基于随机森林的信用卡违约预测研究
2020-07-04郭建山钱军浩
郭建山 钱军浩
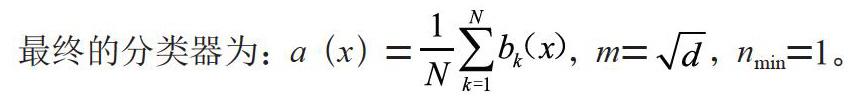
摘 要:近些年信用卡的违约情况呈现逐年上升的趋势,使商业银行面临严重的经营风险,商业银行若想在信用卡业务中获得利润,必须控制信用卡的违约率。关于信用卡违约的研究主要围绕信用评级展开,鉴于传统单一分类器预测模型拟合不足或过拟合的缺陷,提出改进后的随机森林预测模型,并在实证分析中与KNN、逻辑回归、决策树和GBDT相比较。模型提高了信用卡违约识别率,降低了违约风险,对提高商业银行的风险管控能力具有积极意义。
关键词:信用卡违约;逻辑回归;GBDT;ROC曲线;随机森林
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2020)03-0001-05
Abstract:In recent years,the default situation of credit cards has been increasing year by year,which makes commercial Banks face serious operational risks. If commercial banks want to gain profits from credit card business,they must control the default rate of credit cards. The research on credit card default mainly focuses on credit rating. In view of the deficiency or over fitting of the traditional single classifier prediction model,an improved stochastic forest prediction model is proposed and compared with KNN,logistic regression,decision tree and GBDT in the empirical analysis. The model improves the credit card default recognition rate and reduces the default risk,which is of positive significance to improve the risk control ability of commercial Banks.
Keywords:credit card default;logistic regression;GBDT;ROC curve;random forest
0 引 言
隨着近些年我国金融体制的改革发展以及支付方式的变革,信用卡在支付领域扮演着越来越重要的角色。从中国信用卡行业市场现状可以发现,信用卡累计发卡量以及信用卡人均持卡量逐年增长,与此同时,信用卡应偿信贷余额以及授信使用率也在逐步提高,这也导致消费额和透支额的扩大,不可避免地会产生一定的风险。因此,如何有效地利用信用卡用户产生的数据,通过数据挖掘找到降低违约风险的方法,显得尤为重要。
对于信用卡违约的研究,比较常用的方法是建立信用评分模型,也就是根据过去的用户信贷记录、个人信息以及是否违约情况,来预测将来是否会违约。国外对于这方面的研究较早也比较成熟,早在1999年,Brause[1]等就提出了将关联规则和神经网络结合起来预测信用卡欺诈,2018年,Mohamad Jeragh和Mousa AlSulaimi[2]研究了一种基于自动编码器和支持向量机(OSVM)相结合的新型无监督学习模型,效果也得以改善。国内关于这方面的研究起步较晚,不过发展迅速。2004年邹权[3]采用决策树和逻辑回归进行分析和评分,以此对接受的申请者给出不同的信用政策,2018年张双全[4]在传统智能算法的基础上结合模糊集理论、平均影响值法和支持向量机技术,得出改进的智能算法——IFBPNN模型,结论表明该模型相比传统模型预测效果更好。
纵观当前的研究现状,违约预测模型评估通常采用单一的分类器,较容易出现过拟合问题,拟合效果不是很理想。本文通过研究学习曲线,从树的数量、最大深度、叶节点最小样本数和最佳分割时的特征数4个方面,改进传统的随机森林模型,并与K近邻算法(KNN)、逻辑回归、决策树(CART)和梯度提升决策树(GBDT)这4种单一拟合效果较好的算法相比较分析,研究发现改进后的模型相比其他模型效果较好,提高了用户信用卡违约预测的精度和识别率,某种程度上对提高商业银行的风险管控能力具有积极意义。
笔者所学专业为计算机技术,研究方向为数据挖掘,在当前学习阶段主修机器学习、人工智能等方面的课程,并有一定的实践基础,与本文涉及到的研究方法相关,希望对该方面的研究有一定贡献。
1 随机森林预测模型
1.1 算法原理
基本思想:随机森林算法的基本思想基于集成学习(ensemble),也就是使用一系列学习器进行学习,并使用某种规则整合各学习结果,从而获得比单个学习器更好的学习效果的一种机器学习方法。通过取长补短,克服了一些算法的局限性。
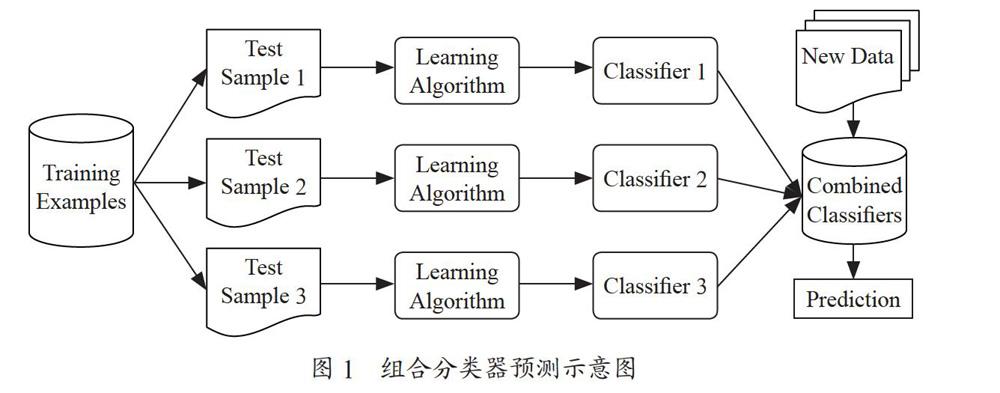
随机森林算法的基本原理主要基于Bootstrapping中的Bagging。首先利用Bootstrap抽样方法从原始数据集中抽取M个样本,然后在每个样本上训练分类器ai(x),建立M个决策树模型,再对每个单独分类器的输出取均值形成组合分类器,最后进行投票预测决定最终分类结果[5],即a(x)= ,如图1所示。
1.2 算法流程
1.2.1 使用随机子空间方法构建集成模型
(1)设样本数为n,特征维度数为d,模型数目为M。
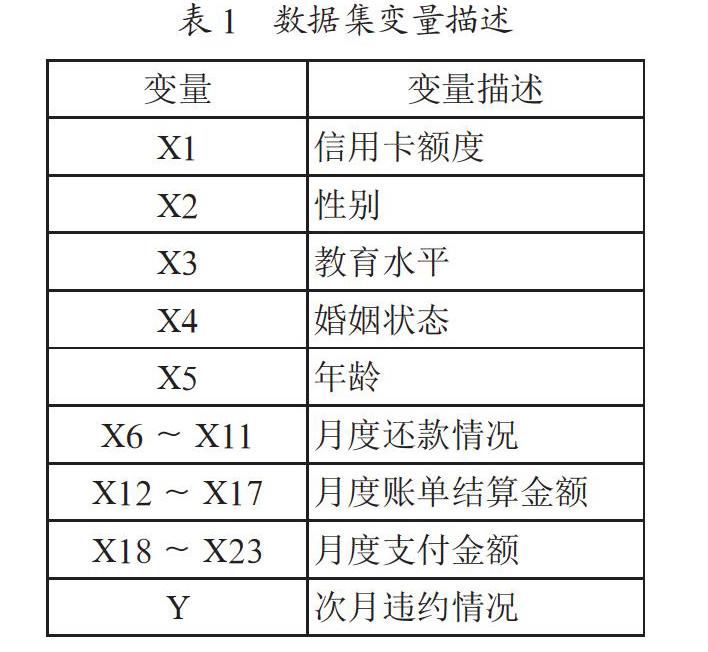
(2)对于每个模型m,选择特征数dm (3)对每个模型m,通过在整个d特征集合上随机选择dm个特征创建一个训练集。 (4)训练每个模型。 (5)通过组合M个模型的结果,将生成的整体模型应用于新数据中。 1.2.2 构建N棵树的随机森林算法 (1)对每个k=1,…,N,生成Bootstrap样本Xk。 (2)在样本Xk上创建一棵决策树[6]bk。 (3)根据设定的标准选择最佳的特征维度。根据该特征分割样本以创建树的新层。重复这一流程,直到样本用尽。 (4)创建树,直到任何叶节点包含的实例不超过nmin个,或者达到特定深度。 (5)每次分割,首先从d个原始特征中随机选择m个特征,接着只在该子集上搜索最佳分割。 最终的分类器为:a(x)=,m=,nmin= 1。 1.2.3 随机森林的参数 本文采用scikit-learn库中的RandomForestClassifier类,用到的参数如下: n_estimators:随机森林中树的数量; max_depth:随机森林中树的最大深度; min_samples_leaf:随机森林叶节点的最小样本数; max_features:寻找最佳分割时的特征数。 2 随机森林预测模型的实证分析 本文采用台湾某银行用户信用卡数据集进行实证研究,通过多种机器学习算法分析比较,以此得出最后的结论。 2.1 数据预处理 该数据集共有30 000条样本,包含24个变量。前23个输入变量描述用户信息特征,最后一个输出变量描述用户次月违约情况,“0”表示履约,“1”表示违约。其中有10个变量为分类数据,14个变量为数值型数据,变量描述如表1所示。 该数据集中“X3”教育水平变量包含14个缺失值;“X4”婚姻状态变量包含54个缺失值;“X12”中9月账单结算金额为负数时表示有存款结余无需还款,这种情况不存在违约的可能性,但样本却显示违约的数量有109个,此类数据为无效数据应舍去。经过前期处理后得到的实际样本数为29 823条。 本文将预处理后的样本数据随机划分为两部分,其中70%作为训练集训练模型,剩下30%作为测试集测试模型的效果。 2.2 实证结果分析 2.2.1 特征选择 由于输入变量较多,但并不是每个变量都有助于模型的训练预测,反而有可能因为相关性降低模型的有效性,因此需要先进行特征选择[7],剔除重要性较低的变量。 本文通过调用SelectKBest包,采用F评分和P值两个指标,对23个输入变量的重要性进行评分,根据Support选出重要性较高的前10个变量:“X1”“X6”“X7”“X8”“X9”“X10”“X11”“X18”“X19”“X21”,如表2所示。 本文利用GBDT对选取的10个变量进行重要性分析,排名如图2所示。 2.2.2 模型評估 本文主要分析比较5种分类模型,分别是KNN、逻辑回归、决策树、GBDT和随机森林,均在Python中实现。本文采用的模型评估[8]度量指标为Accuracy、F1_score和ROC曲线。 在KNN中,通过循环遍历数组,得出正确率较高的K值为14;在逻辑回归算法中,找到最佳正则化系数C为0.1,并以此验证学习曲线;在决策树算法中,分割标准选择更优的Gini系数,通过参数调优,得出最大深度为3,最佳分割时的特征数为7;在GBDT算法中,损失函数选择最小二乘(LS)回归,学习速率为0.1,最大深度为7,并作出特征重要性排名;在随机森林算法中,分割标准选择更优的Gini系数,通过改进树的数量、改进树的最大深度,改进树的叶节点最小样本数和改进最佳分割时的特征数4个方面,找到该算法的最佳参数,分别为100、5、20、8。 本文通过特征选择,划分数据集,建立了相应的评分模型,并训练模型,最后对30%的测试集进行了评估,正确率(Accuracy)和F1值(F1_score)对比如表3所示。 通过对比可以看出,决策树、GBDT、随机森林以及改进随机森林模型正确率都在0.800 0以上,但改进随机森林模型较高一些,除了KNN模型的F1值较低之外,其余的均较接近。因此改进随机森林模型拟合效果较好。 在二元分类问题中,一般设定预测为正的正样本为TP,预测为正的负样本为FP,预测为正的负样本为FN,预测为负的负样本为TN。准确度为Accuracy,精确度为Precision,召回率(即灵敏度)为Recall,精确度和召回率的调和平均为F1_score,在F1_score计算公式中,Precision简称P,Recall简称R。具体公式如下: 根据图3的曲线,树的数量达到100时正确率较高,一般来说树的数量越多拟合效果越好,但达到一定程度时泛化性能会降低,也可能出现过拟合的情况,因此取100较为合适。根据图4的曲线,由于特征变量较多,应限制树的最大深度,当最大深度为5时,正确率最高,拟合效果也较好。根据图5的曲线,树的叶节点最小样本数达到20时正确率较高,如果再增大可能会出现偏差,取20较为合适。根据图6的曲线,当构建决策树达到最优模型时,最大特征数为8正确率最高,拟合效果也较好。通过改进原有的随机森林模型,使正确率提高了0.200 0。
ROC曲线(即受试者工作特征曲线)是指在特定条件下,根据一系列不同的二分类方式(分界值或决定阈值),以假正率(False Positive Rate)为横坐标,以真正率(True Positive Rate)为纵坐标,反映敏感性与特异性关系的曲线。ROC曲线越靠近左上角,模型的查全率就越高。各个算法对应的ROC曲线如图7所示。
由图7可知,相比其他模型,改进随机森林模型的ROC曲线较光滑,没有出现过拟合的情况,AUC(即图例中的area,指曲线与坐标轴围成的面积,也就是曲线下方面积。)[10]的值较高,曲线下方面积较大,正确率较高,模型的预测效果较好。
通过Accuracy、F1_score和ROC曲线三个度量指标综合对比,可以看出决策树类的预测效果较好,决策树类中改进后的随机森林模型预测效果最佳,可以认为改进随机森林模型比其他单一分类器模型具有更好的预测效果。
3 结 论
在当前银行市场,信用卡用户的管理至关重要,充分利用过去的客户借贷记录,挖掘客户违约的特征信息,有助于提高银行对违约客户的识别能力。本文从数据集出发,首先对数据集进行前期处理,其次通过特征选择选取重要性较高的变量,在各个算法中对参数进行调整,最后采用Accuracy、F1_score和ROC曲线3个指标进行模型效果的评估。通过对比可以看出,虽然改进随机森林模型的F1值不是最高的,但跟其他模型相接近,同时改进随机森林模型的正确率最高,ROC曲线效果最好。可以得出结论,改进随机森林模型相比其他模型拟合效果更好,违约风险预测效果更佳。
当然在研究中也发现了不少问题,比如月度账单结算金额和月度支付金额变量存在大量为空的数据,是否应该对这些数据进行处理;主要的分类变量有性别、教育水平和婚姻状态,是否可以考虑增加诸如收入水平或住房情况等个人信息;各种算法的变量复杂,参数调整是否达到了最优程度等等。相信这些问题在之后的研究中会得到解决。
在未来的研究中,将会尝试更多不同的机器学习算法,应用集成学习的思想,组合单一的分类器,对现有的模型加以改进,适当提高算法复杂度,考虑并行化和样本权重,以期实现更好的预测效果。
参考文献:
[1] BRAUSE R,LANGSDORF T,HEPP M. Neural data mining for credit card fraud detection [C]// Tools with Artificial Intelligence,1999. Proceedings. 11th IEEE International Conference on,1999:103-106.
[2] JERAGH M,ALSULAIMI M. Combining Auto Encoders and One Class Support Vectors Machine for Fraudulant Credit Card Transactions Detection [C]// 2018 Second World Conference on Smart Trends in Systems,Security and Sustainability (WorldS4),London,England:2018:178-184.
[3] 邹权.基于数据挖掘的信用卡申请者信用评分模型研究[D].成都:西南财经大学,2004.
[4] 张双全.基于改进智能算法的信用卡客户违约预测研究 [D].长春:长春工业大学,2018.
[5] 余以胜.基于随机森林的用户行为识别模型研究 [J].电脑知识与技术,2017,13(7):156-157.
[6] KUMAR M. S,SOUNDARYA V,KAVITHA S,et al. Credit Card Fraud Detection Using Random Forest Algorithm [C]// 2019 3rd International Conference on Computing and Communications Technologies (ICCCT),Chennai,India:2019:149-153.
[7] XIE Y,LIU G,CAO R,et al. A Feature Extraction Method for Credit Card Fraud Detection [C]// the 2ndIEEE International Conference on Intelligent Autonomous Systems(ICoIAS2019),Singapore,2019:70-75.
[8] MITTAL S,TYAGI S. Performance Evaluation of Machine Learning Algorithms for Credit Card Fraud Detection [C]// 2019 9th International Conference on Cloud Computing,Data Science & Engineering (Confluence),Noida,India:2019:320-324.
[9] MACHADO M. R,KARRAY S,SOUSA I. T. LightGBM:an Effective Decision Tree Gradient Boosting Method to Predict Customer Loyalty in the Finance Industry [C]// 2019 14th International Conference on Computer Science & Education (ICCSE),Toronto,ON,Canada:2019:1111-1116.
[10] GOY G,GEZER C,GUNGOR V. C. Credit Card Fraud Detection with Machine Learning Methods [C]// 2019 4th International Conference on Computer Science and Engineering (UBMK),Samsun,Turkey:2019:350-354.
作者簡介:郭建山(1995.11-),男,汉族,福建莆田人,硕士研究生,研究方向:数据挖掘。
