面向漏洞类型的Crash分类研究
2020-07-06代培武潘祖烈
代培武,潘祖烈,施 凡
国防科技大学 电子对抗学院,合肥 230000
1 引言
互联网的普及给人们带来便利,惠及人们生活的各行各业,但近些年发生的震网病毒、勒索病毒、棱镜门事件等使人们意识到互联网安全的重要性,软件漏洞分析研究是计算机领域的热点难点问题[1]。Fuzzing 技术通过自动或半自动的方法反复驱动目标软件运行并为其提供构造的输入数据,同时监控软件运行的异常结果,能高效地产生Crash(程序异常或崩溃)[2],但该方法存在盲目性,产生的Crash数量巨大,只有极少数与漏洞成因有关,逐个分析会耗费研究人员大量时间,效率低下却错误率较高。因此如何自动化地对Crash进行分类和精简是漏洞研究人员急需攻克的难题。
在早期的软件安全研究过程中,研究人员借助OllyDbg和C32Asm等调试器对二进制代码的整体结构和模块进行手工分析,并在可知的执行路径上进行相应的实际跟踪,这严重依赖分析人员的技术水平和经验能力,误判率较高。后来开发的Valgrind[3]、AddressSanitizer[4]等一些低级的内存检测工具通过错误路径修改、增量分析、SAT 分析来发现导致系统崩溃的内存错误、逻辑错误、指针错误等,但同样存在效率和准确率的问题。动态污点分析(Dynamic Taint Analysis)[5]通过标记非信任数据来源,追踪并记录程序执行过程中污点信息,检测污点数据的非法使用,以达到获取关键位置与输入数据关联信息的分析方法。2014年IEEE会议上,Zhang等人提出新型的二进制可执行程序崩溃分析框架ExpTracer[6]。该框架在二进制插桩平台Pin 上进行开发,使用基于污点分析的数据流引导分析技术直接对二进制可执行程序进行分析,能够识别二进制可执行程序潜在的漏洞并对Crash 进行分类和可利用性判定,但效率低下。UC Berkely大学开发的BitBlaze[7]能通过二进制可执行程序污点分析来确定程序崩溃时哪些寄存器和内存地址来自攻击者控制的输入文件,对NULL指针切片的同时查看指针起始位置来快速判定二进制可执行程序存在的漏洞类型和该Crash 是由何种类型漏洞引起的,但分析对象单一,只能对栈溢出进行分析。李根等人研发的Hunter[8]和Wang 等人开发的TaintScope[9]利用污点类型和污点虚拟化技术对二进制可执行程序进行漏洞检测,但无法分析Crash。
本文主要研究如何利用污点分析技术,判定二进制可执行程序Crash 所属漏洞类型的问题,通过结合动态污点分析方法,修改污点传播规则,添加多种指令类型、寄存器和关键函数传播约束和检测方法,通过对常见缓冲区溢出漏洞崩溃触发特征编写触发规则,在污点检测阶段提出面向漏洞类型的污点检查点设置技术,旨在解决自动化判定Crash的所属漏洞类型的问题。
2 关键技术
2.1 二进制代码翻译
二进制代码翻译(Binary Translation)[10]是将二进制可执行程序翻译成另外一种指令集形式,二进制代码翻译是安全领域研究的热点问题,广泛应用于代码移植、代码优化、模拟器、虚拟化等方面。二进制代码翻译有两种方法,分别是基于直接指令和基于中间语言,直接指令翻译如图1 所示:Source instruction 表示源ISA,它被二进制翻译器翻译为目标Target instruction。翻译过程中可以进行各种处理,如代码优化和profiling等。基于直接指令的二进制代码翻译能够有效处理给定的源和目标指令,适合小型的二进制可执行程序,当程序较大或需要一致性较高的翻译器时,该方法会显得极其复杂。
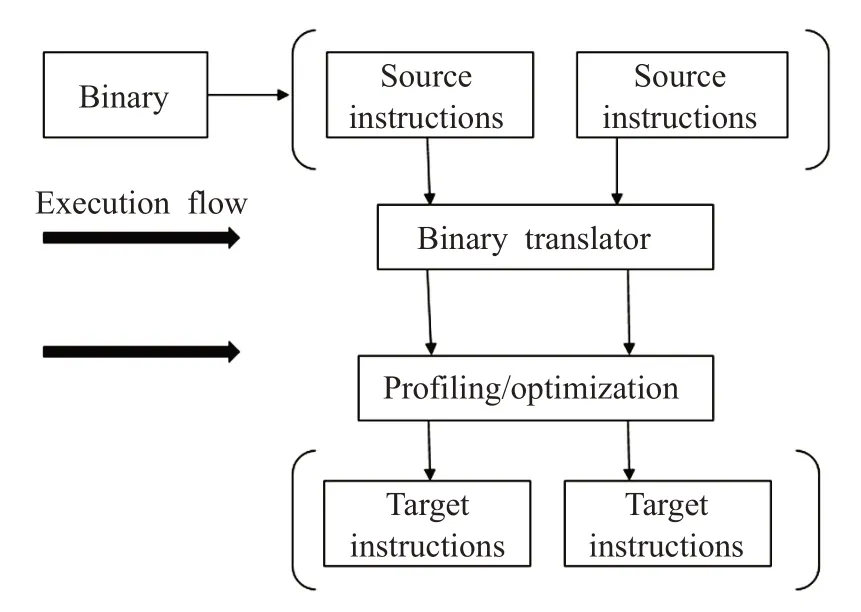
图1 直接指令翻译流程
基于中间语言的方法将二进制可执行程序翻译成中间语言[11](Intermediate Representation,IR),IR是一种通用的表示形式,和平台无关。图2是采用中间语言的二进制程序翻译流程,只需要将二进制可执行程序翻译成对应的IR,而后通过不同架构转换规则进行解读和匹配,IR适用于大型程序的分析和指令转换,对一些规模较小的二进制程序则显得效率低下[12]。例如,以下代码是add eax,ebx指令的Vex表示:
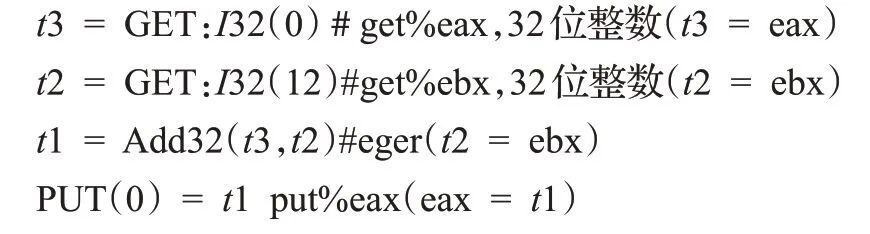
图2 中间语言二进制代码翻译流程
2.2 动态污点分析和动态二进制插桩
动态污点分析将非信任来源数据标记为污点,通过污点标记、污点传播、检测及策略匹配等阶段来准确获取程序的执行过程[13]。动态污点传播一般采用虚拟执行或动态二进制插桩方式对污点数据进行记录和跟踪。动态二进制插桩指的是在程序运行的过程中插入自定义代码,监控程序运行状态,获取程序运行时状态信息,从而对程序进行分析的过程。Intel 公司开发的Pin插桩工具是最近几年比较流行的插桩框架,Pin的基本思路是JIT 编译并插入插桩代码,同时进行优化处理以取得较高效率[14]。Pin 由几部分组成:虚拟机VM、Code Cache(指令缓存)、插桩API,内部架构如图3所示。
VM包括JIT编译器、Emulator和Dispatcher。JIT编译插桩目标程序代码,由Dispatcher执行。被编译/插桩的机器指令放入指令缓存,以便后来执行的代码无需编译就可直接执行。Emulator模拟无法由JIT编译的机器代码,通常用于处理系统调用。选择Pin 作为插桩开发框架主要有以下优势[15]。
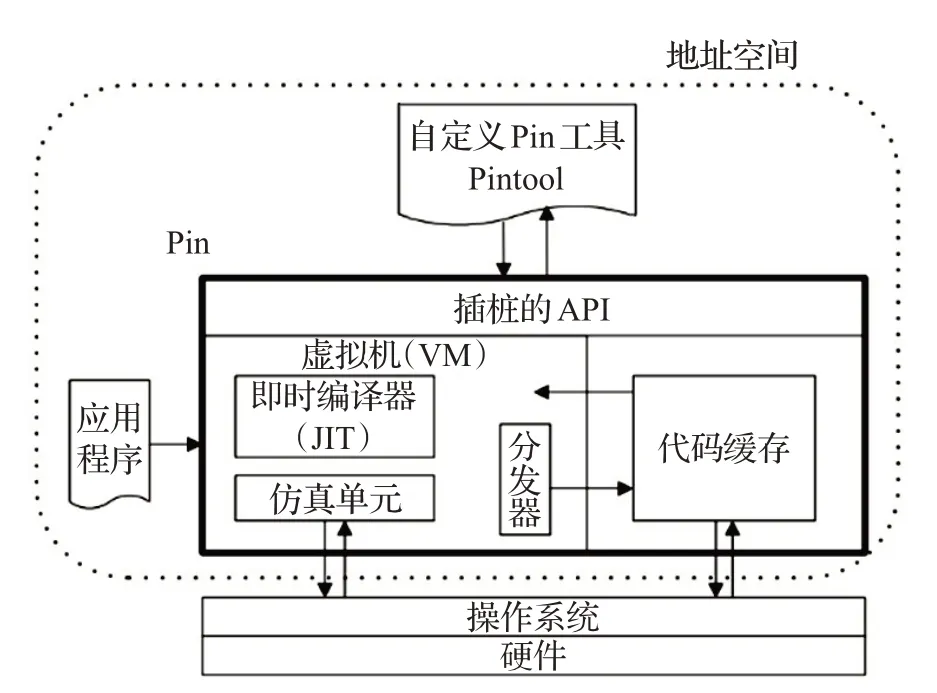
图3 Pin插桩平台系统架构
(1)普适性的插桩机制:使用动态二进制插桩,不需要源代码和重编译。而论文所针对的目标程序正好是没有开放源代码的二进制可执行程序/软件,采用Pin是非常有效。
(2)简单容易的自定制,其自身包含了一套丰富的API编程接口,使得开发人员可以在现有Pintool的基础上进行改进或者创建新的具有特定功能的Pintool。
(3)多平台的支持:支持x86、x86-64、Itanium、Xscale的体系架构以及支持Linux、Windows、MacOS操作系统。
(4)健壮性和稳定性,能够对多种商业级的软件进行插桩,包括数据库、浏览器等;能够对多线程程序进行插桩。
(5)高效性:提供对插桩代码的编译优化。
Pin提供判断操作数类型的API为:
INS_OperandIsMemory(ins,1) // ins是指令,
INS_OperandIsReg(ins,1)// 1 表示源操作数,0 表示目的操作数
插桩指令的核心函数原型如下:
INS_InsertCall(ins,
IPOINT_BEFORE,
analysis_function,
… //多个参数
IARG_INT
第一个参数是指令,第二个参数是插桩时刻,IPOINT_BEFORE是指令执行前插桩,IPOINT_AFTER是指令执行后插桩,第三个参数是用户插桩分析例程,省略号表示多个参数(直到IARG_END 结束),这些参数都是分析例程的实参。
3 系统设计实现
3.1 标记污点源
污点分析的首要任务是识别污点源,将不可信输入标记为污点。二进制可执行程序Fuzz 出的Crash 本身就是一种二进制形式的输入文件,这里认为Crash 就是污点源。为标注污点源需截获相关函数,它有若干种方法实现:(1)驱动程序,这种方法最彻底但编写难度较大且不稳定;(2)通过API截获工具如Detours实现。这两种方法的共同缺点在于需要与动态插桩工具交互,而Pin目前不支持与外部程序的IPC。动态插桩工具Pin提供了系统调用插桩,通过Pin 提供的API 可以方便获取参数和返回值等信息,这里采用MANGO[16]插桩socket、recv、open、read 等系统调用标记污点属性,然后在执行类似GET/PUT或LOAD/STORE之类的指令时对污点的传播和删除情况进行污点标记。污点标记的过程如下。
第一步:平台捕获sys_read 系统调用。通过Pin 可以初始化回调函数在系统调用出现前后添加自定义代码进行动态插桩获取运行时信息,采用的污点跟踪技术粒度为字节,接受外部输入数据首先到达缓冲区,对长度为buffLen 的读入数据进行污点标注,污点表初始化伪代码如下所示:
TaintNOdeTable(buffer,buffLen)
fori← 0 to buffLen−1 do
//将地址 buffer+i插入到 taint_table 表中,taint_table为Hash表
call taint_table_mem_insert(taint_table,buffer+i)
//地址buffer+i的污点标签为
taint_table_mem_add_tag(taint_table,buffer+i,taint_count,i+1)
taint_count←taint_count+1
第二步:获取这部分内存区域的相邻后续参数。当出现系统调用时,通过调用LEVEL_PINCLIENT::PIN_AddSyscallEntryFunction函数来检查该块内存区域是否可读,如果可读则将后续参数保存,将该内存区域添加到定义好的污染字节列表中,输出相关执行结果。
第三步:当出现类似LOAD 和STORE 指令时调用处理程序。为了在受污染的内存区域中获取LOAD/STORE所有指令,为每条指令添加一个主处理程序:
typedef VOID(*LEVEL_PINCLIENT::
INS_INSTRUMENT_CALLBACK)(INS ins,VOID *v);VOID LEVEL_PINCLIENT::
INS_AddInstrumentFunction
(INS_INSTRUMENT_CALLBACK fun,VOID * val);
污点引入通过监控 ReadFile()、RecvFrom()、Getchar()等污点输入函数实现,然后在调用函数时传递指令地址、反汇编代码、内存可读区域的地址等信息[17],对STORE 类型的指令操作类似。内存地址污点污点链表标记如图4所示。
Taint_tag即为污点。比如标记第一个缓冲区的第三个字节,生成一个污点对象,对应的count 为1,taint_tag为3,该字节所在的内存地址经运过算对应Memory_address_0的第二个偏移字节,就将生成的污点对象插入Memory_address_0对应Taint_1链表中。对接受到缓冲区的每个字节进行标记,以上就是污点标记初始化的过程。
3.2 动态污点跟踪
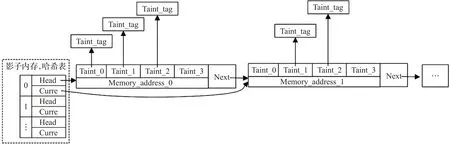
图4 污点链表结构
污点跟踪本质上是对信息流的追踪,动态污点跟踪阶段主要考虑污点的添加和删除,调整污点传播策略以避免出现污染过度和污染缺失现象[18]。例如,当LOAD和STORE的对象是污点数据时,进行污点标记,当STORE的目标是常量时,由于无法控制,需要进行污点清除。这里将对特定地址进行标记而不是将某一整块内存标记为污点属性[19],使用std::list
设计污点传播算法伪代码如下所示:
procedure TaintNodeinit(INS ins,void*t)
switch typeof(ins)//指令传播
case:MOV|CMOVcc|R*L|R*R|XCHG|STOS|LEA//数据移动类指令
e1=getSrcOperand(ins);e2=getDstOperand(ins);Taint(e1->e2)
case:ADD*,MUL*,SUB*,AND*XOR//运算类指令
e1=getSrcOperand(ins);e2=getDstOperand(ins);bitset*s=Union(e1,e2);
case:CMP|CMPS*//比较类指令
e1=LeftOperand(ci);e2=RightOperand(ci);bitset*s=Union(e1,e2);……
end procedure
procedure Taintpropagation(INS ins,void*t)
if(typeof(e1)==MEM(Reg)&&Mem(Reg)TaintMap[e1]!=Mem(Reg)TaintMap.end())
//根据指令语义和关键函数的规则进行污点传播
TaintNode *insertnode(ins_taint,reg_taint)
end if
else if(typeof(e1)==bitset)Mem(Reg)TaintMap[e2]=bitset_copy(e1)
end else if
elseif(Mem(Reg)TaintMap[e1]!=Mem(Reg)TaintMap.end())bitset_free(Mem(Reg)TaintMap[e1])
//对如XOR等指令及一些函数进行污点清除
TaintNode *deletenode(ins_taint,reg_taint)
end if
end procedure
TaintNodeUpdate(INS ins,void*t)
//更新污点表(影子内存与寄存器的污点状态)
…
污点传播需要建立污点源到污点操作数之间的传播规则,具体如表1 所示,这里对x86_64 架构下污点相关指令和函数进行总结归类[20],指令级污点传播主要有以下几种方式:
(1)数据移动类指令,例如mov、movb、movsz、movxz等,污点传播规则时间将源操作数的污点标记赋给目的操作数。
(2)运算类指令,典型指令有add、sub、and、xor、shr、lhr 等,传播规则是将源和目的操作数的污点标记赋给目的操作数。
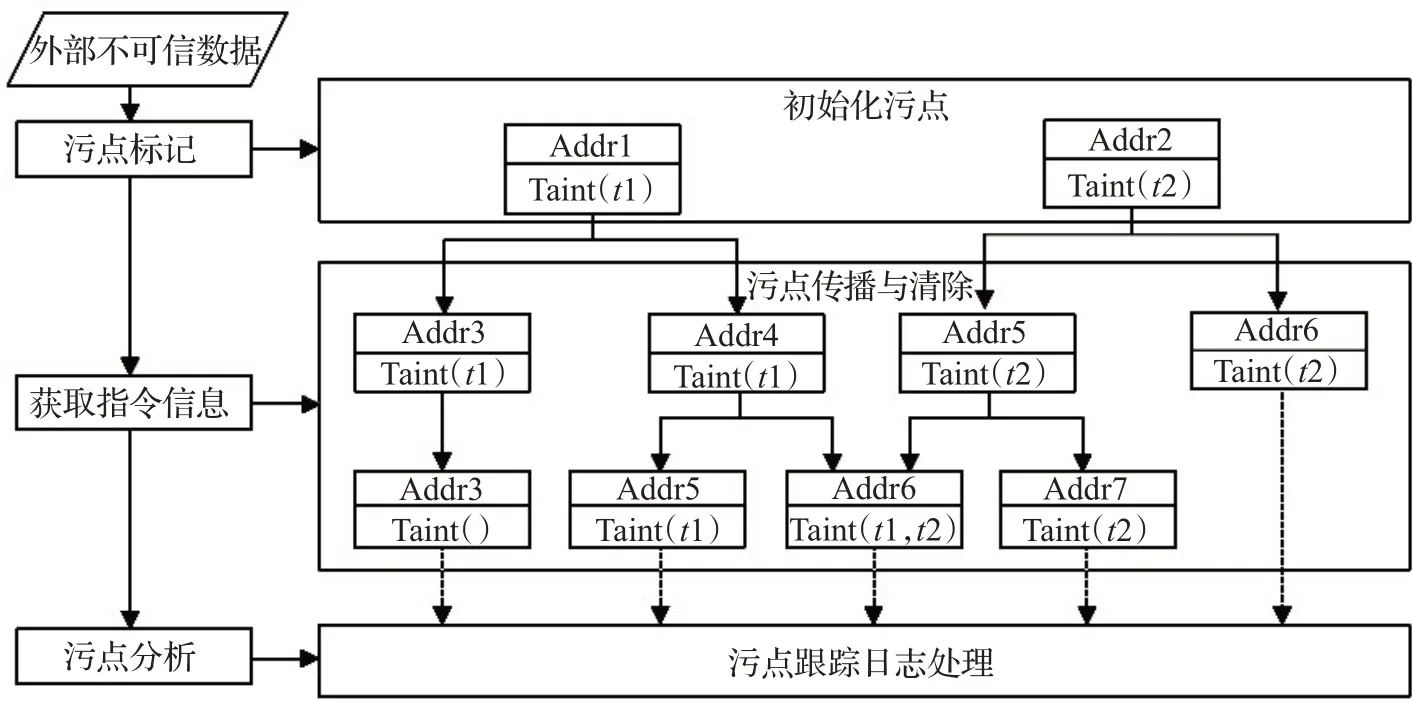
图5 动态污点传播过程
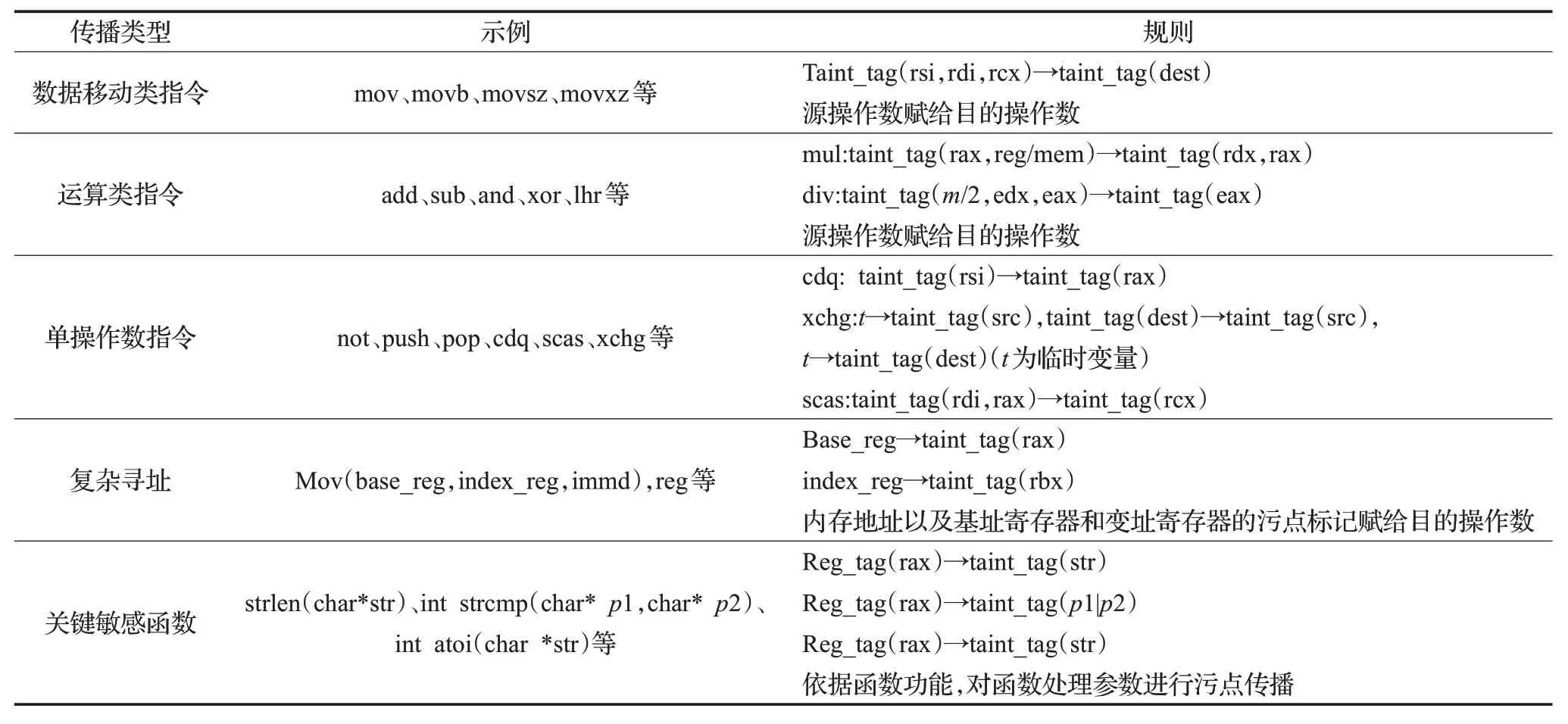
表1 污点传播指令及关键函数的规则说明
(3)单操作数指令,典型指令有not、push、pop 等,not传播规则是清除操作数污点标记,pop传播规则是将rsp内存污点信息赋给操作数。
(4)复杂寻址,典型指令如mov(base_reg,index_reg,immd),reg,传播规则是在内存访问时将内存地址以及基址寄存器和变址寄存器的污点标记赋给目的操作数。
对于敏感关键函数,主要考虑strlen(char* str)、int strcmp(char*p1,char*p2)、strcat(char *p1,char*p2)、int atoi(char *str)、memset(void *m,charc,int len)、void* malloc(int len)、free(p)等函数的传播策略。
污点表更新模块主要是污点链表中污点的添加和删除操作,通过对程序进行指令级插桩,分析指令执行过程的污点传播情况,需要对每条指令做出如下判断:该指令是否是内存/寄存器操作指令?该指令是否引起污点传播?污染表数据结构包含IN 和OUT 两个污染表,分别为同一个block的前后污染信息集合,根据设定的传播策略对满足条件的指令进行taint_tag 添加和删除,最后完成对污点表的合并更新。
3.3 检查点(SINK点)设置
污点检查点是进行漏洞检测和Crash类型识别的关键环节,污点检测主要针对已经被标记为污染源的数据进行检测,记录在程序中的使用情况并通过监控污点数据传播信息来实现漏洞类型判断等操作[21]。为完成以上目标,需要获取二进制可执行程序中的单个模块中的所有关键函数和对应的关键字节,为此设计三个识别模块:关键函数识别模块、函数调用跟踪模块、关键字节识别模块。关键函数识别模块需要找到插桩程序中哪些函数使用了污点数据,哪些关键函数是漏洞触发的高危函数,例如printf函数族、atoi函数等;函数调用跟踪模块分析插桩程序内部的函数调用关系,明确正在执行的指令属于该模块内的哪个函数;关键字节识别模块分析插桩程序指令所使用的关键字节。当某条指令使用了污染数据,通过关键字节识别模块可获得相关的关键字节,通过函数调用跟踪模块可获得该指令属于哪个关键函数,将上面的关键字节归类为关键函数。这样随着程序的运行,即可收集到每个关键函数的关键字节。本文主要对栈溢出、堆溢出、格式化字符串进行漏洞检测,具体检查点设置方法如下:
对二进制可执行程序进行插桩,读入Crash 后运行至程序崩溃,收集崩溃点上下文信息。对栈溢出类型的漏洞进行检查点设置通过检测在LOAD/STORE指令中对原先栈帧的访问过程,和当前栈帧进行对比,如果当前栈帧指针高于原栈帧位置,则EIP 可以由用户控制,该Crash是栈溢出类型的。堆溢出漏洞成因是一块堆内存被释放了之后又被使用,又被使用指的是:指针存在(悬垂指针被引用),这个引用的结果是不可预测的,因为不知道会发生什么。对于该种类型漏洞在污点检查点选择捕获malloc和free函数的所有调用,当malloc发生时在列表中保存这些信息,比如基地址、内存大小和分配状态(是占用还是空闲),当执行LOAD或STORE指令时,检查该地址是否在列表中,而后检查其标志,如果该标志是free且在LOAD或STORE中有权限访问,那就认为是堆溢出漏洞。格式化字符串漏洞两大危害是内存泄漏和内存写数据,主要借助于%s、%c、%d、%p、%x、%n等格式符,格式化字符串的检查点比较简单,主要是针对printf函数族进行污点检查,验证是否符合函数规范,且现在的编译器都增加了对格式化符检测机制,因此该漏洞的实验验证阶段主要通过CTF 试题和收集的一些存在格式化字符串漏洞的小程序对原型系统进行测试。
4 实验分析
本文主要基于Pin插桩平台开发出对二进制可执行程序进行漏洞检测,并对二进制可执行程序Fuzz 出的Crash 进行分类的工具。实验对象是存在栈溢出、格式化字符串、堆溢出等缓冲区溢出漏洞的二进制可执行程序,Crash 是由对应的二进制可执行程序进行模糊测试得到或从一些测试集中获取,实验环境如表2所示。
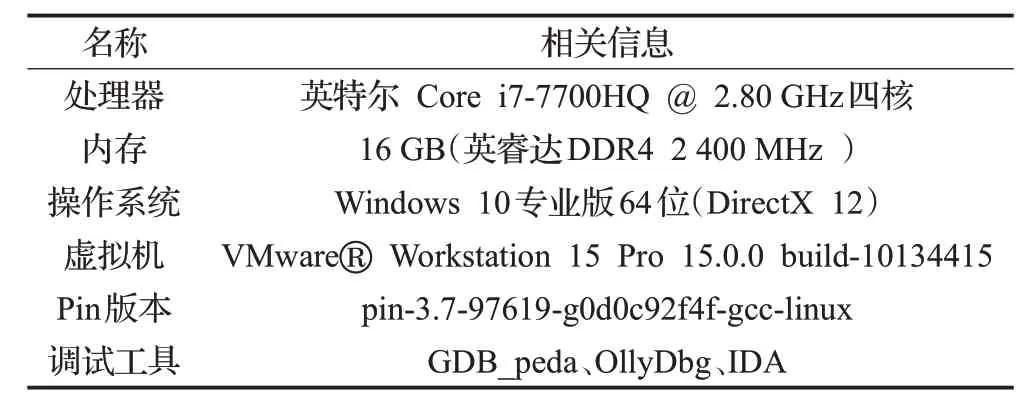
表2 实验环境
综合以上几节,提出Crash 分类框架如图6 所示。二进制可执行程序通过Pin进行插桩,读入Crash文件,在污点标记阶段对Crash 进行污点标注,污点信息分别标注于内存区域、寄存器指令、关键函数等,在污点传播阶段进行依据设定策略进行污点跟踪,主要涉及到重复污点传播合并和无关污点指令删除,在污点检查点收集崩溃点上下文信息,根据不同类型设置污点检查点。
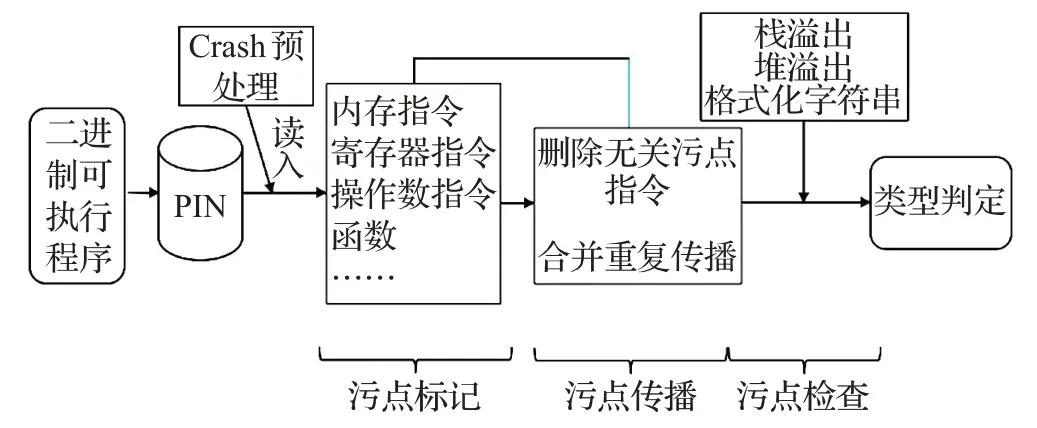
图6 系统执行架构图
类型判定阶段主要采用模式匹配方法,通过分析对污点信息收集模块获取的LOAD/STORE 指令,寄存器状态、内存地址特征,匹配栈溢出、格式化串、堆溢出漏洞崩溃特征。
输出如下:输出崩溃点上下文的污点传播情况、崩溃点指令操作和对应的寄存器内容、栈溢出崩溃点地址、Crash所属漏洞类型等。
4195584:mov dword ptr[rbp-0x8],0x90909090(rsp:7ffc53538080)(rbp:7ffc53538080)
4195591:mov dword ptr [rbp-0xc],0x91919191(rsp:7ffc53538080)(rbp:7ffc53538080)
[Write Mem B] 400507:mov dword ptr [rbp-0xc],0x91919191
counterWrite:1
4195598:mov dword ptr [rbp-0x4],0x0(rsp:7ffc53538080)(rbp:7ffc53538080)
[Write Mem B] 400523:mov byte ptr [rax],0x45
counterWrite:1
[Write Mem B] 400523:mov byte ptr [rax],0x45
counterWrite:2
[Write Mem B] 400523:mov byte ptr [rax],0x45
counterWrite:3
[Write Mem B] 400523:mov byte ptr [rax],0x45
counterWrite:4
[Write Mem B] 400523:mov byte ptr [rax],0x45
400523:mov byte ptr [rax],0x45 -- Stack overflow in 7ffc53538078
counterWrite:0
如图7所示,结合IDA进行具体分析验证该工具的有效性,打开IDA,将位置定位到0x400523,F5 翻译成伪代码进行分析,_int64 foo()函数两个变量v1、v2 在*((_BYTE *)&v1+(signed int)i)=69存在栈溢出漏洞。
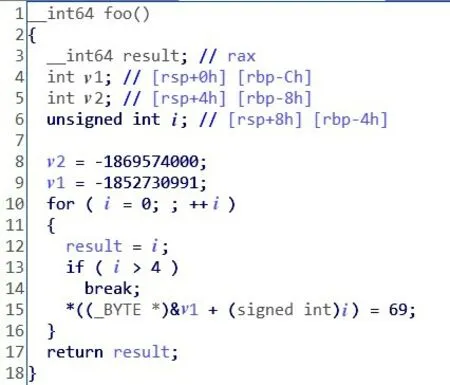
图7 IDA验证栈溢出函数
为了证明该原型系统在Crash类型验证方面的实用性,实验验证阶段选取10个CTF二进制可执行程序和5个二进制CVE漏洞进行测试,如表3所示。CTF二进制程序对应的Crash由AFL进行fuzzing得出,CTF赛题有栈溢出、堆溢出及格式化字符串3 种且较为简单,对这些Crash 逐个进行手动调试并结合BitBlaze 工具确认Crash 所属漏洞类型,留待与原型系统测试结果进行比对。二进制CVE 漏洞程序中,有存在格式化字符串漏洞的Wu-ftpd 2.6.0、Sudo.10,栈溢出漏洞的Libtiff 3.9.2和SWS 0.1.7,堆溢出漏洞的Libproxy 0.3.1,这些漏洞及对应的Crash 由NVD 漏洞库[22]、吾爱漏洞[23]等网站获取,Crash类型已经标注。
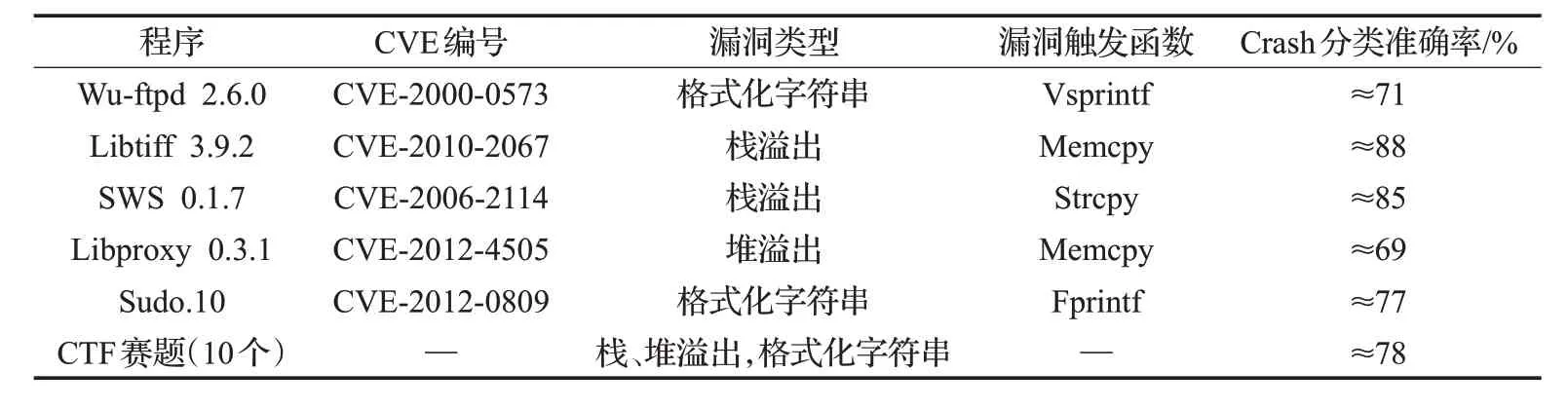
表3 实验验证分析归纳
以CVE-2000-0537 为例,该漏洞是在wu-ftpd 2.6.0及其更早版本中存在的漏洞,是一个典型的格式化字符漏洞,可将用户输入的数据作为格式化字符串传送给vsprintf()函数。通过原型系统验证,可以确定漏洞触发地址、栈帧布局、寄存器信息以及Crash 所属类型等信息。实验结果表明原型系统可以有效甄别Crash所属漏洞类型。原型系统准确识别出的Crash所属类型数目占Crash样本标注所属类型数的比例近似于71%。
由于Crash 数量大,与漏洞有直接或间接关系的Crash比例很小,对于由系统无效访问,空指针访问等与漏洞无关的无利用价值Crash,这里不进行考虑。通过对以上程序进行Crash 类性判定,与原Crash 样本中标注的Crash 所属漏洞类性进行对比,可以计算原型系统判定的准确率。该原型系统的误报主要是因为漏洞触发规则模块编写不够完善,虽然同种漏洞的原理是一样的,但是触发形式多种多样,如何合理编写触发特征以减少误报,是下一步实验的重点研究之一。
5 结束语
Crash 分析是漏洞挖掘利用的关键环节,本文主要研究Linux 系统下针对二进制可执行程序Fuzz 出的Crash 进行分类的问题,提出一种基于污点分析的分类方法,在Pin 插桩平台上设计了对二进制可执行程序进行漏洞检测和Crash 分类的工具。实验证明,该工具能够有效地识别出二进制可执行程序存在的漏洞类型,并判断出Crash和其中的某种漏洞相关。但该工具存在三个主要问题:一是无法有效对存在复合漏洞的二进制可执行程序进行分析;二是检测漏洞的类型不够完善,由于漏洞触发规则模块编写不够全面,对堆的一些其他漏洞(Fastbin、协议、逻辑漏洞等)无法进行检测;三是污点传播过程中对指令类型的传播规则设定不够全面,由于指令集异常庞大,没有考虑到一些特殊指令,例如xchg、cdq、rtdsc 等,这在一定程度上增加了误报率。下一步,将针对以上问题对该工具进行改进,在污点传播阶段增加指令覆盖面,重点研究如何完善漏洞触发规则,提高匹配效率。
