基于BiGRU_MulCNN 的农业问答问句分类技术研究
2020-07-07赵春江吴华瑞缪祎晟杨宝祝
金 宁 赵春江 吴华瑞 缪祎晟 李 思 杨宝祝
(1.沈阳农业大学信息与电气工程学院,沈阳110866;2.沈阳建筑大学研究生院,沈阳110168;3.国家农业信息化工程技术研究中心,北京100097;4.北京农业信息技术研究中心,北京100097;5.沈阳建筑大学党委组织部,沈阳110168)
0 引言
随着移动互联网产业的高速发展,各类移动应用程序产生的评论信息、微信朋友圈、问答社区用户提问等短文本数据呈爆发式增长[1]。在农业领域,“中国农技推广App”作为农业信息服务方面的移动应用程序,为农业技术人员及农户搭建了学习交流平台,帮助农户实时获得在线农业技术指导。但大多数农户不会选择提问分类,部分已选择的也存在分类不准确的问题,从而影响了农业技术指导的高效性、精确性。“中国农技推广”每天增衍提问数量近万条,人工筛选将消耗大量的人力、物力,且无法高效、准确实现分类。因此,利用计算机技术解决农户提问的自动分类是“中国农技推广”当前亟需解决的问题。农业问答问句的自动分类是实现农业智能问答的关键技术环节,是自然语言处理和农业大数据智能研究领域的热点研究方向。
目前,深度学习方法[2-5]和机器学习方法[6-8]在解决文本分类问题上均取得了一定成果。在深度学习方法中,KIM[9]将文本当作固定长度的图像,运用卷积神经网络(Convolutional neural networks,CNN)有效解决了文本分类问题。随后,研究人员以此为基础,不断优化文本分类模型,捕获高层次的文本特征[10-11]。由于CNN 模型未考虑文本的语序,因此无法获得文本上下文信息,制约了文本分类效果。相比于CNN 模型,循环神经网络(Recurrent neural network,RNN)模型可对前后信息进行记忆,并应用于当前的计算,更适合处理序列化的文本数据,MIKOLOV 等[12]运用RNN 模型实现了文本分类。但RNN 长期依赖学习特征,容易出现梯度弥散的问题,为此,研究人员提出了长短期记忆神经网络(Long/short term memory,LSTM)和门控循环单元神经网络(Gated recurrent units,GRU)等优化模型,并应用于文本分类问题,取得了较好的分类效果。RNN 模型存在计算复杂、内存占用大、训练耗时长、对局部关键信息提取不敏感等问题。为更好地提取文本关键信息,注意力机制(Attention)[13]被广泛应用于文本分类问题[14-15],其通过模仿人脑的注意力分配机制,计算不同词向量的权重,使关键词语的权重更高,从而获得高质量的文本特征。在机器学习方法中,K 最近邻算法[16]、朴素贝叶斯模型[17]、隐马尔科夫模型[18]等方法广泛应用于文本分类,但存在严重的数据稀疏问题,影响了分类效果。在农业领域,由于受农业大数据源问题的限制,相关研究仍处于起步阶段。魏芳芳等[19]运用支持向量机算法,周云成等[20]运用朴素贝叶斯算法,实现了机器学习算法对中文农业长文本的自动分类。由于机器学习方法需要人工提取特征,使其特征工程往往仅适用于特定数据集,不具备深度学习方法的适应性和易迁移性。此外,赵明等[21]针对番茄病虫害问答系统问句分类问题,提出了基于双向门控循环单元神经网络(Bi-directional gated recurrent unit,BiGRU)的短文本分类模型,分类准确率明显提升;梁敬东等[22]利用LSTM 算法计算问句相似度,提高了问答系统回答的准确性;许童羽等[23]提出一种基于注意力机制优化的序列到序列(Sequence to sequence,Seq2Seq)问答模型,提高了水稻病虫害问答的准确率;张明岳等[24]利用CNN 提取文本特征,用于判断问句是否有效,识别准确率明显提升。上述研究为深度学习方法在农业领域的文本分类提供了可行性依据和参考,但在文本特征提取方面仍存在不足,特征提取方法较为单一,未能有效解决短文本的特征不足问题,并且相关模型均在特定的农业领域应用,未在涉及多类别的农业问答数据集中进行验证。
针对农业问答问句短文本词汇量少、特征稀疏性强、数据量大、噪声大、规范性差的特点,本文对短文本特征词汇进行拓展,根据词汇重要程度加权表示词向量,利用BiGRU 和CNN 提取文本特征,进一步优化和改进神经网络模型结构及参数,构建一种基于混合神经网络的短文本分类模型,以实现农业问答问句在多个类别上的精准自动分类。
1 BiGRU_MulCNN 文本分类模型构建
本文提出的BiGRU_MulCNN 模型如图1 所示。该模型主要由文本预处理层、双向门控循环单元层(BiGRU)和多尺度卷积神经网络层(MulCNN)3 部分组成。与传统深度学习分类模型相比,本文所提分类模型增加了对文本的加权预处理,使用TF-IDF算法扩充文本特征词语,根据词语的重要程度计算加权词向量;采取多种方法提取文本特征,利用BiGRU 获取词语的上下文信息,构建多尺度并行CNN 以便提取文本不同粒度的局部特征。
1.1 文本预处理
由于计算机无法将中文文本直接作为分类模型的输入进行分类计算,因此需要先将中文文本转换成数字向量。为了尽可能保留文本特征及语义信息的完整性、全面性,本文首先对提问文本进行去噪、分词等预处理操作,然后运用Word2vec[25]方法将分词结果转换为词向量。本文提出的文本预处理流程如图2 所示。
1.1.1 文本分词
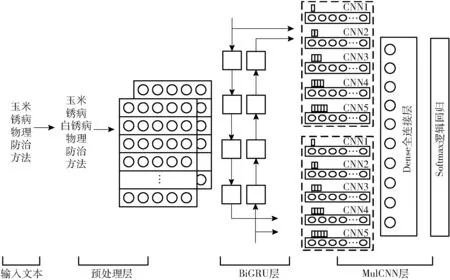
图1 BiGRU_MulCNN 模型结构图Fig.1 Schematic of BiGRU_MulCNN

图2 文本预处理流程图Fig.2 Flow chart of data preprocessing
本文采用Python 的Jieba 分词库对文本进行分词。由于中文的分词结果受语义和语境影响较大,为提高分词的准确度,在分词前加载了停用词表,去除文本中的停用词、特殊字符及空格等不利于特征提取的噪声,减少文本的冗余信息[26]。针对农业问答数据集专业词汇多的特点,本文加载了搜狗农业词汇大全作为分词字典[27]代替基础分词库,提高对农业专业词汇的识别度。
1.1.2 特征词扩展
扩展短文本的特征是提高分类正确率的有效方法[28]。问句中每个词语的重要程度均不相同,重要程度高的词语更能体现提问的语意,更具有代表性。本文采用TF-IDF 方法计算每个词语的重要程度,提取问句中最具有代表性的特征词。TF-IDF 方法可保留文本中具有代表性的低频词语,去除区分度低的高频词,词频(TF)表示词语在全部词语中出现的频率,计算公式为

式中 fi,j——词ti的词频
ni,j——词ti在文本中出现的次数
m——文本包含的单词数
nm,j——词tm在文本中出现的次数
逆文档频率IDF 表示词语的普遍程度,计算公式为

式中 qi——逆文档频率
D——文本总量
dj——包含词ti的文本
j——包含词ti的文本数量
TF-IDF 值为fi,j与qi的乘积,计算公式为

式中 si,j——词ti的TF-IDF 值
将每个问句中TF-IDF 值最高的词语作为问句的特征词。计算其他词语与该特征词的相似度,选择相似度高于80%且排序前5 的词语对文本进行特征词扩充。
1.1.3 加权词向量表示
Word2vec 是近年来较为流行的中文文本分布式表示方法[29]。Word2vec 可根据输入的目标词语,预测上下文信息,并将意思相近的词映射到向量空间中相近的位置,有效解决了One-Hot 方法词向量相互孤立和维度高的问题。本文采用Word2vec方法的Skip-gram 模型训练分词结果,将中文词语转换为低维、连续的词向量。
为进一步突出不同词语对问句含义的贡献程度,本文将词语的TF-IDF 值与Word2vec 词向量的乘积作为该词语的加权词向量。
1.2 文本表示
本文先将问句中包含词语的加权词向量连接起来,组成加权文本向量组,将其作为BiGRU 模型的输入。为充分考虑中文文本语序对语义的影响,本文利用双向门控循环单元神经网络挖掘当前词语的上下文信息,获得表达更为精确、特征更为丰富的文本向量,最后将BiGRU 模型的输出与原加权文本向量组连接,组成新的文本向量。
1.2.1 加权词向量文本
获得每个词的加权词向量后,将文本中的每个词替换成其对应的词向量,组成加权文本向量组。由于问句的长短不一,需统一问句长度后,方可输入到神经网络模型中训练。根据对文本的统计,99.9%的问句长度均少于100 个词,因此将文本问句的长度设置为100,其余提问长度不足的,填充0补齐文本向量,长度超过100 的只取前100 个词。门控循环单元神经网络结构图如图3 所示。

图3 门控循环单元神经网络结构图Fig.3 Schematic of GRU
1.2.2 BiGRU 模型文本
GRU[30]是一种特殊的循环神经网络,能够有效解决循环神经网络中无法长期记忆和反向传播的梯度问题。与LSTM 相比,GRU 具有参数少、结构简单、便于计算、收敛性强的特点,其具体结构如图3 所示。
GRU 结构中包含2 种状态和2 个控制门,分别是隐含状态h、候选状态、重置门r 和更新门z,其中更新门用于控制前一时刻的状态信息传入到当前状态中的程度,重置门用于控制忽略前一时刻状态信息的程度。在t 时刻,的计算依赖于输入词向量xt和ht-1,rt作用于ht-1,并根据ht-1的重要程度控制过去隐含状态保留程度。rt越大,表示ht-1对的影响程度越大。GRU 参数计算公式为

式中 wr——重置门权重 xt——输入词向量
wz——更新门权重
ht——隐含层状态
rt——重置门 zt——更新门
σg——Sigmoid 函数
w——权重矩阵
⊙——对应元素相乘符号
GRU 神经网络是从前向后单向输出的。这与中文语意理解方式略有不同,中文语意与当前文字的上下文均有关系。在文本分类任务中,如果当前时刻的输出能与前后时刻的状态都产生联系,会更有利于文本深层次特征的提取,突出文本关键信息。根据中文语意理解的特点,本文利用BiGRU 模型提取问句的特征向量。BiGRU 模型是由两个单向且方向相反的GRU 组成的神经网络模型,其输出由两个不同方向的GRU 的状态共同决定。文本在t 时刻输入的第i 个句子的第j 个单词的词向量为ctij,其隐含层状态ht由前向隐含层状态hft-1和反向隐含层状态hrt-1加权得到,计算过程为

式中 GRU(·)——词向量的非线性变换函数
yt——前向权重矩阵
vt——反向权重矩阵
bt——偏置
1.3 MulCNN 模型构建
在BiGRU 模型获得词语上下文信息后,构建了MulCNN 模型,进一步提取文本高维度、多尺度的局部特征。MulCNN 模型由多个一维卷积层、池化层、全连接层和分类层组成。
1.3.1 卷积层
卷积层的作用是在设定的窗口范围提取局部特征,利用卷积核对输入向量进行卷积计算,获得特征输出。在一维卷积神经网络中,卷积核长度为词向量的维度,高度为设定窗口的大小,卷积计算公式为

式中 cj——窗口特征值
f——激活函数 xj——词向量
k——卷积核 b——偏置
针对短文本语义依赖距离短的特点[31],为了能够提取文本的多粒度局部特征,本文设置了宽度不同、数量不同的多个卷积核窗口的卷积神经网络。将不同粒度的特征值合并,作为卷积层计算的特征值。
1.3.2 池化层
由于在卷积层选择了多个不同窗口宽度、不同数量的卷积核,使得卷积计算后生成的特征图维度不一致,因此本文在模型中增加了池化层。池化层将卷积层提取的文本局部特征进一步整合,在缩减特征图尺寸、提高计算速度的同时,使特征值获得了全局信息,提高了所提取特征的鲁棒性,控制了过拟合问题发生。本文利用全局平均池化和全局最大池化方法进行池化操作,即抽取每个特征图的最大值和平均值,将两者拼接后作为该特征图的特征值。
1.3.3 全连接层
全连接层进一步对特征值进行抽象,将池化层的全部输出作为输入,其中每一个神经单元都与池化层的每一个单元对接,并通过激活函数ReLu 将池化层向量转换成长向量,将文本从特征空间映射到标记空间。
1.3.4 分类层
使用Softmax 函数作为特征分类器。Softmax 函数对全连接层的输出进行归一操作,映射到(0,1)区间内,得到每类特征输出的估算值。
2 试验与结果分析
2.1 试验数据
从“中国农技推广”农技问答模块2019 年不同月份的提问数据中随机提取20 000 条作为试验数据,提问类别具体分布情况见表1。由表1 可知,试验数据涉及类别多,覆盖了病虫草害、栽培管理、养殖管理等12 个类别,并且数据分布不平衡,病虫草害、栽培管理等类别数据量达几千条,而屠宰加工等类别数据量仅有几十条,数据量相差悬殊,增加了文本分类的难度。
从每个类别的问句中随机选择10%作为测试数据集,共2 000 条。在剩余数据中每个类别选择90%的数据作为训练数据集,共16 200 条;10%的数据作为验证数据集,共1 800 条,用于验证模型训练及优化情况。测试数据集、训练数据集和验证数据集均无重复交叉,因此测试数据集的试验结果可作为模型分类效果的评价指标。

表1 问题类别分布Tab.1 Distribution of question category
2.2 参数设置
使用128 维词向量表示中文词汇,设置问句最大长度为100。BiGRU 层设定GRU 输出特征维度为128 维,并选择concat 模式连接GRU 的前向和后向输出。
由1.3 节可知,MulCNN 模型在同一窗口下包含多组卷积核个数不同的卷积神经网络。试验中,相同窗口下设置了2 组卷积神经网络,不同数量的卷积核得到的试验结果见表2。当卷积核尺寸为(96,160)时,分类效果最佳。

表2 MulCNN 模型卷积核的确定Tab.2 Determination of kernel size in MulCNN
设计多个卷积窗口尺寸不同的卷积层,用于提取不同粒度的文本特征。具体卷积窗口尺寸设置情况及试验结果如表3 所示。当卷积窗口数为5,窗口宽度为1、2、3、4、5 时取得了最好的分类效果。

表3 MulCNN 模型卷积窗口尺寸的确定Tab.3 Determination of filters in MulCNN
为防止过拟合,对BiGRU 和MulCNN 均进行批规范化处理,全连接层单元丢弃比例设定为0.5,训练过程中通过降低神经网络的学习率来提高性能,每隔10 次训练1 次学习率减小到原来的1/10。
2.3 对比模型
将BiGRU_MulCNN 与9 种近年来在文本分类领域和农业领域常用的分类模型进行比较,9 种分类模型可总结为CNN 分类模型、RNN 分类模型和混合神经网络分类模型3 类。
CNN 分类模型:TextCNN 模型是将CNN 首次应用于文本分类的模型;DCNN[32]模型利用K 最大池化的动态CNN 进行文本分类;DPCNN[33]模型利用深层CNN 进行文本分类;Agro-CNN 模型[24]是针对农业问答有效性的识别模型。
RNN 分 类 模 型:TextRNN[34]模 型 利 用 标 准LSTM 进行文本分类;AttBiRNN[35]模型利用BLSTM并引入注意力机制进行文本分类;N-BiGRU 模型[21]是针对番茄病虫害问答系统的多层BiGRU 分类模型。
混合神经网络分类模型:RCNN[36]模型利用前向和后向RNN 结合CNN 进行文本分类;C-LSTM[37]模型利用CNN 获得高维度词表示,结合LSTM 进行文本分类。图4 为不同模型下文本分类正确率的对比。
2.4 结果分析

图4 不同模型下文本分类正确率对比Fig.4 Comparison of accuracy in different models
图4 展示了10 种试验模型在Word2vec 文本及TF-IDF 加权文本表示下的文本分类正确率。正确率是对全部数据集分类结果准确性的判断,一般用于衡量模型的整体分类效果。如图4 所示,针对农业问答问句短文本数据集,本文提出的TF-IDF 加权文本表示方式在10 种试验模型的分类正确率均大幅超过Word2vec 文本表示方式,特别对于RNN 分类模型的正确率提升明显。本文提出的BiGRU_MulCNN 模型在Word2vec 文本表示方式和TF-IDF加权文本表示方式下均取得了最优的结果,正确率分别达到了93.60%和95.90%,相比于其他9 种对比模型优势显著。在TF-IDF 加权文本表示方式下,CNN 分类模型中Agro-CNN 正确率最高,达到94.15%;RNN 分类模型中N-BiGRU 正确率最高,达到93.90%;混合神经网络模型中RCNN 正确率最高,达到93.85%。
图5 展示了在TF-IDF 加权文本表示下,各个类别分类模型中正确率最高的Agro-CNN、N-BiGRU、RCNN、BiGRU_MulCNN 模型对12 个问题类别分类的F1 值。F1 值表示分类精确率和召回率的调和平均数,常用于衡量模型分类性能。如图5 所示,BiGRU_MulCNN 模型的F1 值在病虫草害、市场营销、动物疫病等9 个类别中均为最高,整体分类效果明显优于其他模型。在病虫草害、栽培管理等试验数据量充足的数据集中,本文模型的F1 值略高于其他模型;在动物疫病、养殖管理、农业机械等数据量较少的数据集中,本文模型的F1 值明显高于其他模型,说明BiGRU_MulCNN 模型在数据量不充足的情况下,仍然能够有效提取短文本的特征进行分类。但是在饲料营养、屠宰加工等试验数据集过少的情况下,4 种试验模型表现均不稳定,说明深度学习分类模型需要大量数据集支撑,数据量过小会影响分类效果。

图5 4 种试验模型对于不同问题类别分类的F1 值对比Fig.5 Comparison of F1 values of four models for different question categories
在12 个问题类别中,栽培管理类别虽然试验数据量充足,但分类效果远不如数据量较少的市场营销、动物疫病等类别。通过分析试验文本可知,栽培管理类别涵盖了多种复杂的农业生产操作,覆盖面过大,导致了该类别的特征不明显,影响了分类效果。表4 统计了4 种试验模型在栽培管理类别的精确率、召回率和F1。由表可知,BiGRU_MulCNN 模型的精确率、召回率和F1 均取得了较好的结果,其中精确率和F1 远远高于其他模型,说明了该模型具有较强的鲁棒性。

表4 4 种试验模型在栽培管理类别的比较Tab.4 Comparison of four models in cultivation management categories %
如图6 所示,试验数据集的规模直接影响了模型的分类正确率。随着数据量的增加,各分类模型的正确率均随之增加,其中N-BiGRU 和BiGRU_MulCNN 在数据量较小的情况下分类效果较好,BiGRU_MulCNN 模型在大数据集上分类效果优势明显。
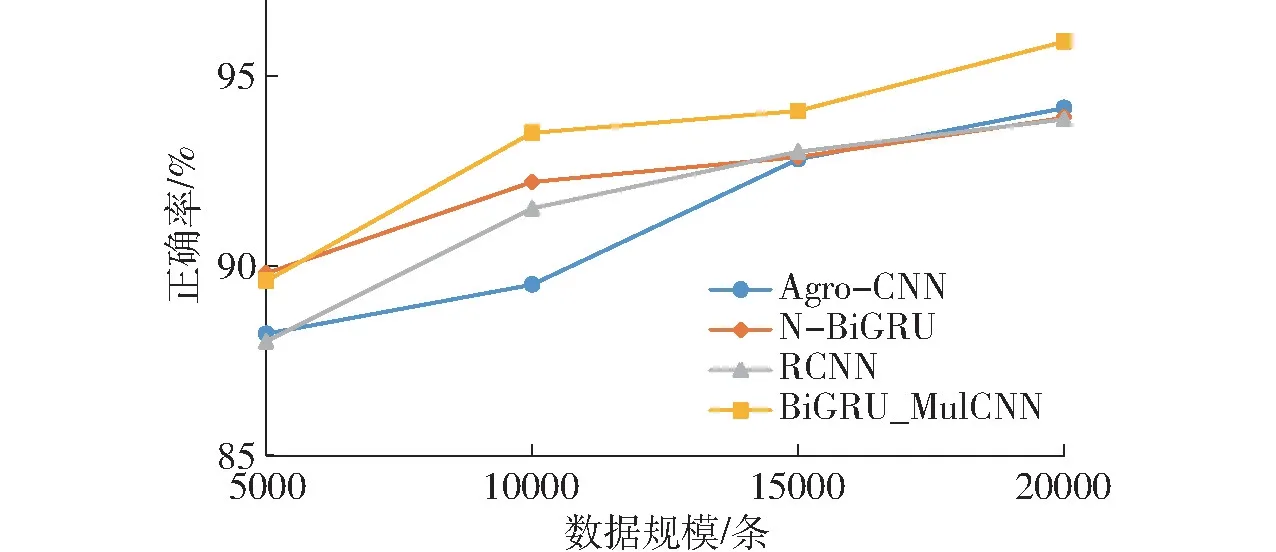
图6 不同数据规模的模型分类正确率Fig.6 Classification accuracy of models for different datasets
如表5 所示,4 种试验模型对2 000 条测试数据的响应时间达到了快速反馈问题分类的要求。其中RCNN 模型由于其结构简单,模型层数较少,在训练时间和测试时间上的优势明显,但其正确率明显低于BiGRU_MulCNN 模型;以CNN 为基础的Agro-CNN 模型的训练时间较短,以RNN 为基础的NBiGRU 模型及基于混合神经网络的BiGRU _MulCNN 模型的训练时间较长。由于分类模型的训练可以离线运行,在分类结果反馈时间基本相同的情况下,分类模型更关注分类正确率的提升。

表5 4 种试验模型的离线训练时间和测试响应时间Tab.5 Offline training time and test time comparison of four models s
3 结论
(1)提出的BiGRU_MulCNN 模型满足实际应用需求,可有效解决农业问答问句在多个类别上的自动分类问题,对测试集的正确率达到95.9%,大幅提高了分类正确率。在数据量不足、数据特征不明显的数据集上仍取得了较好的分类效果,切实解决了传统人工分类耗时、耗力的问题,实现了对农业问答问句的智能分类。
(2)对短文本进行特征词扩充,并根据词语重要性对文本词向量进行加权表示,可明显提高分类的正确率,有效解决了短文本特征不足的问题。
