基于改进RNN的LSTM软件缺陷预测技术的研究
2020-07-09苏智韬


摘 要:针对现阶段软件缺陷预测模型研究少和准确率低的问题,提出了一种基于LSTM的软件缺陷预测模型。基于LSTM对输入序列信息的相关性进行了研究,通过Prophet和Ohba开源数据集对网络模型进行训练和测试。实验结果表明:在输入序列为500时,LSTM的检测效果准确率为99.12%,误报率为0.91%,优于RNN的93.58%的准确率和5.76%的误报率。
关键词:深度学习;长短期记忆;软件缺陷预测;RNN
中图分类号:TP315.53 文献标识码:A 文章编号:2096-4706(2020)21-0017-04
Research on LSTM Software Defect Prediction Technology Based on Improved RNN
SU Zhitao
(School of Computer Science,Sichuan University,Chengdu 610065,China)
Abstract:Aiming at the problem of little research and low accuracy of software defect prediction models at this stage,a software defect prediction model based on LSTM is proposed. The correlation of input sequence information is studied based on LSTM. The network model is trained and tested through Prophet and Ohba open source datasets. The experimental results show that:when the input sequence is 500,the detection accuracy of LSTM is 99.12%,and the false alarm rate is 0.91%,which is better than RNNs 93.58% accuracy rate and 5.76% false alarm rate.
Keywords:deep learning;LSTM;software defect prediction;RNN
0 引 言
早期的软件测试基本等同于调试,最常见的测试方法是面向图形和非图形的用户界面测试,实际上,一个软件从需求分析、开发设计到最后上线交付诞生的过程中,离不开软件缺陷的测试和预测技术的思想。导致软件缺陷的主要因素有概念需求说明的精细化,测试工具和数据的综合化,模型的合理化以及测试人员的专业化[1]。目前,利用机器学习算法对软件缺陷预测是当下的研究热点,国内外学者对软件预测技术进行了一些研究。文献[2]通过LSTM和RNN简化语音识别技术,可预测疾病、图像分类和控制聊天机器人等任务;文献[3]利用RNN输入文本的微小增改处理方法,对错误文本分类。
笔者在软件图形用户界面(GUI)测试中,发现自动化测试工具在某些环节可以代替人工测试与应用程序进行交互,但自动化测试工具在不同的GUI状态下对于可接受的手势识别存在限制和缺陷。不同测试生成器的主要区别在于生成测试用例时所采用的策略,常用的策略主要包括基于模型策略、隨机策略和针对性策略三种[4],本文利用机器学习算法LSTM构建模型策略。测试生成器的模型策略通常使用RNN,主要是基于训练算法BPTT[5]。但是,单纯地使用RNN会出现权重指数级爆炸和梯度消失的问题,难以捕捉长时间输入序列的关联性,使重要的信息可能不会被输出[6]。因此,本文使用了RNN的改进策略长短期记忆模型(LSTM),可以更好地处理和预测时间序列的重要事件。
1 LSTM的网络模型结构
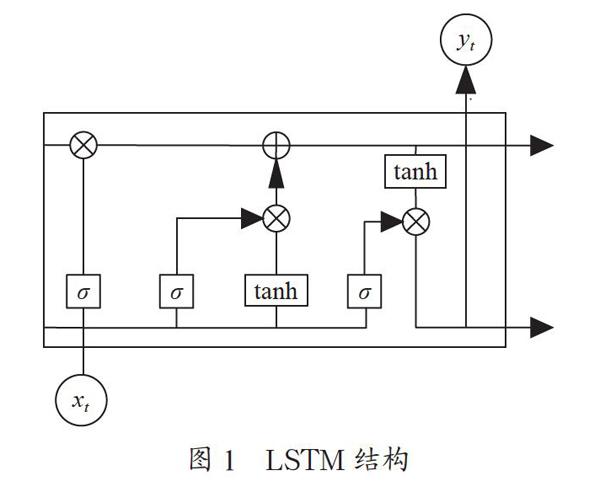
LSTM在语音识别、自然语言处理、图像处理和视频分类等方面表现出了很好的效果[7]。LSTM和RNN相比,主要解决了RNN长期依赖的问题。LSTM的网络模型结构如图1所示,LSTM通过引入记忆单元、输入门、遗忘门和输出门解决梯度消失问题。其中,t时刻的输入信息为xt,yt为t时刻的输出,Sigmoid激活函数为σ,?为元素相乘,⊕为元素相加,门结构由σ和?组成。前一级记忆单元输入的信息是否需要被保留由遗忘门决定,输入门确定重要的信息加载到记忆单元,输出门则决定了下一个隐藏状态。
2 LSTM预测模型的建立
LSTM是一种具有很好学习性的神经网络算法模型[8]。在实际工程软件测试过程中,测试人员依据测试需求说明书和测试用例发现软件缺陷。算法模型的输入层包括日常测试用例、需求说明书、测试用例数个被测对象,输出层则是软件缺陷个数及问题描述。
2.1 LSTM的设计
RNN推导演进后可得到LSTM,原始的RNN由于隐藏层只有一个状态h,对于短期的输入比较敏感。因此,在此RNN的基础上增加一个状态c,状态c又称为单元状态,按照时间维度展开如图2所示,让它保存长期的状态,解决了原始RNN无法处理长距离依赖的问题。
从图2可以看出,LSTM的输入有三个:xt为当前时刻的输入,ht-1为前一时刻的输出,ct-1为前一时刻的单元状态,模型当前时刻的两个输出为ht和ct。LSTM利用三个控制开关控制长期状态,思路方法如下:前一个开关s1保存控制长期状态ct,中间的开关s3将输入的数据传输到长期状态ct,最后一个开关s2控制是否将长期状态ct作为输出,三个开关控制长期状态的模思路如图3所示。
2.2 LSTM的前向计算
门是代替开关算法中的重要组成部分,是一层全连接层,输入和输出都是向量。在LSTM算法中,权重向量为W,偏置项为b,门的一般表达式可写为:
g(x)=σ(Wx+b) (1)
其原理是通过输出向量乘以控制向量,当门输出为0代表不通过,门输出为1时,向量与1相乘则不会改变,表示通过。LSTM用输入门和遗忘门来控制单元状态c的内容,遗忘门决定了前一时刻的单元状态ct-1,输入门决定了当前时刻的网络输入xt保存到单元状态的数量。遗忘门可表示为:
ft=σ(Wf ·[ht-1,xt]+bf) (2)
其中,Wf为遗忘门的权重矩阵,[ht-1,xt]为两个向量的组合,bf为遗忘门的偏置项,σ为激活函数。若输入的维度为dh,单元状态的维度为dc,则Wf维度为dc·(dh+dx)。实际上,权重矩阵Wf是两个矩阵Wfx和Wfh拼接而成。Wf可以写为:
(3)
输入门可以表示为:
it=σ(Wi×[ht-1,xt]+bi) (4)
记忆单元的状态可通过上一时刻的输出和本次的输入计算,即ct-1按元素乘遗忘门ft,当前输入的单元状态乘输入门it,两个乘积项相加可得到ct,将LSTM的当前记忆单元和前一时刻的状态组合得到了新的单元状态。而在数据传输过程中,输入门可以避免当前不重要的信息进入记忆单元,遗忘门可以保存前一时刻的数据信息记忆,最终的输出门控制当前的记忆单元输出数据信息,输出门的计算可表示为:
ot=σ(Wo×[ht-1,xt]+bo) (5)
输出门和记忆单元状态最终决定了LSTM的输出,可以写为:
ht=ot×tanh(ct) (6)
LSTM最终数据输出过程如图4所示。
2.3 LSTM训练
由于输入状态是连续的时间序列,LSTM可以很好地解决时序问题,根据前面的介绍训练模型,LSTM反向传播算法的训练分为三个步骤:
Step1:求解前向计算的每个神经元ft,it,ot,ht向量的输出值。
Step2:分别计算每个神经元两个方向的误差项δ值。即每个时刻和向上一层传播的误差项。
Step3:根据得到的误差项计算权重的梯度。
LSTM的详细计算过程和推导公式为:与RNN类似,LSTM误差反向传播的计算利用误差项的δ值,采用梯度下降法更新权值,在LSTM的训练过程中,需要学习的参数共有8组,分别为输入门的Wi和bi,输出门的Wo和bo,以及記忆单元状态的Wc和偏置项bc。在反向传播时权重矩阵使用不同的公式,因此,权重矩阵Wf、Wi、Wc、Wo被分开为两个矩阵:Wfh、Wfx、Wih、Wix、Woh、Wox、Wch、Wcx。误差沿时间反向传递,E为损失函数,在t时刻LSTM的输出值为ht。我们定义t时刻的误差项δt为:
(7)
通过式(7)可知,损失函数对输出值的导数为误差项,建立的LSTM有四个加权输入,而向上一层传递的只有一个误差项,因此,分别定义四个加权输入对应的误差项为:
netf,t=Wf[ht-1,xt]+bf (8)
neti,t=Wi[ht-1,xt]+bi (9)
=Wc[ht-1,xt]+bc (10)
neto,t=Wo[ht-1,xt]+bo (11)
(12)
(13)
(14)
(15)
沿时间反向传递t-1时刻的误差项δt-1可表示为:
(16)
以输出门为例,根据得到的误差项,计算当前时刻权重矩阵的梯度和偏置项梯度,计算过程可表示为式(17)~式(19):
(17)
(18)
(19)
输出门最终的梯度为各个时刻的梯度之和,同理,遗忘门、输入门和记忆单元的权重矩阵和偏置项的梯度可以依据输出门的求解方法得到。
3 实验及结果分析
本文主要是基于时间序列的测试序列验证。实验环境:主机CPU型号为Intel i5 9300H,主频为2.4 GHz,物理内存为8 G,64位操作系统,深度学习框架为TensorFlow 1.11.10,代码运行平台为Python3.7。采用的训练数据有语言数据联盟提供的汉语文本语料和失效数据集Ohba,训练集是从网上自行下载的Prophet时间序列数据集,随机选取3 271个样本集,训练样本集和测试样本集的占比为8:2。网络模型的参数预设值通过多次实验迭代100次确定,具体参数设置如表1所示。
LSTM结构的输出可以是任意长度的序列,但是序列的长短会影响获取时间,序列越长,模型训练的时间也会增加。序列长度则为包含字符的个数,经多次测试并考虑到训练时间和拟合度的问题,本文选择500作为模型训练的序列长度。为说明验证本文模型特征的有效性,针对同一数据集构建其他文献中常用的RNN检测结果,训练和测试分别表示训练样本集和测试样本集的建模与检测时间。
由表2可知,LSTM调用处理序列在准确率(ACC)、检测率(DR)和误报率(FAR)均优于RNN,文本构建的LSTM的检测效果准确率为99.12%,误报率为0.91%,优于RNN的93.58%的检测率和5.76%的误报率。因为本文的模型训练采用多个数据集不断训练优化模型,反复实验修改迭代次数,LSTM能够对重要的输入信息保留,不会出现权重比较大的信息遗失等问题。
4 结 论
本文对基于软件故障检测和预测进行了研究,提出了一种基于LSTM的软件测试方法,针对目前软件工程的故障类型繁多和需求复杂等特点,为更好地实现软件缺陷预测和故障预测方法,与RNN进行了比较,结果显示提出的LSTM具有以下优势:模型的检测时间短,拟合程度较好;网络模型在准确率、检测率和误报率三个指标上的性能较好;网络结构上要优于RNN的模型结构,LSTM的遗忘门会使得前一级输入的状态信息按照权重大小输出。同时,本文方法也存在一些不足,目前仅提出了字符序列信息,对语音和图像等测试训练还需要加强,且模型构建的时间长,下一步工作将提取更多的输入信息特征,进一步优化模型,提高模型的可用性和高效性。
参考文献:
[1] 王文滔.Android手机软件自动化测试的设计与实现 [D].北京:北京交通大学,2015.
[2] 左玲云,张晴晴,黎塔,等.电话交谈语音识别中基于LSTM-DNN语言模型的重评估方法研究 [J].重庆邮电大学学报(自然科学版),2016,28(2):180-186+193.
[3] TUMULURU V K,WANG P,NIYATO D. A Neural Network Based Spectrum Prediction Scheme for Cognitive Radio [C]//2010 IEEE International Conference on Communications.IEEE,2010:1-5.
[4] AHMAD N S,KHAN M G M,RAFI L S.A study of testing effort dependent inflection S-shaped software reliability growth models with imperfect debugging [J].International Journal of Quality & Reliability Management,2010,27(1):89-110.
[5] 杨波,吴际,徐珞,等.一种软件测试需求建模及测试用例生成方法 [J].计算机学报,2014,37(3):522-538.
[6] 韩文凯.认知网络的频谱感知对抗技术研究[D].成都:电子科技大学,2018.
[7] 李秋英,李海峰,陆民燕,等.基于S型测试工作量函数的软件可靠性增长模型 [J].北京航空航天大学学报,2011,37(2):149-154+160.
[8] 杨宏宇,徐晋.基于改进随机森林算法的Android恶意软件检测 [J].通信学报,2017,38(4):8-16.
作者簡介:苏智韬(1992—),男,汉族,四川绵阳人,硕士研究生在读,研究方向:基于机器学习的软件自动化测试。
