贝叶斯网络查询语义扩展的专家发现方法
2020-07-06侯宏旭班志杰
郑 伟,侯宏旭 ,班志杰
1.内蒙古大学 计算机学院,呼和浩特 010021
2.河北北方学院 理学院,河北 张家口 075000
1 引言
近年来,随着互联网技术快速发展,人们信息需求更加多样化,信息检索的内涵更加丰富与多样化,检索技术在各个领域都有着独特的应用。实体检索(Entity Retrieval,ER)是信息检索技术中一个重要分支[1-3],专家发现也称专家检索,是ER的一个特例,主要研究如何根据给定的查询找到相关领域具有一定威望和专长的专家,并按照专业水平对相关人员进行排序[3-5]。专家发现在企业界和科技知识领域有着广泛应用,如何在海量科技文献信息中准确有效地发现某个领域的专家群体,近年来成为信息检索和知识发现领域的一个研究热点。
国际文本检索会议组织的企业专家检索任务推动了专家检索技术的发展[6-9],Fang等人[6]提出了一个通用概率模型框架,用候选人生成模型和主题生成模型实现检索,在TREC enterprise collections上的实验取得了较好效果。Cifariello 等人[10]提出一种基于实体链接的语义方法用于专家发现,使用语言模型与维基百科中通过实体链接形成的知识语义图进行专家检索。Sharad 等人[11]提出基于一种社会网络计算与本体学习相结合的专家发现算法,该算法通过获取专家profile,使用概念计算和社会网络分析进行专家的综合排序。Zhang 等人[12]利用文献中主题信息构建了局部的专家候选人网络,通过候选人间认可度进行相似关系传播,通过多轮迭代得到专家后选人的最终分数。郑义平等人[13]针对专家与文档的建模问题,提出使用逆向频率方法实现专家与文档的关联强度计算,通过学术合作关系构建专家关系图,经过专家间相似信息的多轮传播计算可得到最终得分。
上述研究中,专家检索性能的提升很大程度上依赖概念匹配和实体网络计算,通过计算概念间距离进行文本匹配,采用图模型分析进行证据的获取与传播。其中文献[12-13]中的相关性传播模型属于两阶段模型,在本文中记为Pa_Model,专家检索时取得了一定的效果,但其没有形成一个有机的整体推理框架,不确定分析存在一定难度,另外如数据规模较大时,计算时间复杂度较高。针对上述问题,本文将贝叶斯网络技术引入到专家发现任务中,提出一种具有查询语义扩展功能的专家发现模型。该模型使用贝叶斯网络对检索任务进行建模,模型具有四层网络结构,整体连接性好,可实现推理计算,借助Word2Vec 技术深入挖掘术语间的语义关系来实现查询语义扩展。
2 经典专家发现模型
在TREC2005中,研究人员介绍了两种用于专家检索任务的语言模型,即候选专家模型(Candidate Model)和文档模型(Document Model),它们是目前较常用的专家检索模型框架[6-7,14],许多扩展方法和新理论均基于该框架。候选专家模型和文档模型均假定候选专家与查询之间是相互独立的。相对于候选专家模型,文档模型的优点在于其保留了完整的查询和文档之间的查询接口,进而可以结合其他检索模型实现专家发现算法的改进,目前较为常用,一般情况下检索性能优于候选专家模型[7,14]。
Document Model基本思想是使用文档检索方法获得与查询相关的文档,然后按照候选专家与这些文档的相关程度对专家进行排序[15],具体算法如下。
给定查询query的条件下,候选专家ca出现的概率为P(ca|query),根据贝叶斯公式有:

Dca为与ca相关的文档集合,假定查询query中,各个词项是独立分布的,则:

根据文献[1,7],假设term与ca之间是条件独立的,θca是候选专家ca的模型,term是查询query中的一个词项,则:

对式(5)进行平滑处理得到:

综合上述各式可得:

其中,n(term,query)表示term在query中出现的次数,P(term|doc)是term在文档doc中出现的概率,P(term)是term在文档集中出现的概率。
3 Word2vec相关语言模型
Word2Vec[16]是google 提出的一个学习词向量的框架,可以把输入的每个长短不一的词转换为维度相同的向量,使得文字处理变得简单化,Word2vec 也叫Word embedding,Word2vec 的训练过程可以看作是通过神经网络机器学习算法来训练N-gram语言模型,并在训练过程中求出word 所对应的vector 的方法。根据语言模型的不同,又可分为“CBOW”和“Skip-gram”两种模型[16],具体实现原理如图1所示。
CBOW 模型利用上下文的若干词去预测当前词,Skip-gram 模型恰好相反,利用当前词预测上下文的若干词。Word2vec训练出的词向量蕴含了词与词之间的联系与相关信息,有助于对文本语义的理解与挖掘,Word2vec技术在自然语言处理领域应用具有较高应用价值。

图1 Word2vec原理模型
4 基于贝叶斯网络模型查询语义扩展的专家发现方法
贝叶斯网络是一种采用有向无环图,能够实现不确定性推理计算,应用领域较为广泛[17-19]。本文提出一种新的专家发现方法,基本思想是采用贝叶斯网络构建一个专家发现算法模型,该模型具有多层结构,能够实现专家发现任务的推理和查询术语的语义扩展。在术语层间采用Word2vec技术对术语进行向量语义相似度计算,找出语义相近的词进而实现查询术语语义挖掘与扩展。
4.1 专家发现算法模型
使用贝叶斯网络图模型的推理机制构建了一个具有查询语义扩展的专家发现模型,命名为NEF(New Expert Finding),模型如图2 所示,其具有四层结构,分别为双术语层T与T′、文档层D和专家层C,模型中的变量集合V可表示为V=T′∪T∪D∪C。
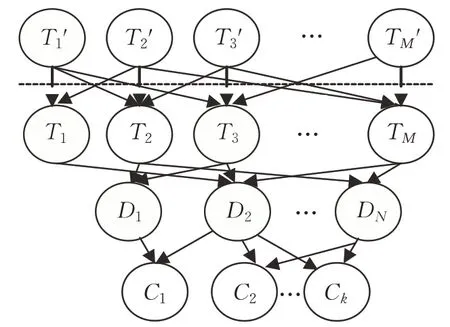
图2 NEF模型
对由于术语层T中的任意节点Ti,其父节点集合为Pa(Ti),若Tj'∈Q且Tj'和Ti存在满足一定条件的语义关系,则父节点集合由其本身Ti'和Tj'构成,存在由Ti'和Tj'节点指向Ti的虚线,术语层间节点的关联可以为查询提供证据支撑信息,能够起到有效扩展查询的功效。专家有与本身相关联的文档,故存在由集合D中节点指向集合C中节点的多条弧。据拓扑结构中弧的指向,可知术语相互边缘独立,文档在给定其包含术语的情况下相互条件独立,专家分布独立,由此可以估计节点的概率分布。给定一个用户查询时,NEF模型将其作为一个证据引入系统中,考虑到网络中存在大量的节点,使用一个与概率传播算法效果等价的简单推理算法来计算每个候选专家C与查询Q的相关概率。
4.2 模型推理
模型对应的检索推理过程如下:
(1)术语节点ti与查询Q的关系可通过术语子网来计算P(ti|Q),uij为术语Ti与Tj'之间的语义关联强度,术语Ti父节点的集合用Pa(Ti)表示。

由于术语节点是边缘独立的,如果Tj'∈Q,则P(tj'|Q)=1,如果Tj'∉Q,则P(tj'|Q)=1/M。
(2)为了区分Ti父节点集合中原节点Ti'与有语义关系的扩展各节点在检索中的作用,采用sim函数来衡量两个不同术语间的语义相关度,β是平滑参数,uij用sim函数展开后公式(7)可变为公式(8)。

(3)根据上述步骤,基于查询Q的文档dj后验概率为:

公式中,wij为术语Ti在文档Dj的权重值,η是一归化常量保证P(dj|Q)值小于等于1。权重wij有多种定义方法,本文中使用的是TFIDF方法。
(4)根据上述步骤,基于查询Q的候选专家Cj后验概率为:

其中,P(Ci|Q)表示候选专家Ci在查询Q条件下的相关概率,是检索结果排序的依据,hij是候选专家Ci与其所属文档dj的相关强度,文章设定hij值为1。
5 实验
本文实验的目是构建贝叶斯网络专家发现算法模型并实现查询语义扩展,通过实验将文献[7,14]中的Document Model、文献[12-13]提出的传播 Pa_Model 与本文提出的NEF 模型进行检索性能比对,验证NEF 模型检索性能的有效性。本文中Pa_Model 的实现是在Document Model基础上构建的两阶段传播模型。
5.1 实验数据
实验数据来自Aminer[20]学术文献数字数据平台中的学术数据集,AMiner平台是计算机科学领域的科研数据平台,其学术资源社会网络数据集是由2 092 356篇文章、1 712 433 个作者、8 024 869 条引用、4 248 615 条协作关系组成的。实验前对该数据集进行清洗,去除具有不完整信息的论文及作者,剔除hi因子较低的作者及对应论文,最终保留文献数量为129 617篇、作者数目33 828名。专家数据来源于AMiner平台专家数据库[21],表1展示了实验中采用的查询主题及对应的专家数目。

表1 计算机科学领域专家一览表
5.2 实验结果及分析
实验分为四个部分:(1)Document Model 上进行专家检索任务实验,找到其最佳的平滑参数设置;(2)word2vec 参数选择,验证查询扩展性能。(3)通过调节NEF 模型的平滑参数β,对其检索性能进行比较分析。(4)将最优参数下的 Document Model 与 Pa_Model作为基线系统,检验NEF模型对检索性能的有效性。实验采用准确率和召回率,P@5,P@10,P@20,P@30 和MAP指标进行评价[22],输出截断值设为100。
在经典专家发现模型实验中,表2数据对应平滑参数α取6个不同值时的检索结果,其中α分别于0.5、0.9与1.0时其P@30值最佳,在0.5、0.9与1.0这3个值中,α等于0.5 时具有最佳MAP 值,故将α=0.5 作为经典模型的平滑参数。

表2 文档模型检索性能比较
NEF模型中查询术语语义扩展采用了Word2vec技术,在Windows 平台下开展训练,词向量上下文窗口设置为5,维度设置为1 000,其他参数按照经验值来设置,选择Skip-gram模型来训练。表3 为NEF 模型在参数β和查询术语扩展数目N取不同值时对应的P@10 和MAP值。

表3 查询术语扩展实验MAP值比较
从表3 中的数据发现,当平滑参数β值等于1 时对应的是贝叶斯网络专家检索模型无查询术语扩展的情况,随着查询术语扩展数目的增加,其检索P@10 和MAP 值保持恒定;当β在[0.7,0.9]区间段取值时,发现随着查询术语扩展数目N值的增加,其P@10 和MAP值也在递增,并在N等于30时P@10达到最大值0.225,MAP 值达到最大值0.218,当β从[0.5,0.6]区间段取值时发现,N值增加时其MAP值呈现下降趋势,其P@10值也较低。综合表3中的P@10和MAP值分析可知,查询术语扩展数目选取30时检索系统能够很好地起到查询术语扩展的功效。
图3 为NEF 模型查询术语扩展数目为30 时的实验结果,图中显示在平滑参数β等于0.8时,专家检索模型NEF 具有较高的 P@5、P@10 和 MAP 值,因此该点具有较高的参考价值,参数β取值1时,对应的是无查询扩展的实验结果,其各项评估指标均低于有扩展的查询实验。

图3 NEF专家发现模型性能分析
将NEF 模型与基线系统进行的专家检索实验评价指标值进行对比,其中Document Model和Pa_Model选用最优参数下的评价指标值,NEF 模型选用β=0.8 时对应的评价指标值,对比结果如表4 所示,表中结果显示 Pa_Model 与 Document Model 具有相同的 P@5 和P@10 值,但在 P@20、P@30、MAP 值上 Pa_Model 要优于Document Model,这是由于Pa_Model 在传播阶段能够有效实现了专家间的信息传递,进一步提升了部分专家的权威度。总体上看NEF模型检索性能良好,相对比Baseline 系统的两个模型,其P@5、P@10 值增幅较大,P@5 增长了10%,P@10 增长了 12.5%,P@20、P@30 和MAP值略有下降。

表4 模型评估分数比较
NEF 模型在P@5、P@10 两项指标上取得了较好评估值,对比基线系统 P@20、P@30 指标,NEF 模型指标值下降的原因在于查询语义扩展的同时会带来查询主题的漂移,导致了部分查询语句对应的结果很不理想,导致平均分下降。在排序前100名作者的条件下,一部分作者排名较靠后,故MAP 值会降低。总体上看实验结果显示出了NEF模型良好的检索效果,P@5和P@10值经过查询扩展后得到了较大提升,有效实现了查询术语的语义扩展。
6 结束语
在分析贝叶斯网络检索和词向量技术的基础上,提出了一种可扩展查询术语语义的专家发现方法。该方法可控制术语语义的扩展程度,更准确地解决了术语间语义概念的匹配问题,比单一使用术语查询取得了更好的检索效果。由于当前语料规模限制及模型参数选择等因素的影响,实验结果还不够理想,后续研究工作将聚焦于主题提炼及进一步寻求优化参数,逐步改善模型的检索性能。
