基于FPGA的运动估计算法优化和硬件架构设计
2020-07-13秦传义于林韬王晓丹朱一峰周玉轩
秦传义 于林韬,2* 王晓丹 朱一峰,2 周玉轩
1(长春理工大学电子信息工程学院 吉林 长春 130022)2(长春理工大学空地激光通信技术国防重点学科实验室 吉林 长春 130022)
0 引 言
随着4K/8K超高清(UHD)视频应用发展和第五代移动通信(5G)技术的部分商用,图像清晰度大幅提高,导致视频流数据量激增。因此,迫切需要利用HEVC/H.265高效的视频编解码标准,用以解决大数据量状态下视频图像传输以及储存不畅问题[1]。与其前身的H.264/AVC相比,HEVC在很多方面有了革命性的变化。更加灵活高效的块结构样式、采样点自适应偏移(Sample Adaptive Offset,SAO)技术和自适应环路滤波(Adaptive Loop Filter,ALF)方法配合并行化设计方案使HEVC获得更好的编码性能和并行处理能力[2]。
该方法在带来系统性能提升的同时使得系统架构更加复杂,很难在实际应用中部署。在实际视频编码过程中,运动估计(Motion Estimation,ME)和运动补偿(Motion Compensation,MC)在帧间预测中高复杂度、高时间消耗等缺点,帧间预测的计算量占总编码运算量44.5%~86.3%,其消耗超过帧间预测时间的90%。ME比MC更具挑战性和耗时,由ME引起的帧间预测时间占75%以上。因此,在保证视频画面播放质量的同时,设计一种快速算法结构从而降低运动估计的复杂程度,并通过新的硬件架构设计加速运动估计过程,以解决传统的嵌入式方案下视频流不稳定、低速率的传输特点,从而提高HEVC编解码速率[3]并以较高的压缩效率进行数据压缩。
HEVC编码的复杂性研究是一个关键主题。由于运动估计占据整个编码的绝大部分时间,因而研究的工作主要是围绕如何减少运动估计所消耗的时间,从而降低HEVC的计算复杂度。这段时间的减少是通过软件和硬件方法完成的。
在基于FPGA的运动估计算法软件优化研究中,主要有线菱形并行搜索算法(LDPS)、水平菱形搜索(HDS)、钻石搜索(Diamond Search,DS)、交叉钻石搜索(CDS)。ME算法有比较高计算复杂度,为降低其复杂度、减少搜索算法所需的时间,许多研究学者在基于传统六边形搜索的快速搜索算法[4]和传统钻石搜索[5]的基础上提出了许多改进搜索算法,文献[6]提出了基于SAD算法的快速帧间CU决策。文献[7]用TZS算法中的六边形点代替八菱形点和八方形点。尽管这些研究有效减少了运动估计时间,但运动估计算法大多基于软件平台算法架构的设计研究,并不适合于传统硬件条件下的实现。
在基于FPGA的硬件架构设计中,目前已有的运动估计硬件架构的设计思路大部分主要用于上一代H.264/AVC编码标准,例如文献[8]中,在Xilinx SpartanII和Virtex-2 FPGA系列上提出了一种快速SAD算法,其块大小范围为4×4到16×16。而在H.265/HEVC上,一些硬件实现通过减少SAD计算时间来减少HEVC编码的运动估计时间。文献[9]提出了一种用于灰度图像的硬件SAD设计,允许并行计算一个4×4维定义块的所有SAD。文献[10]提出了两种新的架构,用于在FPGA Xilinx Virtex 5上计算具有和不具有并行性的SAD,实验结果表明并行架构比非并行架构快3.9倍。
综合上述研究与讨论,本文在传统DS算法架构的基础上,提出基于FPGA的运动估计算法优化方法和新型硬件架构设计,结合HEVC视频编码的并行技术,改进DS搜索算法的硬件架构,该算法在实验仿真中性能损失基本可以忽略。配合改进的硬件架构,减少了系统数据读取时间,提高了硬件资源利用率,加快运动估计过程中系统的处理速度。
1 TZSearch搜索算法
TZSearch算法是由Tang等[11]2010年提出的一种混合搜索模型快速搜索算法,其具体搜索由以下四个步骤组成:运动矢量的预测;初始网格的搜索;栅格的搜索;栅格/星型精细搜索。文献[11]中详细描述了运动搜索环节中编码端模块TZSearch搜索算法的实现细节,其流程图如图1所示。

图1 TZSearch算法
初始网格的搜索窗口中的搜索点总数N1为:
N1=P(1+floor(1bS))
(1)
式中:P为模板每次需要搜索的点数;S是TZSearch算法中搜索窗的大小;floor为向下取整函数。
栅格搜索的搜索窗口通常会处于采样式全搜索状态。当HM16.2的栅格搜索窗的采样参数R的最佳步长B_distance≥R时,最佳步长被赋值为采样参数。如下式所示,每一行/列需要搜索的点是C(S/R),N2的最大值是需要搜索的点数[12]。
(2)
TZSearch算法对比全搜索算法,编码性能略有降低,复杂程度大幅下降,搜索时间仅为全搜索算法的20%。对比常用运动估计快速搜索算法,TZSearch算法加入了初始搜索点的预测,同时使用可变步长的搜索模式进一步降低复杂度,并提高了搜索的准确性。然而TZSearch仍然存在不足之处:在搜索模板的设计上,TZSearch没有根据视频固有特性进行区别的搜索,增加系统编码的复杂程度,在运动矢量水平垂直方向分布概率方面的相关实验数据表现也劣于其他方法,在编码时间和编码效率上的表现差距同样巨大,无法在实际场景中应用。
2 改进的TZSearch搜索算法
2.1 TZSearch复杂分布规律
采用TZSearc搜索算法对Vidyo1和Kimono不同特征序列的时间概率分布进行实验统计,结果如图2所示。

(a) Vidyo1序列

(b) Kimono序列图2 Vidyo1和Kimono不同特征序列的时间概率分布
可见,在TZSearch中执行时间和计算复杂性方面最激烈的阶段是初始搜索和精细搜索,初始搜索和精细搜索部分占TZSearch总时间的75%和68%。实际上,大部分ME时间由初始搜索和精细搜索部分获取。
2.2 运动矢量的十字中心偏置特性
运动矢量在一定程度下具有十字中心偏置特性,文献[13]提出运动矢量出现在水平和垂直方向的概率明显高于其他任何方向。传统状态下的钻石搜索算法的架构决定了其不能从根本上改变这一状况,因此本文需要对钻石搜索算法进行重新设计研究。
2.3 改进的钻石搜索算法
改进的钻石搜索算法(Improved Diamond Search,IDS)是使用菱形搜索算法的搜索路径方法,如图3所示。

图3 菱形搜索模板序列(TZSearch算法)
该模式是轴对称,并且在水平和垂直方向上具有相同的优先级。在DS算法中测试和计算两种类型的钻石图案:小钻石图案和大钻石图案。
(1) 小钻石搜索模式(Small Diamond Search Pattern,SDSP):由图3中四个“1”形成小菱形的点构成,有且仅有一种SDSP。
(2) 大钻石搜索模式(Large Diamond Search Pattern,LDSP):分别由图3中“2”、“4”、“8”、“16”、“32”、“64”八个点组成六种大菱形,一共有6种LDSP。
算法在工作过程中会选择最佳匹配块,从而计算的运动矢量的具体值。匹配算法基于计算当前帧和参考帧之间的误差代价函数,其被称为SAD值,又称绝对差值和。当RB和CB表示参考像素和当前块时,SAD计算方法为:

(3)
对于每个点,确定SAD值并进行比较以提取每个特定距离中的最小值。搜索距离(Search Distance,SD)是中心点(0,0)到SDSP/LDSP的每个点(SD={1,2,4,8,16,32,64})的距离。开始时,SDS位于搜索窗口的中心点(0,0)。该第一操作是针对SD等于1执行的,之后,计算SD等于2的大钻石八个点的SAD。然后,通过在每次迭代中将距离SD乘以2来递归地重复下一个LDS的过程。重复这些操作,直到SAD从一次迭代变为另一次迭代。当两次迭代后最小SAD未改变时,或当距离等于搜索范围时,该过程停止。
DS算法认为是降低计算复杂度的主要研究目标,钻石搜索算法基于具有不同坐标的多个钻石计算,即具有不同距离的钻石,距离为1,2,4,8,16,32,64。因此,当优化一个钻石时间时,仅通过修改距离参数,另一个时间将减少,这将导致所有DS时间减少,并且节省ME时间。图4是IDS算法具体流程图。

图4 IDS算法流程图
在IDS算法中,迭代7次,搜索步长SD为集合{1,2,4,8,16,32,64},利用SDS与LDS方法计算算法迭代过程中的最佳距离B_distance,利用FPGA并行处理结构加速IDS算法使算法性能进一步优化。
3 基于FPGA的搜索算法硬件架构
3.1 基于FPGA的并行硬件架构
为了降低HEVC计算复杂度,减少ME时间。本文利用FPGA器件加速搜索菱形算法,设计并行架构来计算MV,以获得更高的频率,同时尽可能降低面积成本。
图5所示为提出系统的架构及其分解为子模块。通过名为“loading_module”的第一个模块,逐行加载当前CTU和参考块。通过代表第二个模块的搜索模块,计算根据菱形算法的运动矢量及其坐标。

图5 系统的架构及其分解为子模块
3.1.1加载模块
对已有八个源和八个参考搜索区域,而不是参考和源块。将八个参考块(从块ref 0到块ref 7)被并行提取,与此同时选择与每个参考块相关的八个行像素。这种提取只需要一个时钟周期。然后将这八条线传递到下一个模块(SAD模块par)以计算它们相应的SAD值。
3.1.2搜索模块
搜索模块如图6所示,该模块使用图示中的硬件组件,可以计算钻石的八个参考块的SAD值。这样做是为了选择具有最佳SAD的最佳估计运动矢量。硬件结构由四个子模块组成,分别是控制单元、Adaptator模块、Memory模块、SAD模块和比较模块。另外,控制单元选择与每个参考块相关联的像素,负责所有子模块之间的寻址、定时和同步。

图6 搜索模块
3.1.3SAD模块
SAD模块如图7所示,适用于计算参考像素和源像素之间的绝对差值和总和。其由两个子电路组成:“差分模块”和“累加器”,用于计算它们的相加。

图7 SAD模块
为了获得最佳的实时性能,该并行架构使用并行执行的一些并行处理元件(PE)。其设计架构允许并行计算八个SAD值,MV是通过同时提取对应于每个参考块的八条线来完成的。
3.1.4比较模块
比较模块如图8所示,主要是确定MV及其坐标,它将每个获得的SAD值与前一个值进行比较,提取它们的最小值,将MV的位置信息提供给控制单元,以选择另一个距离下一个钻石信息的下一个搜索,直至输出,其输出“结束”信号,则说明钻石的所有块计算结束。
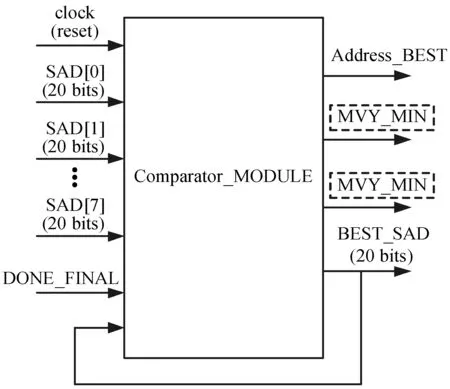
图8 比较模块
4 实验结果与分析
本文以HEVC为参考软件HM16.2作为实验测试平台,在acer T5000笔记本电脑(Intel酷睿i7-6700HQ处理器、16 GB DDR4的内存、Windows 64位的操作系统)硬件条件下进行实验,量化参数选择17、22、27、32、37和42,视频编码100帧,实验结果如表1所示。
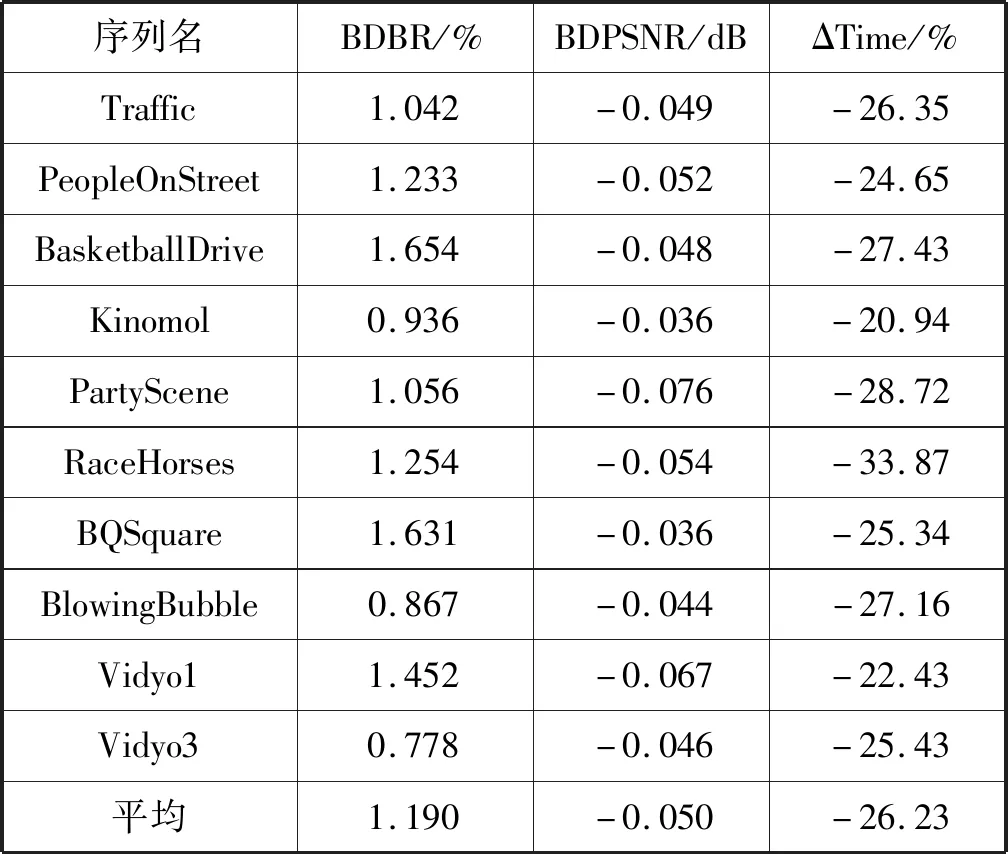
表1 本文算法与HM16.2算法的对比结果
采用同等客观质量下的码率BDBR(Bjøntegaard Delta Bit Rate)、同等码率下的峰值信噪比BDPSNR(Bjøntegaard Delta Peak Signal-to-Noise Rate)和编码时间变化率ΔTime作为快速算法的评价指标。BDBR表示相同PSNR条件下码率的变化百分比,BDPSNR表示相同码率条件下PSNR的变化量。ΔTime计算方法如下:
(4)
式中:HM和proposed分别代表HM16.2和本文算法。表1的实验结果证明:本文算法的复杂度平均下降了26.23%,最大可以达到33.87%。而BDPSNR的损失很小,仅降低了0.05 dB,BDBR的增加也不明显,仅提高了1.19%。实验证明本文设计的编码器性能损失较小,本文算法更适合于实际场景中的应用。
图9是序列Kinomol和Vidyo1使用HM16.2的搜索策略时每帧需要搜索的平均点数。在图9(a)的序列Kinomol中HM16.2大致为120~190,而本文的搜索模板搜索IDS算法的平均每帧需要搜索的点数大致为50~65。

(a) Kinomol
在图9(b)的序列Kinomol中HM16.2大致为150~230,IDS算法的平均每帧需要搜索的点数为40~60。实验进一步说明了IDS算法相关策略可促使传输数据帧中每帧搜索点数进一步减少,从而降低编码所用时间。
图10给出了序列Kinomol和Vidyo1的性能曲线,从曲线图可以看出所提出的IDS算法与原始TZSearch搜索算法相比PSNR值几乎一致,显示IDS算法保持了原有的编码性能。

(a) Kinomol

(b) Vidyo1图10 Kinomol和Vidyo1序列在不同QP下的PSNR曲线图
图11是序列Kinomol和Vidyo在不同QP状态下的Time变化曲线图,从曲线图中可以看出本文所研究设计的IDS算法与原始TZSearch搜索算法相比,运动估计时间降低了15.57%~46.32%。
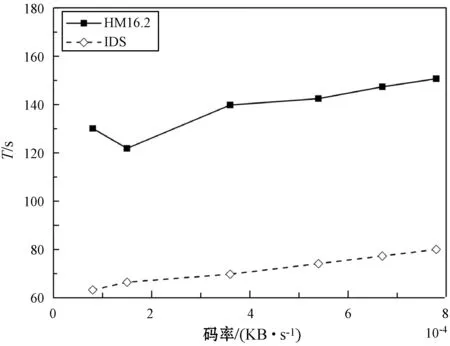
(a) Kinomol

(b) Vidyo1图11 Kinomol和Vidyo1序列在不同QP下的Time曲线图
可以看出,在编码性能上本文优化算法略微有所下降,但是在允许范围内人眼无法察觉。因此,本文算法在保证视频质量的情况下降低系统算法复杂度。影响实验结果的主要原因是本文的IDS算法随迭代次数增加,搜索量也在持续上升,基于运动估计算法的优化和新型硬件架构的设计改进了FPGA中最耗时的搜索模块,当迭代次数较少时钻石搜索将会找到最佳点,从而提前设置了退出搜索的条件并直接退出整个搜索过程,从而保证了系统整体的编码性能。
本文所提出硬件架构以Verilog语言来设计和实现。以Mentor Graphics ModelSim工具验证功能的正确性,运用Virtex-7 FPGA器件在Xilinx ISE 13.1开发平台中完成综合。使用测试平台将像素数据发送到菱形架构并存储计算结果,之后使用Xilinx ISE 13.1将实现合成,放置并最终路由到Virtex-7 FPGA。
表2所示为本文实验结果与相关文献比较情况,文献[14]提出了一种为FS算法设计的并行SAD架构,搜索区域为104×104像素,通过Virtex-5技术获得的合成结果给出了大约348 MHz的频率,与本文架构相比,它的频率较高,但在LUT逻辑资源方面,文献[14]占到Virtex-5平台逻辑资源的36%,需要较大的存储资源。文献[15]也是使用Virtex-7技术用于整数运动估计器的合成和实现,但在时钟周期和延迟时间方面,本文架构远低于文献[15]。

表2 与不同文献硬件结构综合对比

续表2
5 结 语
本文提出一种先小后大钻石算法和FPGA硬件实现的优化方法,来适用于HEVC的运动估计IDS算法硬件单元,结合并行架构,以降低HEVC在执行时间方面的复杂性。其架构在Virtex-7 FPGA Xilinx ISE上实现。综合结果表明,与其他架构相比,并行架构获得一个SAD的相同时间,其允许增益为其他的8倍。此外,计算一个64×64的块所需的时钟周期和所获得的并行版本的延迟优于以前工作中的所有结果。总之,其并行设计可以更好地在FPGA上实现可用资源,有较高的处理速度和资源利用率,所提出的钻石模块可以用于具有一些修改的可变块大小,并且可以提供出色的结果,对以后研究具有一定的实用价值。
