基于聚类的分层降维框架
2020-06-30陈新元谢晟祎
陈新元,谢晟祎
计算机科学与自动化技术
基于聚类的分层降维框架
陈新元1,2,谢晟祎3
(1. 闽江学院 计算机与控制工程学院,福建 福州 350121;2. 福州墨尔本理工职业学院 信息工程系,福建 福州 350121;3. 福建农业职业技术学院 实验实训中心,福建 福州 350181)
在分析、验证主流降维算法性能的基础上,设计了基于聚类的分层降维框架,将聚类和降维结合,实现了类内和类间分别降维的处理机制。实验结果表明,随着数据集规模增长,分层降维框架的时间效率逐渐体现出优势。
高维数据;降维;聚类;分层;分类准确率
1 引言
近年来,随着我国经济的高速发展,行业数据采集、存储和统计分析等方面的需求日益增长。在计算机和物联网等产业的技术支撑下,数据量激增,从大规模数据中提取有效信息并辅助生产,对行业发展具有重大意义。
行业大数据具有维数巨大,复杂度较高等特点,导致识别和处理难度提高;高维数据和稀疏矩阵给计算能力带来了新的挑战。为快速提取信息,人们常根据人工经验和先验信息对维度特征进行筛选,或使用降维算法在尽可能保留数据结构的前提下将数据从高维空间映射至低维,从而降低计算复杂度。
降维算法可依不同标准分为线性和非线性算法,如PCA和KPCA;全局和局部算法,MDS和LLE;监督、无监督和半监督算法,如LDA(监督)和k-means(无监督)等。闫德勤等[1]针对局部线性嵌入算法的局限性,通过统计信息确定稀疏数据的局部可线性化范围,改善高维数据的降维表现;赵孝礼等[2]则将KPCA与正交化局部敏感判别分析方法(OLSDA)结合,先使用KPCA消除冗余属性,保留全局非线性结构,再使用OLSDA挖掘局部的流行结构以避免降维失真,最后通过近邻分类器的识别率和聚类间距验证算法;唐科威等[3]将洛伦兹投影判别法推广到张量空间中,利用二阶张量形式的灰度矩阵进行图像降维以保留局部结构;刘胜蓝等[4]通过改进的协方差阵更新方式解决噪音造成的子空间偏离问题;李海林等[5]使用正交多项式回归模型对时间序列进行特征提取,运用奇异值分解实现特征降维;Lotlikar R等[6]在LDA算法的基础上进行局部切割,通过增量计算流程提高每个子空间内权值计算的准确率;Jun Shi等[7]同样将递归分治结构应用于基于瑞丽熵结构的KECA算法;Miguel Simão等[8]将双三次插值算法与PCA结合,通过重采样及降维提高不完整动态手势的识别率;Fan M等[9]则引入流形回归框架,通过复杂度和平滑度指标衡量降维表现,同时设计了基于流形回归和最小二乘法的MR-KLS算法以进行特征映射和降维。
降维标准的选择也是热门方向。鉴于许多高维数据映射至2-3维(用于可视化)时压缩率过大,数据结构丢失,聚类/分类等指标常被用于判断降维效果。聚类常被用于目标群体划分或样本筛选,如曾蔚等[11]实现基于品牌忠诚度的用户分类;王森等[12]使用聚类筛除离群的专家权重样本;詹胜等[13]应用不同的距离标准取得精确的连铸胚定重数据等。在降维相关研究中,Ding Chris等[10]将LDA和k-means算法结合,在特征选择的基础上进行聚类,并将聚类表现作为该方案的性能度量;Antoniadis A等[13]将降维与非参数判别结合,通过分类性能进行验证;Laohakiat S等[14]将降维融入聚类框架,通过LDA降维寻找子空间,最后验证了方案在提高聚类性能的同时缩短了处理时间。鉴于聚类与降维,特别是K-means与PCA存在密切的内在联系,且降维往往是为了进一步聚类或分类,本文尝试将两者结合。
许多研究侧重于降维准确率的改进,但对于大规模的行业数据,改进算法往往意味着更高的计算复杂度。本文目标是在不增加复杂度的前提下,提高降维处理效率,因此分析、比较了多种基础降维算法、聚类算法,并在此基础上设计并实现了分层降维框架,结合降维算法和聚类算法,先对高维数据进行聚类,根据维度间相似度进行分类,在类内降维、降低冗余的基础上对合并的类间数据进行二次降维,从而减小计算复杂度,提高降维效率,实验阶段验证了降维对分类准确率的影响。
2 分层降维框架
系统框架图如图1所示,使用k-means、层次聚类、SOM神经网络等算法实现数据聚类,并将聚类结果应用于分层降维框架,使用PCA、LDA等算法分别实现类内降维和类间降维,使用SVM进行方案验证。

图1 系统框架图
2.1 降维算法
2.1.1 线性降维算法
PCA:通过max方差或min误差的思路构建高维数据至低维数据的转换矩阵以尽可能保留有效信息。其主要过程包括:对矩阵进行中心化,以表示,计算T,分解矩阵并排序特征向量,将最大的个特征值构成的向量作为高维和低维的关联矩阵,输出=*。
LDA:监督降维算法,根据样本数据分类标签计算类别样本均值和所有样本均值,计算得到类间散度矩阵和类内散度矩阵,以此计算表示空间距离条件的投影矩阵,使同类数据的距离较小,异类数据的间距较大,最后输出=T。
2.1.2 非线性降维算法
KPCA:将PCA算法扩展到非线性空间,主要过程如下:寻找合适的核函数,代入数据后计算核矩阵并进行标准化处理,最后分解特征值并排序输出最大值对应的向量。算法将数据映射到高维空间,实现数据的线性可分。
LLE:局部算法,假定样本数据与其近邻满足带权线性关系,计算中在邻域判定的基础上保证近邻点位置在空间转换的过程中保持稳定,进而保留整体数据结构。其过程如图1所示。
利用k-means等算法求近邻,构建权值矩阵,计算中间矩阵并进行特征分解,选择最小的d个特征值输出。
MDS:全局降维算法,基于流形学习,假定所有样本在低维空间都有对应的流形结构,构造局部结构并拓展到全局结构完成映射。算法思路是将样本点从高维转换至低维后,保持原有距离,因此需要计算高维数据的距离矩阵(基于欧式距离)并根据中间参数进行转换,最后将距离矩阵进行谱分解,选择特征值最大的d个向量构成对角矩阵并处理输出。
ISOMAP:可视为MDS的改进版本,算法执行中先判定邻域,对于邻域外的样本,使用测地距离替换欧式距离以保留流形结构,得到距离矩阵后采用MDS算法得到输出。
SNE:该算法引入了条件概率以判断相似度,概率值接近时表示降维前后样本关系基本得以保存,过程中使用梯度下降算法最小化损失函数。通过设定方差,算法对于局部最小值陷阱有一定的规避能力。
t-SNE:SNE的改进算法,但计算复杂度较高。该算法使用联合概率取代条件概率,同时用柯西分布代替高斯分布以解决异类数据重叠的问题。
鉴于传统降维算法存在矩阵稀疏难以分解、存储计算资源开销大、数据映射过程难以监控等问题,因此本文希望结合聚类算法降低降维的复杂度。
2.2 聚类算法
2.2.1 层次聚类
该算法将维度定义为类别,每维度为一类,将距离最小的两个类合并为一类,多次循环直到类别数满足预设值;其关键在于距离公式的定义,可分为最小距离、最大距离和平均距离等。
2.2.2 k-means聚类
迭代算法,初始时随机选取k个样本作为聚类中心,将维度相似的数据分为同一类别,通过多次迭代不断更新聚类中心,直到收敛。
2.2.3 SOM神经网络
无监督聚类方法,无需输入参数,训练后由输出层计算聚类数。SOM的结构中,输入层神经元个数与维度或样本数相关,最大为属性数。算法结果受到输入数据顺序的影响。其主要过程为:先进行数据归一化处理,将距离输入最近的输出层神经元选为优胜,更新其权值和学习率,直到预设条件满足位置。
3 实验与结果分析
本文将分类性能作为标准验证降维算法的有效性,使用SVM作为分类算法。采用Matlab的Heart Scale与UCI的VOTE、GERMAN数据集,尺寸分别为270*13,453*16和1 000*24,均携带标签。实验中采用了分层降维框架,在聚类的基础上先进行第1次类内降维,降维后合并数据,维度增加,再进行第2次类间降维。降维方法包括:PCA、LDA、KPCA、MDS、ISOMAP、SNE和t-SNE;聚类方法包括k-means和层次聚类。LLE算法的分类准确率偏低,故实验中舍弃。方案性能取10折验证的平均结果。
表1为Heart Scale数据集上的分类结果,可见LDA与聚类结合的方案相比原有降维方案,准确率有明显提高;对SNE和t-SNE算法而言,由于部分维度在聚类过程中合并丢弃,精度略有降低。在Heart Scale这一数据间线性关系明显的数据集上,k-means+PCA的分类准确率最高。
表2为VOTE数据集分类结果,由于数据存在流形结构,部分非线性降维算法在结合聚类方法后准确率一定提高,如SNE和t-SNE。同时可观察到,聚类算法,以及分层降维的操作对降维用时的影响相比表1有所降低。在VOTE数据集上,层次聚类+KPCA的表现较好。
表3为GERMAN数据集分类结果,可以看到几种方案的分类准确率相比单独的降维算法都有一定的提高,且分层降维的用时影响进一步减小,部分方案的时间甚至少于原始降维方案;可以初步判断,若未来数据集进一步增长,分层降维框架有助于减少降维的总时间开销。在GERMAN数据集上,层次聚类+ISOMAP取得了最高的分类准确率。

表1 Heart Scale数据集分类结果
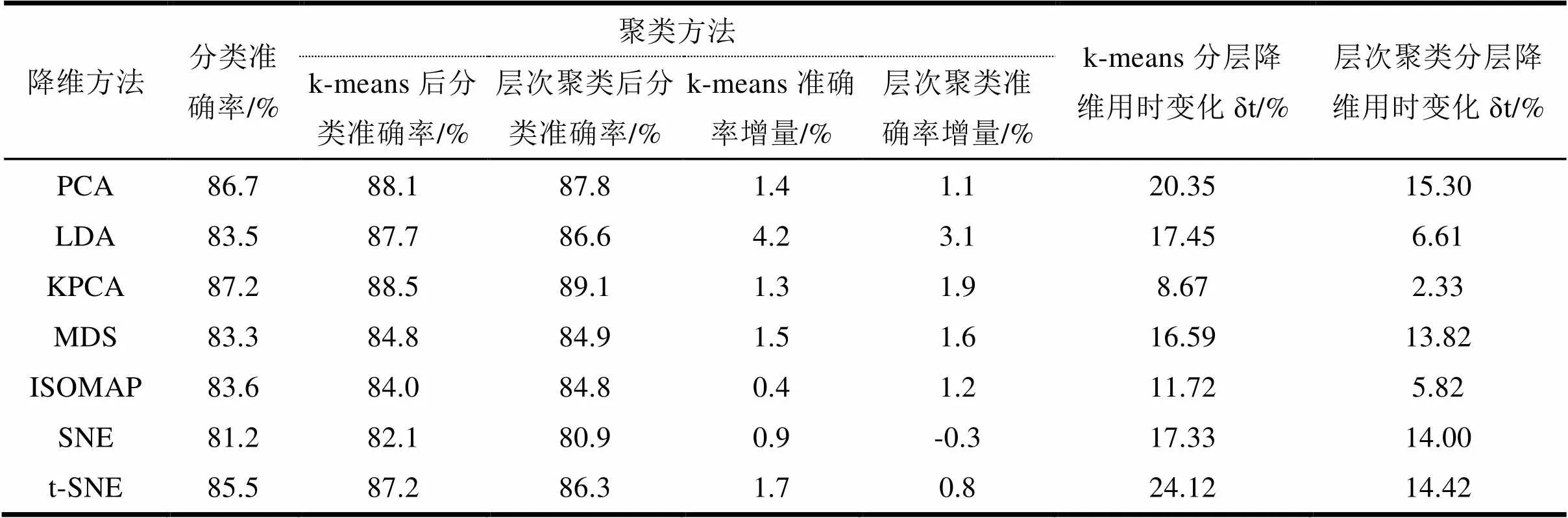
表2 VOTE数据集分类结果

表3 GERMAN数据集分类结果
此外,本文使用自组织映射神经网络对聚类参数进行预估,用于后续的k-means和层次聚类,用以解决传统聚类参数无法自适应的问题;但实验结果表明,算法稳定性略微提高,但处理效率大大下降,不符合本文初衷,故放弃此方案。
4 结论
降维算法是解决维数灾难的关键,可分为线性和非线性降维。本文分析并验证了主流降维算法的性能,通过分类准确率验证数据结构在降维中的保留程度。提出了基于聚类的分层降维框架,结合聚类和降维算法,分层实现类内降维和类间降维。实验结果表明,当数据集规模较大时,尽管聚类算法会带来额外的时间开销,分层降维框架的总用时仍然接近或低于未采用聚类时的降维用时。
未来的研究方向包括:(1)数据集规模进一步增加时,或流形结构复杂度提高时该框架的适用性;(2)如何改善聚类算法参数的稳定性;(3)可考虑针对行业不断增加的数据规模设计增量处理机制。
[1] 闫德勤,刘胜蓝,李燕燕.一种基于稀疏嵌入分析的降维方法[J].自动化学报,2011,37(11):1306-1312.
[2] 赵孝礼,赵荣珍.全局与局部判别信息融合的转子故障数据集降维方法研究[J].自动化学报,2017,43(4):560- 567.
[3] 唐科威,刘日升,杜慧,等.一种基于张量和洛仑兹几何的降维方法[J].自动化学报,2011,37(9):1151-1156.
[4] 刘胜蓝,闫德勤.一种新的全局嵌入降维算法[J].自动化学报,2011,37(7):828-835.
[5] 李海林,杨丽彬.时间序列数据降维和特征表示方法[J].控制与决策,2013,28(11):1718-1722.
[6] Lotlikar R, Kothari R. Fractional-step dimensionality reduction[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 22(6): 623-627.
[7] Shi J, Jiang Q, Zhang Q, et al. Sparse kernel entropy component analysis for dimensionality reduction of biomedical data[J]. Conf Proc IEEE Eng Med Biol Soc, 2015, 168(C): 930-940.
[8] Simã O M, Neto P, Gibaru O. Using data dimensionality reduction for recognition of incomplete dynamic gestures[J]. Pattern Recognition Letters, 2017, 11(25): 32-38.
[9] Fan, Mingyu, Gu, Nannan, Qiao, et al. Dimensionality reduction: An interpretation from manifold regularization perspective[J]. Information Sciences, 2014, 277(8): 694-714.
[10] Ding C, Berkeley L, Li T. Adaptive Dimension Reduct- ion Using Discriminant Analysis and K -means Clustering[A]. ACM. Poceedings of the 24th Inter- national Conference on Machine Learning[C]. Corvallis, OR: ACM, 2007: 522-528.
[11] 曾蔚.基于用户行为聚类的个性化推荐算法研究[J].唐山师范学院学报,2016,38(5):81-84.
[12] 王森,魏旭颖.网络社会场系统的安全评估中专家权重样本的处理方法[J].唐山师范学院学报,2017,39(2): 11-14,27.
[13] 詹胜,周树功,母景琴.聚类分析方法在基于分布式PLC数据采集的连铸坯定尺定重切割中的应用[J].唐山师范学院学报,2013,35(5):33-36.
[14] Antoniadis A, Lambert-Lacroix S, Leblanc F. Effective dimension reduction methods for tumor classification using gene expression data[J]. Bioinformatics, 2015, 4(18): 21-29.
[15] Laohakiat S, Phimoltares S, Lursinsap C. A clustering algorithm for stream data with LDA-based unsuper- vised localized dimension reduction[J]. Information Sciences, 2017, 381(3): 104-123.
Hierarchical Dimension Reduction FrameworkBased on Clustering
CHEN Xin-yuan1,2, XIE Sheng-yi3
(1. College of Computer and Control Engineering, Minjiang University, Fuzhou 350121, China; 2. Department of Information Engineering, Fuzhou Melbourne Polytechnic, Fuzhou 350121, China; 3. Experimental Training Center, Fujian Vocational College of Agriculture, Fuzhou 350181, China)
By analyzing and verifying the performance of mainstream dimension reduction algorithms, a hierarchical dimension reduction framework based on clustering algorithms was proposed, which combined clustering and dimensionality reduction to realize the processing mechanism of dimensionality reduction within and between classes respectively. Experimental results of time efficiency show that this framework bears some advantages over the original dimension reduction scheme as data volume increases.
multiple dimensional data; dimension reduction; clustering; stratification; classification accuracy
TP18
A
1009-9115(2020)03-0078-05
10.3969/j.issn.1009-9115.2020.03.019
福建省中青年教师教育科研项目(JAT160316)
2020-01-03
2020-04-04
陈新元(1984-),男,福建福州人,硕士,讲师,研究方向为机器学习、知识图谱。
(责任编辑、校对:田敬军)
