基于Greenplum的城轨信号系统车载日志大数据分析平台
2020-06-30魏盛昕张奕男
谢 飞,魏盛昕,张奕男
(1.卡斯柯信号(成都)有限公司,成都 610083;2.卡斯柯信号有限公司,上海 200071)
随着我国城市轨道交通迅猛发展,信号系统的运营维护也朝着自动化、可视化和智能化方面发展,其获取的数据量呈现指数级增长且规模日益庞大,如何处理这些海量数据并挖掘其价值已成为业内的一个难题[1]。国内各地铁公司都在探索如何应用大数据技术解决在实际运维过程中的问题,例如:杜时勇[2]提出了利用大数据搭建信号系统线网智能运维平台,杨文轩[3]提出了基于Hadoop 平台构建城轨信号系统健康维护平台,但是,目前主要依赖信号系统定制化的监测系统实现数据存储与分析,很少直接去分析车载日志,因此,无法对关键信息进行深度挖掘,不利于系统安全保障能力的提升。本文旨在构建一种能够对海量的信号系统车载日志T+1 离线分析的大数据平台,实现对车载日志的统计分析和高效管理,以便为地铁公司的日常运维与保障工作提供更好的决策支撑。
1 车载日志大数据分析平台需求
1.1 城轨信号系统车载日志特点
(1)缺乏日志数据的集中管理
在城市轨道交通建设过程中,不同线路采用不同厂家的信号系统,存在标准不统一,各线路之间多为隔离状态,日志数据分散在各个数据孤岛中,不同线路之间无法进行数据的交互和统一管理。
(2)日志分析手段落后
当信号系统车载设备或模块发生故障时,地铁公司需要上车拷贝日志,然后通过日志工具对车载日志文件逐个分析,存在效率低下、过程繁琐等问题。
(3)传统数据库架构无法满足需求
据估算,1 条拥有40 列车的线路每天将会产生近1 亿条原始数据,1 年下来将累积达到近300 亿条的数据规模。在传统数据库架构下,受单机性能的限制,要处理如此大的数据量,已经无法满足用户快速、及时的查询需求。
1.2 车载日志大数据分析平台需求
(1)平台架构需考虑支持多线路车载日志数据的分析,打破不同线路信号系统之间的数据壁垒。
(2)平台架构需考虑支持通过无线网络下载车载日志,并自动完成车载日志数据的解析与存储。
(3)平台架构需考虑满足数据大容量、高可用和高扩展性的需求[4]。
(4)平台架构需考虑地铁公司实际运维的特点,保证数据的处理能够在规定时间范围内完成。
(5)平台规模与造价需要控制在合理范围内[5]。
2 基于Greenplum的车载日志大数据分析平台设计
2.1 Greenplum介绍
Greenplum 是基于PostgreSQL 开发的数据库集群,每个单独的节点都是一个PostgreSQL 数据库,其采用的是Shared-Nothing 架构[6],每一个节点的CPU、内存等资源都是独立的,每个节点都有全部数据的其中一部分。在用户体验方面,Greenplum 与传统数据库类似,但在任务处理上却有本质的区别[7],它能将任务分配给多个节点服务器主机,实现对分布式事务的高效管理,在金融、保险、证券、通信、航空等领域都有着广泛的运用。
本文选择Greenplum 搭建车载日志大数据分析平台,主要还考虑到其拥有的一些独特优势:
(1)开源项目,其造价低,部署灵活且不受限于硬件环境和平台,允许客户能根据自身需求选择最适合的方案,从而降低未来的迁移代价。
(2)关系型数据库,虽然每天产生的车载日志数据量大,但数据本身是结构化数据,开发与运维人员不需要学习很多新的数据库处理技术,能够降低人力成本。
(3)支持处理和分析多种数据源,包括 Kafka、Hadoop、HIVE、HBase、S3、Gemfire 及各种关系型数据库和文件等,便于后续平台的扩展改造。
2.2 平台架构设计
为了满足地铁信号系统中海量车载日志的分析需求,基于Greenplum 的车载日志大数据分析平台主要由数据源层、数据采集层、数据存储层、数据分析层、应用展示层构成,其平台架构,如图1 所示。
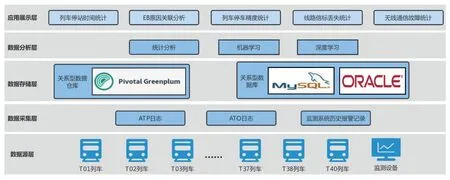
图1 基于Greenplum的车载日志大数据分析平台架构
2.2.1 数据源层
数据源层主要由车载数据日志单元(DLU)板卡、线路服务器、线网服务器及综合监测系统构成。DLU 板卡完成对列车所有行车日志的存储,经由车- 地无线通道把日志文件传送到线路服务器,线路服务器将本地的车载日志文件经由FTP 软件再同步至线网服务器上。另外,地铁综合监测系统存储着列车在线路上运行过程中的综合告警记录。
2.2.2 数据采集层
数据采集层主要负责对车载日志数据的采集、解析以及入库,其中,车载日志分为ATP 和ATO2种日志。数据采集主要分为2 部分:(1)通过FTP方式下载车载日志文件;(2)从Oracle 数据库同步综合监测系统的告警记录。大数据平台通过FTP 方式从线网服务器中下载车载日志文件,并对完整的日志文件按照数据协议进行解析。解析后的日志数据将推送给基于kafka+Zookeeper 的消息中间件,最终这些消息流数据将被Greenplum Stream Server(GPSS)消费,完成到大数据平台的入库操作,具体处理流程,如图2 所示。
2.2.3 数据存储层
数据存储层负责对采集处理后的日志数据和告警记录进行存储。大数据平台采用Greenplum 对日志数据进行存储管理,采用MySQL 对车载日志文件进行FTP 下载记录管理,采用Oracle 对综合监测系统的告警记录进行管理。
2.2.4 数据分析层
数据分析层负责对大数据平台存储的日志数据和告警数据进行统计和分析,同时结合各业务主体需求整理出用于运维决策和应用端展示所需要的统计数据。大数据平台在数据积累的基础上,可以应用目前机械学习领域中相对成熟的算法挖掘出车载日志中关键设备或系统模块的失效原因和故障趋势。
2.2.5 应用展示层
本研究以生态语言学理论、建构主义理论、ESP理论等为理论依据,采用调查、文献、比较等研究方法,并遵循以下思路开展研究。先调研分析高职公共英语教学现状及其所存弊端,提出其改革需融入EOP的必要性;再分析融入EOP后原高职公共英语教学生态失衡产生的失调现象及不良影响,论证重构融入EOP的教学生态的可行性;然后明晰改革思路,开发EOP教学资源,开展考核学生英语应用能力的多元评价,加强EOP师资建设,实现高职公共英语教学生态再平衡;最后总结研究成果,并在其他高职推广。具体研究如下三大内容。
应用展示层负责把数据分析层整理出的结果数据,通过PC 端和大屏端向地铁用户进行展示和应用,主要包括列车停站时间、停车精度、紧急制动(EB)、信标丢失事件以及无线通信故障事件的统计与分析结果的展示。

图2 数据采集层处理流程
2.3 系统功能设计
基于Greenplum 的车载日志大数据分析平台以车载日志和综合告警记录中的特定事件(主要涉及停站、EB、信标丢失以及无线通信中断等)进行统计分析,其主要功能包括列车停站时间分析、列车停车精度分析、EB 事件统计、信标丢失统计和无线通信交叉故障统计。
2.3.1 列车停站时间统计分析
通过ATO 日志对列车停站事件的关键参数进行分析,计算出列车停站过程中的关键指标,主要包括列车停站总时长、乘客有效上下客时间、司机开门响应时间、司机关门响应时间、司机按发车按钮响应时间和乘客上下客效率等。根据列车停站记录,按照列车、车站等维度按日分别统计出列车和车站的停站超标结果,包括超标次数和超标时长。
2.3.2 列车停车精度统计
通过ATO 日志计算出列车每次停车事件发生时的驾驶模式、停站状态(包括正常停、欠停、过停)及停站位置偏差,同时按照列车、车站等维度按日生成列车欠停、过停次数的统计报表,并提供信息查询。
2.3.3 EB事件统计
2.3.4 信标丢失统计
根据列车信标丢失的标记位的变化规律,从ATO 日志中获取发生信标丢失事件的信标ID、开始时间、结束时间以及丢失位置。按照列车、车站、区段等维度,按日生成信标丢失发生次数的统计报表,同时绘制线路信标丢失趋势图。当某个信标丢失事件次数异常时,能及时提醒用户进行维护。
2.3.5 无线通信故障统计
结合车载日志和监测系统的告警数据,计算出列车每次车载发生无线通信故障时的中断时间、恢复时间、发生位置及车载故障Modem名称。按照列车、车站等维度按日统计出无线通信中断的故障统计次数并生成报表,绘制出无线通信故障趋势图,能够及时向用户发出告警,并提示用户及时处理故障。
3 基于Greenplum的大数据平台实现
3.1 大数据平台构建
为了满足车载日志的数据存储、数据分析以及数据查询的性能要求,并充分考虑到大数据平台的建设成本,平台建设时主要采用了Greenplum、Kafka、Zookeeper 及MySQL 等开源组件,形成一套可按需部署、开源软件为主的大数据平台。
基于Greenplum 的大数据平台主要由1 个管理节点和3 个数据节点组成,每个节点配置为2颗8 核 的Intel 64 bit 处理 器、32 GB 内 存及3 块600 GB SAS 硬盘,每个节点间使用千兆网络连接,Greenplum 版本为5.19,其拓扑结构,如图3 所示。每个数据节点上部署2 个主实例和2 个镜像实例,各数据节点之间进行交叉镜像配置,提高了集群的可用性[6]。在部署实际的生产环境时,根据实际需求可以增加两台服务器,一台作为大数据应用展示的Web 应用服务器,另一台作为存储车载日志文件的数据日志服务器。

图3 基于Greenplum的大数据平台拓扑结构
在完成大数据平台部署后,通过数据采集/解析服务将线网服务器中的车载日志数据加载到平台中去。Greenplum 作为一个分布式数据库,数据分散在每一个节点上[8],而采用列车号作为源数据表的主键会造成数据倾斜问题。因此,该平台在数据分布策略上采用随机分布方式。
3.2 大数据平台关键性能指标评估
基于Greenplum 的大数据平台的建设目标是必须满足车载日志T+1 离线分析的要求,主要包括数据质量和分析速度两方面,数据质量必须满足报表展示的要求;分析速度要求必须满足地铁车辆运营的时间特点。车载日志离线分析的工作时间可以分为两个阶段,第1 阶段列车正常运营回库后到第2 天出车前,即每日晚上23:30—次日5:30,这个阶段内要完成从列车DLU 板卡到线网服务器的日志收集工作;第2 阶段是列车出库后到白班上班前,即次日5:30—次日9:00,这个阶段为大数据平台的工作时间,共计3.5 h,主要完成从线网服务器下载日志文件到统计报表生成。
大数据平台对6 列车1 天的车载日志数据(约540 个日志文件,共239 MB)从数据下载→解析→入库→清洗→查询的整个数据链路的关键性能进行了测试,具体测试结果分析如下。
(1)数据下载性能:由于大数据平台与线网服务器之间采用千兆局域网连接,平均网速约为30 MB/s,通过FTP 传输工具完成车载日志测试数据下载,实际耗时约20 s,因此日志下载环节的耗时可以忽略不计。
(2)数据解析性能:大数据平台跑单任务解析单个日志文件耗时大约35 s,即解析速度为170 条/s。为了缩短解析时间并充分利用平台的计算资源,可在平台上同时运行40 个解析任务去解析日志文件,最终完成车载日志测试数据的解析实际耗时约为0.8 h。
(3)数据入库性能:日志数据入库采用的是GPSS,其原理是通过外部表的方式实现数据高并发加载到Greenplum 数据库的ETL 工具。在大数据平台上通过GPSS 方式入库的实测速度约为2 500 条/s,完成车载日志测试数据解析入库实际耗时约为1.8 h。由于数据解析的同时会进行入库,因此数据入库总耗时包含了数据解析耗时。
(4)数据清洗性能:车载日志测试数据由原始日志表到中间日志表清洗耗时约为18 min,从中间日志表到统计结果表清洗耗时约为16 min。从原始日志表到统计结果表的清洗过程共耗时约为0.57 h。
(5)数据查询性能:对原始日志表、中间日志表和统计结果表中数据量最大的表分别执行相同操作的SQL 语句,记录执行时间,其测试结果,如表1 所示。从数据查询耗时的结果来看,数据查询阶段的耗时可以忽略不计。

表1 大数据平台数据查询结果
综上所述,车载日志从下载到报表生成的整个数据链路耗时等于数据入库时间加上数据清洗时间,总共耗时约为2.37 h,小于大数据平台实际要求的最大工作时长3.5 h。因此,本文所搭建的基于Greenplum 的大数据平台完全符合车载日志T+1 离线分析的要求。
4 结束语
基于Greenplum 的车载日志大数据分析平台具有良好的扩展性和实用性,在实际生产部署时,可以根据日志分析需求增加Segment 节点数和硬盘容量,并考虑采用万兆交换机和性能更高的处理器。该平台为解决城市轨道交通信号系统的车载日志分析提供了一种解决方案,弥补了目前城轨信号系统在运维管理方面的不足之处,是对今后城轨信号系统向智能化运维发展的一次应用探索。
