基于改进ZS细化算法的手写体汉字骨架提取
2020-07-13常庆贺吴敏华骆力明
常庆贺 吴敏华 骆力明
(首都师范大学信息工程学院 北京 100048)
0 引 言
手写体汉字识别是模式识别的重要分支,也是文字识别领域最为困难的问题之一。细化是手写体汉字识别与处理中的一个重要环节,其又可称为骨架化,一般是指在保持图像原像素拓扑链接关系的前提下,接连删除图像边缘像素直至达到单个像素宽度骨架的过程。图像细化所提取出的骨架不仅是目标图像重要的拓扑描述,还减少了图像中的冗余信息,在图像分析、信息压缩、特征提取、模式识别等领域具有非常广泛的应用[1-2]。
现有的细化算法有:Hilditch细化算法[3]、Pavlidis细化算法[4]、基于索引表的细化算法[5]、基于Voronoi图的构造模型细化算法[6-7]、基于轮廓筛减的细化算法[8]、Zhang-Suen细化算法[9-10]等。在应用于细化手写体汉字图像时,由于汉字结构较复杂,加之手写体汉字书写风格随意,Hilditch算法提取的骨架有扭曲变形的现象,且算法需反复对汉字图像迭代处理,耗时较长。Pavlidis算法通过并行和串行混合的方式提取骨架,但骨架存在较多冗余像素,难于排除撇、捺以及T行交叉点的畸变并易出现断点的现象。基于索引表的细化算法根据预定的规则建立索引表,按照行列顺序比较的形式提取骨架,细化速度非常快,但细化受限于索引表,骨架存在较多毛刺,笔画交叉处和拐角处有畸变。基于Voronoi图细化算法需将图像拟合成多边形,利用多边形的边界特征获取Voronoi图进而提取骨架,但对于二值图像,边界拟合、直线求交比较复杂且计算量较大。基于轮廓筛减的细化算法需预先检测图像轮廓,再对轮廓范围内的图像提取骨架,对图像噪声较为敏感,不适用于复杂图像的处理。Zhang-Suen细化算法通过逻辑运算的方式循环删除图像中的非骨架像素点提取骨架,具有迭代少、速度快,保证提取出的汉字骨架中直线、T行交叉和拐角与原图像一致的特点[11],但存在骨架毛刺,骨架斜线区域易出现像素冗余。
本文针对Zhang-Suen细化算法提取手写体汉字图像骨架时出现的问题做出改进。引入消除模板消除骨架冗余像素;引入保留模板避免因过度消除冗余像素造成的骨架断裂;根据毛刺的特点引进门限长度机制[11]消除多余的毛刺。改进后算法所提取的汉字骨架较平滑,无毛刺和冗余像素,能够完整、正确地突出手写体汉字的特征。
1 算法研究
手写体汉字识别中,汉字的结构信息集中体现在汉字骨架中,对手写体汉字细化,有利于突出字体形态特征,减少汉字图像的数据存储空间,进而提高识别效率。细化算法对文字细化效果的优劣直接影响字体识别的准确率。细化算法一般需满足以下要求[12-13]:
1) 连续性:保持原有笔画的连续性,不能出现笔画断裂的现象。
2) 中轴性:骨架应尽量是原手写字体笔画的中心线。
3) 拓扑性:要保持原手写字体的特征结构,即细节特征、曲线端点等。
4) 保持性:保持笔画交叉点特征,避免畸变。
5) 细化性:字体骨架应细化为宽度为1 bit的单线,即单像素宽。
6) 快速性:算法简单,执行速度快。
细化算法根据是否使用了迭代计算,分为迭代细化算法和非迭代细化算法[14]。非迭代细化算法不以像素为基础,通过一次遍历的形式生成中值或中心线,进而一次性抽取骨架,这种算法处理速度快但容易产生噪声块。迭代细化算法则是通过固定顺序反复检测并删除图像中符合条件的像素,直至得到1 bit宽的图像骨架。根据像素检测所使用的不同方法,迭代算法又可分为串行细化算法和并行细化算法。串行细化算法在第n次迭代的过程中是否删除目标像素点与前n-1次迭代结果和第n次所检测的像素情况相关;并行细化算法在第n次迭代的过程中是否删除目标像素点只与n-1次迭代结果相关。
串行算法对手写体汉字图像的细化结果依赖于对像素处理的先后顺序,像素点的消除或保留不可预测,并行算法细化时利用相同的预定条件检测图像中的全部像素点,其细化结果具有各向同性,且并行细化算法具有快速而准确的特性,一直是人们研究的热点[15]。
2 算法思想
2.1 基本概念
设G为二值图像,P0是图像G中任意一个值为1目标像素点。
定义18-邻域:与P0相邻的八个邻域所组成的像素点集合S={P1,P2,P3,P4,P5,P6,P7,P8}称为像素点P0的8-邻域,如图1所示。
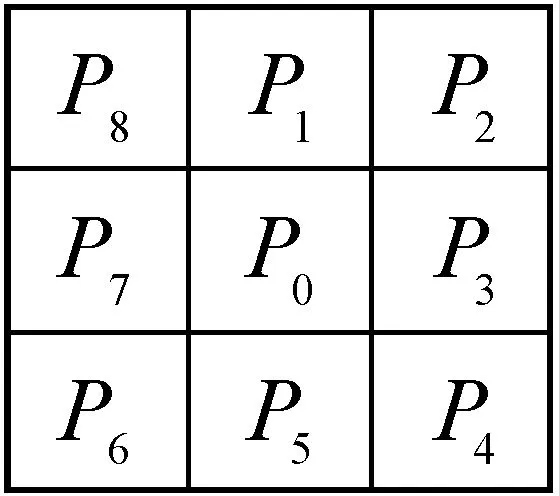
图1 目标像素点的8-邻域


图2 目标像素点的16-环域
定义3前景点和背景点:二值图像中值为1的像素点为前景点,值为0的像素点为背景点。
定义4P0的连接数:与P0相邻的8-邻域中前景像素点的个数记为N(P0),与P0相邻的16-环域中前景像素点的个数记为M(P0)。
(1)
(2)
定义5P0的交叉数:在与P0相邻的8-邻域中以顺时针为序转一圈,像素点从背景点变化到前景点的总次数和,记为:
(3)
定义6端点end[16]:若P0的8-邻域内只有一个骨架点像素并且P0本身就是骨架点,称P0为端点。记为:
(4)
式中:count为当前像素点P0的8-邻域内骨架点总数。
定义7节点node[16]:若P0的8-邻域内存在两个或更多骨架点像素,称P0为节点。记为:
(5)
式中:count为当前像素点P0的8-邻域内骨架点总数。
定义8生长点grow[17]:若P0的8-邻域内存在三个或更多骨架点像素,并为毛刺起点,称P0为生长点,其属于节点的一种。记为:
(6)
式中:change为当前像素点P0的8-邻域内由骨架点到背景点的变化次数。
定义9步长:以像素为单位,单一像素宽度骨架分支所具有的所有像素点个数。
定义10毛刺:骨架由于噪声的影响出现不能反映目标结构信息的分支。结合细化的迭代次数得出对于毛刺的判定阈值[18]为:
(7)
式中:L是毛刺长度;ceil表示取大于等于括号内的最小整数;times为图像细化迭代的次数。
2.2 算法定义
Zhang-Suen算法是典型的迭代、并行细化算法,细化对象是二值图像,具有速度快,能精确的保持原图像直线、T型交叉和拐角的特点。Zhang-Suen算法根据8-邻域的情况重复执行逻辑运算,当符合非骨架点的删除条件时,对像素进行标记,在遍历完全部图像点阵之后再统一执行删除操作。算法分为两个子过程,细化过程如下:
子过程1若同时满足以下4个条件,则标记P0为可删除的点。
1) 2≤N(P0)≤6
2)N(P0)=1
3)P1×P3×P5=0
4)P3×P5×P7=0
条件1判断P0是否为端点,如果P0仅有一个邻点,则为端点,不能被标记;如果P0有七个邻点,为保证骨架的连通性,不能被标记。条件2检测P0的8-邻域是否有0到1之间的变化,以保证骨架像素点不被标记。条件3标记8-邻域东南边的非骨架像素点。条件4标记8-邻域西北角的非骨架像素点。
子过程2若同时满足以下四个条件,则标记P0为可删除的点。
1) 2≤N(P0)≤6
2)N(P0)=1
3)P1×P5×P7=0
4)P1×P3×P7=0
条件1、条件2同子过程1。条件3标记8-邻域西北边的非骨架像素点。条件4标记8-邻域东南角的非骨架像素点。
算法重复迭代上述两个子过程,对手写体汉字图像中的非骨架像素点进行标记。在迭代过程中检测是否有被标记的点,若有则继续重复进行迭代过程;反之则删除所有被标记的点,细化算法结束。此时剩下的点所构成的区域即为骨架。
2.3 改进算法
Zhang-Suen算法对手写体汉字图像进行细化,发现细化所提取的文字骨架普遍存在冗余像素以及骨架毛刺的现象。本文在分析手写汉字结构特点的基础上,发现细化不完全的冗余像素常见于手写体汉字骨架的斜线区域,如图3所示。由于汉字书写的随意性较大,书写时所用纸张的不同,在手写体汉字骨架的笔画边界处易产生骨架毛刺,如图4所示。为保证细化后手写体汉字骨架的细化性和拓扑性,需要对Zhang-Suen算法的结构元素做消除骨架冗余像素和骨架毛刺的改进。

(a) 像素冗余图 (b) 部分斜线区域放大图图3 斜线区域冗余像素图

(a) 像素毛刺图 (b) 部分边界区域放大图图4 边界处骨架毛刺图
2.3.1消除冗余像素
分析Zhang-Suen细化算法的原理,发现造成手写体汉字骨架非单一像素宽的主要原因为图像中部分像素点不满足N(P0)=1而未被标记删除。为了消除图像冗余,保证文字骨架的细化性,本文提出消除模板,如图5所示。消除模板可以较好地删除手写体汉字骨架斜线区域的非骨架像素点。
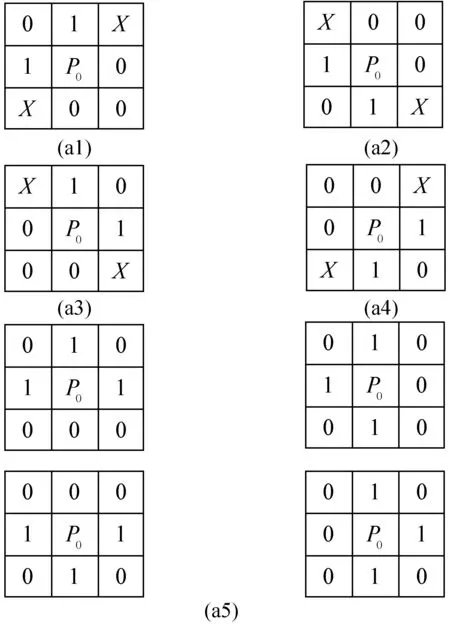
图5 消除模板
图5消除模板中P0满足的5个条件为:
a1 (P1×P7=1)&&(P3+P4+P5+P8=0)
a2 (P5×P7=1)&&(P1+P2+P3+P6=0)
a3 (P1×P3=1)&&(P2+P5+P6+P7=0)
a4 (P3×P5=1)&&(P1+P4+P7+P8=0)
a5P2+P4+P6+P8=0&&P1+P3+P5+P7=3
消除条件a1-a4主要用于消除图3所示的斜线冗余像素。当N(P0)=3时,P0点可能是分叉点,也可能是边界点。由于分叉点同样会出现冗余像素,如图6所示,故引入消除条件a5用于分叉点冗余像素的删除,如图7所示。

图6 分叉点细化不彻底

图7 分叉点彻底细化后


图8 保留模板
图8保留模板中P0满足的4个条件为:
b1P1×P3×P4+P6=1
b2P2×P3×P5+P8=1
b3P4×P5×P7+P2=1
b4P1×P2×P7+P4=1
2.3.2消除骨架毛刺
由于手写字体结构的复杂性和书写的随意性较大,经过细化后的手写体汉字骨架仍存在少量毛刺,毛刺破坏了汉字骨架的拓扑性,不利于突出手写体汉字的形状特征。
毛刺长度一般难以归纳,但相对于骨架中心来说,骨架的长度一般远大于毛刺长度[19],所以利用这一个特性,设定一个门限值L,选取最小步长分支进行毛刺的判定与消除。
c1N(P0)≥2‖M(P0)≥2
c2S(P0)=3&&M(P0)≥3&&N(P0)≥3
具体步骤如下:
步骤1遍历细化后的单像素宽度手写体汉字骨架,若当前骨架像素点P0符合条件c1或c2时,该点可能为节点node或生长点grow。
步骤2检测该像素点P0是否为毛刺的起始位置,以端点end为起点对分支进行扫描,记端点到该点的长度值为步长K。
步骤3取最小步长与阈值L进行比较,若该分支的步长K小于阈值L,则标记该分支,并计算分支所在节点node或生长点grow的总分支数,若总分支数大于2,则该分支判定为毛刺,删除该分支。
步骤4若该节点node或生长点grow删除分支后的余留分支数等于2,则通过P0的8-邻域像素分析删除该点是否会导致骨架断点,影响骨架连通性。若没有出现断点,则保留该点;若出现断点,则删除该点。
步骤5重复执行步骤3直至手写体骨架像素遍历完毕。
3 预处理
手写字体汉字与印刷体汉字有所不同,不同类型的书写工具、不同纸张以及书写时所用的不同力度等情况导致手写体汉字图像难以细化。
分析Zhang-Suen算法原理发现,手写体汉字图像中由书写不当所造成的凹凸点和孤立点会对骨架的提取结果造成较大的影响。为了能更好地抽取出图像中的手写汉字骨架,减少干扰因素对细化时可能产生的影响,有必要在手写体汉字图像细化之前对图像做预处理[20]。本文设置了数个模板对手写体汉字图像进行预优化,在细化算法开始执行之前,调用模板对手写体汉字图像进行预处理操作。首先调用图9的凹凸点和孤立点消除模板消除图像凹凸点和孤立点。如果前景点P0的8-邻域满足图9的四个模板,则将前景点P0更改为背景点。其次调用图10的四个模板消除文字图像中可能出现的孔洞,若前景点P0的8-邻域满足图10的四个模板,则将P0的8-邻域全部像素点更改为前景点像素。

图9 凹凸点和孤立点消除模板

图10 孔洞消除模板
图11与图12中对比了未经模板处理和经模板处理过的二值手写体汉字图像,图像中矩形区域标注了改进的地方。实验证明:经过预处理后的手写体汉字图像填补了手写体汉字图像原有的孔洞,孤立的噪声块消失,字体边缘的凹凸点变得光滑。

(a) 预处理前二值图像 (b) 局部放大图11 预处理前的文字图像效果

(a) 预处理后二值图像 (b) 局部放大图12 预处理后的文字图像效果
4 算法步骤
步骤11) 对图像按照按从上到下、从左到右的顺序遍历,寻找前景点P0; 2) 若前景点P0满足Zhang-Suen算法设定的迭代条件,则标记P0为可删除的点;3) 在遍历完手写体汉字图像后,删除所有被标记的点,得到初步细化的手写体汉字骨架。
步骤21) 对细化后提取的手写体汉字骨架进行遍历,寻找前景点P0; 2) 若前景点P0满足删除模板a1-a5,则标记该点为可删除的点,再检测该像素点是否符合保留模板条件,若符合则去除标记为可删除的点,否则继续遍历; 3) 在遍历完手写体汉字图像后,删除所有被标记的点,得到像素为1 bit宽的手写体汉字骨架。
步骤31) 遍历单一像素宽度的手写体汉字骨架,寻找前景点P0; 2) 若前景点P0为节点node或生长点grow,则循环计算细化后骨架各个分支步长,取其中小步长与阈值进行比较,删除符合条件的分支毛刺,得到无毛刺的手写体汉字骨架。
算法工作流程如图13所示。
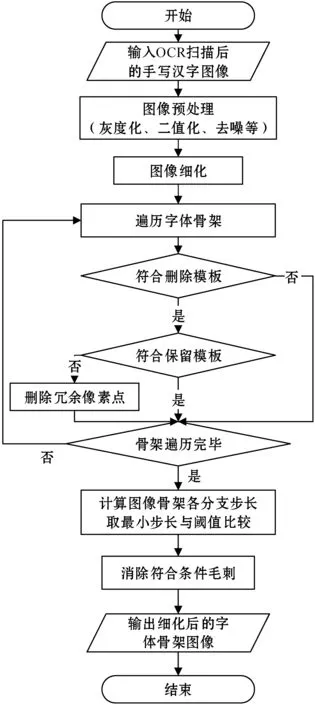
图13 本文算法工作流程图
5 实 验
为验证改进算法的细化效果,实验选取了860幅不同的手写体汉字图进行细化处理。在运行改进算法的同时,使用Hilditch细化算法、Pavlidis细化算法、基于索引表的细化算法、Zhang-Suen细化算法以及改进算法对其中20幅不同手写体汉字图像进行细化对比实验。在Windows 7操作系统的PC机上,硬件配置为Inter(R) Core(TM) i7-6700 CPU 3.4 GHz,8 GB RAM,使用Visual Studio 2015开发环境并使用OpenCV 3.4.1计算机视觉库对手写体汉字图像进行实验,图14-图20为部分图像细化效果。

图14 手写体汉字二值图像

图15 Hilditch细化算法

图16 Pavlidis细化算法

图17 基于索引表的细化算法
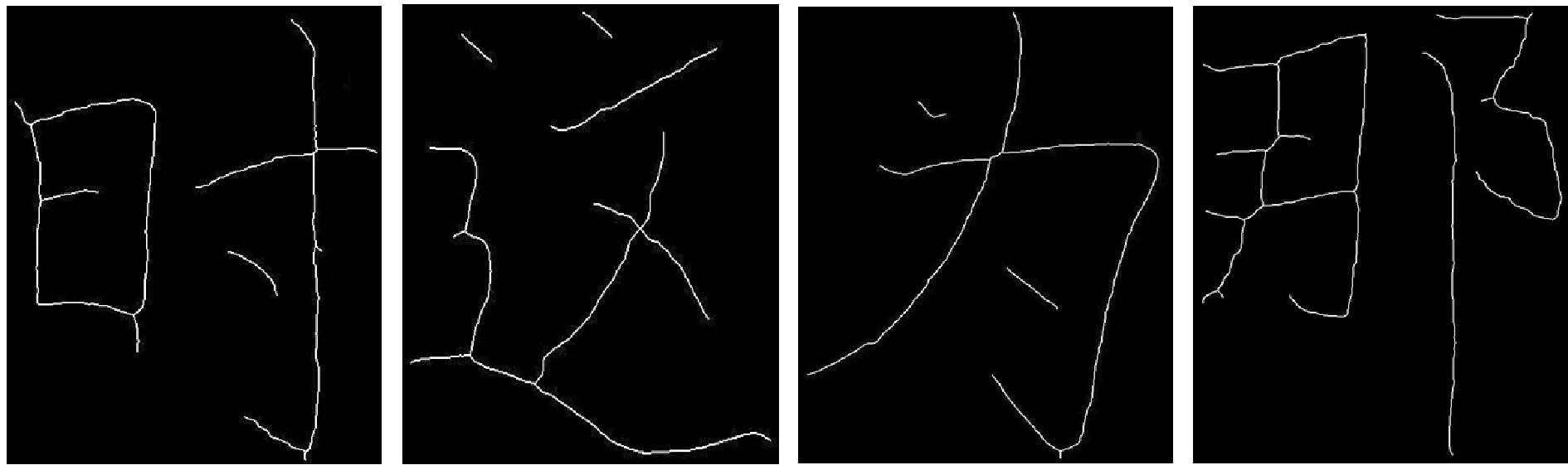
图18 Zhang-Suen细化算法

图19 改进算法

图20 改进算法局部放大
通过对比各个细化算法对手写体汉字的骨架提取效果得出:改进算法所提取出的骨架能够保持汉字形状特征,骨架像素宽度为1 bit,且不存在毛刺。
在相同配置环境下采用本文算法与其他细化算法对随机选取的20幅手写字体图像进行细化处理,并以实验中的平均结果为例进行分析。实验结果如表1所示。

表1 细化算法结果比较
可以看出:五个算法中索引表细化算法细化速度最快,但对手写体汉字骨架的处理效果最差,不能准确表示手写体汉字的结构特征。Zhang-Suen细化算法速度次之,细化结果上有了很大改善,但提取出的汉字骨架存在毛刺,并且不能保证斜线区域的像素宽度为1 bit。本文改进算法的速度和Zhang-Suen细化算法接近,但去除了骨架毛刺和像素冗余,能够准确、完整地提取手写体汉字骨架。
6 结 语
Zhang-Suen算法是一种较实用且细化速度相对较快的细化算法,但是对手写体汉字细化时,易出现斜线区域像素细化不完全以及汉字骨架“毛刺”的问题。本文对Zhang-Suen快速并行细化算法作了改进,引进了消除和保留模板,在保证手写汉字骨架的连续性、拓扑性的基础上,实现了对手写字体的完全细化,并且通过门限机制去除了骨架毛刺。细化结果完整保留和突出手写体汉字的特征信息,对手写体汉字的识别有着重要作用。
