基于K近邻一随机森林集成算法的肝病预测研究
2020-07-04蔡莉莉侯珂珂
蔡莉莉 侯珂珂


摘要:为了提高肝病预测准确率,提出一种基于K近邻一随机森林算法的肝病预测集成模型。首先对UCI数据集中的印度肝病数据集进行数据预处理;然后分别采用K近邻和随机森林算法构建出肝病预测的弱分类器;最后将两个弱分类器利用voting策略进行集成以获得集成肝病预测模型。同时分析了特征对模型的贡献程度。实验结果表明模型的性能指标F1一分数取得了84%的良好表现。因此利用该集成模型可为医生的临床诊断提供支持。
关键词:肝病预测;K近邻;随机森林;集成模型;F1-分数
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)13-0204-02
1引言
由于病毒感染、过量饮酒,吸人有害气体以及摄人受污染的食物、咸菜和毒品等,近年来,肝病患者一直在不断增加。慢性肝病容易诱发肝纤维化,若不及时诊治会诱发为肝硬化甚至恶化为肝癌。根据相关数据显示,全球肝癌及肝硬化死亡人数由1990年的130万人上升至2010年的180万人。原发性肝癌在2015年全球最常见癌症中排第六位。5%至20%肝硬化病例会演变成肝癌,而超过50%的原发性肝癌由肝硬化引起。由于肝癌通常于末期才可确诊,故死亡率居高不下,五年存活率约为5%。因此,在恶化成肝癌前,能够及时有效地确诊患者肝部疾病对于保障患者的生命健康起到至关重要的作用。
随着计算机技术及人工智能理论的发展,在医疗领域,将机器学习算法应用于疾病诊断的研究十分广泛。刘宇、王健等将XGBoost和卷积神经网络应用于心脏病预测研究中,葛皓昀将K近邻算法应用到肝炎预测中取得了较好的预测效果,此外,一些经典的机器学习算法如SVM,随机森林也被应用到相关疾病预测的决策问题中。因此考虑将机器学习的方法应用于肝病患者的诊疗中,一方面为医生的临床诊断提供指导帮助,另一方面也可有效提高医生的诊疗效率。在借鉴上述工作的基础上,本文提出一种基于K近邻一随机森林算法的集成学习策略,借助于集成学习良好的泛化性能及学习能力,将其应用于患者肝病诊断问题研究中。
2K近邻一随机森林的集成肝病预测模型构建
K近邻(K nearest neighbour,KNN)算法作为常用的监督学习算法之一,广泛应用于分类问题中。应用K近邻算法进行分类的核心思想是通过度量特征空间中样本之间的相似性,获得距离目标点最近的k个点,然后根据少数服从多数的分类决策规则,将k个点中类别标签数最多的类赋予目标点,从而确定目标点的分类。K近邻算法因原理简单,对异常值不敏感,使用起来较为方便,且分类效果较佳,得到了广泛的应用;但由于K近邻算法度量距离时其复杂性依赖于数据集的大小,当样本量较大时其计算复杂度较高,并且容易过拟合,因此在实际应用中也常将K近邻算法与其他算法结合使用以提高模型的泛化能力。
集成学习(ensemble learning)是时下非常流行的机器学习算法。它本身不是一种独立的机器学习算法,而是一种学习策略,基于数据构建出多个弱分类器模型,然后集成所有模型的建模结果,广泛应用于市场营销、疾病风险预测、金融风险评估等领域。集成学习算法常见的有袋装法(bagging),提升法(boosting)等。随机森林是隶属于bagging集成学习算法中的一种经典算法,其以决策树作为弱分类器,通过构建多棵决策树形成的随机森林对目标样本进行决策。森林中的各个决策树是独立的,将若干个弱分类器决策树的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的核心思想。
本文采用KNN算法和随机森林算法作为弱分类器,分别针对肝病数据集建立预测模型,然后采用投票(voting)策略对两个弱分类器进行集成,其流程图如图1所示。
步骤一,将原始数据进行预处理后按照训练测试集比例7:3进行划分,基于训练集分别采用KNN算法和随机森林算法构建出弱分类器;
步骤二,对构建出的两个弱分类器模型采用投票法进行集成,构建集成模型;
步骤三,计算模型的评价指标以评估模型的性能。
3实验结果与分析
3.1数据集描述
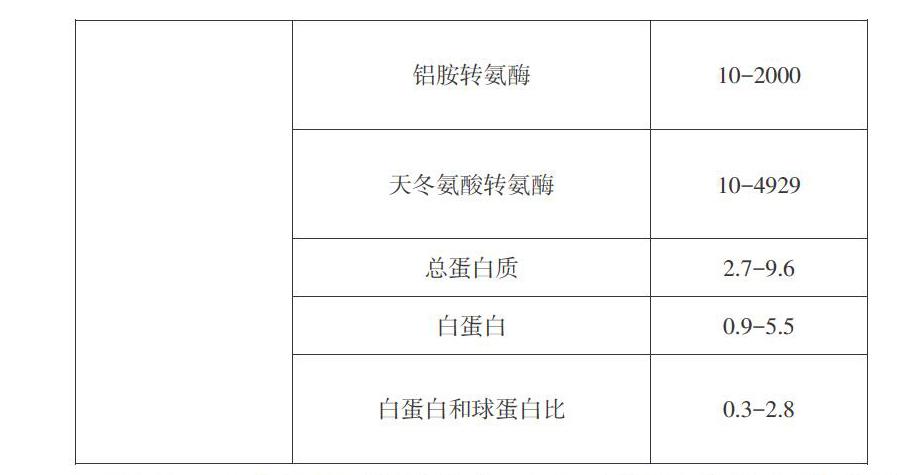
本文研究的肝病数据集来源于印度安得拉邦东北部收集的共583条患者数据记录,其中确诊肝病患者为416例,无肝病者为167例。该数据集性别分布为:男性441位和女性142位。样本集中每个样本具有10个特征及1个类别标签属性,其中类别标签标明了患者肝部是否患病。而10个特征分别记录了每位患者的性别、年龄及一些生理指标信息。特征列表如表1所示。
通过表1可以发现,该数据集的10个特征中大部分均为连续值属性,仅性别为离散型二值属性;而连续值属性中如碱性磷酸酶、铝胺转氨酶及天冬氨酸转氨酶等取值极差较大,如果不加处理则会对最终预测结果造成干扰。因此,对这类数据采用标准化方法进行处理。另外,数据集中有4位患者的白蛋白和球蛋白比存在缺失值,针对这四条缺失的记录,采用中位数进行填充。
3.2模型评估标准
该医学问题事实上是个分类问题,分类模型的评价指标有准确率(Accuracy)、查准率(Precision)、查全率(Recall)、Fl一分数等。基于医学问题的特殊性,本文分类模型的主要目的是正确筛查出患有肝病的病人。假设患有肝病的样本为正类样本,则未患病的样本为负类样本。在该问题中,我们更关注正类样本被有效识别为正类的准确性,即正类样本的查准率和查全率指标。因此在下面的模型评估指标中选取预测准确率,正类样本的查准率、查全率及F1-score作为模型的评价指标。
3.3实验结果分析
本实验的实验环境为:CPU为Intel i5 2.39GHz;RAM为4GB。采用skleam模块进行程序实现,实验参数选取采用网格搜索法确定K近邻的最佳K值为21,随机森林中决策树的个数为9。基于训练集训练后的弱分类器模型及集成模型在测试集上的性能表现如表2所示。
由表2可以看出,采用KNN算法及随机森林算法构建的集成模型融合了两种算法的优势,使得模型的分类准确率和F1-分数得到了提升,泛化性能较为优越。
由于集成模型中的随机森林仍然属于树模型,对于树模型可以判断每个特征变量对模型的贡献程度,从而判断哪些特征变量对于患肝病的影响更为显著,为医生临床诊断提供参考指标。图2绘制了各个特征对于预测模型的重要性程度。
如图2所示,其中排在前5位的F2,F4,F5,F0,F6分别代表特征总胆红素、碱性磷酸酶、铝胺转氨酶、年龄、天冬氨酸转氨酶。因此患者应着重关注这些指标,将他们控制在正常范围内以降低患病的概率;而患病风险一般是随年齡增长而增加,因此对于年长者也应格外关注自己的这些指标。对于医生在后续的临床诊断中也可参考这些指标的数值作为诊疗判断依据。
4结论
本文使用uCI数据集中的印度肝病病人数据集展开研究,提出一种基于K近邻和随机森林的集成模型用于预测病人的肝脏是否患病。实验结果表明,该集成模型提高了样本集的泛化能力。此外,针对用于建模的特征集合进行了重要性的评估,找出了对模型贡献程度较高的一些指标,为患者的就医指导提供了相关依据,同时也对医生的临床诊断具有一定的参考价值。
