基于深度CRF网络的单目红外场景深度估计
2020-07-01王倩倩赵海涛
王倩倩,赵海涛
基于深度CRF网络的单目红外场景深度估计
王倩倩,赵海涛
(华东理工大学 信息科学与工程学院,上海 200237)
对单目红外图像进行深度估计,不仅有利于3D场景理解,而且有助于进一步推广和开发夜间视觉应用。针对红外图像无颜色、纹理不丰富、轮廓不清晰等缺点,本文提出一种新颖的深度条件随机场网络学习模型(deep conditional random field network, DCRFN)来估计红外图像的深度。首先,与传统条件随机场(conditional random field, CRF)模型不同,DCRFN不需预设成对特征,可通过一个浅层网络架构提取和优化模型的成对特征。其次,将传统单目图像深度回归问题转换为分类问题,在损失函数中考虑不同标签的有序信息,不仅加快了网络的收敛速度,而且有助于获得更优的解。最后,本文在DCRFN损失函数层计算不同空间尺度的成对项,使得预测深度图的景物轮廓信息相比于无尺度约束模型更加丰富。实验结果表明,本文提出的方法在红外数据集上优于现有的深度估计方法,在局部场景变化的预测中更加平滑。
红外图像;深度估计;条件随机场;有序约束
0 引言
单目图像深度估计是计算机视觉中最基本的任务之一,已经在场景理解[1]、3D建模[2]、机器人[3]、自动驾驶[4]等领域获得了广泛应用。图像深度即图像上某点像素到拍摄相机的距离。早期的单目深度研究主要关注几何假设,如箱体模型推测场景的空间布局[5]等,由于其严格的环境假设导致模型只在特殊场景下有效。
在单目场景深度估计的研究中,基于概率图模型(probabilistic graphical models, PGM)的方法能够在输入和输出之间建立结构化联系,因此被广泛应用到单目深度估计中。马尔可夫随机场(Markov random field, MRF)和条件随机场(conditional random field, CRF)是应用最多的PGM方法,他们的关键点在于构造合理以及正确的特征表示。早期的研究[6]关注如何从单目线索中构造MRF的绝对特征(一元特征)和相对特征(成对特征),但是这些纹理变化、运动、遮挡、阴影、散焦等单目线索都是低维手工特征,缺乏场景的通用性。
为了解决特定场景的限制,结合语义等其他任务信息[7-8]和基于数据驱动的非参数方法[9-10]在一定程度上缓解了场景限制问题。Liu等学者[7]以语义分类和几何先验为前提条件,首先通过MRF完成对图像的语义标注,之后使用预测的语义标签来指导深度估计模型。但在现实生活中,很难获得可靠的语义或其他额外信息。基于数据驱动的非参数方法是通过视觉相似性比较,从具有图像-深度的数据集中搜索候选图像的近似深度图。Liu等学者[9]将深度估计当作连续离散的CRF优化问题,采用级联的GIST、PHOG等手工特征通过K近邻算法检索前个候选深度图,但是CRF成对项只考虑了相邻超像素之间的遮挡关系。
Eigen等学者[11]首先将卷积神经网络(convolutional neural networks, CNNs)应用在深度估计,从图像块上训练两个尺度的CNNs,从而获得了较好的结果。之后的很多研究都是通过修改深度网络框架以期待获得更精确的结果。Laina等学者[12]在ResNet[13-15]中利用了反向Huber损失;Gu等学者[13]基于ResNet估计红外图像的深度;Wu等学者[14]在CNNs的基础上引入循环神经网络(recurrent neural network, RNN)的序列特征用于红外视频的深度估计。
上述基于深度学习的方法由于没有考虑优化结构损失,从而造成预测深度图的景物轮廓模糊等问题。CRF(或MRF)明确地包含了结构约束,CNNs与CRF(或MRF)的结合成为深度估计、语义分割等视觉任务的主流方法。Chen等学者[16]采用全连接的CRF[17],通过平均场近似实现CRF推理,成对项特征来自预设的颜色和位置特征。Li等学者[18]提出深度回归和深度精细框架,该模型CRF成对特征的设计来自文献[17]。Liu等学者[19]提出了用于深度估计的DCNF模型,作者致力于在一个统一的框架下学习连续CRF和CNNs。后来,Liu等学者[20]进一步提出全卷积网络训练和超像素池化方法。文献[19-20]中CRF成对特征均来自颜色、颜色直方图和纹理这3个简单预设信息。Xu等学者[21]将Attention机制与CNN-CRF结合用于深度估计,其CRF也是针对可见光图像设计的。
由于红外和可见光的成像原理差异,使得可见光图像适用于光线充足的环境,而红外图像不受光线条件的限制,这使其特别适用于夜间无人驾驶等夜视应用[22],因而估计车载红外图像的深度信息意义重大。早前针对红外图像的研究[23-24]大多停留在手工特征的提取上,由于红外图像存在纹理、色彩信息不丰富等缺点,提取针对红外图像的特征具有一定的挑战性。
本文将深度估计表示为离散CRF学习问题,提出深度条件随机场网络学习模型,该模型主要由特征学习和CRF损失层组成。首先,一元项对单个像素的信息进行了估计与约束,成对项鼓励相邻像素拥有相似的深度信息。本文的一元特征是基于Dense-Net[25]的深度卷积网络,充分利用了密集连接机制,能够通过特征在维度上的连接实现特征重用,使得模型的参数更少,性能更优。Noh等学者[26]指出浅层CNNs可以获得某些低级特征及其非线性组合,本文成对特征来自四层密集连接的全卷积网络,为红外图像提供了更丰富的特征表示。其次,受文献[27-28]启发,并考虑车载图像的远近特性,本文将连续深度值离散到对数空间以获得有序标签,从而在CRF损失层中提出自适应Huber Penalty来增加标签有序性约束和多尺度信息交互约束。
1 基本原理
Cao等学者[27]已经证明将传统的回归问题转化为有序多分类问题,不仅会增加预测结果的正确性,而且会加快预测效率。针对车载红外图像本身存在的特点,本文在对数空间里平均分割真实深度图获得各个深度层级的分类标签,用于深度估计实验:

式中:Î{1,2,…,},l(k)和d(k)分别表示第张图像上像素的真实深度标签和真实深度值;min和max分别表示原深度图中所有像素点的最小和最大真实深度值;floor(×)表示向下取整;是深度标签的等级。
图1(a)、(b)展示了数据集中任一深度图在原始空间和对数空间的分布情况,可以得出,在对数空间里分割原深度图可以获得更加均匀的深度分布。图1(c)、(d)表明值的选取影响整个分类的好坏,如果选取过大,说明分割很密集与原深度图相差较少,则对提高预测效率贡献较小;反之,分割结果会很稀疏与原深度图相差较大,则会降低预测正确率。本文通过实验分别设置值为12、22、32、52、72,从数据分布图上可以得出结论:=32时,效果最佳。
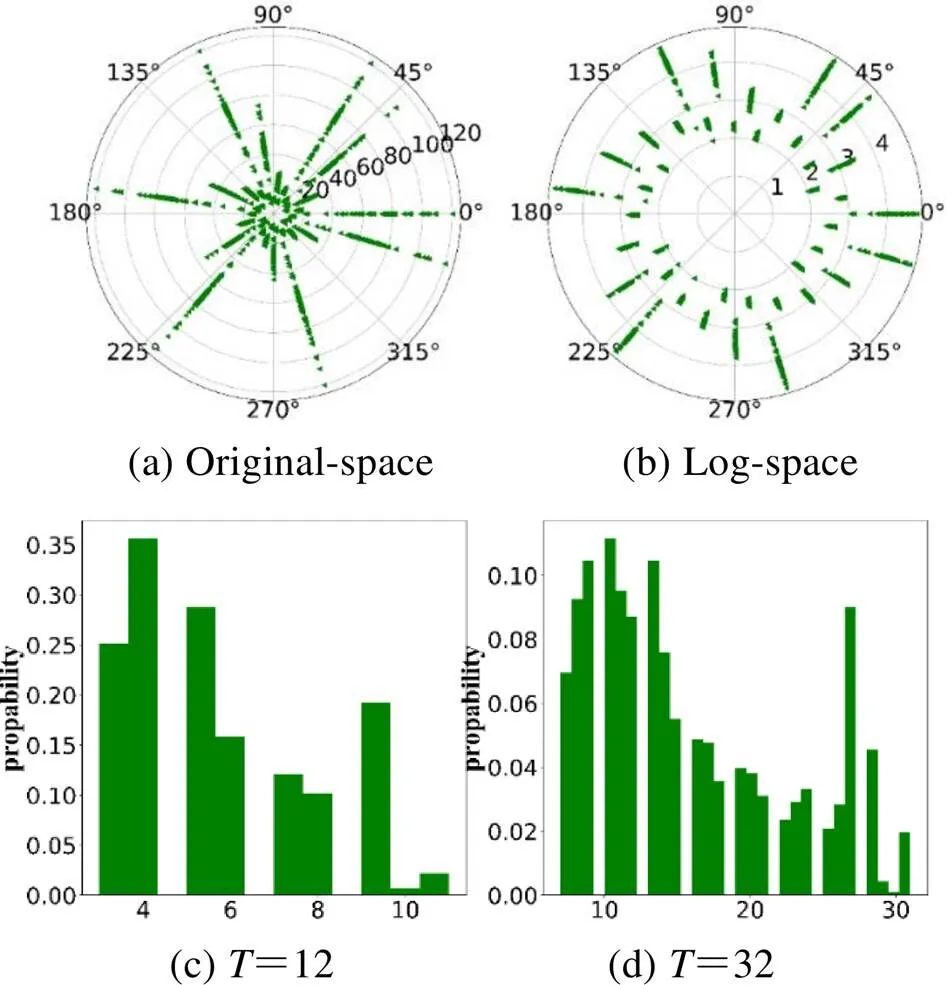
图1 深度分布
2 深度估计模型的设计
本文的目标是估计红外图像上每个像素点的深度标签信息,将单目深度估计问题当作CRF学习问题,从而提出深度条件随机场网络学习模型(deep conditional random field network, DCRFN)。DCRFN的整体结构如图2所示,由特征学习和CRF损失层组成。在特征学习中,采用两个深度卷积模型分别学习CRF的一元特征和成对特征。其中,一元模型直接从输入图像学习每个像素到深度标签的映射,从而获得全局深度估计的结果;成对模型旨在获得邻域像素之间的约束关系,与传统CRF成对特征的简单预设不同,本文提出的成对特征可以从一个新颖的深度卷积网络中提取。在CRF损失层,其CRF一元项和成对项来自两个深度卷积模型的输出,通过最小化负对数似然获得最优的深度估计结果。
2.1 DCRFN描述
假设={1,…,I}表示任意一张红外图像,其中是输入图像的总像素;={1,…,Y}表示每个输入像素的深度标签,其中YÎ{1,2,…,l}。CRF为给定随机场条件下,离散随机变量的马尔科夫随机场。条件随机场(,)可以通过如下的Gibbs分布表示:

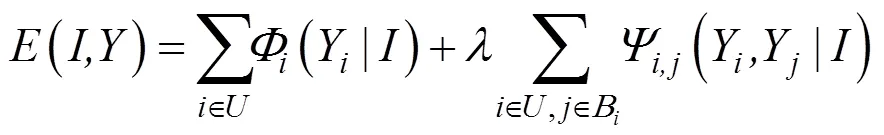
式中:是平衡参数。一元势反映了每个像素分配标签的置信度,成对势,j鼓励相邻像素被赋予相同的深度标签。表示输入红外图像的所有像素,B是像素(Î)的邻域。
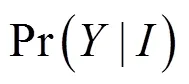
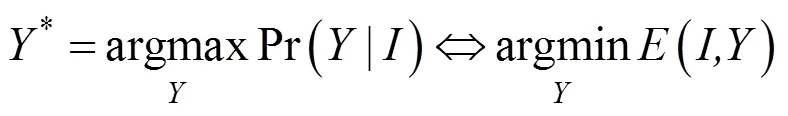
2.2 势函数
根据图2的两个深度卷积模型重新定义CRF的一元势和成对势。输入红外图像经过一元模型直接学习每个输入像素到深度标签的映射(1),经过成对模型(2)在邻域上建立相关关系;通过特征学习的(1)、(2)作为输入传递给CRF损失层。
2.2.1 一元势函数
CRF的一元势,也就是等式(2)的第一项。本文引入密集连接模型作为一元分类器,其势函数定义:
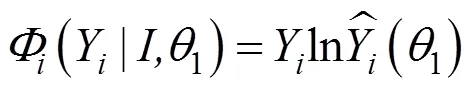
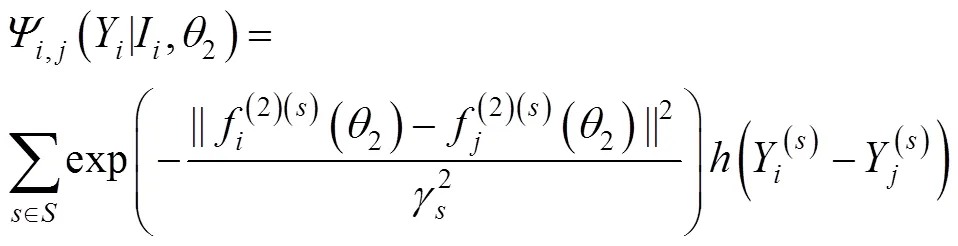
一元模型是基于Dense-Net的深度卷积网络,主要由密集块、上采样模块和卷积层组成,其密集块如图2所示。输入红外图像首先经过一个7×7的卷积层获得丰富的特征,之后通过4个密集块,每个密集块之间通过3×3的卷积连接实现尺寸的降低。通过对比实验确定各层输出通道数从前到后为4、8、12、24。密集块充分利用了跨层连接操作,每个层都会与前面的层在维度上连接在一起,并作为下一层的输入,要求各层的特征图大小要一致。由于池化操作会损失大量的细节信息[28],本文用卷积操作替代平均池化实现下采样。之后经过上采样模块恢复特征图尺寸至真实深度图尺寸。本文将最后两层全连接改为全卷积结构,输出特征图像尺寸为[40,144,32],从而实现像素级别的分类预测。
2.2.2 成对势函数
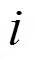
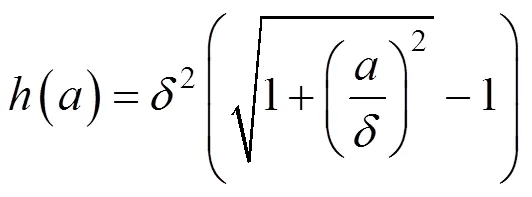

图3 DCRFN邻域约束关系
一元项只对单个像素的信息进行了估计与约束,成对项鼓励相邻像素拥有相似的标签信息。本文首先考虑红外图像无颜色且纹理信息不丰富,很难通过手工提取特征的缺点;其次考虑到CRF推断的可行性,成对模型在Dense-Net思想上引入跨密集块的密集连接。由于只有4层卷积,且卷积大小均为3×3,大大减少了模型的参数量,使得CRF在邻域上实现精确推断。通过2×2和4×4的池化操作实现降采样,使得跨层连接不受特征图尺寸的限制,从而通过全密集连接获得红外图像丰富的成对特征。
2.3 DCRFN的推理和学习
等式(5)、(6)分别定义了CRF的一元势和成对势,本文通过最小化能量函数实现对参数的更新,对参数求偏导:
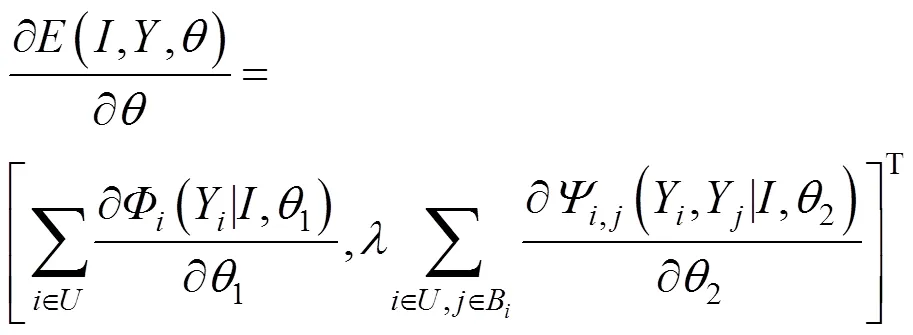
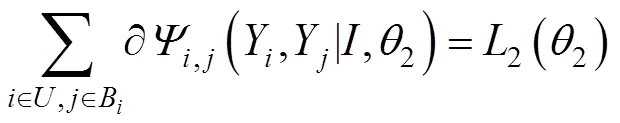
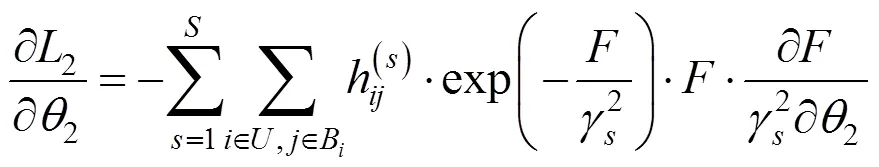



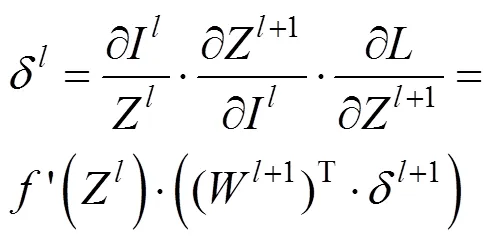
进一步,通过BP对参数反向推导,2关于第层权重2和偏置2梯度为:
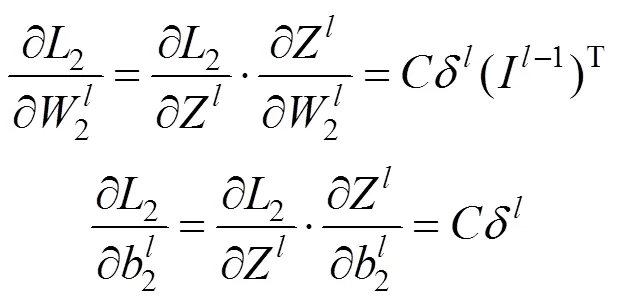
3 网络训练
3.1 数据采集
NUSTMS数据集由南京理工大学无人车队拍摄所得,包含5098对由远红外摄像机拍摄的红外图像和测距雷达生成的深度图。红外图像和相应的深度图的分辨率分别为576×160和144×40。本文数据集被分成训练集(3488对),验证集(586对)和测试集(1024对),数据集的深度范围为3~100m。其数据采集装置如图4所示。
3.2 训练过程
本文所有实验均在GeForce GTX 1080Ti显卡上采用深度学习库TensorFlow实现。在训练阶段,预先对红外图像进行归一化,通过截断正态分布来初始化权重,并将偏置初始化为零。采用计算每个参数自适应学习率的优化器Adam Optimizer来更新权重和偏置,初始学习率设置为1×10-4。实验设置迭代次数为100000,batch-size为4。成对项的参数涉及{,1,2,3,},其中参数用于平衡CRF一元势和成对势的贡献程度,本文在验证集上采用网格搜索,在区间[0,1]上确定表现最优的参数,取值为0.3时可以获得最优的rel和rms。s,Î{1,2,3}等价于在尺度下相似特征的方差,它表达了相似特征的相似性和接近度。是自适应Huber Penalty的常数,首先将=1.5作为初始化,在验证集上确定=1.2最佳。整个网络在训练集上耗时约18h,运行一张576×160的红外图像约0.04s(包括前端和后端)。
4 实验结果与分析
采用误差和正确率准则来定量评价本文提出的深度模型的表现,则有:
1)误差准则
2)正确率
4.1 DCRFN超参数的选择
参数决定了成对势函数的能量约束原则,它不仅影响模型的复杂程度,而且影响预测深度图的平滑性。本文将参数分别设置为0、1、2、3、4、5,在评估指标和模型大小方面分析最优参数。表1展示了不同值的表现,当的值大于或等于3时,误差和正确率准则趋于稳定,最后一列表明模型尺寸随着尺度参数的增大呈现上升趋势,为了实现更小的模型尺寸和更好预测性能的目标,本文设置=3。
除此之外,DCRFN的超参数1,2,3表达了在尺度参数=3下相似特征的方差,决定了成对势函数的能量在像素的特征空间邻域的分布。若参数越小,则能量集中在特征空间较小的邻域内,使得模型对图像的边缘更敏感;反之,能量分散在特征空间较大的邻域内,使得模型对预测深度图的平滑性贡献更大。本文首先通过学习曲线缩小1,2,3的搜索范围为[10,20]、[20,30]、[25,35]。实验发现3在区间[25,35]的变化几乎不影响模型的性能,故取3为26。其次以rel指标为参考(如图5),通过网格搜索在1,2,空间内搜索最优参数,其中颜色越深表示rel值越小,颜色越浅表示rel值越大,当1=13,2=24时,rel指标达到极小值,即寻得最优参数。

(a) 车载远红外相机及测距雷达;(b) 雷达散点图;(c) 原始红外图像;(d) 真实深度标签

表1 定量评价指标在超参数S上的比较结果
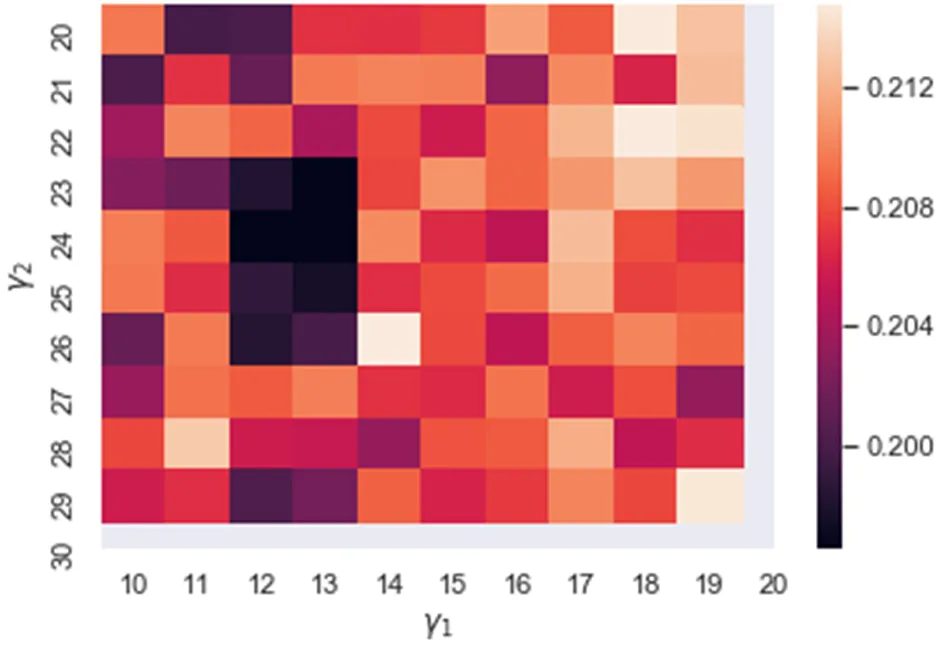
图5 DCRFN超参数寻优
4.2 实验结果分析
在给定模型最优超参数的情况下,表2列出了本文提出的DCRFN与一些经典方法定量比较的结果。可以看出,在NUSTMS数据集上,本文方法优于有监督学习的方法。相比较于文献[6],本文方法在误差和正确率两个评估指标上表现突出,说明通过深度卷积网络获得的一元和成对特征远优于文献[6]中通过手工提取的特征。文献[11]没有考虑邻域关系,这使得它们表现弱于将CNNs与PGM结合的方法(文献[16,19,27]和本文的DCRFN)。在基于PGM的方法中,本文提出的方法优于其他3种方法,这主要由于本文针对红外图像的特点分别设计了两个深度特征模型,而文献[16,19,27]的成对特征来自简单的预设先验。图6列出了红外测试集中任意4个不同场景下的定性评估预测结果。可以看出,针对可见光设计的特征只能粗略的估计出红外场景的总体深度信息,缺乏了细节特征,如第一列树木的轮廓、第二列较深处的景物、第三列路上的行人等;而本文由于存在针对红外场景设计的深度特征网络,因此可以获得更加丰富的细节信息。
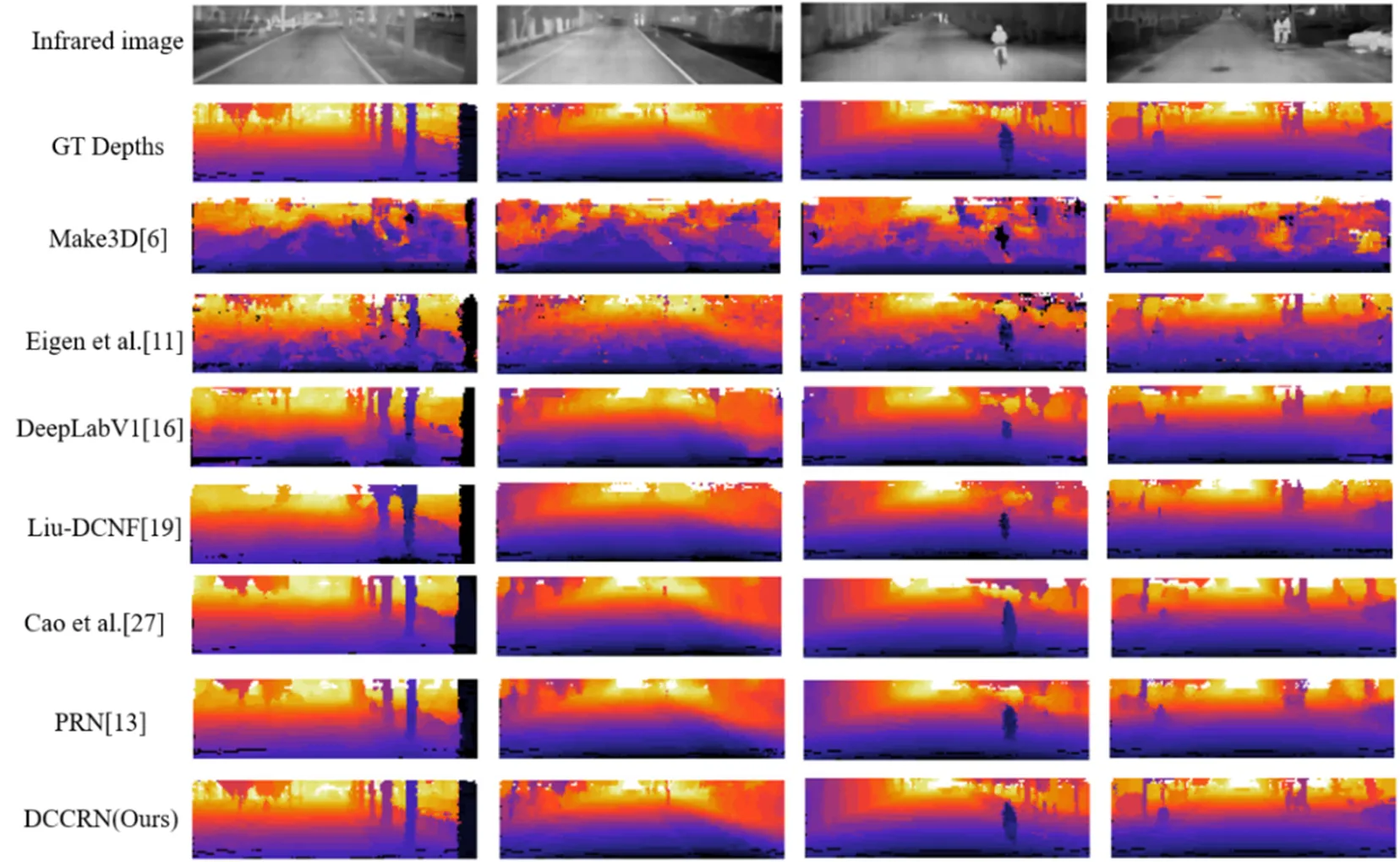
图6 NUSTMS数据集下预测深度图实例
最后,本文分析证明了成对项模型于整个模型的重要性。如图7所示,本文分别输出了仅一元模型,仅成对模型和总体输出结果的对比。通过定义一元项和成对项来模拟标签的联合分布,可以看出,仅由一元模型虽可以估计出的整体的深度图,添加了成对模型的约束后,使得预测结果更加平滑。与真实深度图相比,通过本文提出的DCRFN预测的深度图获得了更加良好的视觉体验。图8在指标rms和正确率上定量验证了上述说明。
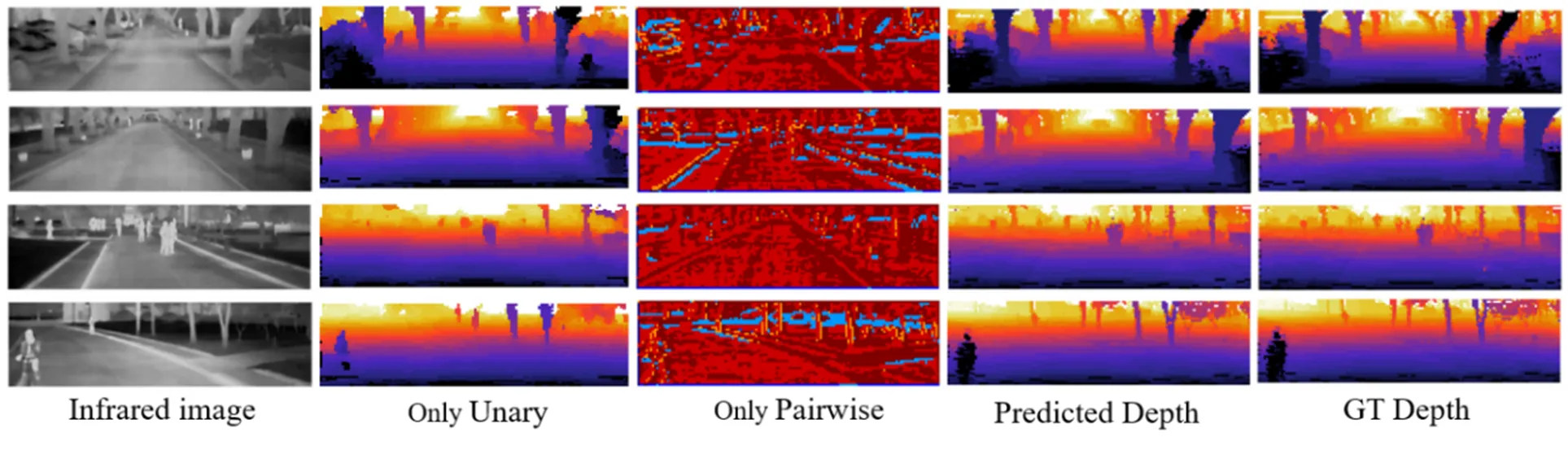
图7 DCRFN分解对比结果
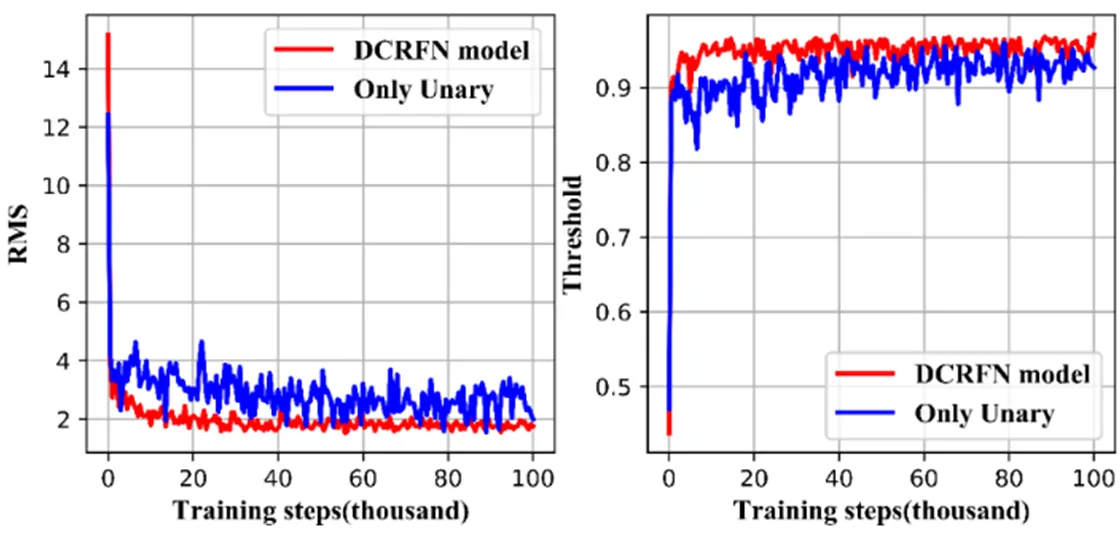
图8 训练过程中DCRFN分解表现对比
5 结论
本文提出一种新颖的DCRFN模型来估计单目红外图像的深度信息,这有助于推进夜间视觉产品的应用。现有的红外图像深度估计方法虽基于CNNs,由于忽略了优化结构损失,造成预测深度图模糊甚至错误。本文在充分考虑红外图像特点的条件下,将CNNs与CRF的优势结合在模型中,二者的联合优化提升了模型的泛化能力。值得注意的是,DCRFN模型无需预先定义成对特征,可以实现全自主学习。同时深度的离散策略,使得有序约束能够融合到DCRFN损失函数中,从而获得更好的景物边缘预测。除此之外,DCRFN不仅建立了原始红外图像和深度图之间的关系,而且还构造了场景不同尺度深度序列之间的关系。最后,实验评估指标证明了本文方法的可行性与准确性。
在未来的研究工作中,将考虑采用精简模型降低网络的参数规模,以便模型能在夜间自动驾驶领域实际应用。除此之外,考虑将红外场景深度估计任务用于如合成任务、目标追踪等夜视应用,从而辅助智能产品的夜间决策。
[1] Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C]//, 2016: 3213-3223
[2] PENG X, SUN B, Ali K, et al. Learning deep object detectors from 3D models[C]//, 2015: 1278-1286.
[3] Biswas J, Velos oM. Depth camera based indoor mobile robot localization and navigation[C]//, 2011: 1697-1702.
[4] Sivaraman S, Trivedi M M. Combining monocular and stereo-vision for real-time vehicle ranging and tracking on multilane highways[C]//, 2011: 1249-1254.
[5] Hedau V, Hoiem D, Forsyth D. Thinking inside the box: using appearance models and context based on room geometry[C]//, 2010: 224-237.
[6] Saxena A, SUN M, Ng A Y. Make3D: learning 3D scene structure from a single still image[J]., 2009, 31(5): 824-840.
[7] LIU B, Gould S, Koller D. Single image depth estimation from predicted semantic labels[C]//, 2010: 1253-1260.
[8] Russell B C, Torralba A. Building a database of 3D scenes from user annotations[C]//, 2009: 2711-2718.
[9] LIU M, Salzmann M, HE X. Discrete-continuous depth estimation from a single image[C]//, 2014: 716-723.
[10] Karsch K, LIU C, KANG S B. Depth extraction from video using non-parametric sampling[C]//, 2012: 775-788.
[11] Eigen D, Puhrsch C, Fergus R. Depth map prediction from a single image using a multi-scale deep network[C]//, 2014: 2366-2374.
[12] Laina I, Rupprecht C, Belagiannis V, et al. Deeper depth prediction with fully convolutional residual networks[J].3, 2016: 239-248.
[13] 顾婷婷, 赵海涛, 孙韶媛. 基于金字塔型残差神经网络的红外图像深度估计[J]. 红外技术, 2018, 40(5): 21-27.
GU T T, ZHAO H T, SUN S Y. Depth estimation of infrared image based on pyramid residual neural networks[J]., 2018, 40(5): 21-27.
[14] WU S C, ZHAO H T, SUN S Y. Depth estimation from infrared video using local-feature-flow neural network[J/OL]., 2018: doi.org/10.1007/s13042-018-0891-9.
[15] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//, 2016: 770-778.
[16] CHEN L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]., 2015(4): 357-361.
[17] Krähenbühl P, Koltun V. Efficient inference in fully connected CRFs with Gaussian edge potentials[J]., 2012(24): 109-117.
[18] LI N B, SHEN N C, DAI N Y, et al. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs[C]//, 2015: 1119-1127.
[19] LIU F, SHEN C, LIN G. Deep convolutional neural fields for depth estimation from a single image[C]//, 2015: 5162-5170.
[20] LIU F, SHEN C, LIN G, et al. Learning depth from single monocular images using deep convolutional neural fields[C]//, 2015: 5162-5170.
[21] XU D, WANG W, TANG H, et al. Structured attention guided convolutional neural fields for monocular depth estimation[C]//, 2018: 3917-3925.
[22] Ibarra-Castanedo C, González D, Klein M, et al. Infrared image processing and data analysis[J]., 2004, 46(1-2): 75-83.
[23] 张蓓蕾, 孙韶媛, 武江伟. 基于DRF-MAP模型的单目图像深度估计的改进算法[J]. 红外技术, 2009, 31(12): 712-715.
ZHANG B L, SUN S Y, WU J W. Depth estimation from monocular images based on DRF-MAP model[J]., 2009, 31(12): 712-715.
[24] 席林, 孙韶媛, 李琳娜. 基于SVM模型的单目红外图像深度估计[J]. 激光与红外, 2012, 42(11): 1311-1315.
XI L, SUN S Y, LI L N. Depth estimation from monocular infrared images based on SVM model[J].,2012, 42(11): 1311-1315.
[25] HUANG G, LIU Z, Laurens V D M, et al. Densely connected convolutional networks[C]//, 2017: arXiv:1608.06993.
[26] Noh H, HONG S, HAN B. Learning deconvolution network for semantic segmentation[C]//, 2015: 1520-1528.
[27] CAO Y, WU Z, SHEN C. Estimating depth from monocular images as classification using deep fully convolutional residual networks[J]., 2017(99): 1-1.
[28] FU H, GONG M,WANG C, et al. Deep ordinal regression network for monocular depth estimation[C]//, 2018: 2002-2011.
Depth Estimation of Monocular Infrared Scene Based on Deep CRF Network
WANG Qianqian,ZHAO Haitao
(School of Information Science and Engineering, East China University of Science and Technology, Shanghai 200237, China)
Depth estimation from monocular infrared images is required for understanding 3D scenes; moreover, it could be used to develop and promote night-vision applications. Owing to the shortcomings of infrared images, such as a lack of colors, poor textures, and unclear outlines, a novel deep conditional random field network (DCRFN) is proposed for estimating depth from infrared images. First, in contrast with the traditional CRF(conditional random field) model, DCRFN does not need to preset pairwise features. It can extract and optimize pairwise features through a shallow network architecture. Second, conventional monocular-image-based depth regression is replaced with multi-class classification, wherein the loss function considers information regarding the order of various labels. This conversion not only accelerates the convergence speed of the network but also yields a better solution. Finally, in the loss function layer of the DCRFN, pairwise terms of different spatial scales are computed; this makes the scene contour information in the depth map more abundant than that in the case of the scale-free model. The experimental results show that the proposed method outperforms other depth estimation methods with regard to the prediction of local scene changes.
infrared image, depth estimation, conditional random field, ordered constraint
TP391.9
A
1001-8891(2020)06-0580-09
2019-05-29;
2019-07-12.
王倩倩(1993-),女,硕士研究生,主要从事计算机视觉方面的研究。
赵海涛(1974-),男,博士,教授,主要从事模式识别、计算机视觉方面的研究。E-mail:haitaozhao@ecust.edu.cn。
国家自然科学基金(61375007);上海市科委基础研究项目(15JC1400600)。
