面向智能电网的关联规则挖掘算法的设计
2020-06-29尹蕊郭江涛王晓磊王天军潘建笠
尹蕊 郭江涛 王晓磊 王天军 潘建笠

摘 要:为有效满足智能电网的关联规则挖掘需求,在继承关联规则挖掘频繁树算法优势的基础上完成了 FP-network模型的构建,在一个无向网络图上对所需挖掘的信息进行压缩处理,在此基础上完成事务项目关联矩阵的构建,实现数据的存储和挖掘过程。详细介绍了在输电线路故障分析中该关联规则挖掘算法模型的应用流程,该挖掘算法只需扫描一次数据库,显著提高了关联规则挖掘的效率,该模型能够有效满足智能电网大数据间关联的挖掘需求。
关键词:智能电网;关联规则;挖掘算法;FP-network算法
Abstract:In order to effectively meet the needs of association rules mining in smart grids, this study completed the construction of the FP-network model by inheriting the advantages of association tree mining frequent tree algorithm, and compressed the information to be mined on an undirected network graph. On the basis of this, the paper completed the construction of the transaction item association matrix, realized the data storage and mining process. It also introduced in detail the application process of the association rule mining algorithm model in the transmission line fault analysis. The mining algorithm only needs to scan the database once. The efficiency of mining association rules is significantly improved, and the model can effectively meet the needs of mining big data associations in smart grids.
Key words:smart grid;association rules;mining algorithm;FP-network algorithm
0 引言
隨着自动化及智能化水平的持续提升,电力系统中的电力数据量不断增加,电网运行需基于更高的实时数据质量实现,进而对数据的处理和分析过程提出了更高的要求,尤其是不良数据的及时检测和辨识。目前应用处理不断增加的智能电网数据时仍面临着严峻的挑战,主要表现在数据可视化、存储及处理的实时性和效率、多源异构数据的有效融合等方面,为保障智能电网的安全稳定运行、充分发挥大数据的作用,本研究主要对面向智能电网的关联规则挖掘算法进行了设计。
1 现状分析
我国已相继完成了特高压和超高压输电线路的建设,电网规模及复杂程度不断增加,智能电网管理过程中的用电预测、设备故障诊断等问题均需基于电力相关数据的处理完成,传统的数据挖掘算法(包括分类、聚类、关联规则等)虽已取得了不错的效果,但随着各输电网区域间联系日益紧密以及实际应用的不断扩展,输电网线路信息随之增多,导致电力系统故障频繁发,电力系统故障呈现出复杂多样化特点,而电网故障的各属性间存在不同程度的关联性,传统的数据挖掘算法大多建立在充足的数据源基础上,对于较为稀疏分散的源领域数据会由于欠拟合问题的存在而难以有效满足实际工作对电网数据的挖掘需求。将关联规则挖掘算法运用于历史故障信息中,通过分类和研究故障数据获取潜在联系,在此基础上实现对故障的诊断和预测分析过程,以确保输电网的安全稳定运行[1]。
2 FP-network模型
Agrawal等提出的关联规则挖掘算法能够在大量历史数据中完成相关关联性的寻找(包括频繁项或属性间的关联),目前较为常用的关联规则挖掘方法为FP-Tree(频繁模式树)和Apriori算法,需寻找大量侯选项目集的Apriori算法在数据库较大的情况下易出现组合爆炸问题,并且需对数据库进行多次扫描。通过FP-Tree 产生频繁项集(J.Han提出)可弥补Apriori算法的不足,该算法在FP-Tree上压缩处理数据库(提供频繁项集),并始于初始后缀模式完成条件模式基的构造以及条件FP-Tree的形成,然后在该树上递归的进行挖掘,无需产生候选项,频繁模式通过递归访问 FP-Tree产生,仅需遍历2 次事务数据库,分别完成频繁 1-项集及FP-Tree的创建。FP-Tree算法较难实现,双向遍历数据库不利于数据库更新的处理,因需不断递归地生成“树”增加了挖掘过程的时空复杂度。为此本研究通过在FP-network上压缩所需数据(提供频繁项集)及其形成的关联矩阵实现计算机存储和挖掘过程,无需产生候选项及数据库重复扫描,更加适用于智能电网大数据的复杂规律的挖掘[1]。
2.1 FP-network模型的建立
电力系统的数据库主要体现在事务和项目间的关联,事务数据库如表1所示。
2.2 FP-network的矩阵形式的构建
为使上述网络图形式存在的问题得以有效解决,计算机存储采取了路径-节点(对应智能电网电力系统的事务和项目)关联矩阵的表示方式,具体由T=f(B,I)表示,假设,事务集合与项目集合分别由T和I表示,事务-项目关联矩阵由矩阵B表示(由bij代表的元素构成,其中i=1,2…,9、 j= 1,2,…,5),bij定义为:在事务i同项目j相关联的情况下bij取值为1,否则bij为0,以表1为依据建立如下关联矩阵[4]。
在生成关联矩阵过程中,由于智能电网大数据通常表现为项目数目远小于事务数目,矩阵的时间复杂度近似为事务数目,数据库存储受到存储和布尔矩阵B和I的转换显著节省了内存空间。
2.3 FP-network算法步骤
通过FP-network算法的使用使关联规则的挖掘过程得以有效简化,具体步骤为:首先给定由Smin表示的最小支持度阈值,然后对数据库进行扫描,在Smin大于fj的情况下将第j个节点信息删除,在此基础上完成矩阵B、I的构建;接下来找到非零的nk,并以第k个节点作为挖掘初始节点,矩阵B中仅保留 bik取值1的节点k的路径构成集合I(I={i|bik=1}),以点k前的节点信息作为保留内容,从而构成新的B、I矩阵;对于节点k在Smin小于nk的情况下,则将其作为频繁项集的一个元素,Smin大于等于nk则删去此节点信息,形成新的B、I矩阵,重新进行上述操作直至挖掘完全部 nk为非零的节点。以表1为依据取Smin=2,节点频数均超过2的I1-I5的所有节点信息均保留下来,以节点I3作为挖掘起始点,节点I3在矩阵B中对应第3列,第3、5、6、7、8、9行的元素均为1需保留,得到新的矩阵表达式如下[5]。
3 基于FP-network算法的智能电网大数据算例分析
本研究通过设置对比实验介绍基于FP-network算法的智能电网大数据挖掘过程,实验环境选用Windows 10操作系统、CPU为Intel(R)Core(TM),结合运用Anaconda平台和python开发语言,完成对FP-network、Apriori、FP-Tree三种算法的测试过程,传统以估计后的算法为主的不良数据检测方法的计算量较大,且易出现"残差淹没/污染"问题,为此需在估计前检测辨识出不良数据,具体以输电线路故障分析中关联规则挖掘的应用为例,并以某电力公司提供的输电线路故障信息作为实验数据,预处理2010—2017年的历史数据(包括除噪、清洗、过滤等)获取有效信息共1 276条,构成线路典型故障事务数据库,通过复制真实事务信息获取事务数据库(包含127 600条信息)以便更好的满足算法测试需求。由于其他属性本身就是离散变量,仅需离散处理数据库的“时间”属性,根据实际分析需要可不考虑年份信息,春季(3—5月)、夏季(6—8月)、秋季(9—11月)、冬季(12月至次年2月)分别由T1、T2、T3、T4表示,预处理后的结果如表2所示[6]。
在Smin=0.5%且实验环境相同的情况下,对在不同规模数据库下三种算法的运行速率进行测试,结果表明,如图1所示。
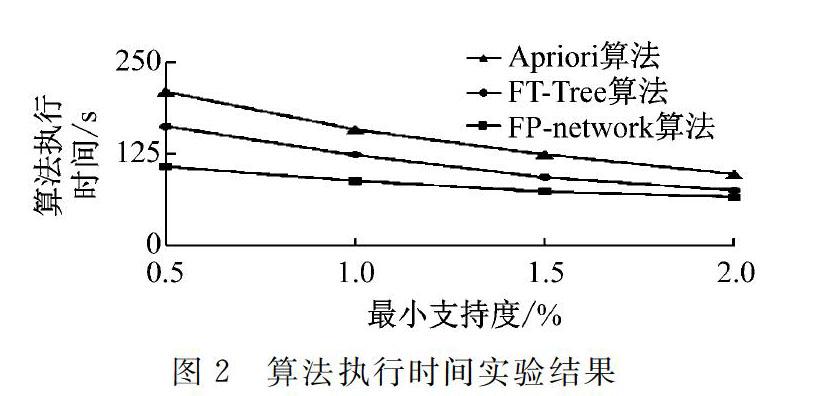
相比于其他2种算法本研究算法的运行速率最优,随着数据库规模的增大FP-network的优势更加明显。支持度的改变会改变频繁项集的规模(对事务数据库的规模不产生影响),在不同支持度下(包括最小支持度)采用数据库(包含127 600条信息)对算法性能及执行时间进行测试,如图2所示。
结果表明在不同支持度下相比于其他两种算法本研究算法的运行速率最优,3种算法的执行时间在调低最小支持度后均增加,但FP-network算法的运行速率变化幅度最小,能够较好地应对支持度的变化。证明了FP-network算法的性能优势,能够有效满足智能电网电力系统的大型数据库的实时性处理需求。
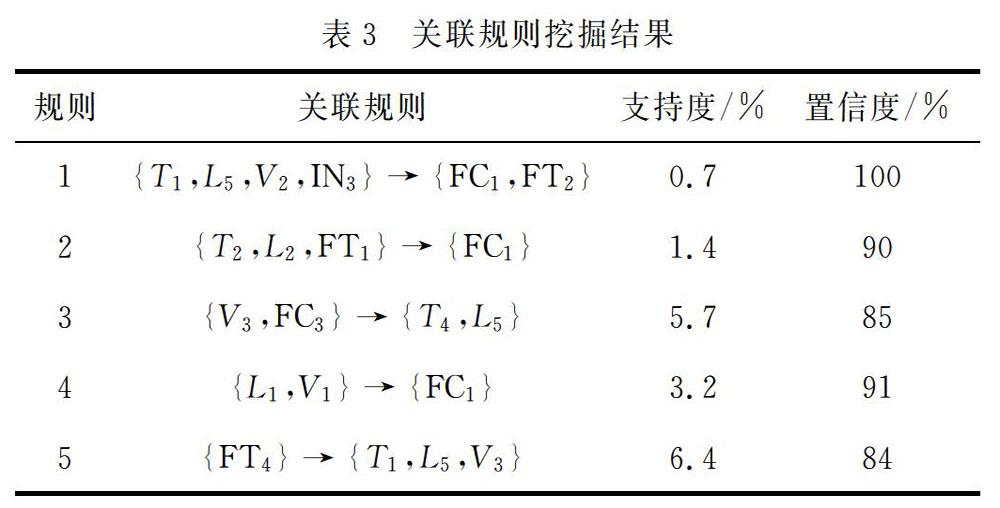
取Smin=0.5%分析故障信息数据库并获取全部的频繁项集,在此基础上对关联规则做进一步挖掘,所获取的上百条关联规则中并非全部都有价值,部分关联性极弱的规则没有实际的意义,通过使用计算规则置信度方法完成置信度超过75%的規则的筛选,部分结果如表3所示。
根据实际电力知识及获取的挖掘结果即可对智能电网中的线路故障情况进行分析,找到薄弱环节并据此提出改进措施和方案:对于规则1,在3—5月份(春季)该省中部地区220 kV线路出现了导线及地线舞动,需做好相关预防措施;对于规则2,在6—8月该省南部地区出现了较多的导线及地线故障,主要由因外力破坏导致,需采取措施杜绝违规施工;对于规则3,在12月至次年2月,该省中部地区的500 kV出现了主要有绝缘子故障引起的线路故障,需检修部门有针对性地对中部地区增加冬季巡查;对于规则 4,东部110 kV线路故障主要由导线及地线故障引发,需对脆弱地区的线路布局等进行优化处理;对于规则5,3—5 月是该省线路(以中部地区的500 kV线路为主)覆冰故障的集中发生期,需中部地区在此时段内加强线路监测并及时进行处理[7]。
4 总结
为进一步完善现有关联规则挖掘算法,本研究根据智能电网大数据发展需求未处理更加适用的FP-network模型的构建,FP-network模型继承了FP-Tree算法的优点,适用于分类(离散)变量,需先离散化处理事务数据,将所需数据压缩于一个无向网络图上,只需扫描1次原数据库,并采取矩阵式的存储形式,显著扩大了存储的事务规模。使智能电网中的大型数据库在时间和空间上的复杂度得到显著降低,在简化被挖掘数据的更新和维护过程的同时,提高了关联规则挖掘算法的效率,能够有效满足智能电网大数据挖掘需求。
参考文献
[1] 孟建良,刘德超.一种基于Spark和聚类分析的辨识电力系统不良数据新方法[J]. 电力系统保护与控制, 2016(3):85-92.
[2] 黄彦浩,于之虹,谢昶,等. 电力大数据技术与电力系统仿真计算结合问题研究[J]. 中国电机工程学报, 2018(1):13-22.
[3] 罗明,孟传伟,黄海量. 基于加权频繁模式树的通信网络告警规则挖掘方法[J]. 计算机工程, 2016(4):190-196.
[4] 薛振宇,胡航海,宋毅,等. 基于大数据分析的县公司综合评价策略[J].电力自动化设备,2017(9):199-204.
[5] 郝然,艾芊,肖斐. 基于多元大数据平台的用电行为分析构架研究[J].电力自动化设备,2017(8):20-27.
[6] 王干军,李锦舒,吴毅江,等. 基于随机森林的高压电缆局部放电特征寻优[J]. 电网技术,2019(4):1329-1336.
[7] 徐遐龄,胡伟,王春明,等. 考虑特征组合效应的电网关键稳定特征筛选方法研究[J]. 中国电机工程学报,2018(8):2232-2238.
(收稿日期:2019.09.23)
