基于机器学习算法构建缺血性卒中3个月死亡预测模型研究
2020-07-07陈思玎刘欢黄馨莹李皓琳谷鸿秋姜勇
陈思玎,刘欢,黄馨莹,李皓琳,谷鸿秋,姜勇,2
卒中是全球第二大死因,在中国近年来已经成为人群死亡的首要原因,缺血性卒中占全部卒中的80%,具有高致残率、高致死率及高复发率等特点[1]。根据我国卒中流行病学调查研究推算,目前每年约有240万人新发卒中,每年110万人死于卒中,现存的卒中患者1100多万[2]。在国内,卒中单病种死因顺位排名自2010年上升到第一位后,仍未改变[3-5]。因此,探讨缺血性卒中死亡的预测具有重要意义。随着大数据时代的到来,在医疗领域中各种繁杂的医疗信息被整合为大数据,为将机器学习引入医疗领域创造了条件。本研究旨在比较机器学习模型和传统统计学模型对缺血性卒中患者发病3个月死亡预测效果,以期为后续建立更加完善的缺血性卒中死亡预测提供借鉴。
1 研究对象与方法
1.1 研究对象 CNSR为全国范围内前瞻性及观察性急性卒中登记研究,其数据库资料连续记录了2007年9月-2008年8月全国27个省和4个直辖市(包括香港)132家医院的急性卒中患者信息。本研究纳入CNSR数据库中基线和随访数据齐全且明确诊断为缺血性卒中的住院患者进行数据分析与研究。
1.2 结局与变量初步筛选 基于CNSR数据库资料,总变量有1219个,本研究结局变量是缺血性卒中患者发病3个月死亡。结合临床知识,将与死亡结局强相关的变量(如癌症是否转移)以及和卒中结局不相关的变量(如是否做2次MRI)进行人工筛选剔除。经过人工筛选后确定438个变量,包括人口学特征(性别、年龄等)、既往病史(高血压、糖尿病、血脂异常等)、用药史、首发症状(失语症、感觉障碍、吞咽困难等)、并发症(消化道出血、肺炎、泌尿道感染等)、实验室检测指标和评分指标等。
1.3 模型构建方法 将总数据集按7∶3随机分为训练集和测试集,训练集用于构建预测模型,测试集用于评价模型效果。1.3.1 XGBoost预测模型 XGBoost算法是集成学习boosting方法的一种,兼具线性规模求解器和树学习算法。XGBoost是对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项,整体求最优解,用于权衡目标函数的下降和模型的复杂程度,避免过拟合,提高模型的求解效率。SelectFromModel是一个通用转换器,如果相应的coef或feature_importances值低于提供的阈值参数,则认为这些特性不重要并将其删除。
XGBoost模型通过SelectFromModel对全部变量(438个)进行特征筛选,筛选时变量逐步增加,步长为1时,发现选取20个变量代价最低,故而筛选出相应预测变量。XGBoost对训练集采用5折交叉验证法,在训练集内进行5折交叉验证调参数,模型参数learning_rate为0.1,n_estimators为40,max_depth为3,min_child_weight为5,seed为0,subsample为0.6,colsample_bytree为0.6,gamma为0.1,reg_alpha为0.1,reg_lambda为0.05。
1.3.2 Logistic回归预测模型 Logistic回归模型适合于预测结局变量为二项分类的情况,Logistic模型是一种概率模型,该模型参数估计是采用经典算法——最大似然估计法。在训练集中,对全部变量采用非条件Logistic回归,建立预测模型,选择纳入模型的预测指标。首先采用单因素Logistic回归,以P<0.1为纳入多因素分析的标准;将单因素分析选择出的危险因素纳入多因素分析,采用逐步回归法,以P<0.05为最终纳入多因素模型的标准,建立缺血性卒中发病后3个月死亡预测模型。
1.3.3 缺失值处理 缺失值分三种类型处理:①跳转变量:如果一级变量选否,二级变量自动补0;②删掉缺失值超过30%的变量;③剩余缺失值,分类变量用99填充缺失值;连续变量用均值填补缺失值。
1.4 统计学方法 本研究应用SAS 9.4统计软件进行Logistic回归模型的建立,使用逐步回归法。应用Python3.6.8进行XGBoost机器学习模型建立,XGBoost调用xgboost API,采用scikit-learn中GridSearchCV函数做参数遍历选择,matplotlib API提供作图支持,绘制预测的ROC曲线。两种模型的预测性能采用ROC曲线下面积(area under the curve,AUC)表示,AUC越高表明模型预测性能越好。P<0.05为差异具有统计学意义。
2 结果
2.1 一般资料 CNSR数据库共22 216例急性卒中患者,排除1765例从其他非登记医院转入患者、314例基线信息不完整患者、120例最终诊断不明确患者、1437例未同意随访患者及6165例非缺血性卒中患者后,有缺血卒中患者12 415例。基于研究需要,保留其中收入院的病例11 327例,再去掉缺失结局观测和随访相关变量后,最终纳入10 645例缺血性卒中患者。患者平均年龄65.18±12.23岁,女性4045例(38.0%),入院NIHSS评分4(2~9)分,3个月死亡患者447例(4.48%)。其中训练集7451例,3个月死亡334例;测试集3194例,3个月死亡143例。
2.2 预测模型变量筛选结果 XGBoost模型最终筛选出20个变量纳入预测模型,Logistic回归预测模型最终纳入27个变量,两个模型预测因子大多数属于基线特征变量。两种模型筛选出的变量有3个相同,分别为入院NIHSS评分、健康教育和住院总天数。具体其他变量如表1所示。2.3 预测模型效果比较 训练集与测试集中,XGBoost与Logistic回归预测模型的AUC差异均无统计学意义(0.9001vs0.8933,P=0.3420;0.8539vs0.8278,P=0.0835),其余结果如表2所示,测试集ROC曲线如图1所示。
3 讨论
传统Logistic回归模型[6]作为一种有效的数据处理方法,广泛应用于医学、生物信息处理等领域。而XGBoost是美国华盛顿大学陈天奇[7]于2016年开发的Boosting库,其兼具线性规模求解器和树学习算法。XGBoost算法是集成学习boosting方法的一种,具有运行速度快、分类效果好、有效避免过拟合、支持自定义损失函数等优点,在机器学习领域受到追捧和青睐[8]。现如今越来越多的学者将机器学习模型预测结果作为一种临床辅助医师判断手段,为临床诊疗提供参考意见,以适应实际临床应用环境。现阶段,在临床诊疗方面已有一些尝试,如基于国际中心注册的急性心肌梗死预测研究[9]、癌症患者化疗后的死亡预测[10]及卒中后肺炎预测等[11]。
本研究基于CNSR项目的缺血性卒中病例,分别采用了传统的Logistic回归和机器学习XGBoost算法,来构建缺血性卒中3个月死亡结局预测模型。考虑到两种模型的底层结构不同,因而各自筛选变量以适应各自模型,采用分别进行变量筛选的方法来进行预测模型评价,也保证了对比的公平性,是本研究的优势,与既往研究不同[12]。
在本研究中,总数据集10 645例,3个月死亡477例。对于类似这种大样本、大批量数据而言,相比传统Logistic模型,机器学习模型XGBoost有众多优点:首先,支持并行计算,可调用计算机的所有内核同时运算,节省运算时间;同时采用L1+L2的正则化方法可防止因维度过高而带来的过拟合问题;自带交叉验证及缺失值处理机制;灵活支持个性化目标函数和评估指标。其次,Logistic回归分析假设中各特征之间是相互独立的,并且模型只有线性的分割面,而应用XGBoost算法构建预测模型时能够保留特征之间的相关性,使得预测效果更准确[13]。由于各研究中具体研究问题、研究设计及数据不同、XGBoost预测模型的表现也不尽相同,与传统Logistic回归预测模型相比,有些情形下两者相当,有些情形下XGBoost更优。在类似数据量大、预测变量多、关系复杂时,机器学习模型更能凸显其优势。
未来如果要进一步提高机器学习模型(算法)的准确性,可以尝试通过改变分类阈值提高灵敏度或阳性预测值,或结合更优的选择算法来提高精准预测的能力[14]。其次,在本研究中应用特征筛选,最大限度地从原始数据中提取特征以供模型使用。数据清理和特征筛选都是特征工程的一部分,特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样是确定的步骤,更多是临床和工程上的经验和权衡,因此没有统一的方法,但它是必须且特别重要的一项工作,本研究在特征工
程上还需进一步探索。
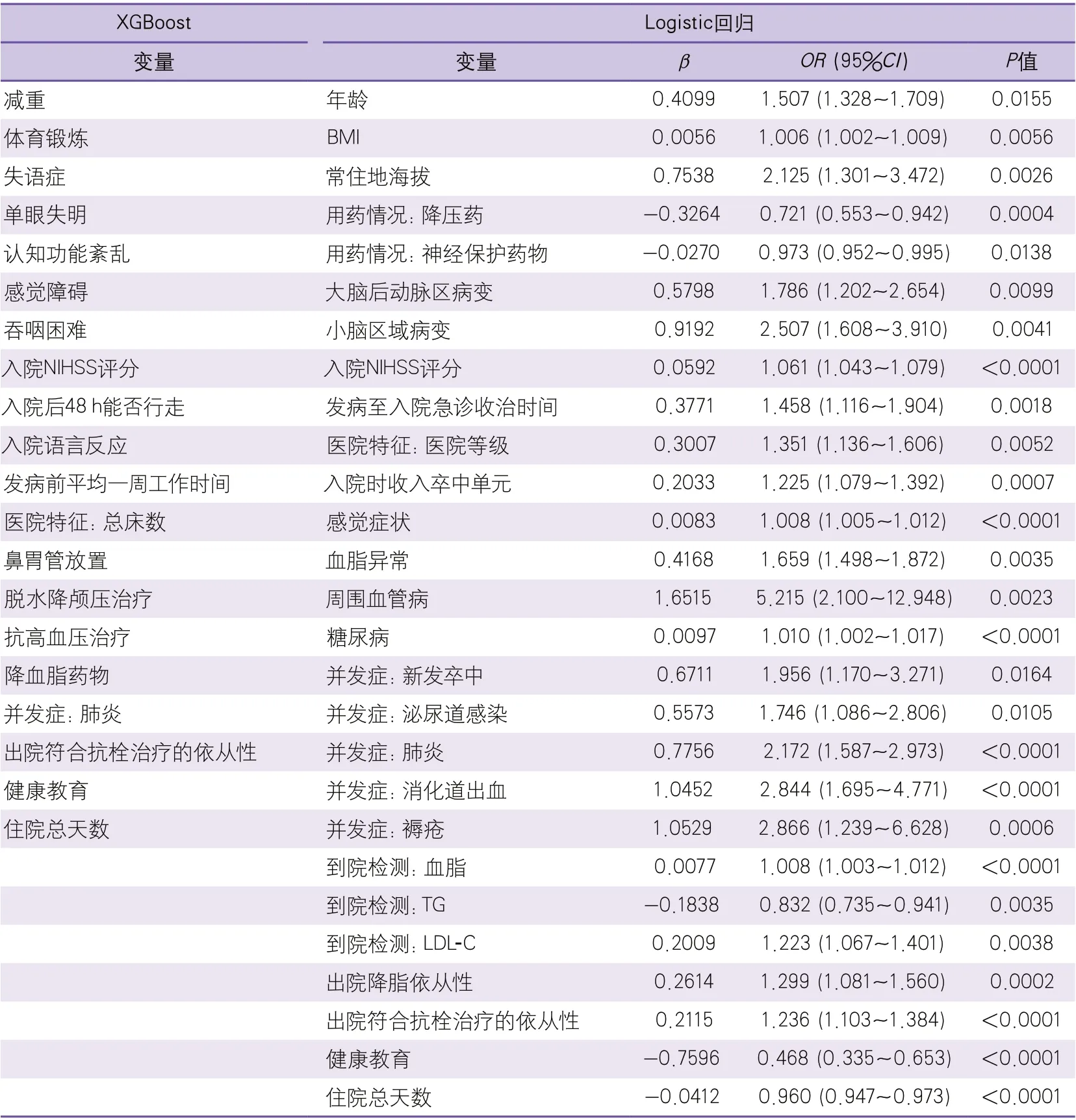
表1 两种预测模型变量筛选结果
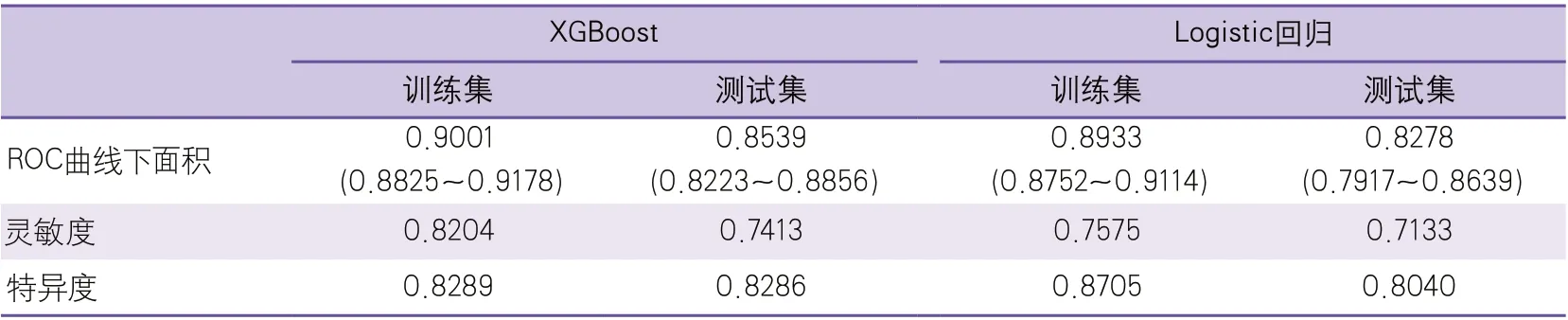
表2 两种预测模型效果比较
本研究的局限性在于进行预测模型评价时所用方法单一,主要考虑模型在AUC方面的表现。在评价预测模型时未来可以考虑综合多种指标,常用的如Brier分数、F1-score等指标[15]。未来将会进一步探究不同模型对于缺血性卒中的适应条件,在预测因子、模型开发以及预测性能方面进行全面研究,以期为后续建立更加完善的缺血性卒中死亡预测提供更全面的借鉴。
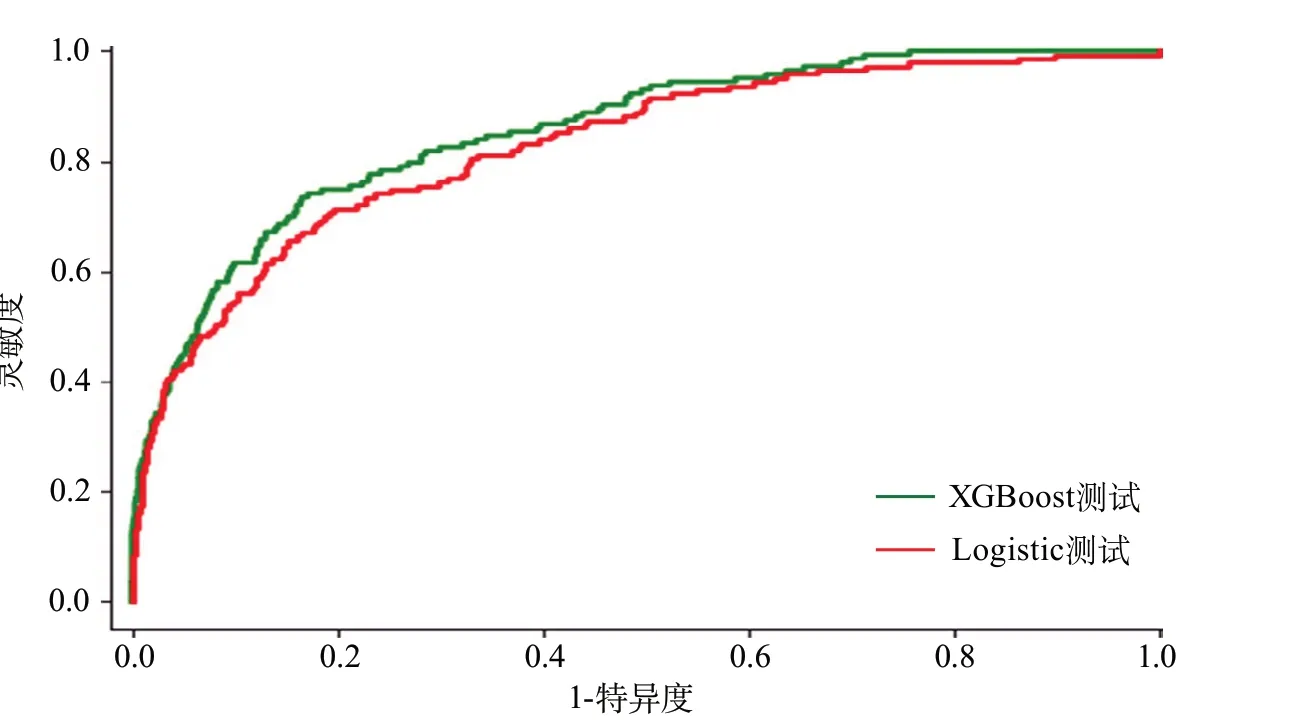
图1 两种预测模型的测试集ROC曲线
[9] AL'AREF S J,MALIAKAL G,SINGH G,et al. Machine learning of clinical variables and coronary artery calcium scoring for the prediction of obstructive coronary artery disease on coronary computed tomography angiography:analysis from the CONFIRM registry[J]. Eur Heart J,2020,41(3):359-367.
[10] ELFIKY A A,PANY M J,PARIKH R B,et al. Development and application of a machine learning approach to assess short-term mortality risk among patients with cancer starting chemotherapy[J/OL]. JAMA Netw Open,2018,1(3):e180926[2020-02-20]. https://doi.org/10.1001/jamanetworkopen.2018. 0926.
[11] GE Y Q,WANG Q H,WANG L,et al. Predicting post-stroke pneumonia using deep neural network approaches[J]. Int J Med Inform,2019,132:103986.
[12] 王孟,覃露,王春娟,等. 基于机器学习算法的脑出血相关肺炎预测模型研究[J]. 中国卒中杂志,2020,15(3):243-249.
[13] 许源,马健勇,葛艳秋,等. XGBoost模型对缺血性脑卒中出院后90 d内复发再入院风险的预测效果分析[J]. 中华神经医学杂志,2018,17(8):813-818.
[14] 刘泽文. 基于机器学习的脑卒中复发预测模型研究[D]. 长沙:湖南大学,2015.
[15] POWERS D M W. Evaluation:from precision,recall and F-measure to ROC,informedness,markedness and correlation[J]. J Mach Learn Tech,2011,2(1):37-63.
