基于BP神经网络的重要水库水源地风险预测
2020-07-08蔡旺炜夏志昌
刘 瀚,蔡旺炜,夏志昌,董 旭
(1.河海大学农业工程学院,南京 210098;2.温州市水利局,浙江 温州 325000)
1 研究背景
水源地是以维系生态平衡为基础要求,同时提供动植物生长与人类生产生活用水的复杂系统。维护水源地水源健康是保证饮水安全与农业生产的重要基础[1-2]。2012年环保部办公厅印发《全国集中式生活饮用水水源地水质监测实施方案》(环办函[2012]1266号)提出,要全面、客观、准确地掌握我国集中式生活饮用水水源地水质状况及变化趋势,保障用水安全。因此,科学准确地判断水源地健康风险并进行趋势预测和分析显得尤为重要。
近年来,相关学者在水源健康的评价方法上不断推陈出新[3]。刘志明等基于灰色预测模型预测了区域水资源承载力[4],陈洁等基于三角模糊数对地下水源水环境健康进行了风险评价[5],卫召基于神经网络对南水北调中线工程的水质进行了评价和预测[6]。然而,目前国内水源地健康风险的评价大多仍停留在水质、水量的层面[7],预测方法也存在精度不高、过于繁杂等缺点。神经网络算法在进行水源健康评价时,往往只局限于5类水质评价标准,收敛次数少,结果范围广,难以发挥其高计算速度、高计算精度的优点。
本文拟根据珊溪(赵山渡)水库实测资料,结合国内外相关条例与评估经验,从多方面构建水源地健康风险综合评价指标体系。基于BP神经网络算法,结合综合权重评价法的具体数值结果作为健康预测目标结果,建立水库水源地健康风险预测模型,实现对水库水源健康的科学评价,为库区居民的工农业用水安全提供保障。
2 材料与方法
2.1 研究区概况
珊溪(赵山渡)库区位于浙江省南部,界于北纬27°36′~27°50′、东经119°47′~120°15′,规划区行政总面积为2 326.14km2,集水面积2 076.6 km2,主要由珊溪水库和赵山渡引水工程两部分组成。该库区以城市供水和灌溉为主,兼有发电和防洪等功能,是典型的水库型集中水源地[8-9]。近年来,其上游社会经济的发展带来了诸多水污染问题,对水源健康构成了潜在威胁。
本文按照其地理位置及行政区划设置了12个有代表性的监测点位,如图1所示,并以此将库区分为珊溪、黄坦坑、峃作口、三插溪1、洪口溪、三插溪2、莒江溪、飞云江、泗溪、桂溪、赵山渡和玉泉溪,共12片水域。
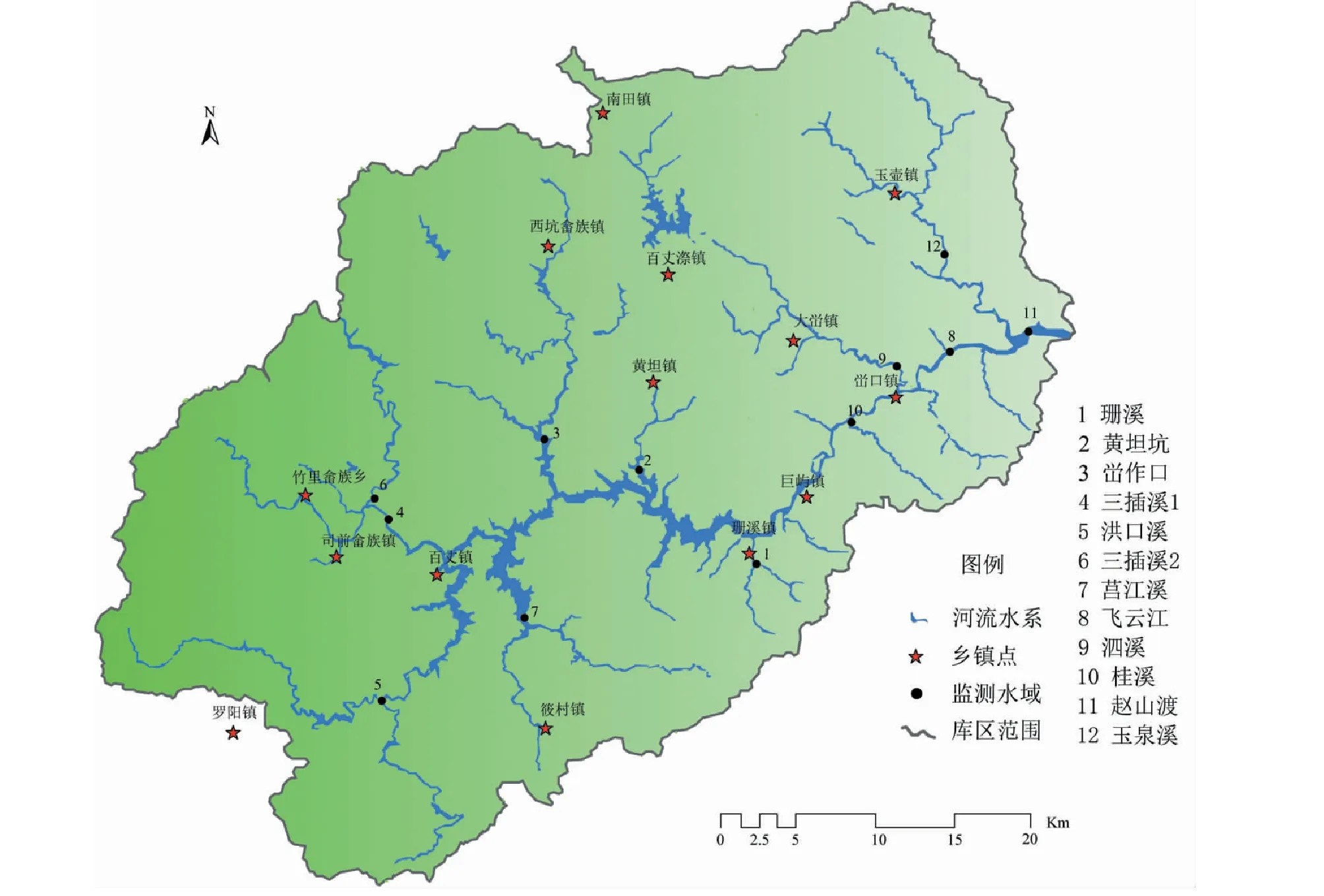
图1 监测点位分布图Fig.1 Distribution of monitoring points
2.2 数据来源
本研究按照春夏秋冬不同季节,分别于2017年7月、2017年10月、2018年1月、2018年4月、2018年7月、2018年10月先后对珊溪水库全库区开展了6次现场调查、监测、取样和资料收集。每次主要调查土壤、植被、水体环境、浮游生物等,收集水文、水质监测资料。
评价体系的建立主要依托于《全国重要饮用水水源地安全保障评估指标的指南(2015.4)》《浙江省水功能水环境功能区划分方案(2005.12)》《地表水环境质量标准(GB3838-2002)》等。
2.3 方法介绍
2.3.1 综合权重评价法
在水源地健康评价的过程中,需要对不同的指标赋予不同的权重来反映指标的相对重要程度,以增强评价结果的准确性和可靠性。本文采取综合权重评价法,综合考虑主观权重和客观权重。主观权重是河道管理人员根据现实情况,邀请熟悉情况的专家人员对各指标进行打分,根据分值计算权重。客观权重即根据粗糙集理论[10~12]进行权重计算。
2.3.1.1 客观权重的计算
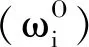
(1)
σR(xi)=γR(D)-γR-{ri}(D)(i=1,2,…,n)
(2)
(3)
式中,γR(D)表示决策属性集D对条件属性集R的依赖度,γR-{ri}(D)表示决策属性集D缺失i属性时对条件属性集R的依赖度,γR(D)与γR-{ri}(D)的差值σR(xi)表示第i个属性对系统的重要度。crad表示集合元素个数计算函数,PR(D)表示全体样本的集合U关于条件属性R的正域。
2.3.1.2 主观权重的计算
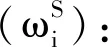
(4)
式中,R(xi)表示第i个指标的专家打分总分,n表示专家人数。
2.3.1.3 综合权重的计算
在计算粗糙集权重的同时,加入主观赋权的方法,以取得更加合理的属性权重。对应各指标不同属性,加入不同的调整参数η(0≤η≤1),结合主客观权重,求出综合权重[13]。由此得出综合权重(ωi)的公式为:
(5)
式中,η反映了决策过程中,决策者对每个指标的客观权重和主观权重的偏好程度。η越大则表明决策者对该属性重视主观赋权;η越小则表明决策者更看中客观求得的权重。
水源地健康状态是一个定性指标,需要对其量化,以建立评价指标指数与和水源地风险等级之间的关系。通过综合权重的计算及指标数值的归一化处理,得到水源地健康风险综合指数在0~1之间的数值结果。
2.3.2 基于Matlab的BP神经网络模型
BP神经网络(Back Propagation Neural Network)由众多的神经元可调连接权值连接而成,利用梯度搜索技术,以使网络的实际输出值和期望输出值的误差均方差最小[14]。本文按照有导师学习的学习方式对训练样本进行信息处理,网络经过对样本的训练得到参数优化后的参考模型,进而用于解决实际问题。本文设置该模型学习速率为0.05,最大训练次数为2 000次,期望误差为10-3,有16个输入节点、1个输出节点,并根据经验公式得到隐含层层数的取值范围为(5,14],通过逐步验证得到,当模型误差最小时,隐藏层节点个数为8。
(6)
式中,m表示隐藏层节点数,n表示输入层节点数,l表示输出层节点数,α为1到10间的常数。
完成设定后,模型随机选取训练样本,导入各指标参数以及对应的目标健康指数,通过训练网络实现函数值的近似。通过计算隐藏层神经元的输入与输出变量,得到所有神经元节点的加权值与偏差值,随后调用反向传播算法将性能调整到最佳。利用梯度下降法对权重系数ω进行更新,其公式为:
(7)
(8)
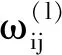
其中J(ω,b)求得的是每个经过模型的输入值对应的输出值与实际对应y(标准答案)的欧式距离。整体代价函数越小则模型越接近目标输出结果。
最后计算神经网络模型的全局误差,得到模型误差值,与预设值进行对比。当误差值达到期望误差或者训练次数达到预设值则结束训练。其全局误差δ计算公式为:
(9)
式中,m表示训练样本数; q表示目标值总数;hn(k)表示第k个样本的第n个目标值;yn(k)表示第k个样本第n个实际输出值。
经过多次训练后的神经网络模型达到预期的精度要求,即可建立起较为稳定的各输入指标间的关系网络,实现对水源地风险的预测。
3 结果与分析
3.1 水源地健康风险综合评价体系的建立
3.1.1 评价指标体系的建立
水源健康主要体现在水量安全、水质安全、生物安全、管理安全以及对人体健康的风险安全。本文根据浙江省2015年建立的《重要饮用水水源地安全保障评估指标体系》,基于水量、水质、监控、管理四个角度对水库水源地健康进行综合评价,同时根据水库水源地特有的防洪防涝特征,初步构建了一套水源地健康评价指标体系,分为“总目标—子目标—指标”三层结构。可从自然结构、水体状况、生物组成、功能与管理四个方面构建,如表1所示。
其中,水体状况和生物组成的评价指标具有普适性,自然结构和功能与管理需要根据水源地类型的不同,进行指标相应的取舍与替换,如河流型水源地滨岸带的土地利用类型差异、地下水型水源地的管理方式差异等。

表1 水源地健康风险综合评价指标体系Tab.1 Comprehensive evaluation index system of drinking water source health risk
3.1.2 评价等级的构建
病限值通常是用来表示病情严重程度的等级分界线,即各种状态之间的临界值。科学合理的病限值对于评价与预测的准确性具有重大影响。本文依据理论研究中病限设置的具体描述以及水库水源地的现状特征值、发展规划值、国家地区管理要求,应用模糊数学理论,将水库水源地健康程度分为健康(1~0.65)、亚健康(0.65~0.4)、轻病(0.4~0.2)、重病(0.2~0.1)和病危(0.1~0)等5个等级,各等级对应于绿色、蓝色、黄色、橙色和红色5个风险评判等级。具体等级见表2。

表2 水源地健康等级与风险评判Tab.2 Health grade and risk assessment of drinking water sources
3.2 基于综合权重评价法的水源地健康指数计算
本文以综合权重评价法得出6个实测时段共72组数据的健康指数。首先通过对16个评价指标的归一化计算得出评判指标值,随后根据综合权重法得到各指标权重,从而计算出库区的健康指数,得出库区的风险状况。以2018年10月的指标数据为例,通过计算得到各指标综合权重系数如表3所示,通过综合权重评价法得到各水域的健康指数如表4所示。根据综合权重分析结果,C9(蓝绿藻覆盖率)和C11(水质质量指数)的变化对水源地健康指数具有最为显著的影响。
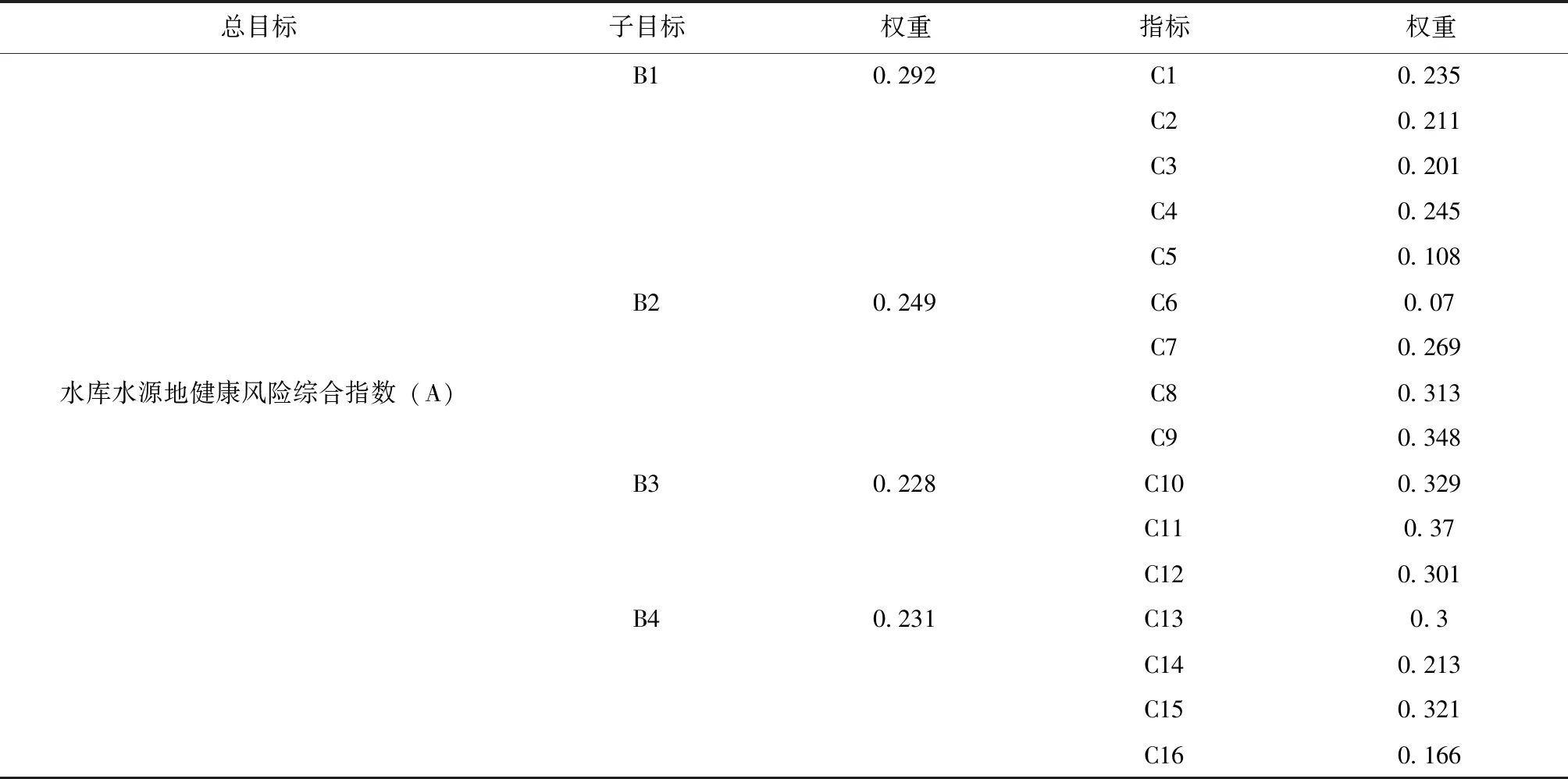
表3 综合权重系数Tab.3 Comprehensive weight coefficient

表4 库区健康指数Tab.4 Health index of reservoir area
续表4
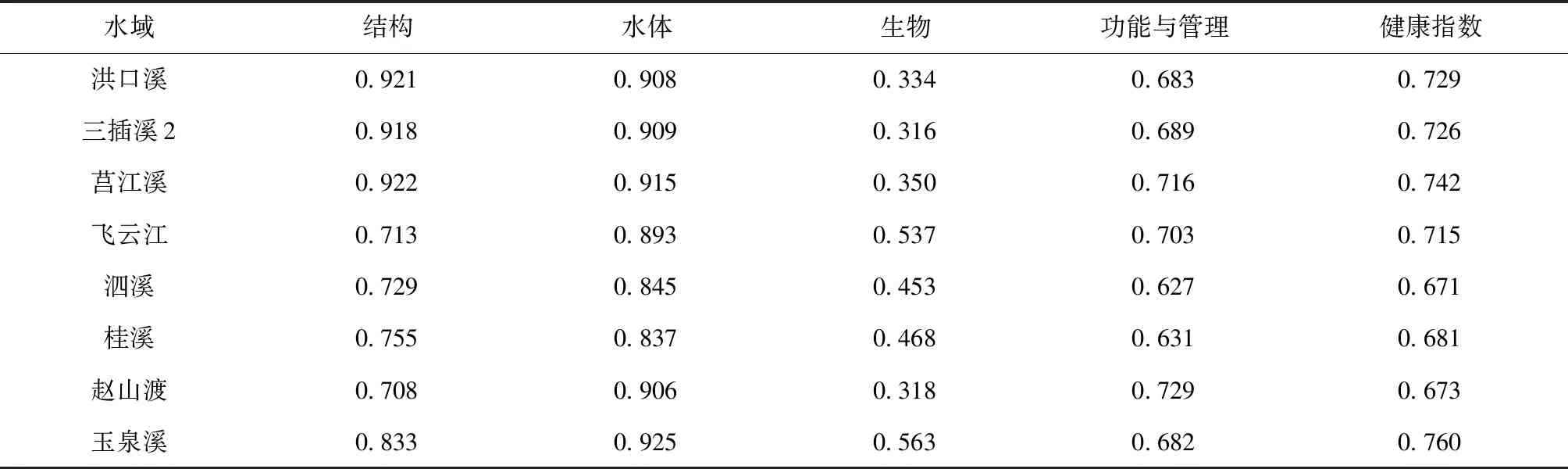
水域结构水体生物功能与管理健康指数洪口溪0.9210.9080.3340.6830.729三插溪20.9180.9090.3160.6890.726莒江溪0.9220.9150.3500.7160.742飞云江0.7130.8930.5370.7030.715泗溪0.7290.8450.4530.6270.671桂溪0.7550.8370.4680.6310.681赵山渡0.7080.9060.3180.7290.673玉泉溪0.8330.9250.5630.6820.760
3.3 基于模糊神经网络的水源地健康指数预测
将2017年7月、2017年10月、2018年1月、2018年4月和2018年7月的5次12片水域共60组调查数据作为训练样本,2018年10月的12组调查数据作为预测样本;16个评价指标的数据集作为输入数据矩阵,水源健康指数作为目标输出矩阵,预测出12片水域2018年10月的水源健康指数预测值。通过Matlab软件构建神经网络模型进行训练模拟,可以得到系统自动生成的12片水域训练误差变化曲线,以玉泉溪水域为例,如图2所示,当目标误差小于10-3或多次迭代趋于平稳时,训练结束,其余11片水域均呈现相似趋势。同时获得训练过程中12片水域的60组预测值与计算值的对比曲线如图3所示。通过预测值与指标计算值的回归分析,复相关系数R保持在0.99以上,如图4所示,模型稳定性较好,该神经网络模型具有良好的预测精度。
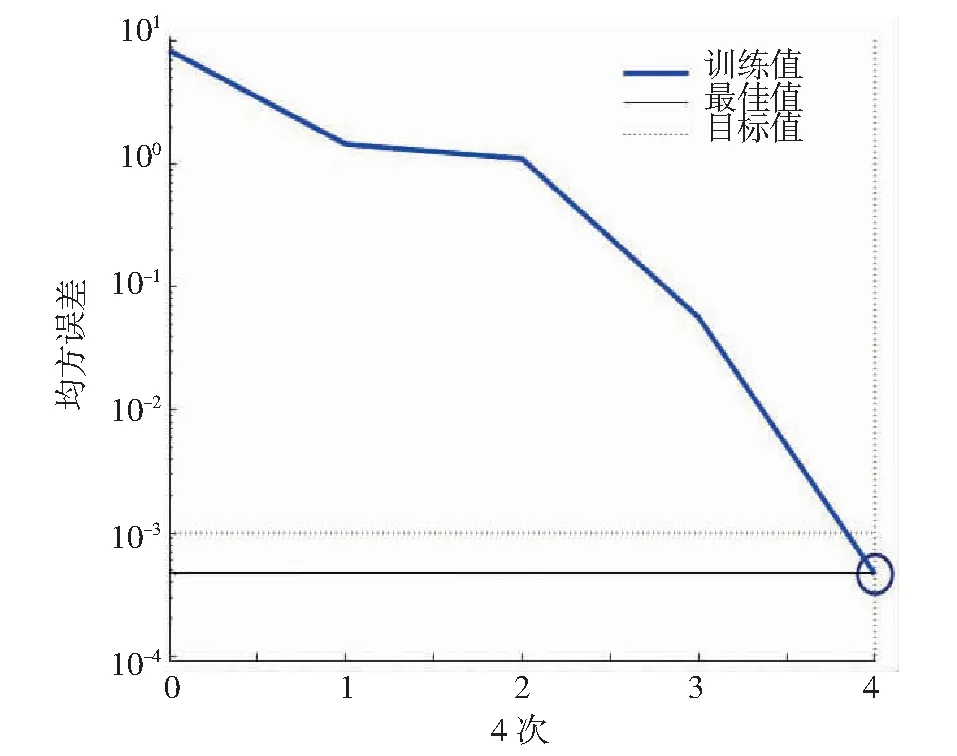
图2 误差变化曲线Fig.2 Curve of error variation
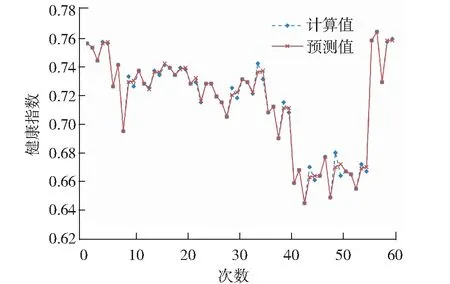
图3 训练样本中健康指数预测值与计算值的比较Fig.3 Comparison of predicted and calculated values of fitness index

图4 预测值与计算值回归分析Fig.4 Regression analysis of predicted and calculated values
3.4 综合指标计算值和BP神经网络预测值的对比分析
将最终得到的预测样本预测值与综合指标法的计算值进行对比评价,如表5所示。对12片水域健康指数的预测值与计算值进行相关性分析,得到
R2=0.969,P<0.001,两者存在极显著相关关系。从评价结果上看,珊溪(赵山渡)库区水源整体显示为健康状态,风险评判为绿色,表明本文研究时段内,该库区可以满足生活供水与农业灌溉的需求,但是泗溪、桂溪和赵山渡局部水域健康指数逼近临界值,存在一定的安全风险。同时根据当地水文部门的调查报告,在取样时间段内未发现重大水污染事故,因此,该饮用水源健康风险情况与模型预测相吻合,神经网络模型对饮用水源健康的预测具有较好的效果。
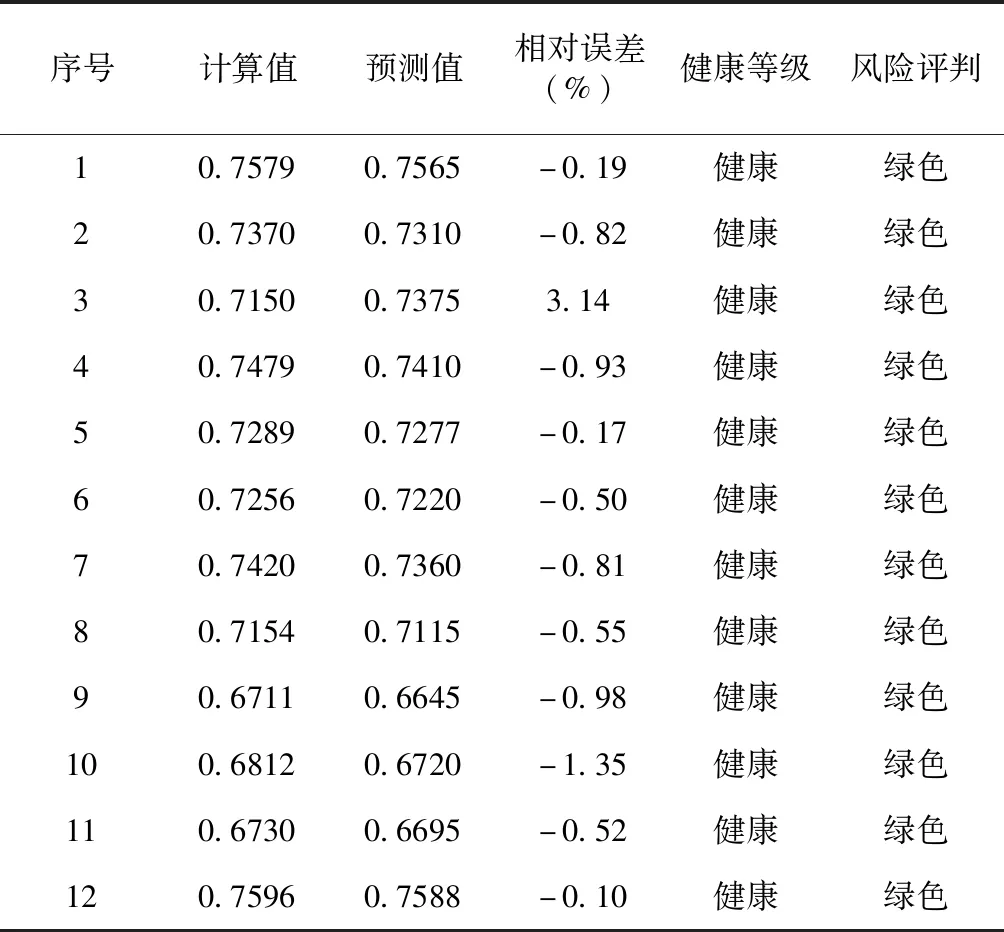
表5 预测样本中健康指数预测值与计算值的比较Tab.5 Comparison of the predicted and calculated health index values in predicted sample
4 结 论
4.1 本文根据综合权重评价法以及BP神经网络算法自2017年7月以来对珊溪(赵山渡)库区进行了6次水源地健康风险评价,以一个季度为一个周期,结果均显示该水库水源地为健康状态。同时,综合权重分析结果表明,蓝绿藻覆盖率和水质综合质量指数的变化会对水源健康指数产生显著影响,水库管理部门需加强对库区周边农业废料的管控,防止水体的富营养化。
4.2 神经网络与模糊评价相结合对饮用水源健康风险进行预测,兼具高效性与实用性,为大批量指标的综合利用提供了新的思路。根据对珊溪(赵山渡)库区的验证分析,证明了神经网络模型在饮用水源健康风险预测中的可行性。在经过更长时间、更多批次的数据学习后,模型的预测精度将得到进一步提升,为饮用水源地管理部门制定相应政策提供有价值的参考。
