基于IFSSD 卷积神经网络的柚子采摘目标检测模型
2020-07-07肖德琴蔡家豪林思聪杨秋妹谢晓君郭婉怡
肖德琴 蔡家豪 林思聪 杨秋妹 谢晓君 郭婉怡
(1.华南农业大学数学与信息学院,广州510642;2.广州中医药大学医学信息工程学院,广州510006)
0 引言
我国是柚子种植面积最大的国家,柚子产量仅次于美国,位于世界第二位[1]。自2000 年以来,我国柚类产品得到国际市场的认可,柚类出口量急剧增长,具有巨大的发展前景。在柚子的生产过程中,采摘是最耗时费力的过程,后续的存储和加工过程直接取决于采摘效果,所以保证柚子采摘质量成为关键环节。目前,国内的水果采摘主要是由人工完成,工作强度大,且效率低下[2]。有研究表明,用于采摘过程的费用占生产总费用的50% ~70%。随着水果的大面积种植,传统的人工采摘方式已经不能满足生产需求,研究水果采摘机械化意义重大[3]。
在自然环境下,快速、准确识别与定位柚子是实现柚子自动化采摘的重点研究方向之一,因此,研究者提出一系列水果检测识别方法[4-6]。深度学习在农业领域取得了显著的进展[7-9]。在传统方法中,柚子的颜色、形状以及纹理特征因受自然环境的影响而产生变化,所以很难对柚子进行有效的描述,从而对算法的泛化性产生了极大影响。基于深度学习的方法可以通过学习训练数据的特征来提供准确的结果。深度学习方法已被用于农业研究的各个领域,如FERENTINOS[10]使用卷积神经网络对健康和患病植物的简单叶片图像进行植物疾病检测和诊断。彭红星等[11]使用Res101 结合SSD 构建了深度水果检测模型,对自然条件下的多种水果进行检测识别。然而小目标柚子在图像视野中占比较少,边缘特征不明显,甚至缺失,由于分辨率和信息有限,使得传统基于深度学习的柚子检测算法效果并不理想[12]。同时,常见的目标检测算法是根据重叠度(Intersection over Union,IoU)阈值,从先验框中挑选IoU 小于0.7 和IoU 大于等于0.7 的先验框分别作为正负样本,进行分类网络的训练。然而包含叶子背景的柚子负样本远远大于正样本,导致样本不平衡,使柚子检测模型存在很严重的偏向性。
为此,本文提出一种基于IFSSD 卷积网络的柚子检测模型,对膨大期、成熟期两个阶段的柚子进行检测试验。
1 材料与方法
1.1 试验数据的获取
试验中的柚子图像于2018 年4 月1 日—10 月10 日在广东省梅州市的顺兴果园获得。果园中共种植柚子树1 500 余棵,柚子树随机分布。选用海康威视DS-2CD3T56WD-I3 型摄像头进行拍摄,将4个摄像头固定在离地面3 m 的支架上,摄像头分别向正北、正东、正西、正南4 个方向。支架之间的距离为60 m,共9 个支架。试验设备和现场图如图1所示。拍摄图像的尺寸为1 920 像素×1 080 像素,JPG 格式。于每天09:00—17:00 每隔1 h 拍摄一次图像,其中包含了晴天正午、晴天傍晚以及阴天正午等特殊光照条件,共获得了5 000 幅图像。其中图像中存在枝叶遮挡和果实互相遮挡的图像数量分别为3 563 幅和2 469 幅。

图1 试验设备和现场图Fig.1 Photos of experimental equipment and site
1.2 柚子检测数据集的构建
在5 000 幅柚子树图像中利用随机抽取的方式选择4 000 幅图像,使用Labelme 软件进行标记作为训练集,其他图像作为测试集。
图2 为训练集的样本预处理过程,通过对图像分别进行翻转、平移和裁剪来扩充数据集。

图2 图像预处理Fig.2 Image preprocessing
在柚子训练集中,柚子分为膨大期果实和成熟期果实,如图3 所示,膨大期果实和成熟期果实在颜色上有明显的区分。

图3 膨大期和成熟期柚子果实Fig.3 Grapefruit fruit during expansion and maturity
1.3 基于深度学习的柚子检测算法
1.3.1 InceptionV3 网络
InceptionV3 是Google Inception 系列网络中的一种,该网络在InceptionV2 的基础上提出了一种新的结构,网中网(Network in network,NIN)结构[13]。InceptionV3 是Inception 模块按照NIN 结构构建的一种新型网络。InceptionV3 的Inception 模块如图4所示。
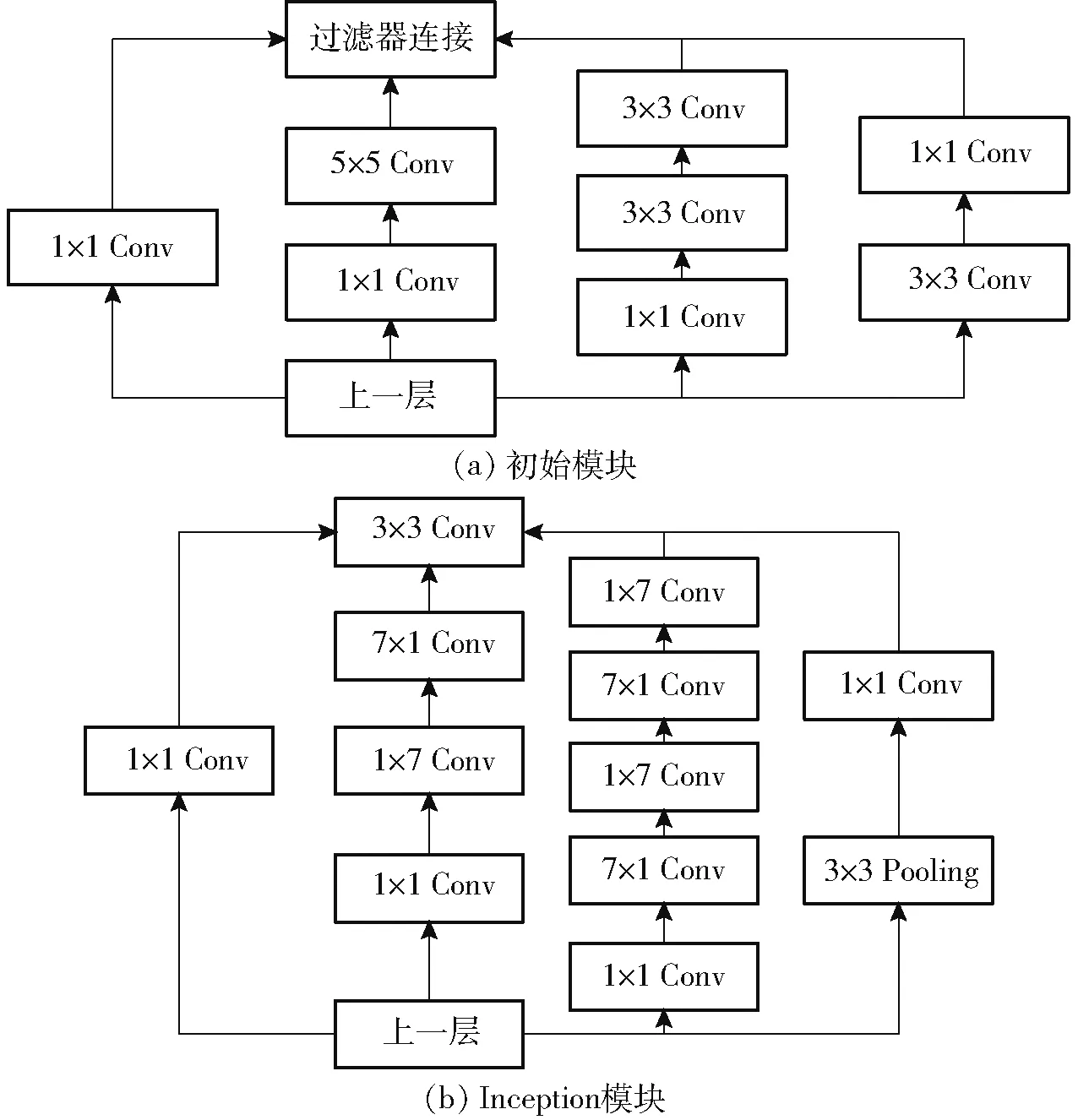
图4 InceptionV3 的Inception 模块结构Fig.4 Structure of InceptionV3 Inception module
如图4 所示,InceptionV3 模块通过提取不同尺度的特征来减少模型的参数数量[14],同时多尺度特征可以提高模型的识别能力。研究证明,卷积核为1 ×1 的卷积层可以通过少量的计算实现特征的转换、提高网络的识别能力以及改变卷积模块输出的通道数[15]。InceptionV3 的第5 ~9 Inception 模块使用更大的卷积核来获取更加抽象的特征。针对于卷积核为7 × 7 且容易产生大量参数的卷积层,InceptionV3 使用1 ×7 卷积层和7 ×1 卷积层,从而提高算法的效率并降低过拟合的风险。试验证明,这种不对称卷积结构可以处理越来越丰富的空间特征并增加特征多样性。
1.3.2 SSD 与FSSD
InceptionV3 网络模型主要是对柚子的成熟情况进行分类,存在一个局限条件就是每幅图像中只能有一个柚子,柚子占据图像的面积要尽量大。为了解决这个问题,许多目标检测方法被提出,例如使用颜色和纹理特征来检测水果。由于柚子等水果是簇状结果,因此在柚子检测过程当中容易发生重叠和误检的情况,使得检测精度大大降低。
目前有许多用于目标检测的深度学习方法被广泛应用于农业领域,如借助区域提议网络实时目标检测算法(Towards real-time object detection with region proposal networks,Faster-RCNN)[16]、通过基于区域的全卷积网络目标检测算法(Object detection via region-based fully convolutional networks,RFCN)[17]、单 镜 头 多 盒 探 测 器 算 法(Single shot multibox detector,SSD)[18]、YOLO 算 法(You only look once,YOLO)[19]以及RetinaNet[20]等。此外,柚子检测对于算法的实时性能和小物体检测有着更高的要求,所以需要在保证精度符合要求的情况下尽量选择效率更高并且对小物体检测更有效的算法。
SSD 是一种在图像中使用同一个深度神经网络进行检测和识别检测目标的算法。SSD 生成一系列尺寸不同的候选框,通过计算标注框与候选框的偏置值来匹配两者,一般每个标注框都会匹配多个候选框。SSD 将IoU 大于0.5 的候选框认为是正样本,其他设置为负样本[21]。
SSD 使用VGG16 作为骨干网络[22],通过 在Conv4_3、FC7、Conv7_2、Conv6_2、Conv8_2 和pool6中提取不同尺寸的特征图来形成多尺度检测,SSD的网络结构图如图5a 所示。其中特征图尺寸为5 像素×5 像素、3 像素×3 像素和1 像素×1 像素,低级特征图有利于小目标的检测,特征图尺寸为38 像素×38 像素、19 像素×19 像素和10 像素×10 像素的高级特征图则有利于大目标检测。SSD 使用通道数为1 024 的3 ×3 卷积层和1 ×1 卷积层代替全连接层和丢失层,从而达到减少模型参数、提高计算效率以及有效防止过度拟合的目的。SSD 的损失函数为
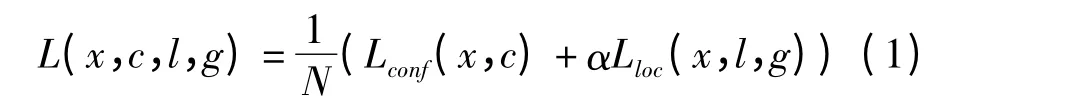
式中 L(x,c,l,g)——总体损失值
x——卷积特征值 c——真实类别
l——预测框的位置坐标值
g——真实框的位置坐标值
Lloc——预测框和真实框间的平滑损失值
N——候选框的数量
Lconf——多类置信度下的softmax 损失值
α——Lloc的权重
Multibox Loss 由两部分组成,前者使用了softmax 进行分类损失计算,后者通过局部损失来预测位置。
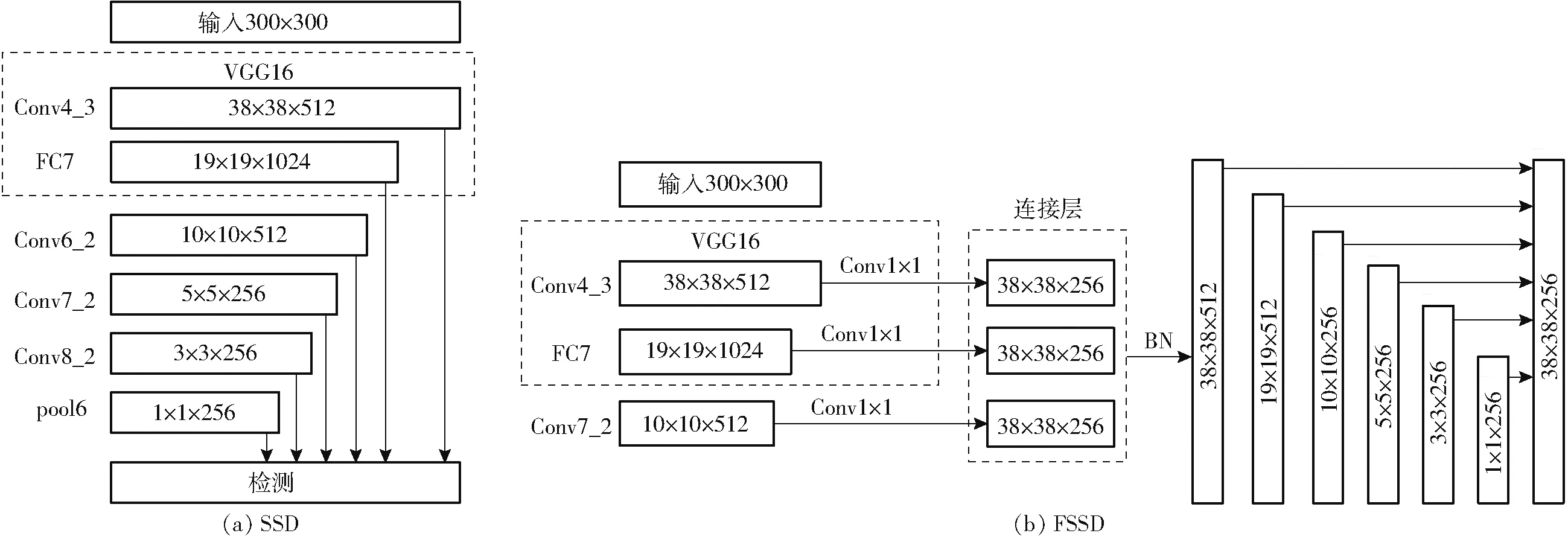
图5 SSD 和FSSD 模型的结构Fig.5 Model structure of SSD and FSSD
SSD 为柚子检测任务提供了坚实的基础,其主要优点是检测速度快。然而,试验表明,SSD 存在以下问题:较小的目标难以识别;一些背景区域被识别为目标对象;重复识别目标。为了解决这些问题,SSD 模型被修改为FSSD 模型且不增加模型参数的数量,并降低检测速度。
FSSD 模型的提出者认为SSD 模型中用于预测的每个层之间的关系是相互独立的[23]。FSSD 模型是将这些层与不同比例的特征图进行融合[24],以便它们相互通信并提高准确性。但是,这种方法不适合在FSSD 模型中融合小于10 ×10 的特征映射,因为几乎没有要合并的信息。合并3 个较大层的特征图以生成38 像素×38 像素的特征图,并生成特征金字塔网络(Feature pyramid networks,FPN)[25]。最后,FSSD 模型从FPN 中提取特征。
FSSD 模型的结构如图5b 所示。FSSD 模型以VGG16 作为主要骨干网络。Conv7_2 的特征映射变为10 ×10。FC7 和Conv7_2 使用双线性插值将特征图尺寸调整为38 像素×38 像素,然后将它们与Conv4_3 连接,在该步骤中,合并层的通道数为768(256 +256 +256)。然后BN 作用于合并层,该层的通道数减小到512。另外使用5 个卷积层来减小特征图的尺寸。最后,获得6 种不同尺寸特征图(38 像素×38 像素、19 像素×19 像素、10 像素×10 像素、5 像素×5 像素、3 像素×3 像素和1 像素×1 像素),并将它们用于多尺度预测。这种方法可以将浅层细节特征与高级语义特征相结合,可以比SSD模型更好地识别小物体[26],并降低误检率。但FSSD 模型的速度比SSD 模型的速度略有下降。
1.3.3 IFSSD 模型建立
在本文中,只需要判断检测目标是否是柚子,并不需要进行多类别分类。柚子的特征相对简单,可以简化模型,所以本文选择InceptionV3 作为IFSSD的骨干网络。IFSSD 模型结构如图6 所示。
(1)InceptionV3 深度网络优化
为了减少参数数量和提高对小目标的检测效果,本文对InceptionV3 进行了调整,以实现检测器基于不同感受野的多尺度检测。本文对mixed7 层进行了删除。IFSSD 模型在mixed6 层之后添加1 ×1 卷积,步长为2,通道数为768,然后进行批量归一化。新添加的图层mixed6_s 的特征图尺寸为18 像素×18 像素。mixed7 层的特征图尺寸从原来的35 像素×35 像素变成18 像素×18 像素。在mixed7之后加入卷积核为1×1、步长为2、通道数为768 的卷积层。mixed7_s 的特征图尺寸为9 像素×9 像素。图6 中改进后的网络结构用黄色方框表示。
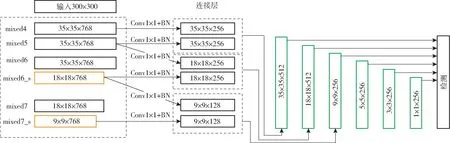
图6 基于IFSSD 的柚子检测模型结构Fig.6 IFFSD-based grapefruit detection model structure
IFSSD 模型与FSSD 模型类似,都对较大的特征图进行合并。在IFSSD 模型的InceptionV3 中,分别选择特征图尺寸各不相同的4 层模块,分别是mixed4、mixed5、mixed6_s、mixed7_s。在第1 个连接层中,卷积核为1 ×1、步长1、通道数为256 的卷积层被应用于mixed4 和mixed5。这样做的目的是在不改变特征图尺寸的前提下减小模型参数,从而减少模型中的参数数量并增加增强模型的非线性识别能力。卷积后生成的特征图尺寸为35 像素×35 像素,然后将mixed4 和mixed5 卷积生成的特征图合并到一起。在第2 个连接层中,在mixed5 模块之后添加一层卷积核为1 ×1、步长为2、通道数为256 的卷积层,其生成的特征图尺寸为18 像素×18 像素。在mixed6_s 之后添加一个卷积核为1 ×1、步长为1、通道数为256 的卷积层。其生成的特征图尺寸为18 像素×18 像素。然后,对两个特征图进行合并。在第3 个连接层中,一个卷积核为1 ×1、步长为2、通道数为128 的卷积层被添加到mixed6_s 之后,生成了9 ×9 ×128 的特征图。最后卷积核为1 ×1、步长为1、通道数为128 的卷积层被添加到mixed7_s 之后,其生成了9 ×9 ×128 的特征图,并将两个特征图进行合并。
在IFSSD 模型中,35 ×35 ×512、18 ×18 ×512和9 ×9 ×256 的连接层用于生成FPN。在9 ×9 ×256 的连接层之后添加一个卷积核为3 ×3、步长为2、通道数为256 的SAME 卷积层,生成特征图尺寸为5 像素×5 像素。其后,添加一个卷积核为3 ×3、步长为1 ×1、通道数为256 以及使用VALID 的卷积层,生成特征图尺寸为3 像素×3 像素。最后,在3 ×3 ×256 层之后,添加一个卷积核为3 ×3、步长为1、通道数为256 的VALID 卷积层,生成的特征图尺寸为1 像素×1 像素。图中绿色方框所示的6 层不同尺度的预测框用于获得柚子的位置和置信度。
可以看出,FSSD 模型使用双线性插值从VGG16 中3 个不同层获得相同的尺寸,并将它们融合在一起以获得输出层并生成FPN。IFSSD 模型使用1 × 1 卷积来修改InceptionV3 中的mixed4、mixed5、mixed6_s、mixed7_s 层的通道数和图像尺寸,并且成对地融合上述修改后的卷积层以获得3个不同层,然后基于这3 个层生成FPN。
(2)损失函数优化
一阶段算法(one-stage)和二阶段算法(twostage)的表现不同主要是由大量前景背景类别不平衡导致[27]。二阶段算法中,在候选框阶段,通过得分和非极大值抑制(Non-maximum suppression,NMS)筛选过滤掉了大量的负样本,然后在分类回归阶段又固定了正负样本比例,或者通过难例挖掘(OHEM)在线挖掘困难样本使得前景和背景相对平衡。而一阶段算法需要产生约100 kB 的候选位置。虽然有重复采样,但是训练仍然被大量负样本所主导。本文使用的IFSSD 模型属于one-stage 模型,使用Focal Loss 代替原有的损失函数。
Focal Loss 主要是为了解决one-stage 目标检测中正负样本比例严重失衡的问题[28]。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。Focal Loss 是在交叉熵损失函数基础上进行的修改。二分类交叉熵损失值计算式为
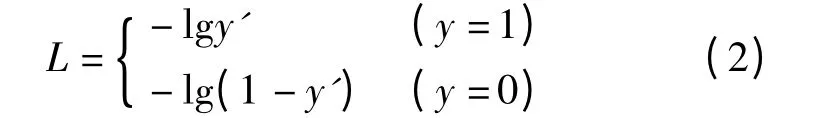
式中 L——二分类交叉熵的损失值
y——真实分类 y′——预测分类
y′是激活函数的输出,取值在0 ~1 之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小;对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。
Focal Loss 在原有基础上加了一个常数因子γ,以减少易分类样本的损失,从而更关注于困难的、错分的样本。此外,加入平衡因子at,用来平衡正负样本本身的比例不均,具体公式如下
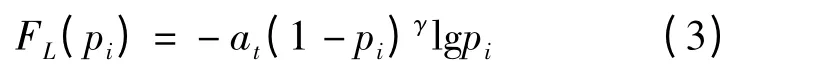
式中 pi——不同类别的概率
at——正样本和负样本的比例,前景类别使用at时,对应的背景类别使用1 -at
2 试验与结果分析
2.1 试验方法与参数设置
柚子数据集中包含一定量果实膨大期和成熟期的图像。训练集和验证集以4∶1的比例进行随机划分。其中训练集包含4 000 幅图像,使用Labelme 标注软件对每幅图像中成熟期和果实膨大期的柚子进行标注,最后按照PASCAL VOC 数据格式[29]构建训练集,另外1 000 幅未被标注图像作为测试集,用来评价模型在未知柚子图像数据集上的泛化性能。
为了评估IFSSD 模型对柚子的检测识别性能,首先通过预处理的4 000 幅RGB 图像创建IFSSD 模型。剩余的1 000 幅测试图像用于IFSSD 模型的测试。测试环境为IntelXeon E3-1245 v3 CPU、主频3.40 GHz、内存32 GB,GPU 为GeForce RTX 2060、操作系统为Ubuntu 16.04,Cuda 版本为9.0,Keras深度学习框架,OpenCV 4.0、Python3.7 编程语言。
IFSSD 模型使用自适应矩估计(Adaptive moment estimation)作为优化算法,同时以TensorFlow 作为张量操作库的Keras 深度学习框架在GeForce RTX2060 显卡上进行加速运算。
本文模型设置不同参数,通过交叉验证选取最优参数设置,初始学习率设置为0.001,经过多次迭代后微调为10-4,偏差1 设置为0.9,偏差2 设置为0.999,归一化的最小值边界设置为0.000 1,权重衰变为5 ×10-4,图像批量为16。
本文模型对300 像素×300 像素图像的检测速率为29 f/s,训练过程中损失值变化曲线如图7 所示,随着迭代次数增加,IFFSD 模型的损失值不断下降,经过100 次迭代后,下降趋势趋向于平缓,并在200 次迭代后趋于稳定。
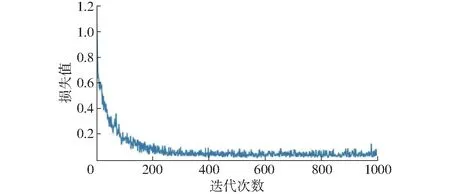
图7 IFSSD 模型训练过程中损失值的变化曲线Fig.7 Change of loss value during IFSSD training
2.2 检测结果分析
本文使用IFSSD、SSD、FSSD 模型分别对数据集进行检测。表1 为检测结果,其中检测出来的目标定为正样本,未检测出来的目标定为负样本。IoU阈值为0.5,试验结果有4 种,分别为IoU 值小于等于0.5(FP)、IoU 值大于0.5(TP)、未检测出真实目标FN、TN。本文不统计TN 类样本。准确率计算公式为

式中 TP——检测出的正样本数量
FP——检测出的负样本数量
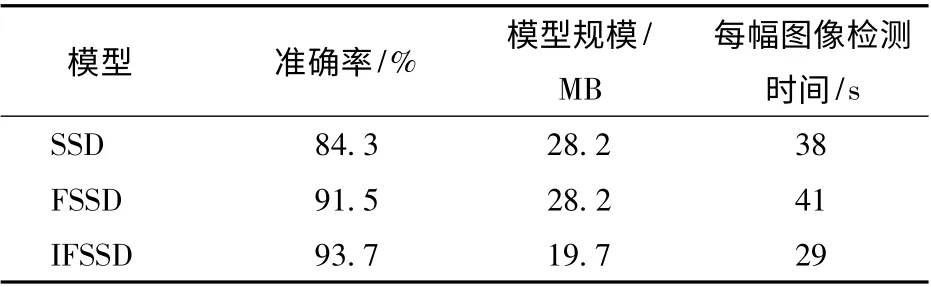
表1 不同检测模型的检测结果Tab.1 Detection results of different detection models
在检测精度方面,IFSSD 模型的准确率为93.7%,分别比SSD 模型和FSSD 模型提高了9.4个百分点和2.2 个百分点。在图像检测速率方面,IFSSD 模型每幅图像检测时间为29 s,低于SSD 模型的38 s 和FSSD 模型的41 s。
如表2 所示,IFSSD 模型的准确率比梯度直方图(Histogram of oriented gradient,HOG)+支持向量机(Support vector machine,SVM)和变形零件模型(Deformable parts model,DPM)+SVM 提高了14.1个百分点和16.4 个百分点,这是由于传统目标检测算法只适用于特征明显、背景简单的图像,而在实际应用中,背景复杂多变,且待检测的目标复杂多变,很难通过一般的抽象特征完成对目标的检测,而深度学习可以提取同一目标的丰富特征,完成目标的检测。然而在模型规模上IFSSD 模型要大于HOG+SVM 和DPM+SVM,这是由于IFSSD 模型的参数较多。从效率方面看,IFSSD 模型的效率与传统方法较接近。
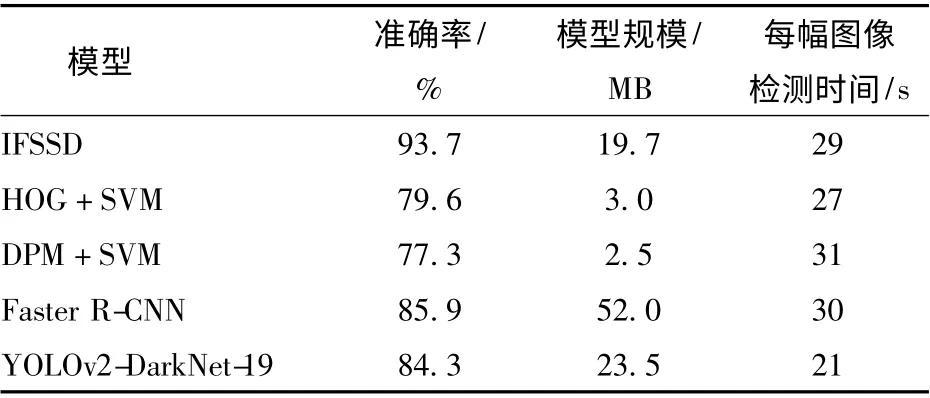
表2 IFSSD 与传统检测模型性能的比较Tab.2 Comparison of IFSSD and traditional grapefruit detection models
相对于Faster R-CNN 和YOLOv2-DarkNet-19,由于IFSSD 模型加入了FPN 结构和Inception 骨干网络,使得准确率分别提高了7.8 个百分点和9.4个百分点;从检测时间看,IFSSD 模型与Faster RCNN 模型较接近。
本文分别从目标大小、物候期、重叠情况、光照情况以及有无枝叶遮挡等方面分别对SSD、FSSD、IFSSD 模型进行比较。从表3 可以看出,IFSSD 模型的总体性能优于FSSD、SSD 模型。从目标大小方面看,加入了FPN 模块的FSSD、IFSSD 模型在小目标检测方面有了一定的提升,这是由于FPN 能够从更小的特征跨度进行特征融合,来进行多尺度预测。从不同物候期方面进行分析,IFSSD 模型对膨胀期的识别提升较为明显,相对于SSD、FSSD 模型分别提高了5.21 个百分点和4.51 个百分点,这是由于膨胀期的柚子颜色为绿色,容易因正负样本不平衡而导致错检和漏检,Focal Loss 的引入缓解了这个问题。但是在重叠、光照和有枝叶遮挡的情况下,IFSSD 模型检测效果没有明显的提高,仍然需要进一步优化。由于摄像机型号不同,不同的焦距和距离导致柚子图像的尺寸不同,本文采用将摄像头固定并通过调整焦距来获得小目标、中目标和大目标3 种类型的图像。图8 是使用以上3 种模型对部分图像处理的效果。从图中可以看出,对于中型和大型目标,3 种模型都能检测到大部分的目标。对于大型目标,3 种模型的准确率均达到92%以上。但是对于极小的目标,SSD 模型效果要比IFSSD 模型和FSSD 模型差,SSD 模型容易漏检大部分小目标柚子。这是由于SSD 模型虽然从不同层次的特征进行预测,ConvNets 提取的特征随着层次的增加语义越来越强,但是SSD 模型却把它们当成一样的层次去预测,不能充分地利用局部细节特征和全局语义特征。FSSD 模型采用FPN 方法把细节特征(定位)和全局语义(识别)结合起来,即把浅层的细节特征和高层的语义特征结合起来,因此IFSSD、FSSD模型在小目标检测方面得到了进一步的提升。
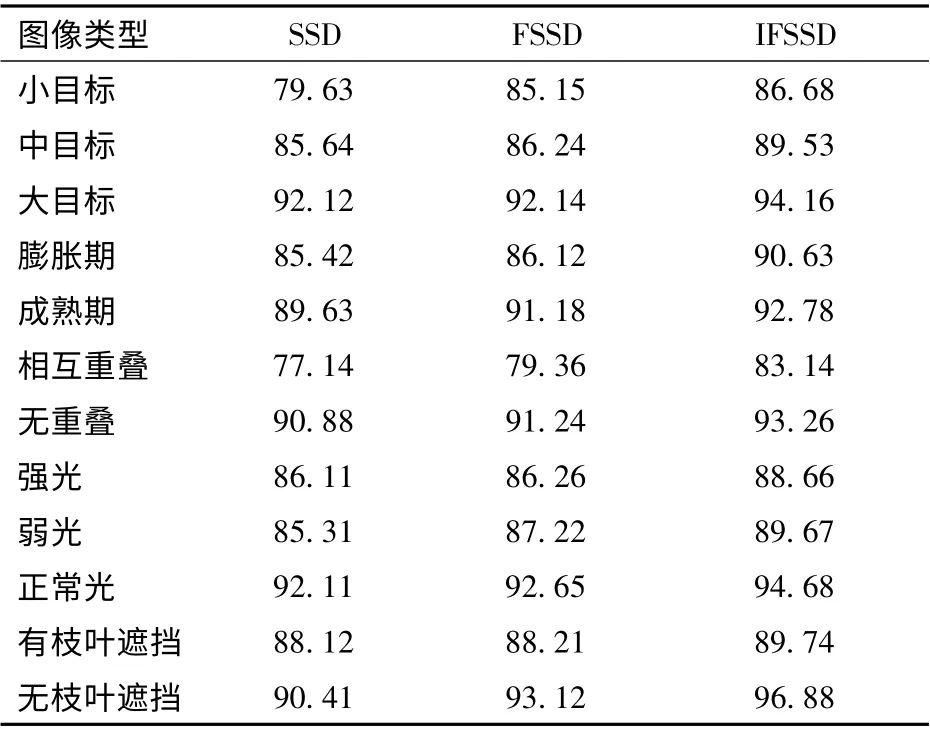
表3 不同图像类型下不同模型的检测准确率Tab.3 Detection accuvaey of different models under different image types %

图8 3 种模型对图像的处理效果Fig.8 Processing effect of three models on images
进一步通过试验来分析IFSSD 模型在数据不平衡下对柚子检测效果的改进。
如图9 所示,对于成熟期的柚子而言,IFSSD、FSSD、SSD 模型都具有较精确的检测效果。这是由于成熟期的柚子是黄色的,相对于背景和果实膨大期的柚子有着明显的颜色区别。但是SSD 模型和FSSD 模型会将某些叶片检测为果实膨大期的柚子,这是因为叶子与果实膨大期的柚子的颜色相似,同时在数据不平衡的情况下,以叶子为主的背景样本明显要多于果实膨大期的柚子样本,这会造成模型对于果实膨大期柚子的识别效果较差,同时在光线等自然条件的影响下,容易将成簇的叶子错认为是处于膨大期的果实。

图9 柚子识别检测结果示例Fig.9 Examples of grapefruit identification results
图10 为SSD、FSSD 模型将绿色叶子错误检测为膨大期柚子的情况,而IFSSD 模型能够极大地避免此类情况的发生,这表明Focal Loss 损失函数的引入能够改善数据不平衡带来的影响,从而提高柚子的检测精度。

图10 膨大期柚子漏检示例Fig.10 Examples of expanded leaves misidentified as grapefruit
3 结束语
本文设计了一种改进的特征融合单镜头检测器(IFSSD),提出了基于IFSSD 卷积神经网络的柚子检测模型,并对所提模型进行检测试验。结果表明,本文模型对柚子检测的准确率达到93.7%,每幅图像的检测时间为29 s。
