基于SSD方法的小目标物体检测算法研究
2020-07-04胡梦龙施雨
胡梦龙 施雨
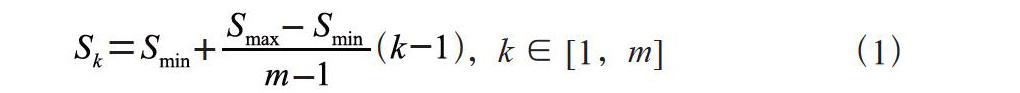


摘 要:SSD方法是目前为止主要的目标检测算法之一。针对该方法处理小目标物体检测时精度不高的问题,文章在对SSD卷积神经网络的网络结构进行分析的基础上,在使用原有多层卷积特征图结构的前提下通过特征增强的方法来改善网络结构,构建了一种新的小目标物体检测算法模型。将该模型在PASCAL VOC 2012目标检测数据集上进行精度检测,检测结果与原始的SSD网络相比有了较好的提升。
关键词:SSD方法;小目标物体;多层卷积特征图;特征增强
中图分类号:TP391.41;TP181 文献标识码:A 文章编号:2096-4706(2020)03-0005-05
Abstract:SSD method is one of the main target detection algorithms so far. Aiming at the problem of low accuracy when this method is used to detect small target objects,Based on the analysis of the network structure of SSD convolution neural network,this paper improves the network structure by the method of feature enhancement on the premise of using the original multi-layer convolution feature map structure,and constructs a new algorithm model of small target detection. This model is used to detect the accuracy of PASCAL VOC 2012 target detection data set,and the detection result is improved compared with the original SSD network.
Keywords:SSD method;small target object;multi-layer convolution feature map;feature enhancement
0 引 言
目标检测作为计算机视觉的基础研究内容,在近几年发展突飞猛进。2013年Ross Girshick等提出了R-CNN[1]算法,该算法的提出将原本只能通过手工提取特征的方式转变成通过神经网络自动提取特征的方式。在此之后,出现了很多基于卷积神经网络的目标检测算法的研究,一般来说分为基于候选窗口的方式或基于回归的方式两大类。
基于候选窗口方式的主要有2014年4月Kaiming He等提出的SPP Net[2]算法,该算法主要对R-CNN进行改进;Girshick对R-CNN进行了进一步优化,提出了Fast R-CNN[3]算法,将串行结构改成了并行结构,在分类的同时进行回归;Shaoqing Ren等人提出的Faster R-CNN[4]在Fast R-CNN的基础上使用了区域选择网络(RPN)来代替选择性搜索网络方法(SS)。基于候选窗口方式的算法存在的缺点是检测速度相对较慢,实时性效果较差。
2016年,Radmon等人提出了YOLO[5]网络模型。Liu等人又在YOLO的基础上提出了SSD(Single Shot MultiBox Detector)[6]网络,该方法是一种基于回归的目标检测方法,主要思想是在一张图片中直接预测,不需要推荐预选框和特征重组的步骤,真正意义上实现了端到端的方法。基于回归的目标检测方法有着检测速度快的特点,但是相对于基于候选窗口的目标检测方法有着明显的缺陷:检测精度较差,尤其体现在检测小目标的物体上。因此,如何提高检测精度是该方法的主要研究目标之一[7]。
本文基于南京市经信委重点项目“交通大数据公共服务平台”、南京市科委“大数据驱动下的大型客运枢纽监控预警与应急处置”项目中对交通十字路口车辆小目标检测问题,是项目中的一项关键技术。以SSD为研究的基础框架,通过对多层卷积特征图的改进来提升算法对小目标的识别能力。
1 SSD方法
1.1 方法原理
1.1.1 算法原理
(1)采用多尺度特征圖用于检测:SSD算法采用基础网络VGG16。不同于原本VGG16网络的是,该算法将该网络最后的两个全连接层fc6和fc7变成了3×3卷积层Conv6和1×1卷积层Conv7。移除用来防止过拟合的Dropout层以及全连接层fc8,并从中提取Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2作为检测用的特征图。通过这种方式可以在低层预测小目标,在高层预测大目标。
(2)设置了多种不同尺度的候选区域框:SSD采用多尺度特征方法,需要设置不同尺度的候选区域,其候选区域的选择公式如下:
1.1.2 算法实现步骤
(1)首先输入一张300*300的图片,将图片经过卷积进行特征提取,生成特征图。
(2)从每层的特征图中提取其中一张特征图,共6张,在特征图上的每个点上生成候选区域。
(3)将生成的候选区域通过非极大值抑制(NMS)筛选,输出结果。
1.2 评估指标
本文使用mAP指标以及FPS指标来评估算法的性能。
1.2.1 mAP指标
mAP是先对类别内求平均精度,之后再对所有的类别的平均精度求平均。其公式如下:
其中,C为样本种类数,AP为样本的平均精确度,计算公式如下:
其中,N表示recall的数量,r表示召回率,p(r)表示最大准确率,准确率p和召回率r计算公式如下:
1.2.2 FPS指标
FPS指1秒内识别的图像数,是用来检测模型的检测速度的指标。
2 小目标物体检测模型
2.1 算法模型
原本的SSD模型,没有将深层特征层的上下文信息与浅层特征层相结合。对于小目标物体在浅层特征层而言其特征相对过少,在浅层特征图中进行定位可能会出现漏检的情况。我们通过对深层特征图先进行上采样操作,再将其与浅层的特征图进行融合,可以提高对小目标物体的识别能力[8]。本文设计的网络结构如图1所示。
左边是原有的SSD算法网络结构,首先在Conv11_2特征层使用上采样操作得到Conv11_2_2特征层,需注意的是此时通过上采样得到的特征层必须要与其上一层的特征层维数保持一致。再将Conv11_2_2与上一层Conv10_2特征层进行特征融合得到Conv10_2_2特征层;再将Conv10_2_2特征层进行上采样操作并与上一层Conv9_2进行特征融合得到Conv9_2_2,以此方法依次得到余下的特征层Conv8_2_2、Conv7_2_2、Conv4_3_2。最后将Conv11_2、Conv10_2_2、Conv9_2_2、Conv8_2_2、Conv7_2_2、Conv4_3_2特征层送入预测层,进行目标的定位和分类。
2.2 特征增强方法以及采取的策略
特征融合主要有两种方法,一种是特征连接的方法,另一种是将两个特征图进行升维或降维等操作将其变成同样维度的特征图,再将每个对应的特征值相加[9,10]。本文使用的是第二种方法,通过对两个特征层进行加权操作,以此对需要检测的目标达到特征增强的目的。
如图2所示,首先将Conv2特征层进行上采样操作得到与Conv1特征层维数相同的特征图,再将Conv2特征层与Conv1特征层进行加权操作,将两个特征层合并为一个Conv1_1特征层。再将Conv1_1进行正则化处理得到最终的特征层Conv1_2。
图2 特征融合方法
通过对特征图的多次迭代可以将深层特征图中的所有上下文信息反馈给浅层特征图,这样就可以增强小目标物体的特征,从而可以更好地实现对小目标物体的识别。
这种方法可以保证网络结构总体不变,输出层还是6个特征图且其维数仍然保持不变。
3 实验环境与实验结果
3.1 实验环境
本文的实验环境为Linux系统,16 GB内存,GPU,使用Python3.7、TensorFlow等软件对算法进行实验。
本文的实验是在PASCAL VOC 2012数据集上进行的,实验的模型有本文改进的SSD算法,以及Faster R-CNN、YOLO、SSD300、SSD512。改进的SSD算法预测层有Conv11_2,Conv10_2_2,Conv9_2_2,Conv8_2_2,Conv7_2_2,Conv4_3_2。通过对比发现改进之后的SSD算法在识别小目标物体上有一定的精度。
3.2 预处理
在对模型进行训练之前,首先要对数据集进行预处理。本文所使用的是PASCAL VOC 2012数据集。因为着重需要检测小目标物体的情况,对于小目标物体的形变以及失真等特殊情况,本文也通过对数据集的处理进行了检验。
通过对数据集中的图像进行缩放、局部遮挡、旋转、形变等操作会使需要检测的目标出现多种不同的情况。同时,通过这种方法也使得训练集的数量增大,在一定程度上增加了模型的准确率。如图3所示,对其中一个图片的处理过程进行了展示。
(a)正常状态
(b)旋转
(c)局部遮挡
(d)缩放
(e)形变
图3 对图片的处理过程
3.3 实验结果
本文所使用的PASCAL VOC 2012数据集分为20类,包括背景可以分为21类,具体分类如表1所示。
表1 PASCAL VOC 2012数据集类型
PASCAL VOC 2012数据集作为测试数据集和训练数据集,将本文改进的SSD算法与Faster R-CNN、YOLO、SSD300、SSD512作比較,比较结果如表2、表3所示。
表2 PASCAL VOC 2012测试集mAP指标
表3 PASCAL VOC 2012测试集FPS指标
SSD300指的是输入图片的维度为300*300,SSD512输入图片的维度为则512*512。如表3算法在PASCAL VOC 2012测试集mAP检测结果来看,本文所改进的SSD算法相对于Faster R-CNN算法mAP值提升了2.2%,相对于YOLO算法mAP值提升了9.0%,与SSD300原始算法相比提高了1.1%,说明改进之后的算法确实优化了原算法中的一些问题。
通过表4的PASCAL VOC 2012测试集FPS指标可以看到Faster R-CNN的检测速度非常慢,FPS只有7.0,SSD512因为其输入图片维度的原因检测速度也不是很高,FPS只有19.0,YOLO的检测速度与SSD512相近,SSD300检测速度最高FPS达到46.0,本文改进的SSD算法相比较SSD300原始网络算法略低,这是因为在原有的网络结构中添加了部分迭代以及卷积操作,所以对检测速度有一定的影响,但是总体来说,因为其检测精度有所提高,相比之下检测速度的影响并不是很大。
通过对Faster R-CNN、YOLO、SSD300、SSD512以及本文改进的SSD算法的mAP和FPS的计算,可以得到检测速度与检测精度的分布图,如图4所示。
图4 检测速度与检测精度分布图
通过图4发现本文改进的SSD算法在检测精度上有一定的提升,但是在检测速度上比FPS最高的SSD300略慢一点。从测试集中选取一张图片,分别对SSD300和本文算法对小目标物体的检测进行了对比,结果如图5所示。
(a)SSD
(b)本文改进的SSD
图5 SSD与本文算法对比
从图5可以看到原SSD算法对小目标物体的识别能力很弱,图片中只识别出了左侧较大的物体。而对SSD算法进行改进之后,如图5(b)識别出了SSD算法没有识别出来的小目标物体,实验证明通过对SSD算法的改进有效地增强了对小目标物体的识别能力。
4 结 论
本文通过对原有的SSD算法的网络结构进行了改进,增强了算法对小目标物体的识别能力,并在一定程度上提高了检测精度,但是对于检测速度没有得到提高,并且在实际检测过程中发现仍然会有漏检的情况发生。因此对于实验过程中出现的问题,接下来的工作将是对改进算法速度上的优化以及对检测时出现漏检的问题进行进一步的研究。
参考文献:
[1] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]//CVPR 2014,2014:580-587.
[2] HE K,ZHANG X,REN S,et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [C]//European Conference on Computer Vision. Springer,Cham,2014.
[3] GIRSHICK R. Fast R-CNN [J/OL].arXiv:1504.08083[cs.CV].(2015-09-27). https://arxiv.org/abs/1504.08083.
[4] REN S,HE K,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,39(6):1137-1149.
[5] REDMON J,DIVVALA J,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [J/OL].arXiv:1506.02640 [cs.CV].(2016-05-09). https://arxiv.org/abs/1506.02640.
[6] LIU W,ANGUELOV D,ERHAN D,et al SSD:Single shot MultiBox detector [J].Computer Vision–ECCV 2016:21-37.
[7] 寇大磊,权冀川,张仲伟.基于深度学习的目标检测框架进展研究 [J].计算机工程与应用,2019,55(11):25-34.
[8] 谭红臣,李淑华,刘彬,等.特征增强的SSD算法及其在目标检测中的应用 [J].计算机辅助设计与图形学学报,2019,31(4):63-69.
[9] BELL S,ZITNICK C L,BALA K,et al. Inside-Outside Net:Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,2016:2874-2883.
[10] Kong T,Yao A,Chen Y,et al. HyperNet:towards accurate region proposal generation and joint object detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos:IEEE Computer Society Press,2016:845-853.
[11] 陈冰曲,邓涛.基于改进型SSD算法的目标车辆检测研究 [J].重庆理工大学学报(自然科学),2019,33(1):58-63+129.
[12] 王文光,李强,林茂松,等.基于改进SSD的高效目标检测方法 [J].计算机工程与应用,2019(13):28-35.
[13] 张建明,刘煊赫,吴宏林,等.面向小目标检测结合特征金字塔网络的SSD改进模型 [J].郑州大学学报(理学版),2019,51(3):61-66+72.
作者简介:胡梦龙(1993.05-),男,汉族,安徽淮南人,硕士研究生,研究方向:图形图像处理;施雨(1995.09-),男,汉族,江苏射阳人,硕士研究生,研究方向:人工智能。
