基于堆叠去噪自编码器的桥梁损伤定位方法研究
2020-07-09程海根胡钧剑
程海根,胡 晨,姜 勇,胡钧剑
(华东交通大学土木建筑学院,江西 南昌330013)
改革开放以来,我国桥梁建设取得瞩目的成就,随着建设桥梁数目增多,桥梁方面的安全问题也备受关注[1]。 随着控制技术、传感技术和计算机通信技术、人工智能技术以及其他结构分析技术的不断发展,各领域知识逐渐被引入桥梁结构的健康监测技术中[2]。 而不断研发能够准确反映桥梁结构状态的监测技术已经成为未来的研究方向[3]。
众多学者在如何从监测数据中提取有效特征对桥梁进行损伤识别方面做了大量的研究。 邱飞力等学者[4]利用实测和有限元模型间的柔度矩阵残差修正目标函数,得到了以模态柔度矩阵为目标函数的损伤识别方法。文献[5]由均匀荷载面曲率差指标推导出一种加权柔度矩阵指标构造方法,以计算损伤程度,且通过算例验证了该方法的有效性和可行性。 文献[6-7]基于结构动力响应的小波包能量谱提出了结构损伤特征指标,以此来表征结构动力系统的损伤状况。 随着人工智能的发展,人工神经网络方法被广泛使用在损伤识别的各个方面[8-9]。 文献[10]则通过瞬态分析得到位移响应信号,再结合小波包分解和神经网络建立损伤识别模型。但是现有的方法对于原始健康监测数据的处理能力有限,提取的信息少,不能全面反应桥梁结构的健康状态。 而通过神经网络方法提取特征指标需要花费较长的时间,如果数据出现细节丢失则可能面临难以收敛等问题。 深度学习的出现恰巧可以解决此类问题,且已经在图像识别领域和损伤识别领域得到广泛的应用[11-13]。
鉴于深度学习的优秀表现, 本文提出了一种基于堆叠去噪自编码器 (stacked denoising auto-encoder,SDAE)的桥梁损伤定位方法,利用堆叠去噪自编码器提取外界荷载激励下桥梁的大量加速度信号值与损伤状态之间隐含的拓扑关系,以此得到桥梁损伤位置判别信息,如图1 所示。 相比于传统的机器学习方法,即BP 神经网络和支持向量机,具备定位准确率高和抗噪性能好的优势。
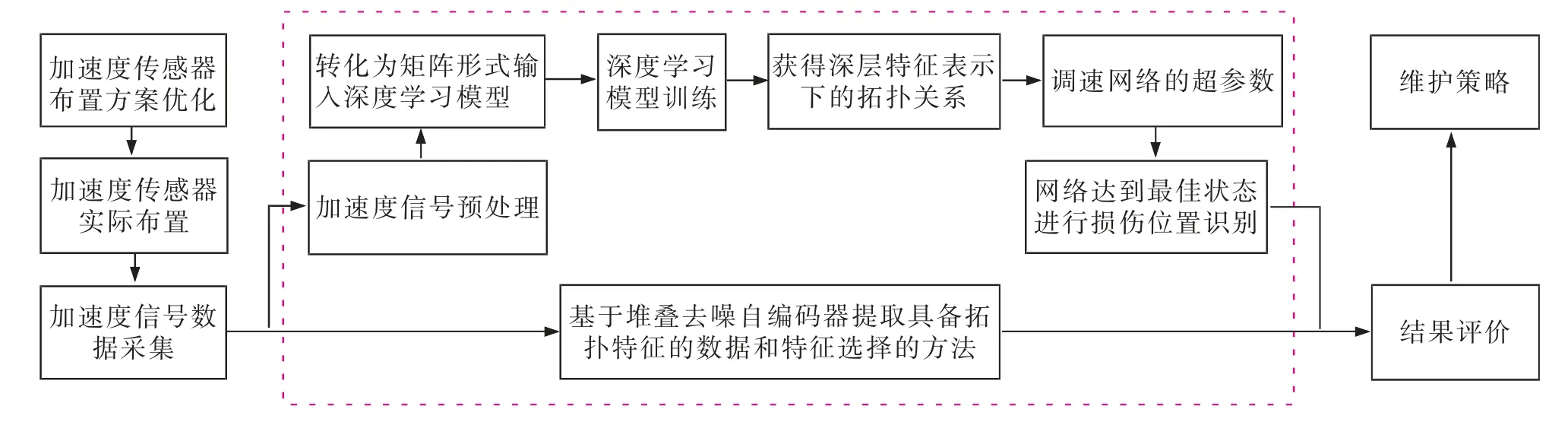
图1 基于堆叠去噪自编码器的桥梁损伤定位方法的组成Fig.1 The composition of damage position identification method based on stacked denoising encoder for bridge structure
1 堆叠去噪自编码器基本原理
堆叠去噪自编码器顾名思义是通过堆叠多个去噪自编码器组成。 而去噪自编码器是基于自动编码器的基础上,通过随机屏蔽一些训练的输入数据,强迫网络模型学习去噪并还原形成这些输入数据。 在输入数据受损的情况下,更稳定且更有用的特征凭借着自动编码器的特性得以找到,组成了输入数据更高层次、更抽象的描述,整个模型的鲁棒性得以增强。
1.1 自编码器的结构
自编码器是非监督形式的3 层神经网络。 其中2 个重要组成部分是编码器和解码器,包括输入层、隐藏层以及输出层,结构如图2 所示。
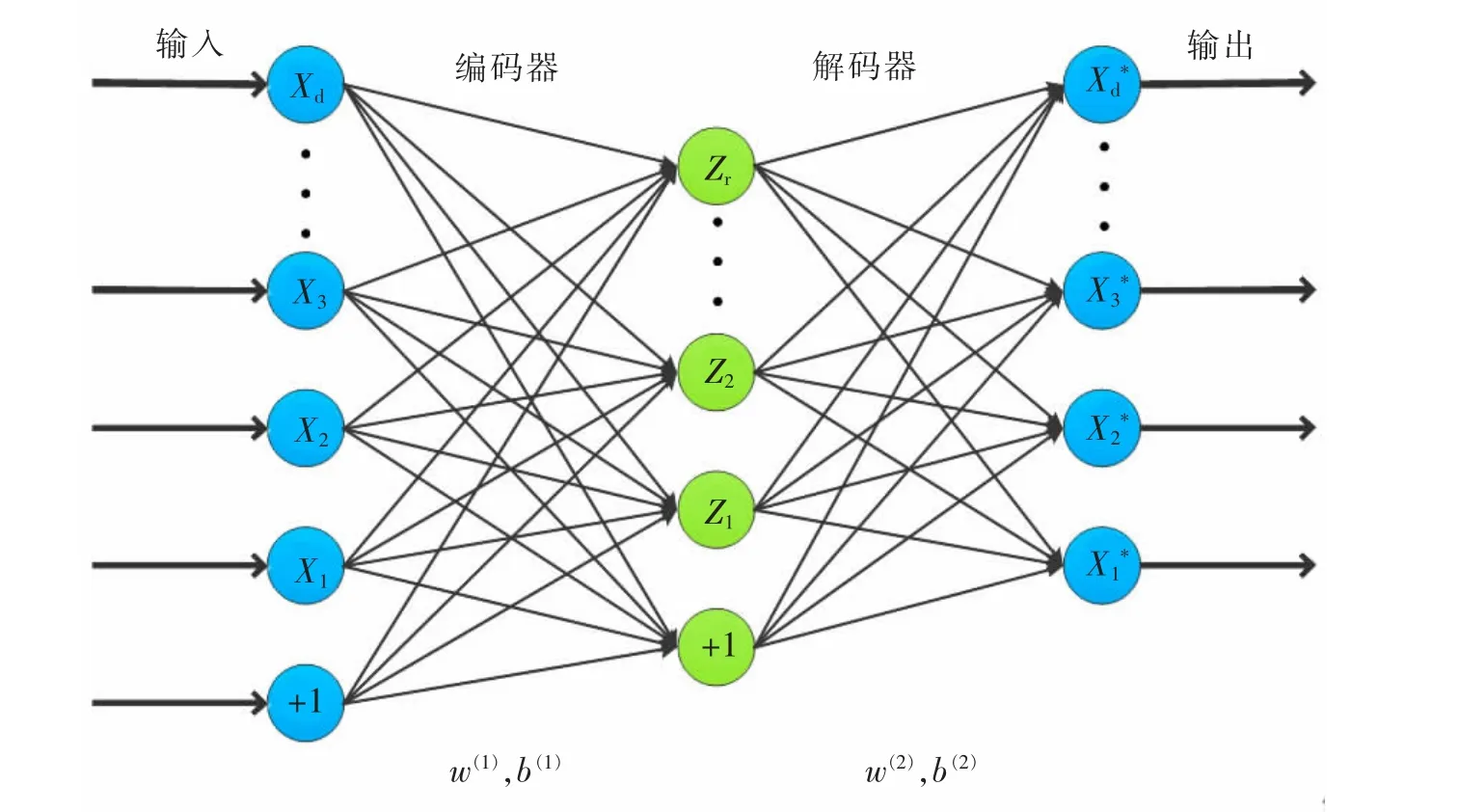
图2 自编码器网络结构Fig.2 The structure of auto-encoder network
编码器的作用是通过激活函数将输入向量非线性映射到隐藏层,得到更高层次、更抽象的特征表示,函数表达如下

式中:X 为编码器的输入矩阵;Z 为编码器的输出矩阵;r 为隐层单元的数目;W(1)为隐藏层的输入权值;b(1)为隐藏层的输入偏置;s 为激活函数。
解码器的功能就是将隐藏层中的数据特征,经过一种特定的函数来映射到原始的数据中,该函数的表达式为

式中:X*为解码器的输出矩阵;W(2)为输出层的输入权重;b(2)为输出层的输入偏置。
在设计自编码器的时候,应设计成输入到输出不完全相等,需要加入一些约束,以使自编码器只能近似地复制与训练数据相似的输入,才能够学习到训练数据的特征。
1.2 去噪自编码器的结构
去噪自编码器是一类接受损坏数据作为输入,并训练来预测原始未被破坏数据作为输出的自编码器。 该网络模型的去噪训练的原理如图3所示。
如图3 所示,去噪自编码器从原始数据X 中添加噪声得到受损的数据X1,接着隐藏层对受损数据X1进行编码而得到y,y 表示对X1进行编码得到一个新的特征。 对y 解码可得尽量还原为原始输入数据的Z。 去噪自编码器的优势在于可以学习容量很高的编码器,同时防止编码器和解码器学习一个无用的恒等函数。
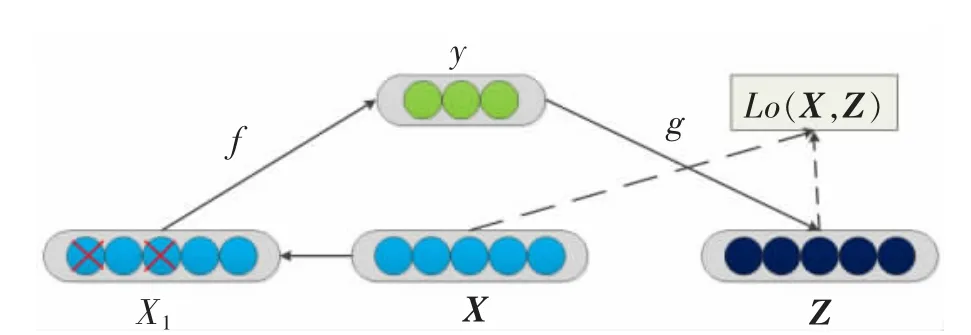
图3 去噪训练原理Fig.3 Principle of denoising training
1.3 堆叠去噪自编码器的训练
堆叠去噪自编码器的训练是使各去噪自编码器输出的信号Z 与输入的信号X 无限接近,定义误差函数如式(3)

采用预训练的无监督学习对每个去噪自编码器的参数θ={W,b}进行初步确定,然后通过BP 算法对整个堆叠去噪自编码器进行有监督学习训练,使全局参数θ={W,b}进行微调,最终保证模型具备良好的判别性能。
2 桥梁有限元模型介绍
2.1 桥梁仿真有限元模型
本文采用ANSYS 有限元软件模拟某简支板梁,采用均质截面,以验证本文提出的损伤定位方法。 该模型桥梁为简支梁桥,净跨径为10.0 m,混凝土等级为C50。 桥梁单元划分图和板梁截面图如图4 所示。
由图4 (a)可知,本仿真有限元模型均匀划分为20 个单元,共21 个节点。其中1 号和21 号节点为桥梁端节点,1 号节点为固定铰支座,21 号节点为滑动铰支座。 主梁采用二维等参梁单元(Beam3 单元)模拟,支座用节点不同的自由度约束状态来模拟,即节点1 约束水平和竖直方向位移,节点21 约束竖直方向位移。 由图4(b)可知,该梁单元的截面惯性矩为0.004 2 m4,截面面积为0.2 m2,梁高为0.5 m,弹性模量为3.5×104MPa,密度ρ=2 500 kg/m3。 将以上实常数分配给相应的单元。
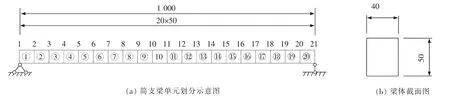
图4 简支梁示意图(单位:cm)Fig.4 Schematic diagram of simply supported beam (Unit:cm)
2.2 简支梁桥的损伤工况
损伤程度定义材料弹性模量减少量。 鉴于本文是对深度学习模型应用于桥梁损伤定位的一种尝试,故而采用单个损伤单元作为讨论,以简化桥梁的损伤状态。 每个工况均采用简支梁边界条件,且桥梁上部布置一移动荷载,以集中力F=100 kN 代替,并规定该移动荷载以速度v=18 km/h 由1 号节点向21 号节点定向移动。 以无损伤状态和某个损伤单元的某种损伤程度建立7 个测试样本的损伤工况,对应的测试样本的损伤标签库如表1 所示。 建立的训练样本为无损伤状态和3 号、7 号、11 号单元各自的5%,15%,25%,35%,45%,55%,65%,75%,85%,95%的损伤程度状态,测试样本则为表1 所示工况。
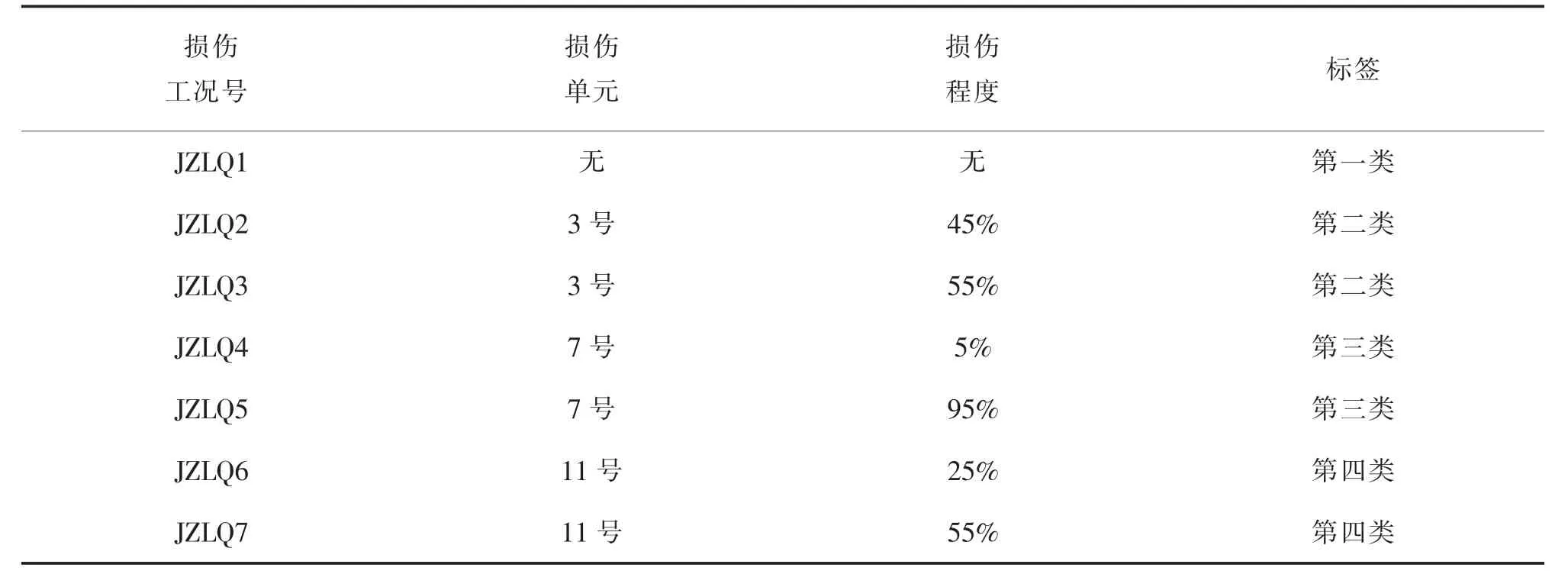
表1 简支梁桥测试样本的损伤标签库Tab.1 Damage tag library for test samples of simply supported girder bridges
2.3 数据预处理
在桥梁上部移动荷载作用下,随机选取简支梁在3.0 s 内的5 号节点、9 号节点、13 号节点、17 号节点的各时间点的竖向加速度值作为损伤指标,然后统一进行z-score 标准化预处理作为训练样本库。 按照前述,简支梁桥的堆叠去噪自编码器的训练过程可以详细解释为:将270 组测点竖向加速度响应值作为无监督学习的预训练样本库以使去噪自编码器完成自身参数的初步确定,接着再用此270 组竖向加速度响应值及与之一一对应的标签作为有监督学习的训练样本库达到模型全局参数的微调。 同时将30 组测试样本的各测点竖向加速度响应值进行预处理作为基于堆叠去噪自编码器的桥梁结构损伤定位模型的输入。训练样本的竖向加速度响应值和测试样本的竖向加速度响应值经预处理后的结果如图5 所示。
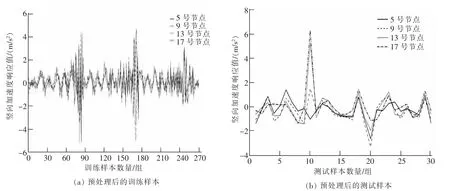
图5 预处理后的训练样本和测试样本Fig.5 Pre-processed training samples and test samples
3 结果分析
将预处理后的测试样本作为堆叠去噪自编码器的输入数据,得到深度学习模型的识别结果,将得到的结果与表1 作比较即可得到该方法的损伤定位准确率。 将得到的所有结果汇总如表2 所示。

表2 基于堆叠去噪自编码器的简支梁桥损伤定位的结果Tab.2 The result of damage position identification based on stacked denoising auto-encoder for simply supported beam bridge
通过表2 可知,基于堆叠去噪自编码器的简支梁桥损伤定位方法具有不错的表现,其定位准确率高达93.33%(28/30)。 其中损伤类别为第一类,即无损伤单元的情况,成功完成定位;损伤类别为第二类,即损伤单元为3 号单元,定位准确率为90.00%(9/10);损伤类别为第三类,即损伤单元为7 号单元,成功完成定位;损伤类别为第四类,即损伤单元为11 号单元,定位准确率为88.89%(8/9)。以上结果表明堆叠去噪自编码器能够应用于简支梁桥的单个损伤单元的损伤定位当中。
在桥梁损伤检测中常用的机器学习方法主要分为:BP 神经网络和支持向量机(SVM)。 为了验证本文提出的基于堆叠去噪自编码器的简支梁桥损伤定位的方法,建立了BP 神经网络和SVM 与其在无噪声状态下识别结果作比较,汇总如表3。
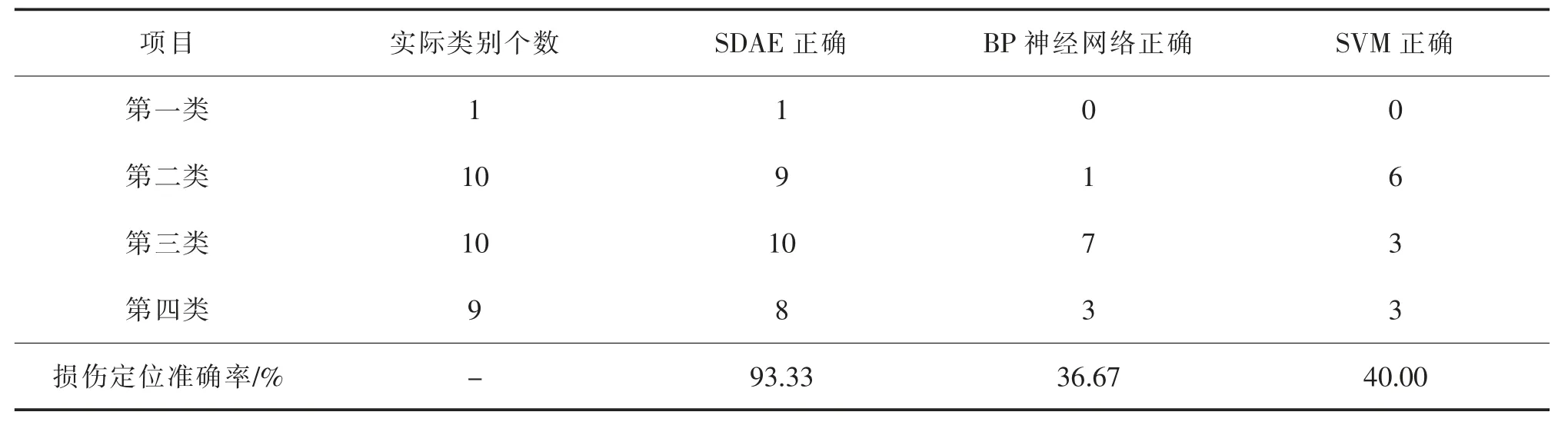
表3 无噪声状态下识别结果比较Tab.3 Comparison of recognition results in noiseless state
从表3 可以看出, 堆叠去噪自编码器对于每个不同工况的定位准确率都高于传统的BP 神经网络和SVM,说明本文提出的方法相较于传统方法来说更具实用性。
由于数据采集人员的操作不当、复杂环境的影响、设备精度不足等原因会对采集的加速度响应值产生相应的噪声误差。 为了检测本文所提方法是否具备噪声的鲁棒性,向训练样本库和测试样本库中的输入数据分别添加5%,10%,15%的高斯噪声,噪声添加方式如公式(4)

式中:xi*为经噪声处理后的第i 个输入数据;xi为原始的第i 输入数据;η 为噪声程度;normrnd(0,1)为均值为0,方差为1 的高斯噪声。
得到各个噪声状态下的识别结果如表4~表6 所示。
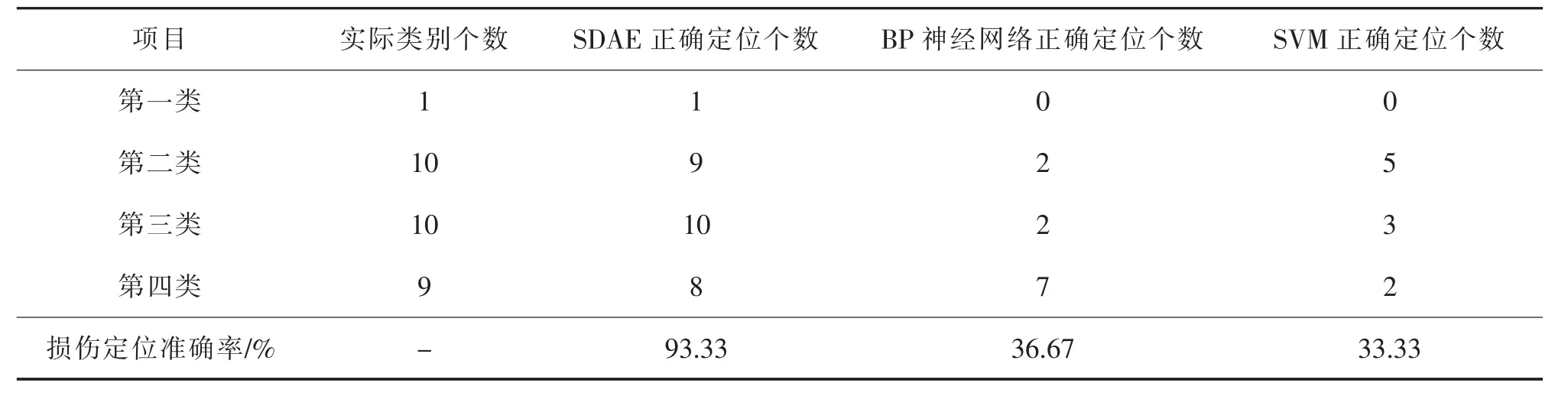
表4 5%噪声状态下识别结果比较Tab.4 Comparison of recognition results under the condition of 5% noise

表5 10%噪声状态下识别结果比较Tab.5 Comparison of recognition results under the condition of 10% noise
汇总表3 至表6 的结果做图可以明显看出本文提出的堆叠去噪自编码器的优势。如图6 所示。
通过图6 可知, 在5%,10%,15%高斯噪声状态的情况下,本文提出的方法相比于传统的方法具有更高的定位准确率和鲁棒性。随着噪声影响的增大,传统方法逐渐显现出定位准确率下降的趋势,而本文提出的方法依然保持着高准确率的识别结果。
4 结论
针对现有识别算法存在的精度不足的问题, 本文提出了一种基于去噪自编码器的桥梁损伤定位方法,将各个节点的加速度响应信号合成加速度矩阵,该矩阵可以充分反映桥梁结构健康信息。 再利用堆叠去噪自编码器的深度学习能力提取加速度响应信号的深度特征,最后判别桥梁结构损伤发生的位置。 经模型验证,本文提出的损伤定位方法展现出了定位准确率高和抗噪性能好的特点,具备可实施性,可以为以后的桥梁结构损伤识别方面的研究提供参考。
