成带出现,主要有NE向、NW向等多组。其中NE向、NW向断裂是本区构造的主体,规模较大,切割较深,是控矿的主导性构造。
4) 新类测试集特征hj与分类权重集合W通过注意力机制小样本权重生成器,生成测试集权重Wij;
5) 新类的测试集权重作为学到的知识,将其保存到基类权重中,为下一次学习新类提供参考。
将基于注意力机制的小样本权重生成器与基于皮尔森相似度的CNN识别模型相结合,实现了小样本的快速学习。
3 方法实现
3.1 基于注意力机制的小样本权重生成器
为了能将学习过的知识运用到新类中,本文提出一种基于注意力机制的小样本权重分类器。使用注意力机制保留先前学习到的重要权重。
图2中,加号以下是编码器,编码器将输入向量X={x1,x2,…,xT}提取特征向量hj,再转换为中间状态c,由特征向量的加权和计算得出:
(3)
式中:αij表示第i个类别的第j个分量的权重;hj表示特征向量。中间状态c是引入注意力机制的关键所在,作用是将输出与相关输入联系起来。权重αij与上一个状态Si-1和新类的特征向量hj有关。
(4)
权重αij能够识别输入中的哪些特征与当前的输出关系比较大,可将αij理解为一个归一化的概率值,表示输入的第j个特征对当前输出的关系概率。eij的计算如下:
eij=a(Si-1,hj)
(5)
式中:a是一个对齐模型,对第i个输出与第j个输入的匹配程度进行打分,它由一个前馈神经网络实现,在训练时一起被训练。Si的计算如下:
Si=f(Si-1,Yi-1,ci)
(6)
即当神经网络预测新类时,根据上一个状态Si-1、输出Yi-1以及中间状态ci进行的。这是一个迭代循环的过程。
同时也可用求平均值的方法计算分类权重:
(7)
最终分类权重向量是基于平均分类向量和基于注意力分类向量的加权和:
(8)
式中:δ*和δ都是可学习的向量。使用平均分类向量和注意力分类向量的线性组合能有效地改善性能。
3.2 基于皮尔森相似度的识别模型
皮尔森相似度用于计算两个变量之间的相关程度,其值在-1与1之间。若值大于0则表明两者是正相关,且越接近1相关性越强;若值小于0则表明两者是负相关,且越接近-1相关性越弱;若值为0则表明两者不存在相关关系。
本文将皮尔森相似度用于判别特征表示与分类权重之间的相似性程度。上述基于注意力机制的分类权重生成器为新类生成了一组分类权重向量Wij,Wij∈Wn,对应的特征向量为hj,hj∈Hn。新类与先前学习过的基类的皮尔森相似度为:
(9)
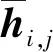
(10)
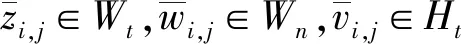
4 实 验
4.1 实验环境
实验开发环境为Python 3,使用Pytorch作为主要的机器学习框架,处理器为i5 8600K,内存32 GB,2 TB机械硬盘,同时使用NVIDIA GTX1080Ti来实现GPU加速训练。
4.2 实验数据
本文使用了三种数据集进行实验,数据集Omniglot和Mini-ImageNet用于训练网络并作为实验对比数据,环境微生物数据集(EMDS)作为应用数据集。Omniglot数据集包含来自50个不同字母的1 623个不同手写字符,每个类别有20个样本,其中30个类用于测试集,20个类用于测试集,将图像大小调整为28×28,并将图片旋转90度作为新样本以扩充样本集。MiniImagenet数据集由48 000幅来自Imagenet数据集的图片组成,这是一个有标签的图像数据集,一共有100个类,每个类有600个样本,其中80个类作为训练集,20个类作为测试集。EMDS数据集包含20类微生物像素级图像,用ωi(1≤i≤20)表示,每个EM类有20幅图像,共有400幅图像,其中16个类作为训练集,4个类作为测试集。
4.3 图像预处理
由于EM图像中的大多数区域是背景,需要先对图像进行预处理,即提取特征图,获得像素级图像中的主体部分,用于小样本的分类。由于VGG-16使用了3个3×3卷积核来代替7×7卷积核,在提升网络深度的同时减少了参数的数量,更适合EMDS数据集,所以采用VGG-16模型来实现。提取倒数第二个卷积层上的1 024幅特征图,将其双线性插值到原始图像大小,再对经过处理后的图像进行小样本分类。其经过特征提取后的特征图如图4所示。

ω1 Actionphrys ω2 Arcella ω3 Aspidisca

ω4 Codosiga ω5 Colpoda ω6 Epistylis

ω7 Euglypha ω8 Paramecium ω9 Rotifera

ω10 Vorticella ω11 Noctiluca ω12 Ceratium

ω13 Stentor ω14 Siprostomum ω15 K.Quadrala

ω16 Euglena ω17 Gonyaulax ω18 Phacus

ω19 Stylonychia ω20 Synchaeta图4 EMDS中每个类的特征示例图
4.4 实验及结果分析
本文使用卷积神经网络对Omniglot和Mini-ImageNet数据集进行图像特征的提取,并用皮尔森相似度识别模型对图像分类。其中包括4个卷积块,每个卷积块都有3×3的卷积核,再进行批量标准化操作,经过ReLU函数激活后通过2×2最大池化层,得到特征矩阵。设置batch_size为8,epoch_size为8 000,学习率为0.1。
实验结果以图像分类准确率为评价指标对本文方法进行评估。考虑了在5-way 1-shot和5-way 5-shot(5-way表示测试集有5个类,5-shot表示每个类的测试集只选取5个样本)这两种情况下,遗忘前的准确率和遗忘后的准确率的分类精确度(95%置信区间)。
实验将Omniglot和Mini-ImageNet数据集作为基类,EMDS数据集作为新类。使用Omniglot和Mini-ImageNet的训练集来训练网络模型,再通过其测试集观察网络性能,得到图像分类的准确率,即遗忘前的准确率。通过上述的模型训练EMDS数据集中的训练集,将其应用到对应的测试集中。此时经过EMDS训练的网络调整了自身的权重,更加拟合EMDS中的图像。重新测试Omniglot和Mini-ImageNet数据集中的测试集,得到图像分类的准确率,即遗忘后的准确率。与原型网络(Proto network)、匹配网络(Match network)、基于领域分量分析(NCA)[14]、MAML[15]以及Neural Statistician(NS)[16]方法的实验结果进行了对比,如表1、表2所示。可以看出,应用本文提出的克服灾难性遗忘的小样本学习方法,即使EMDS数据集中的样本数量很少,但是仍可以在其测试集上取得较高的分类准确度。
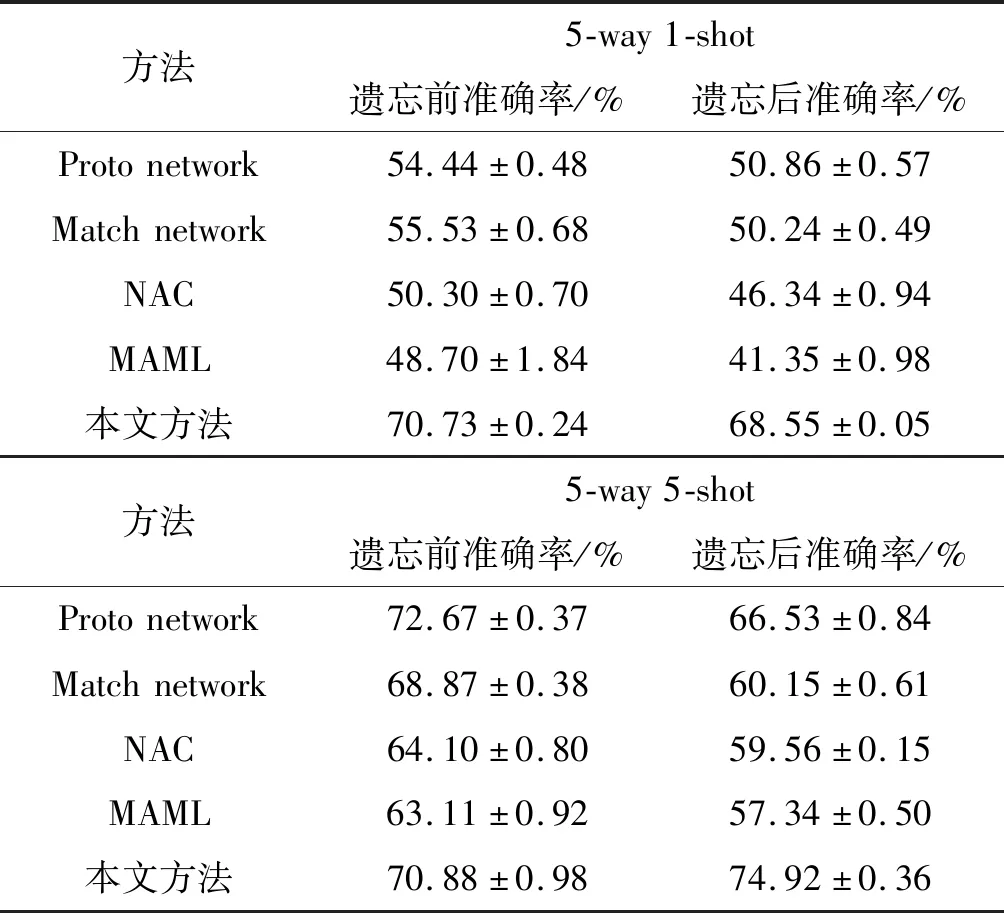
表2 MiniImagenet数据集不同方法实验结果对比表
表1是Omniglot数据集上的实验结果。可以看出在训练EMDS数据集之前,基于原型网络、匹配网络、Neural Statistician、MAML方法的实验结果精度都能达到97%以上,在5-way 5-shot的条件下精度甚至能达到99%以上。然而在经过EMDS的小样本学习之后,各个方法的准确度出现了明显下降。本文方法遗忘后的准确率并没有下降,甚至在5-way 1-shot的条件下,遗忘后的准确率高于遗忘前的准确率。原因在于注意力机制结合了训练数据集与新样本的特征,通过小样本学习新数据集,神经网络并不会遗忘之前学习的“经验”。
表2是Mini-ImageNet数据集上的实验结果。根据表2所示,在训练新样本之前,基于原型网络、匹配网络、NCA、MAML方法的实验结果在5-way 1-shot条件下准确率最高,为54.44%,且在5-way 1-shot和5-way 5-shot这两种情况下遗忘后的精度都低于遗忘前的精度,平均下降了6%,表明先前的方法为了在新类上取得更好的效果,一定程度上舍弃了已经学习到的知识。这是由于原型网络在学习新的类别时,通过改变网络的参数使网络更适合新类的分类,而没有考虑到网络是否适合基类。而本文方法是基于注意力机制来生成权重,新类权重的生成基于先前学习过的知识,能够保证适用于新类的参数同样适合基类,从而在基类上也有很好的表现。可以看出,本文方法在Mini-ImageNet数据集上达到了70%以上的精确度,即使在新样本训练后,准确度仍高于其他方法。
基于原型网络、匹配网络、NCA、MAML方法在5-way 5-shot条件下对新类分类准确度如图5所示。本文方法在5-way 5-shot条件下,对新类的分类准确率达到了70%,高于其他方法,并且新类的分类准确率没有降低,达到74%。从中可以更直观地看出,本文方法与其他方法相比具有更高的精确度,且克服了灾难性遗忘问题。
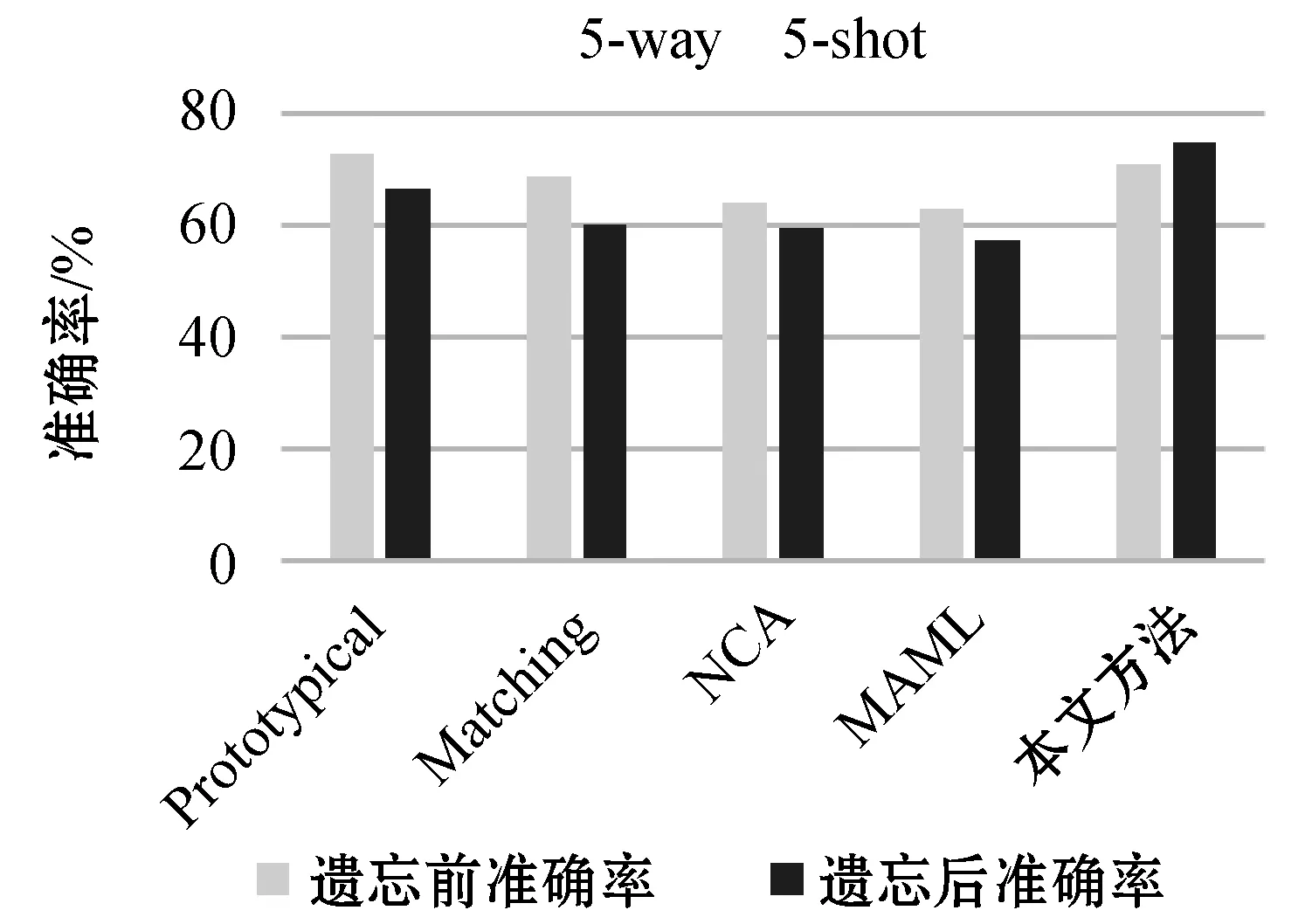
图5 5-way 5-shot不同方法实验准确度图
EMDS数据集不同方法实验结果对比如表3所示,通过应用训练好的模型,采用本文提出的方法,准确度达到了76%,普遍高于其他方法。并且相比5-way 1-shot,在5-way 5-shot条件下,实验准确度得到了明显的提升。由此得出以下结论:本文方法在分类精度方面明显优于其他方法。通过不断地训练新数据,实验准确度随样本的增加而增高,并且再重新测试基类数据时不会出现灾难性遗忘问题。
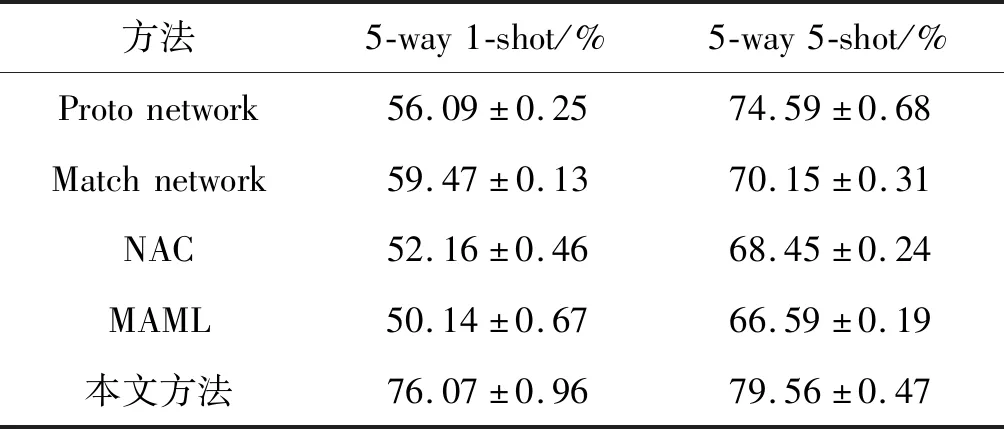
表3 EMDS数据集不同方法实验结果对比表
本文方法在一定程度上提高了网络的性能,原因是网络在学习新类时只需要1个或是5个样本,大大减少了训练时间。由于运用了基于注意力机制的小样本权重生成器,新类的分类结果并没有因为训练样本的减少而降低分类准确度,且新样本权重的生成基于基类,所以网络在学习了不同分布的数据之后,对之前学习的数据仍有较高的分类准确度。本文方法具有更好的鲁棒性,泛化能力更突出,为小样本学习提供了一个较好的解决方案。
5 结 语
本文提出了一种克服灾难性遗忘的小样本学习方法,设计了基于注意力机制的小样本权重生成器,用基于皮尔森相似度的CNN识别模型进行分类。将注意力机制运用于新类权重的生成,有效地解决了灾难性遗忘问题,使新类权重的生成基于基类的权重。并与不同的方法通过实验对比图片分类准确度,结果表明:本文方法在相同的数据集上有更好的分类效果,并且在提高新类分类准确度的同时,没有牺牲基类的分类准确度。下一步的工作是使用元学习的方法结合注意力机制生成分类权重,进一步提高图像分类准确度。
