基于双向门控循环单元和双重注意力的实体关系抽取*
2020-07-02谢卓亨李伟铭冯浩男李明轩陈珂
谢卓亨,李伟铭,冯浩男,李明轩,陈珂
(广东石油化工学院 计算机学院,广东 茂名 525000)
自然语言处理范畴里的信息抽取主要是从文本数据选出的信息创建相应的实体关系。实体关系抽取则是信息抽取里非常重要的环节,其功能是结构化地识别已标记的实体间关系[1]。现阶段实体关系抽取普遍采用基于句法特征工程、基于核函数和基于神经网络等方法。基于句法特征的方法其优点是了解上下文,考虑到语境的因素,缺点在于语法结构的复杂需要大量的人工进行特征标注,难以进一步提升该方法对关系抽取任务的精准性。基于核函数的方法通过注重语料本身的结构信息,输入对象为语法结构树的输入,关系分类是通过语料之间的结构相似性,其优点在于无需构建多维的特征空间向量,缺点是长语句的结构树复杂,使得分析过程耗时缓慢。文献[2]主要探讨基于核方法中选取不同语料树和最短路径的关系在关系提取中的性能问题,取得了不错的进展。近年来机器学习领域不断地出现神经网络的身影,许多人倾向于采用神经网络去构建机器学习中的模型。文献[3] 为了解决递归神经网络模型中时间复杂度的问题,提出了基于分析树和递归神经网络的方法,却没有考虑到文本的特征信息。文献[4]提出了基于逐词输入双向循环神经网络的模型来提取文本信息特征,缺点在于没有消除无用信息和保留有效信息。黄兆玮等[5]提出了基于 GRU和注意力机制的方法来抽取实体关系,该模型收敛快,但拟合的效果一般;车金立等[6]则采用了远程监督结合双重注意力机制的方法,较好地取得了有效信息,但没有简化输入语料信息,整个数据过于庞大。以上方法都取得了一定的效果。
本文借鉴以上设计思路,考虑到神经网络的优势,采用cw2vec、双向门控循环单元和双重注意力机制来构建模型。使用cw2vec词嵌入模型训练出词向量库作为输入值之一,进而加大词与词之间的关联。使用双向门控循环单元神经网络消除前后词对该词的影响和歧义性,使用双重注意力机制提高对关注目标的细节信息,剔除无用信息。
1 基于双向门控循环单元和双重注意力的中文关系提取
双向门控循环单元和双重注意力实体关系抽取的神经网络模型结构(如图1所示)主要分为五层:数据预处理层、嵌入层、双向门控循环单元层、注意力机制层和输出层。

图1 双向门控循环单元和双重注意力实体关系模型
1.1 数据预处理层
该层结构主要是将实体对、关系和对应句子数据经过分词、独热编码、词向量化处理后转变为可被计算机快速处理的序列向量,保持数据本身特征后为下一层提供输入数据。
一个具有r个词的句子可表示为S= {x1,x2,x3,…,xr},利用cw2vec模型将词x1,2,3,…,r映射到对应的200维的向量空间来进行句子的向量化。其表示为
er=Wordw.vi
(1)
式中:vi为词的独热编码表示形式;Wordw为句子的向量矩阵,w为词向量维数,取200。
此时,词的向量化为
ev={e1,e2,e3,…,er}
(2)
1.2 嵌入层
该层使用 cw2vec模型将中文语料库映射到低维向量,每个词语使用n-gram计算出相对应的笔画序列。计算句子的相似度时,先计算出词WA,WB之间的相似度,查询HowNet[7]得到相应的DEF集合,可得词WA,WB的最大相似度为
simW(WA,WB)=sim(DEFWA,DEFAB)
(3)
此时,句子的相似度simS(s1,s2,n)为
(4)
(5)
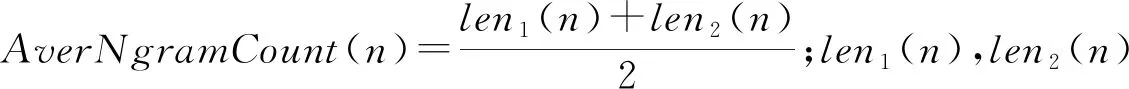
1.3 双向门控循环单元层

图2 GRU单元内部结构
该层将从cw2vec模型训练而得的词向量库和上一层的数据通过扁平化操作转变为低维数据,便于模型的训练,通过双向门控循环单元多次迭代训练后获得输入数据的特征向量,为自我学习并寻找到一组合适的参数和一个符合模型输入值到输出特征值之间联系的函数。GRU(门控循环神经网络)是一种改进的循环神经网络结构,GRU解决了时间序列中时间步距离较大的依赖关系的问题,并且通过学习门来控制信息的流动,能很好地应用在实体关系抽取中。GRU单元(见图2)包括更新门和重置门,使其具备学习长距离内容的能力。
更新门zt为zt=σ(Wz·[ht-1,xt])
(6)
重置门rt为rt=σ(Wr·[ht-1,xt])
(7)
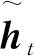
(8)

(9)
t时刻记忆体的值为yt=σ(W0·ht)
(10)
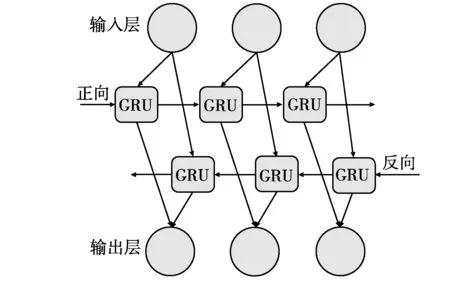
图3 双向GRU网络
利用正向和反向输入的信息,采用双向GRU网络作为模型的一部分,其结构见图3。
双向GRU网络多了一层隐藏层,文字信息可以通过正向和反向输入,第x个文字的输出为
(11)

神经网络学得权重向量Ω后与由双向门控循环单元层训练得到的特征向量进行矩阵乘积后得到基于字级别的特征向量R,将特征向量R与句子特征r进行矩阵相乘后再与relation_embedding相乘加上偏移bias后,再经过字、句子级别注意力层。
1.4 字、句子级别注意力层
注意力机制的出现,可以让计算机在处理数据的行为更接近于人类的行为,更好地解决计算机注意不集中的问题。本文在模型中使用词级别注意力层和句子级别注意力层的双重注意力,设由实体(e1,e2)所有句子集合S={s1,s2,s3,…,si},设e1与e2的关系为L,集合S中每个句子si都含有一定量的信息表示L,为了测定L,先把集合S转成对应的向量Sv,其表示为
(12)
式中:βi为句子si的权重;A为一个对角矩阵。
此时,集合S的向量表示形式
(13)
得到Sv后,用一个线性函数表达出关系L的得分,其表示为
y=MSv+b
(14)
式中:b为偏置量;M为关系矩阵。
1.5 输出层
输出层的结果由GRU输出的向量,经过字级别注意力层后再经过句子级别注意力层的处理求得,再经过softmax算法的处理后得到一个score。此时,将score通过一次softmax with temperature放大分类结果,从而获得关系分类结果。
2 实验结果与分析
2.1 实验数据和实验模型
实验采用的是远程监督学习模式, 通过远程监督的模式来爬取数据集。该数据集包含12类关系(父母、师生、兄弟姐妹、夫妻、合作、同门、情侣、祖孙、朋友、上下级、亲戚、同学),80000条关系语句,数据集格式见表1,并抽取60000条为训练语句。训练模型的参数设置见表2。

表1 实验数据格式

表2 模型参数表
为了比较本文使用的模型中注意力机制对命名实体关系抽取效果的影响,将模型拆分为:(1)利用训练语料无字和无句子注意力层机制模型,记为GRU;(2)利用训练语料采用句子注意力层和无字注意力层的单注意力模型,记为SattGRU;(3)利用训练语料采用字注意力层和无句子注意力层的单注意力模型,记为WattGRU;(4)利用训练语料采用字注意力和句子注意力层模型的双注意力模型,记为WattSattGRU。
2.2 结果分析
本文基于Google的深度学习框架tensorflow实现4种模型的关系抽取的训练,并在训练时使用交叉熵作为模型的损失函数,还使用L2正则化防止模型出现过拟合和Dropout技巧防止神经网络连接过多导致模型训练时间过长,并且对于每一种模型,都尽量地通过调节学习率、词、句子向量的大小、训练次数等参数以得到最好的训练结果。
为了更方便对比模型之间的性能,本文采用准确率(ACC值)、损失值(sofxmax_loss)和正确率-召回值(P-R)曲线来对模型进行评估。P-R图能够直观地显示出模型性能的优劣,通常,P-R曲线下所包含的面积越大,则表明改模型性能越好。4种模型实验经过350次迭代训练后,每50次训练输出的ACC值、sofxmax_loss值和P-R曲线分别见图4、图5和图6。

图4 4种模型ACC值 图5 4种模型softmax_loss值 图6 4种模型的P-R曲线
由图4可知,使用注意力机制(WattGRU模型和SattGRU模型)相比无注意力机制(GRU模型)表现得更好,而本文提出的双重注意力机制模型(WattSattGRU模型)相比于其它两种使用单层的注意力机制拥有更高的ACC。由图5可知,使用双层注意力的模型在训练的后半部分收敛得更快,且在训练中具有更低的损失值。图6中,使用单层注意力机制(WattGRU模型和SattGRU模型)分别考虑了语料中字或句子中的信息,相比完全不考虑语料中特定信息的注意力机制(GRU模型)在一定程度上提高了模型的性能。而使用双重注意力机制(WattSattGRU模型)相比其它三种模型的表现更好,其原因是双重注意力机制模型可结合字符级与句子级机制的优点,通过对字符级注意力机制自动捕获句子中关键的特征信息,再通过句子级注意力解决了句子与句子之间的噪声问题,从而提高实体关系抽取的准确率。
3 结语
本文针对自然语言处理中的实体关系抽取,提出了基于双向门控循环单元和双重注意力机制的模型。实验表明该模型有效地提高了文本实体识别关系的精确度。但由于数据的限制,模型评估结果达不到测试集上的表现。因此,下一步的工作将进一步扩展实体关系表示,探究各种实体关系的度量方法,并进一步优化模型。
